
51、读写锁RWMutex的实现原理?
概念:读写互斥锁是对Mutex的一个扩展,当一个Goroutine获得读锁后,其他Goroutine仍然可以获取读锁。当一个Goroutine获取写锁后,其他Goroutine不能获取读锁和写锁。
使用场景:适用于读多写少的情况。(保证线程安全,有不差的性能)
type RWMutex struct {
w Mutex // 复用互斥锁
writerSem uint32 // 信号量,用于写等待读
readerSem uint32 // 信号量,用于读等待写
readerCount int32 // 当前执行的读的Goroutine数量
readerWait int32 // 被阻塞的准备读的Goroutine数量
}互斥锁与读写互斥锁的区别?
- 读写互斥锁分为读者和写者,而互斥锁不区分。
- 读写互斥锁同一时间可以有多个读者,但只能有一个读者;互斥锁同一时间读者和写者只能有一个。
52、Golang中原子操作有哪些?
- 概念:原子操作是直接通过一个独立的CPU指令实现,是无锁的。其他同步技术的实现常常依赖原子操作。
- 适用场景:当需要对某个变量并发修改时,可以使用sync/atomic包的原子操作,它能够保证对变量的读取和修改不被其他协程所影响。atomic包提供的原子操作能够保证任一时刻只有一个goroutine对变量进行操作,善用atomic能够避免程序中出现大量的锁。
- 常见的操作:增减(Add)、载入(Load)、交换(Swap)、比较并交换(CompareAndSwap)、存储(Store)。
53、原子操作和锁的区别?
- 原子操作是底层硬件支持的;锁是原子操作和信号量完成的。因此原子操作效率更高。
- 原子操作是单个CPU的互斥操作;锁是一种数据结构。
- 原子操作是无锁行为,属于乐观锁;锁一般属于悲观锁。
54、Goroutine的实现原理?
55、Goroutine和线程的区别?
从内存占用、创建和销毁以及切换三方面总结。
内存占用:创建一个Goroutine耗费2KB大小的内存;线程耗费内存为1MB。
创建和销毁:Goroutine由Go runtime管理,是用户级,创建和销毁消耗较小;线程由内核管理,创建和销毁消耗较大,通常的解决方法是线程池。
切换:Goroutine切换只需保存3个寄存器,消耗时间为200纳秒(ns);线程切换需要保存各种寄存器,消耗时间为1000-1500ns。
56、Goroutine泄漏的原因?
- Goroutine中对channel或mutex等读写操作被一直阻塞。
- Goroutine中发生死循环,资源一直无法被释放。
- Goroutine中的业务逻辑进入长时间等待,不断有新增的Goroutine进入等待。
监控Goroutine的方法:使用runtime.NumGoroutine()、使用PProf工具(生产/测试环境)
57、Golang中Goroutine到线程实现模型?
概念:Golang实现的是两级线程模型(M:N),准确来说是GMP模型,是对两级线程模型的改进,使它能够更加灵活地进行线程间的调度。
三种线程模型:内核级线程模型、用户级线程模型和两级线程模型。它们之间的区别在于用户线程与内核线程的对应关系。
内核级线程模型(1:1):一个用户线程对应一个内核线程
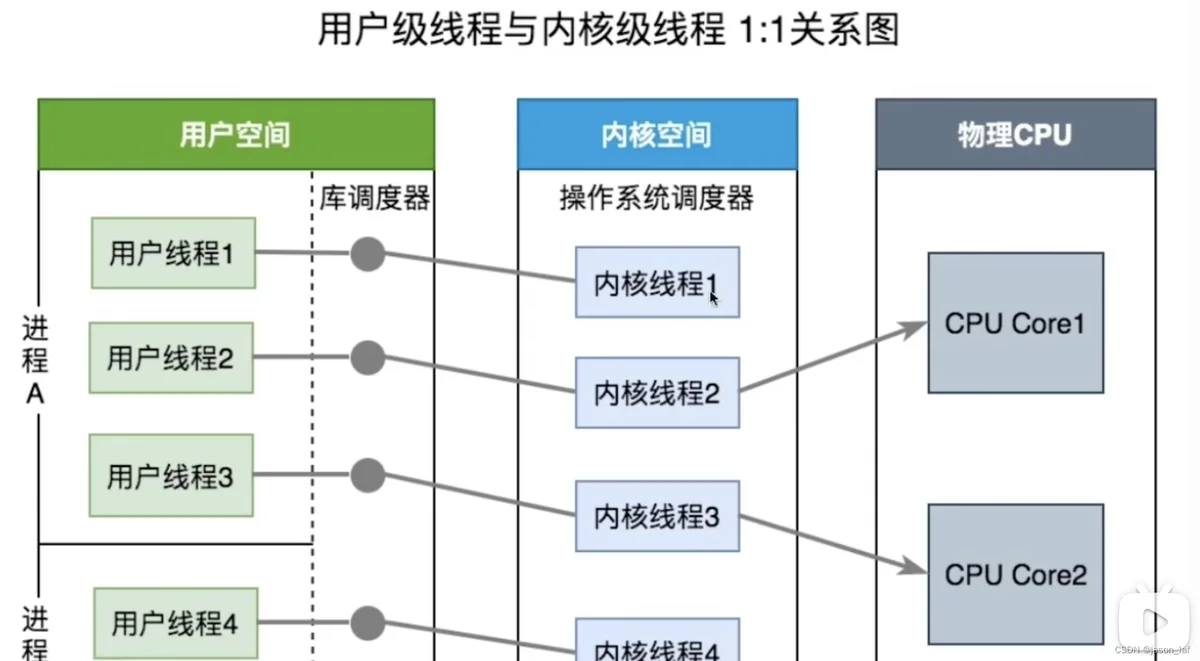
- 优点:容易实现、能够利用CPU多核、如果一个线程被堵塞,不会阻塞其他线程,可以切换到同一进程内的其他线程执行。
- 缺点:切换上下文成本高,在内核态完成切换。创建、删除和切换都由CPU完成。
用户级线程模型(N:1):N个用户线程对应1个内核线程
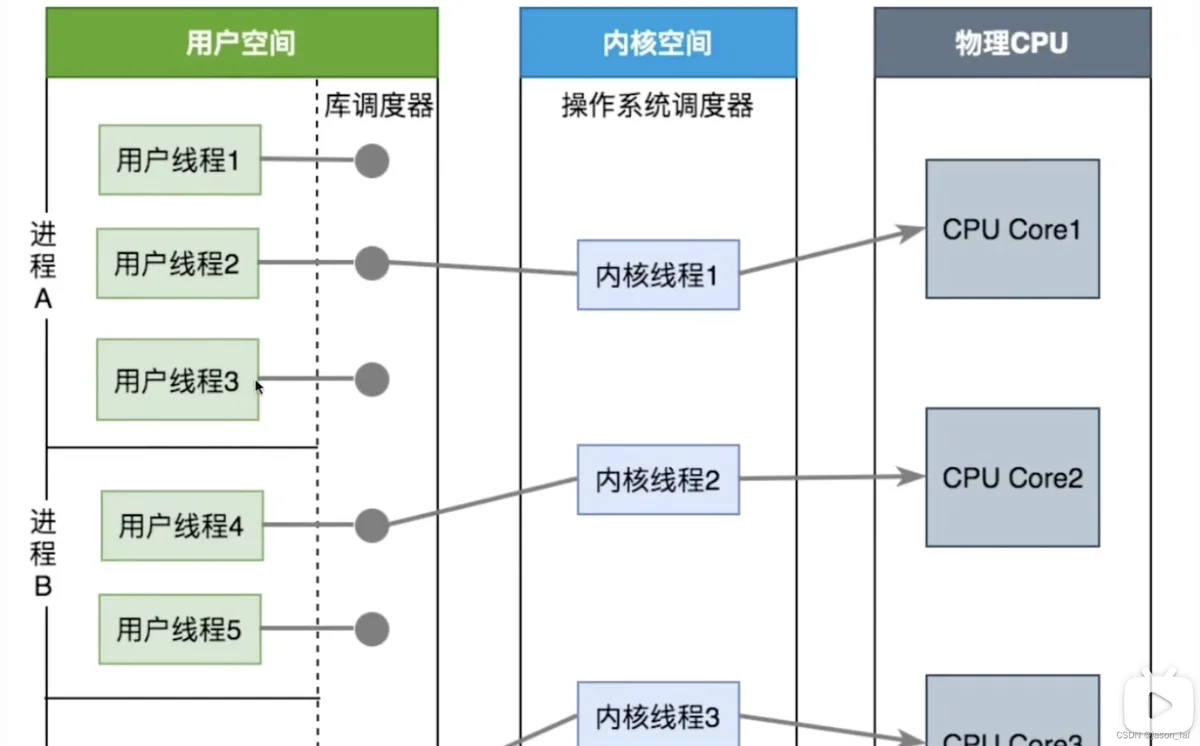
- 优点:上下文切换成本低,在用户态即可完成切换。
- 缺点:一个进程无法充分利用CPU多核、一个线程被阻塞会阻塞本进程的其他线程。
两级线程模型(M:N):M个用户线程对应N个内核线程
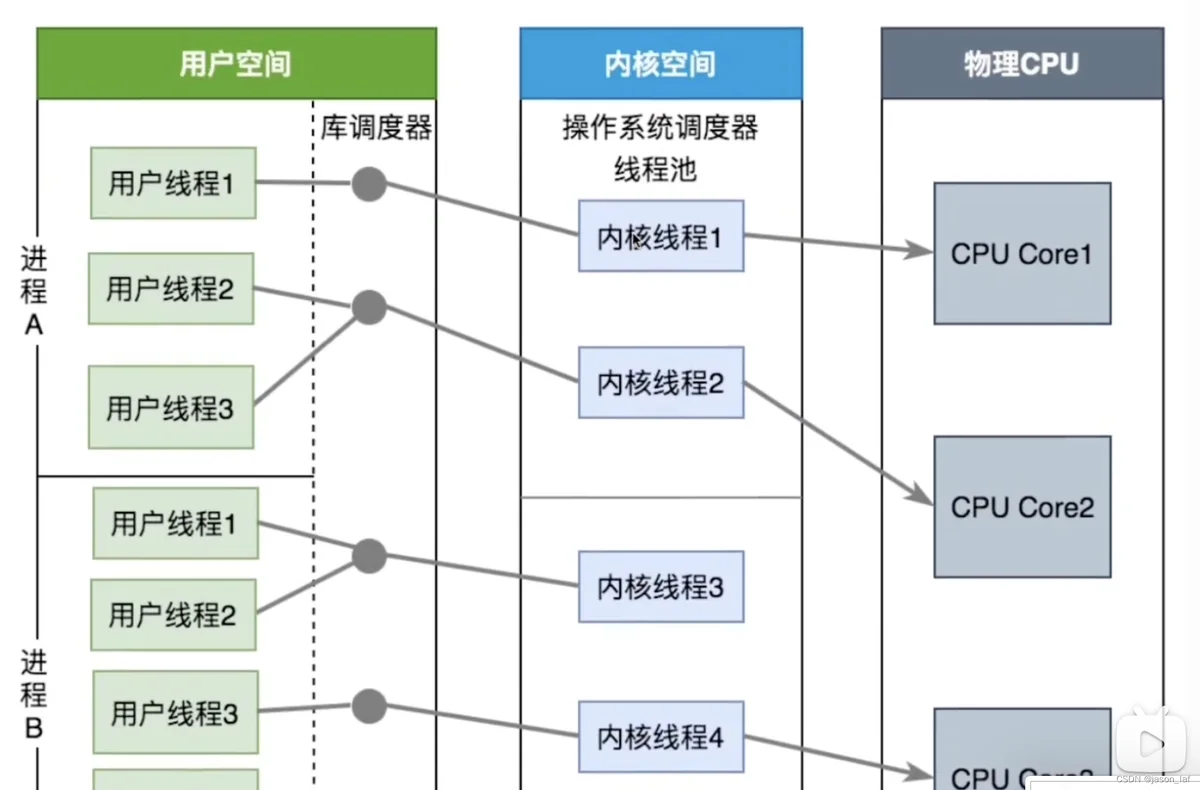
优点:上下文切换成本低、能够充分利用CPU多核、一个线程被阻塞不会影响其他线程。
缺点:实现复杂。
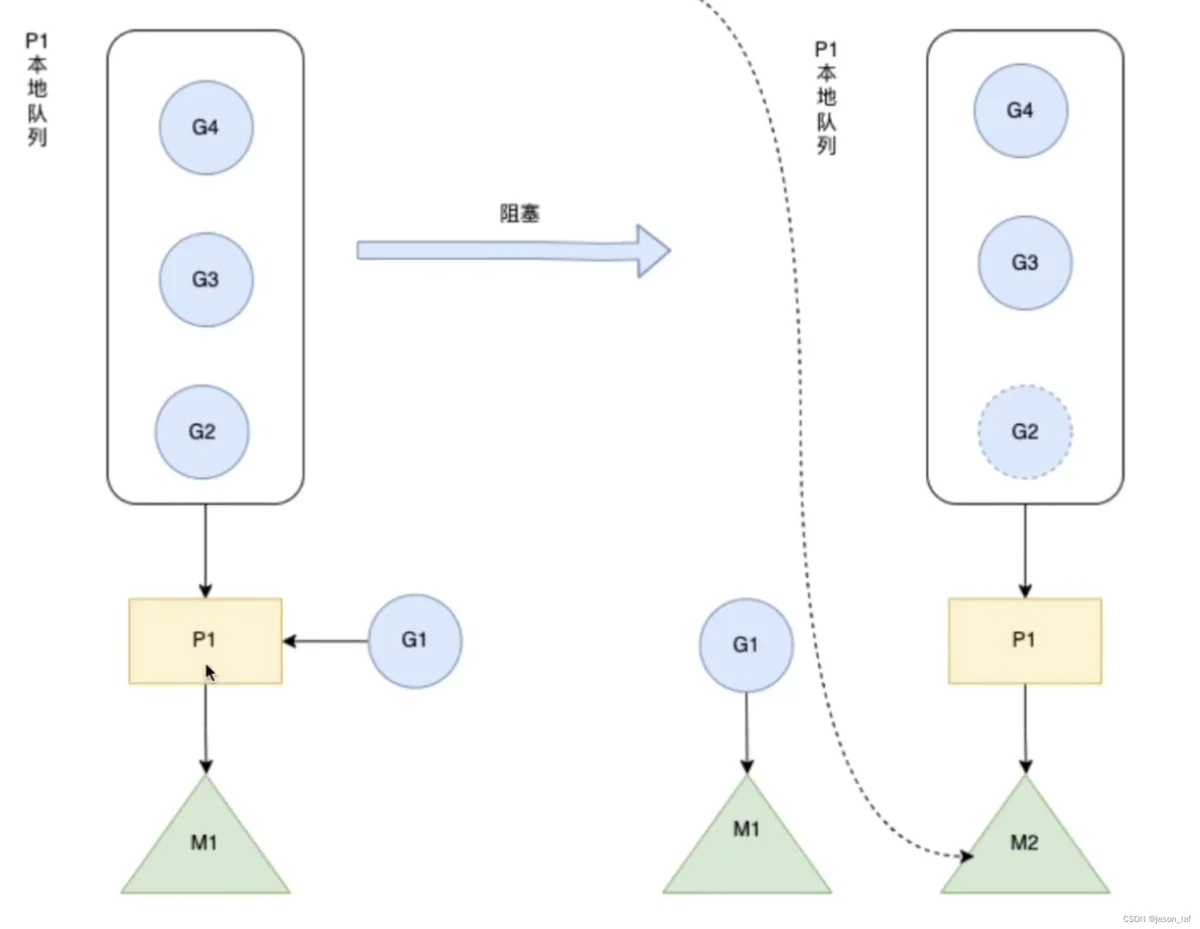
58、Golang中hand off机制?
hand off机制也被称为P分离机制,其作用是当本线程M由于G的系统调用而被阻塞时,M会将P释放给其他空闲的M执行,这样就提高了M的利用率。
59、work stealing机制?
概念:当线程M没有可以运行的G时,会尝试从其他的P(全局队列、netpoller和其他本地队列)中偷取G,从而提高线程利用率。
- 从其他的本地队列偷取的G数量:N=len(LRQ)/2;
- 从全局队列偷取的G数量:N=min(len(GRQ)/GOMAXPROCS+1, len(GRP)/2);
- 从netpoller(网络轮询)中拿到的是_Gwaiting状态(存放的是由于网络IO被阻塞的G),从其他地方拿到的是_Grunnable状态。
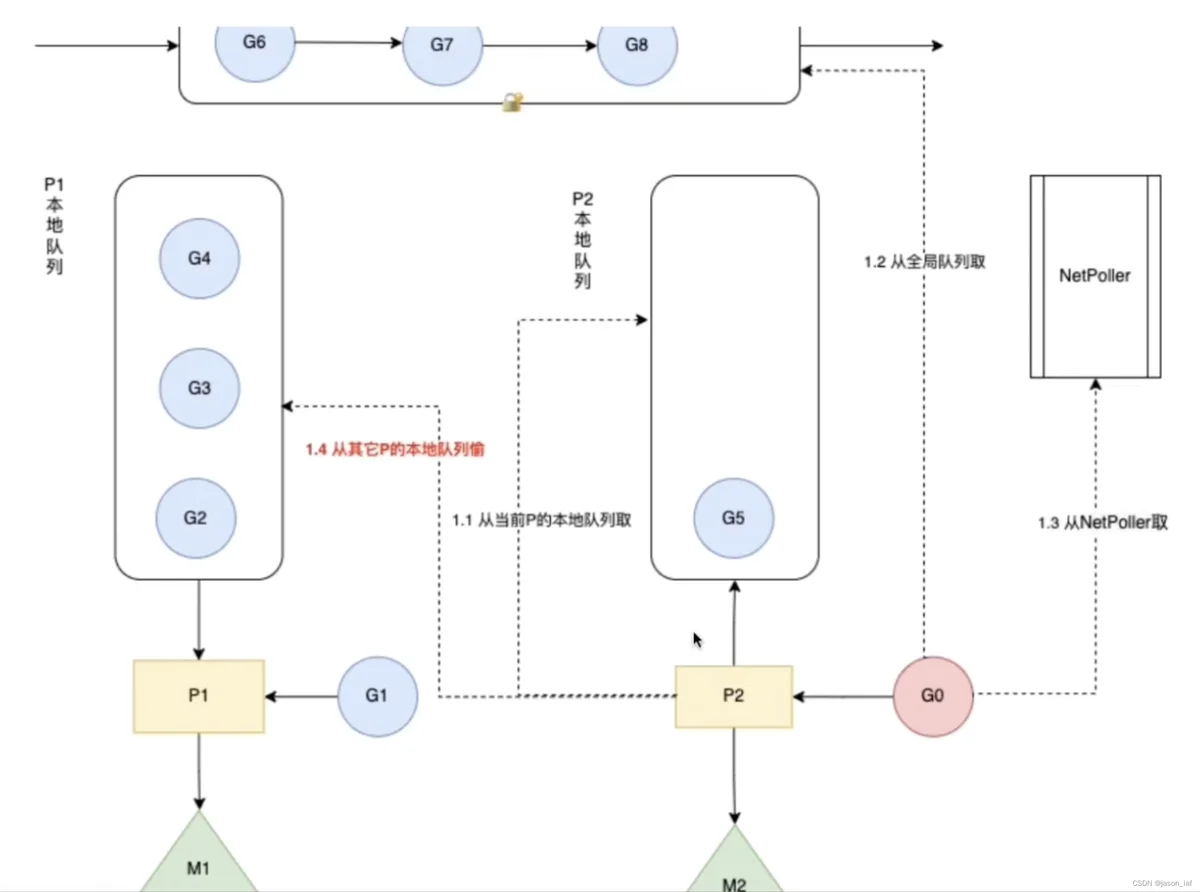
选择要窃取的P:为了保证公平性,窃取的P并不是固定从第一个开始,而是随机选择。
60、GMP和GM模型?
一、GM模型
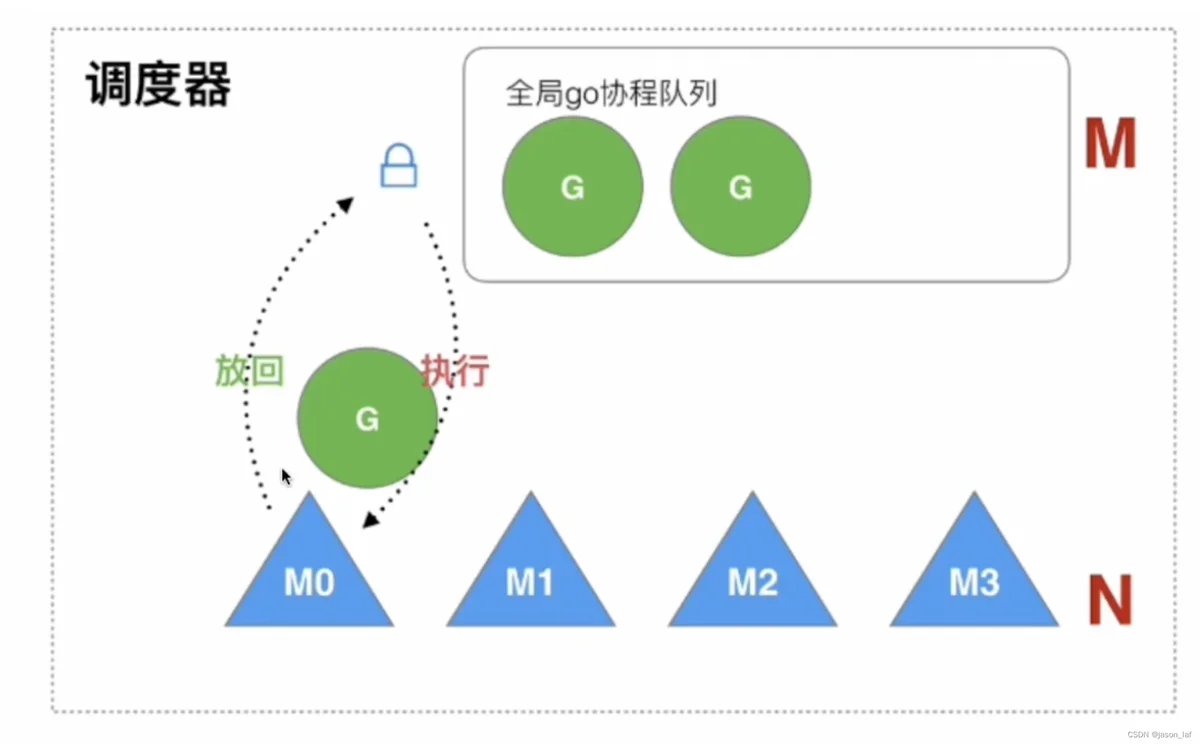
存在的问题:
- 当M从全局队列中添加或者获取G的时候,都需要获取队列锁,存在激烈的锁竞争
- M转移G增加额外的开销,当M1执行G1时,创建了G2,为了继续执行G1,会将G2放到全局队列中,因此可能有其他的M执行G2,但是由于M1保存了G2的信息,因此G2最好是在M1上执行
- 没有hand-off和work- stealing机制,对线程的利用不充分
二、GMP模型
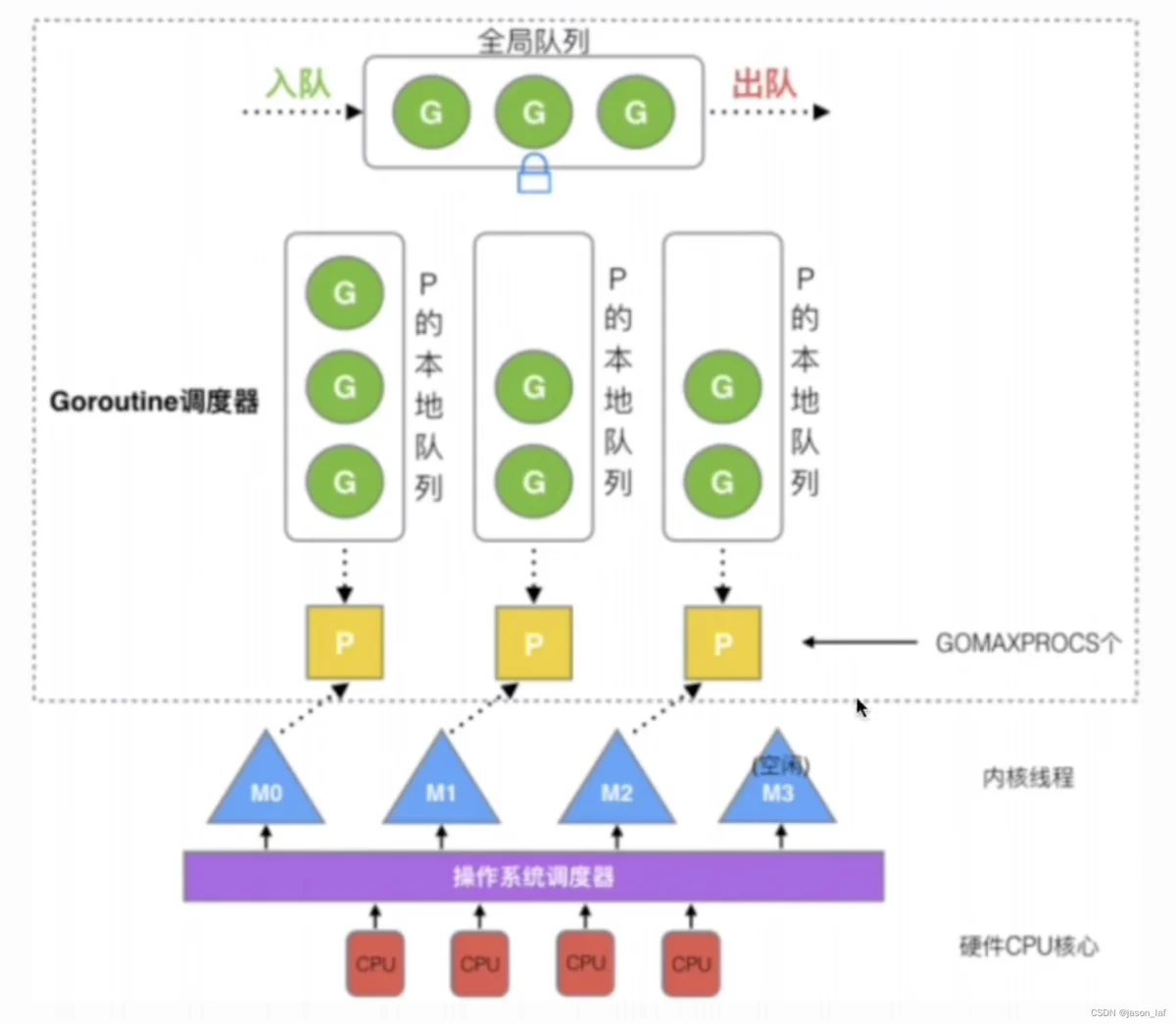
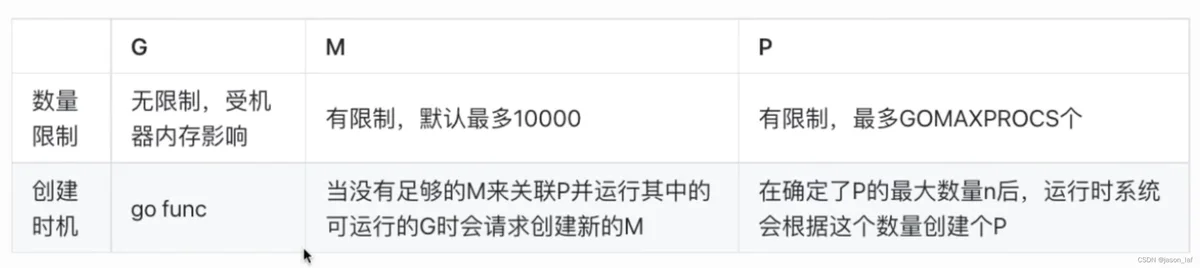
- G(Goroutine),G存储了Goroutine的执行栈信息,状态以及任务函数等。G的数量无限制,只收到内存大小限制,创建一个G的初始栈大小为2-4KB。G在执行完后会被清理放到本地队列或者全局队列的闲置列表中以重复使用。
- M(Machine)是对操作系统线程的封装,可以看成操作系统内核线程。M的数量有限制,默认为10000。M在绑定P后进入调度循环,从本地队列和全局队列中获取G,切换到G的执行栈上并执行G的函数,在清理后回到M,如此反复。M并不保存G的状态,这是G可以夸M执行的基础,
- P(Process)是虚拟处理器,包括M执行G所需要的资源和上下文,只有将P和M绑定,才能让runq中的G真正运行起来。P的数量决定了系统最大可并行的G的数量,P受到CPU核数影响。
61、Goroutine调度原理?
调度本质是将Goroutine按照一定的算法放到CPU上去执行。
CPU感知不到协程,只知道内核线程。因此,需Go调度器将协程绑定到内核线程上,再由操作系统调度器将内核线程放到CPU上执行。
62、Golang抢占式调度?
概念:golang的抢占式调度是基于系统信号的,也就是通过向线程发送信号的方式来抢占正在运行的Goroutine。不管协程有没有意愿让出CPU运行权,只要某个协程执行时间过长,就会发送信号强行夺取CPU运行权。
- 每个M会注册一个信号处理函数
- 存在一个定时任务监控协程的运行时间。如果发现某协程独占P超过10ms,就会给M发送信号
- M接收到信号会将当前协程由_Grunning状态转换为_Grunable状态,然后把协程放到全局队列里,再去找其他的协程运行
- 被抢占的G再次运行时,会继续原来的执行流
63、如何产看运行时调度信息?
go tool trace和命令行GODEBUG两种方法。
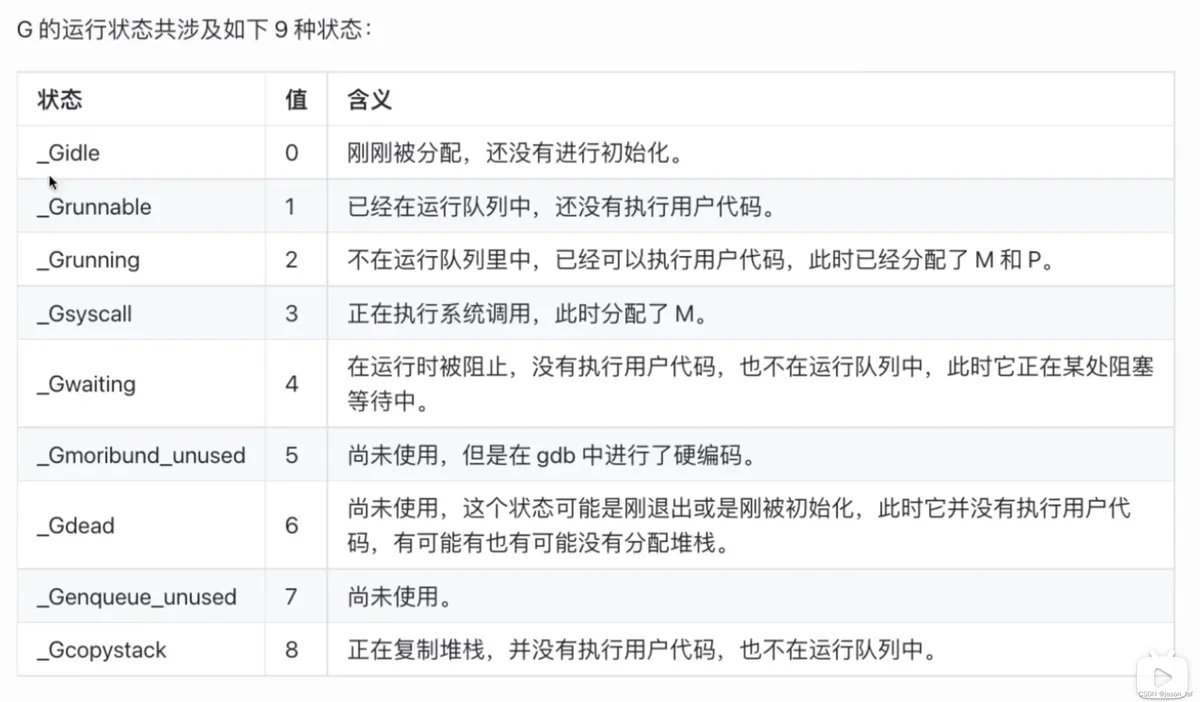
64、sync.Map的实现原理?
核心原理:空间换时间、读写分离、原子操作。
// 封装的线程安全的map
type Map struct {
// lock
mu Mutex
// 实际是readOnly这个结构
// 一个只读的数据结构,因为只读,所以不会有读写冲突。
// readOnly包含了map的一部分数据,用于并发安全的访问。(冗余,内存换性能)
// 访问这一部分不需要锁。
read atomic.Value // readOnly
// dirty数据包含当前的map包含的entries,它包含最新的entries
// (包括read中未删除的数据,虽有冗余,但是提升dirty字段为read的时候非常快,
// 不用一个一个的复制,而是直接将这个数据结构作为read字段的一部分),有些数据还可能没有移动到read字段中。
// 对于dirty的操作需要加锁,因为对它的操作可能会有读写竞争。
// 当dirty为空的时候, 比如初始化或者刚提升完,下一次的写操作会复制read字段中未删除的数据到这个数据中。
dirty map[interface{}]*entry
// 当从Map中读取entry的时候,如果read中不包含这个entry,会尝试从dirty中读取,这个时候会将misses加一,
// 当misses累积到 dirty的长度的时候, 就会将dirty提升为read,避免从dirty中miss太多次。因为操作dirty需要加锁,后续的store操作会生成新的dirty。。
misses int
}
// readOnly is an immutable struct stored atomically in the Map.read field.
type readOnly struct {
m map[interface{}]*entry
// 如果Map.dirty包含一些读map中没有的数据,这个值为true
amended bool
}
// An entry is a slot in the map corresponding to a particular key.
type entry struct {
// *interface{}
p unsafe.Pointer
}sync.Map底层使用了两个原生map,一个叫read,仅用于读;一个叫dirty,用于在特定情况下存储最新写入的key-value数据。
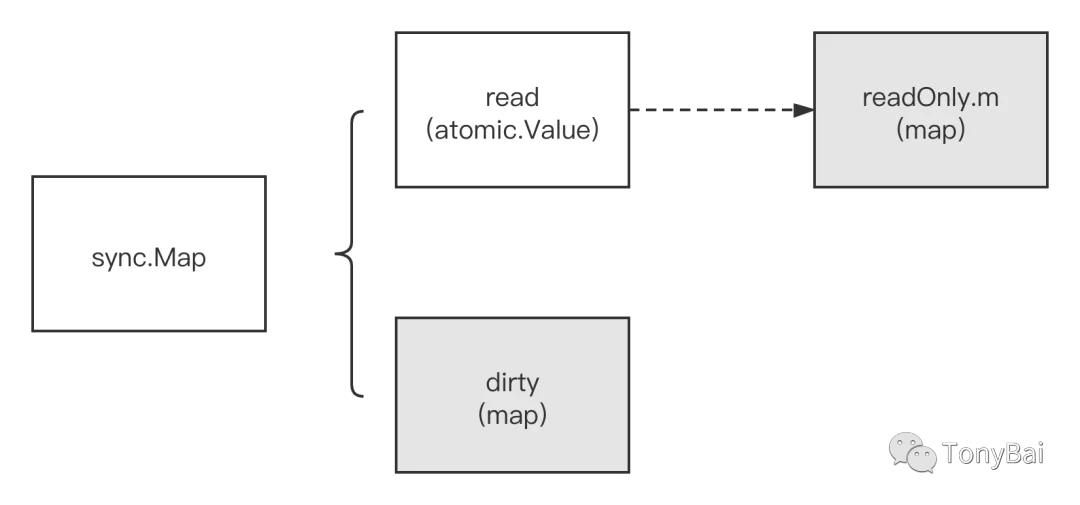
read(这个map)好比整个sync.Map的一个“高速缓存”,当goroutine从sync.Map中读取数据时,sync.Map会首先查看read这个缓存层是否有用户需要的数据(key是否命中),如果有(命中),则通过原子操作将数据读取并返回,这是sync.Map推荐的快路径(fast path),也是为何上面基准测试结果中读操作性能极高的原因。
sync.Map主要包含四个操作:Load、Store、Delete和Range。
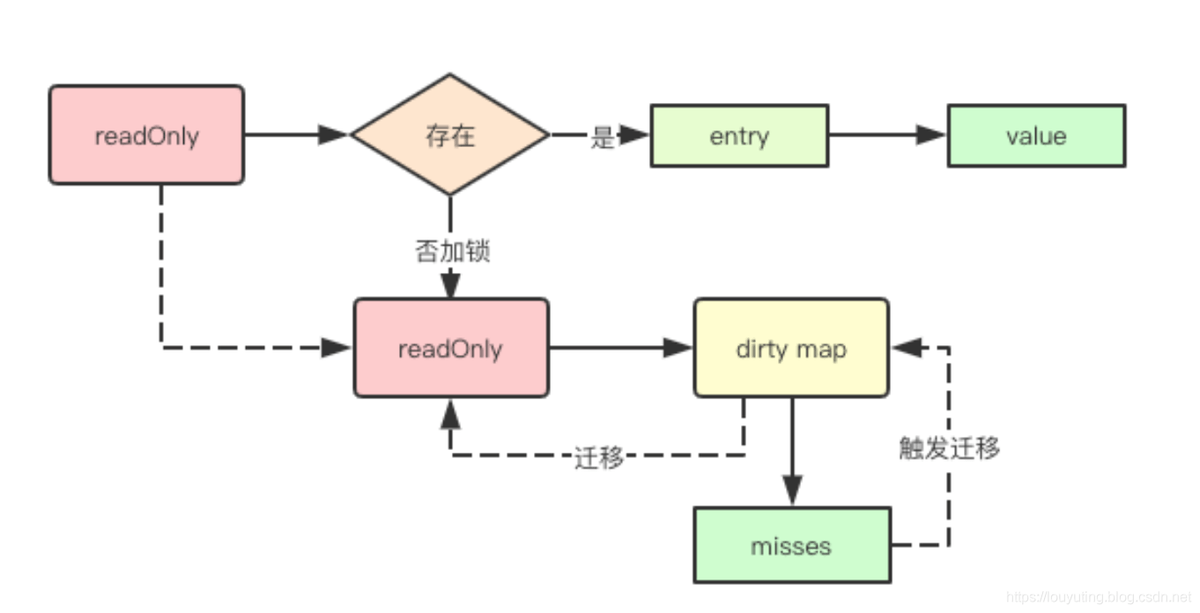
Load操作
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
// 1.首先从m.read中加载只读的readOnly, 从它的map中查找,无锁。
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 2. 如果没找到,并且m.dirty中有新数据,需要从m.dirty查找,这个时候需要加锁
if !ok && read.amended {
m.mu.Lock()
// 3. 二次检查(避免加锁时dirty升级为read)
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 4. 二次检查还没有就去m.dirty查找
if !ok && read.amended {
e, ok = m.dirty[key]
// 不管m.dirty中存不存在,都将misses计数加一
// missLocked()中满足条件后就会提升m.dirty
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
// 原子加载 *entry 所保存的value。
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
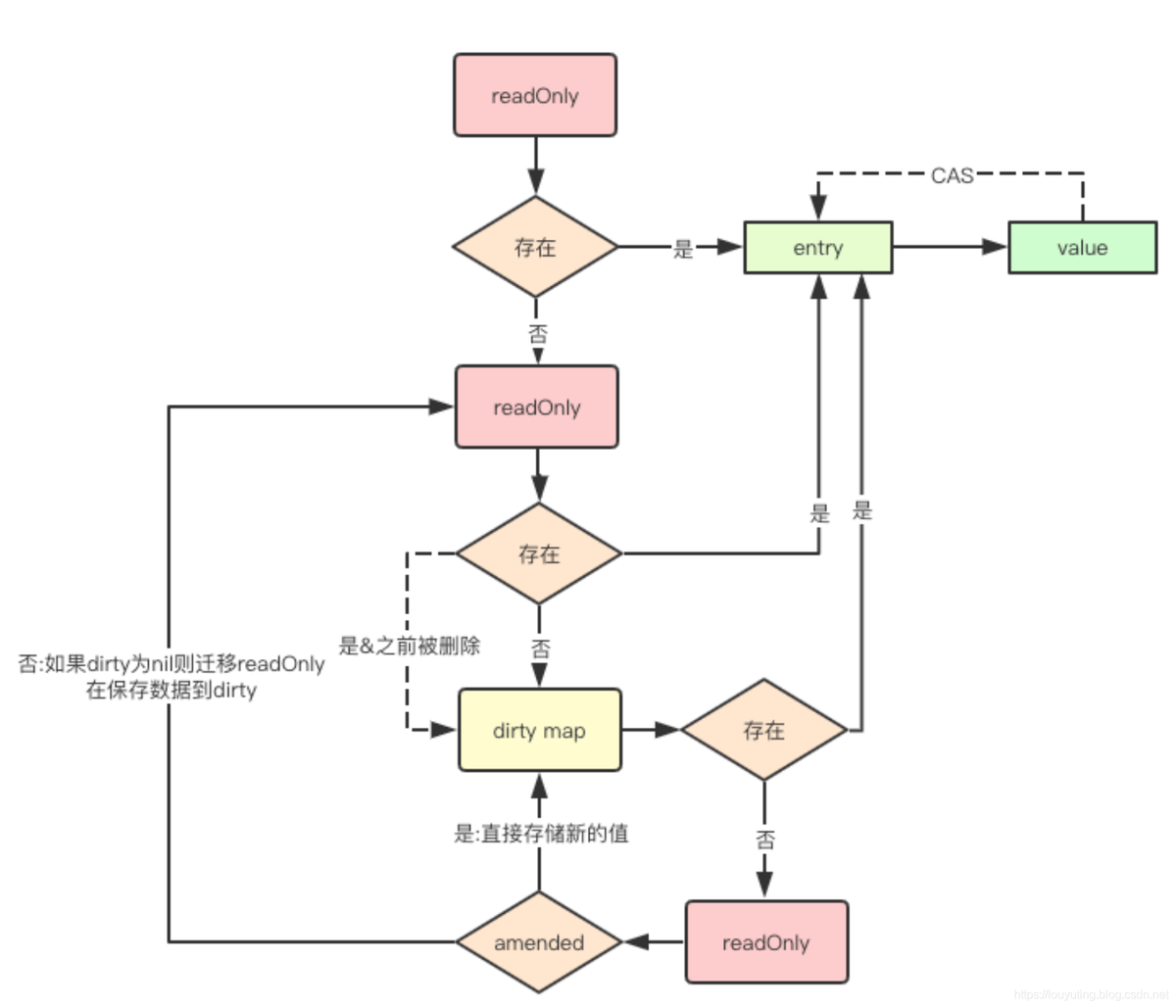
Store操作
// Store sets the value for a key.
func (m *Map) Store(key, value interface{}) {
// 1. 如果m.read存在这个键,并且这个entry没有被标记删除(expunged),那么cas自旋更新value。
// 因为m.dirty也指向这个entry,所以m.dirty也保持最新的entry。
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
// 2. m.read不存在或者已经被标记删除
m.mu.Lock()
// double check
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {//标记成未被删除
//m.dirty中不存在这个键,所以加入m.dirty
m.dirty[key] = e
}
e.storeLocked(&value)
// m.dirty存在这个键,更新
} else if e, ok := m.dirty[key]; ok {
e.storeLocked(&value)
//新键值
} else {
//m.dirty中没有比m.readOnly更新的数据,往m.dirty中增加第一个新键
if !read.amended {
// 从m.read中复制未删除的数据
// 并标记m.read已经落后于m.dirty
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
//将这个entry加入到m.dirty中
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
// tryStore stores a value if the entry has not been expunged.
//
// If the entry is expunged, tryStore returns false and leaves the entry
// unchanged.
func (e *entry) tryStore(i *interface{}) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
Delete操作
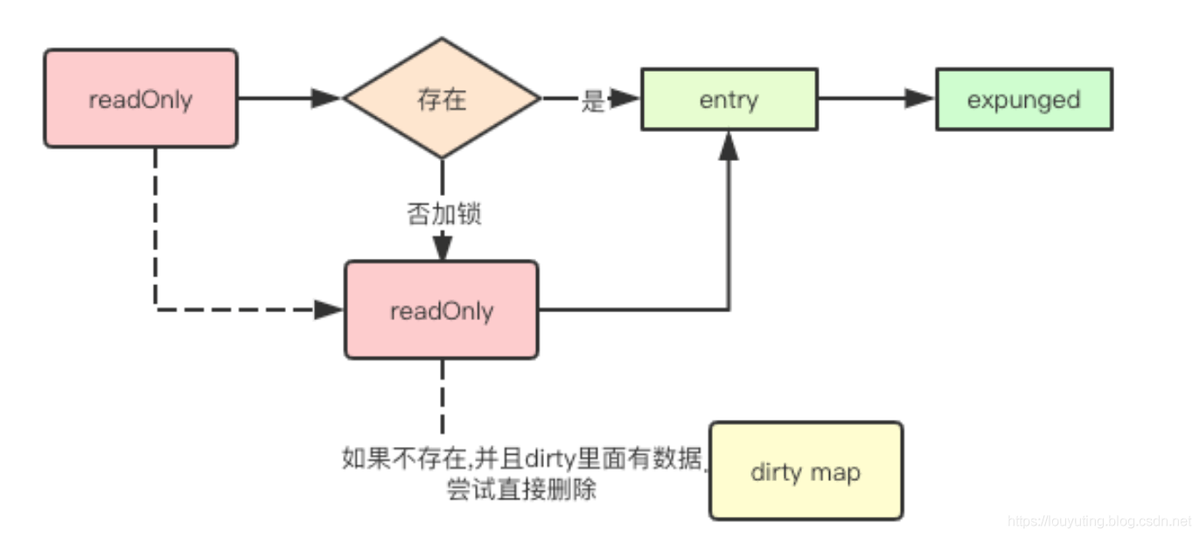
func (m *Map) Delete(key interface{}) {
// 1. 如果不存在于 m.read中,而且 m.dirty 和 m.read 数据不一致。
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
if !ok && read.amended {
// 加锁,double check, 然后删除对应的key。
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
e.delete()
}
}
Range操作
func (m *Map) Range(f func(key, value interface{}) bool) {
// 如果m.dirty中有新数据,则提升m.dirty,然后在遍历
read, _ := m.read.Load().(readOnly)
if read.amended {
///提升m.dirty
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
// 遍历, for range是安全的
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}
sync.Map 的实现原理可概括为:a、过 read 和 dirty 两个字段将读写分离,读的数据存在只读字段 read 上,将最新写入的数据则存在 dirty 字段上b、读取时会先查询 read,不存在再查询 dirty,写入时则只写入 dirtyc、读取 read 并不需要加锁,而读或写 dirty 都需要加锁d、另外有 misses 字段来统计 read 被穿透的次数(被穿透指需要读 dirty 的情况),超过一定次数则将 dirty 数据同步到 read 上e、对于删除数据则直接通过标记来延迟删除