
字符在计算机中以二进制编码的方式存储,就是我们通常说的ascii
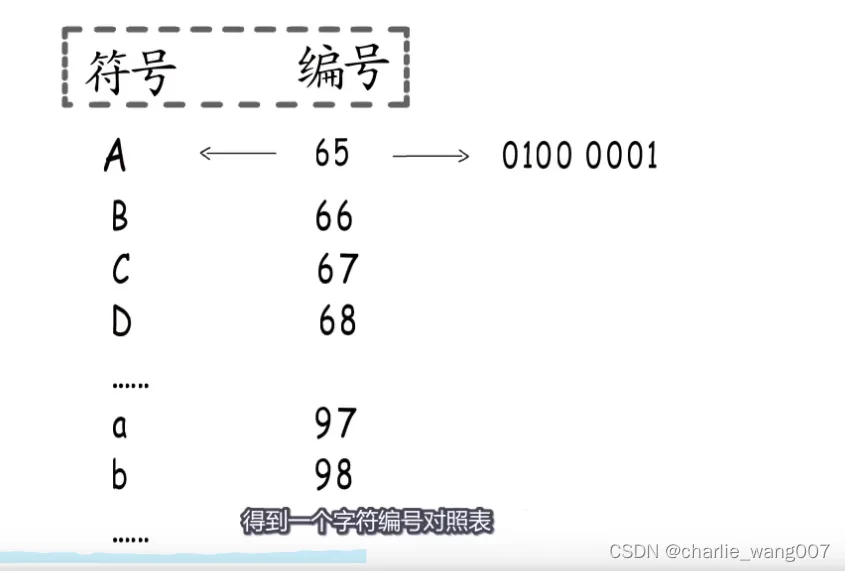
像这样简历字母和二进制对应关系的对照表 我们称为字符集,
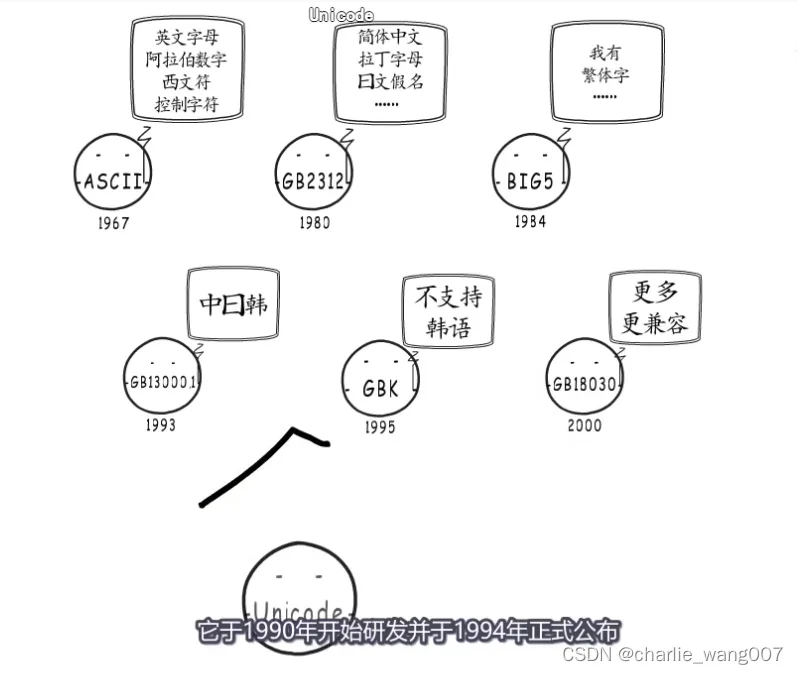
随着计算机的发展,产生了不同的编码集,目前unicode统一了全球各种编码
但是在使用中有出现了新的问题
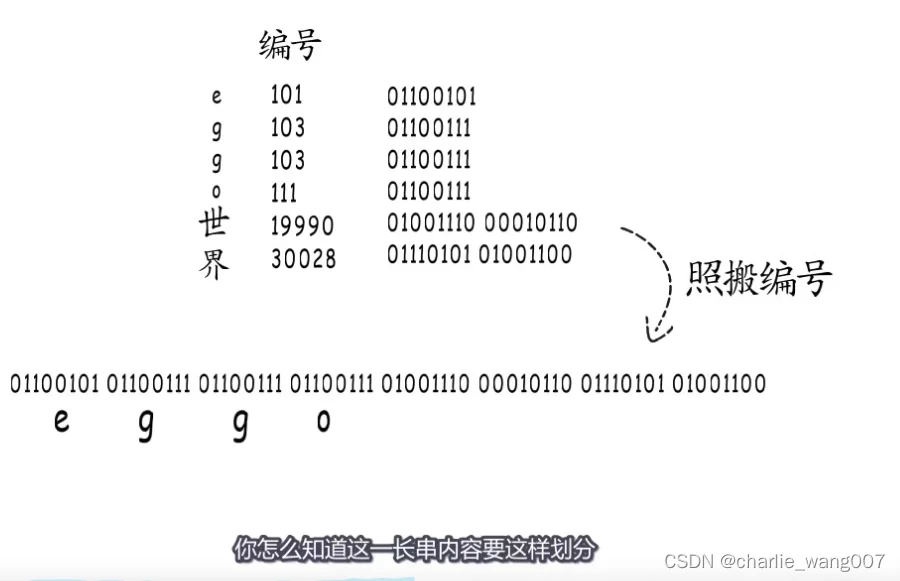
因为各种字符的编码长度不一样,在编码后计算机读取的时候,不能确定编码后的边界

定长编码的方式无疑会造成内存的浪费

变长编码以字符编码的区间和高位的标记来表示字节的长度边界
- 0-127 占1字节 高位为0
- 128-2047 占2字节 高位为11
- 2048-65535 占3字节 高位为111
通过这个编码的模板,可以实现编码以及解码


这也就是go使用的utf-8编码
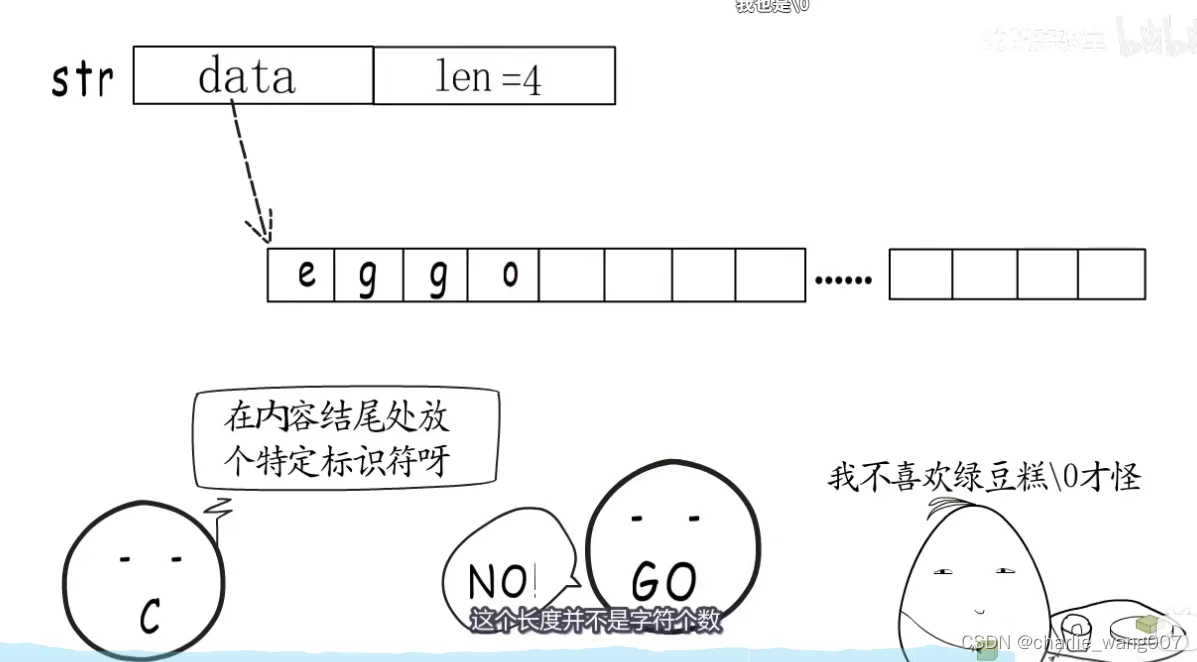

go存储字符串的时候,指定了存储的位置,以及长度,这样操作系统就知道从哪里读取字符串,以及读多少,
Slice的底层以及扩容规则结构
slice底层有三个属性
- 数据存储地址
- 存储的数量,存了几个
- 数组的容量
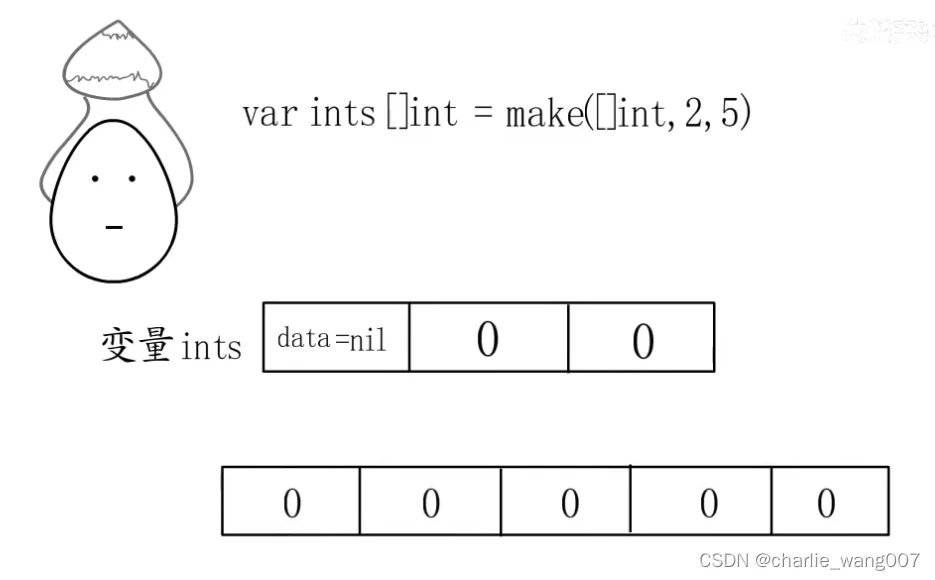
初始化
make():
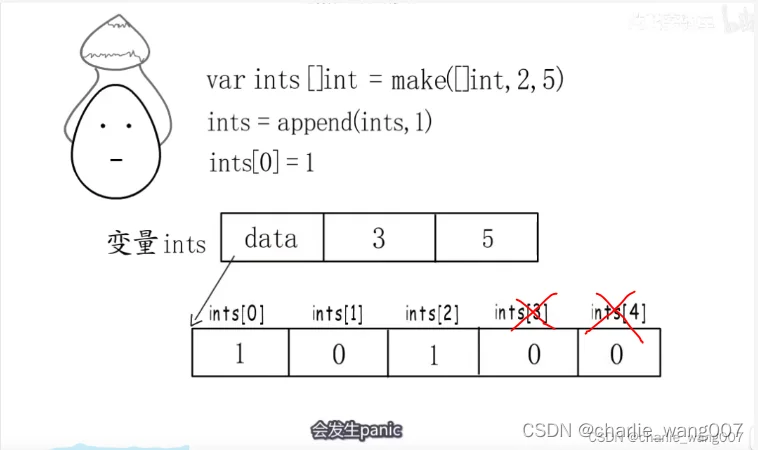
new()
只会返回一个位nil的地址

append才会申请内存
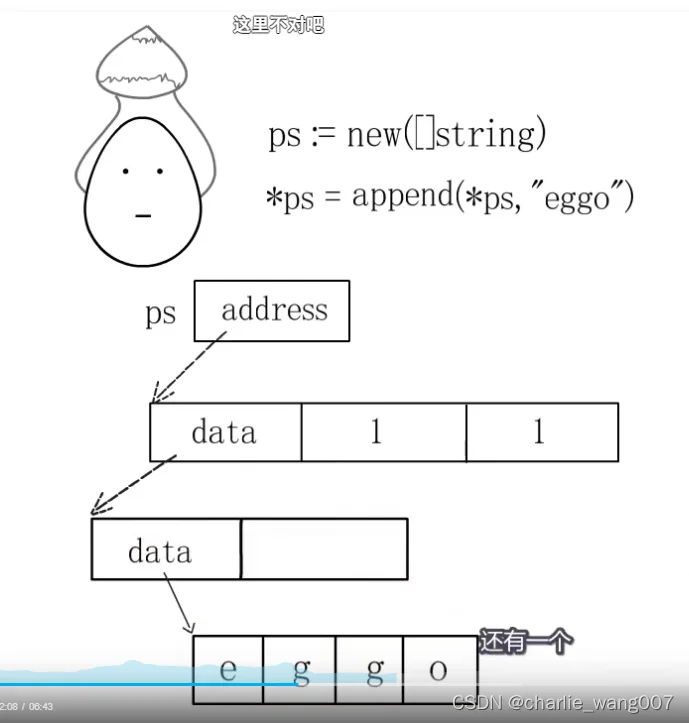
使用slice需要注意:
1 定义slice最好一次分配好cap,防止append操作再次申请内存降低代码性能
2 访问还没有初始化的元素,或者越界访问会panic,coding时要清除自己slice的cap
3 make方法会申请内存,初始化元素为0,new只会返回一个底层数组的起始地址,通过append申请内存
slice与底层数组的关系
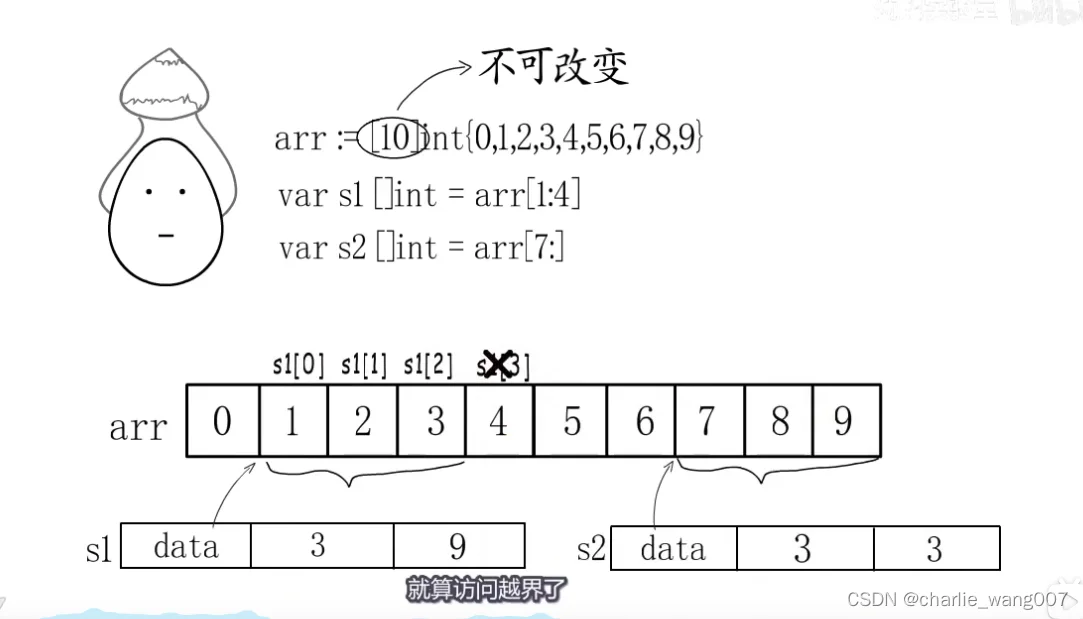
1 s1和s2都是从arr的切片,但是他们的起始地址并不是arr的起始地址,而是截取的开头字符地址
2 切片访问元素同样不能越界
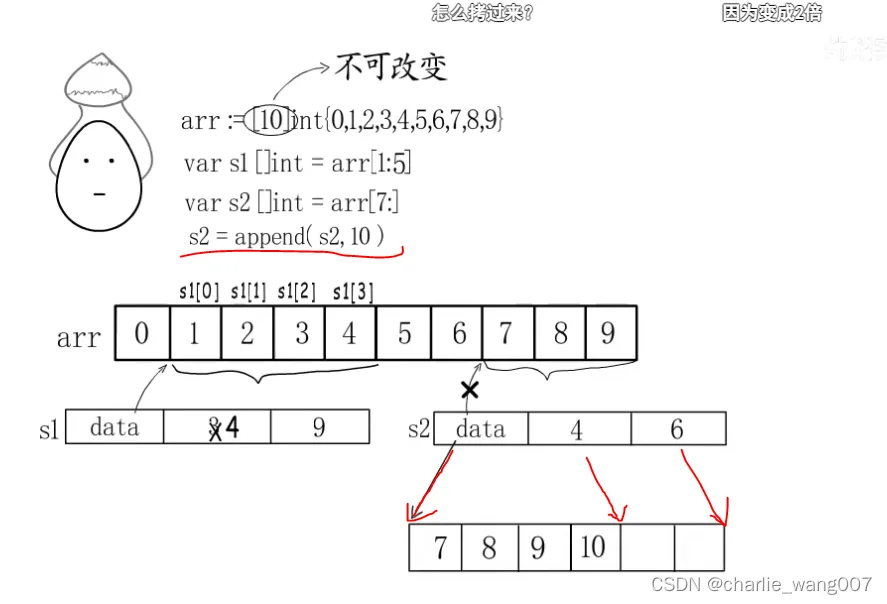
3 如果给s2append一个元素,s2就不能共享原始arr的存储地址了,就要开辟新的地址
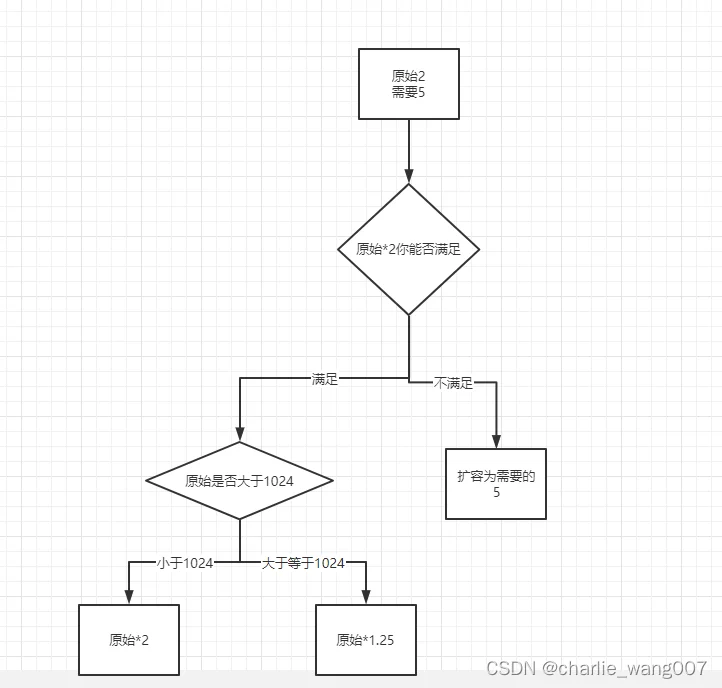
扩容规则
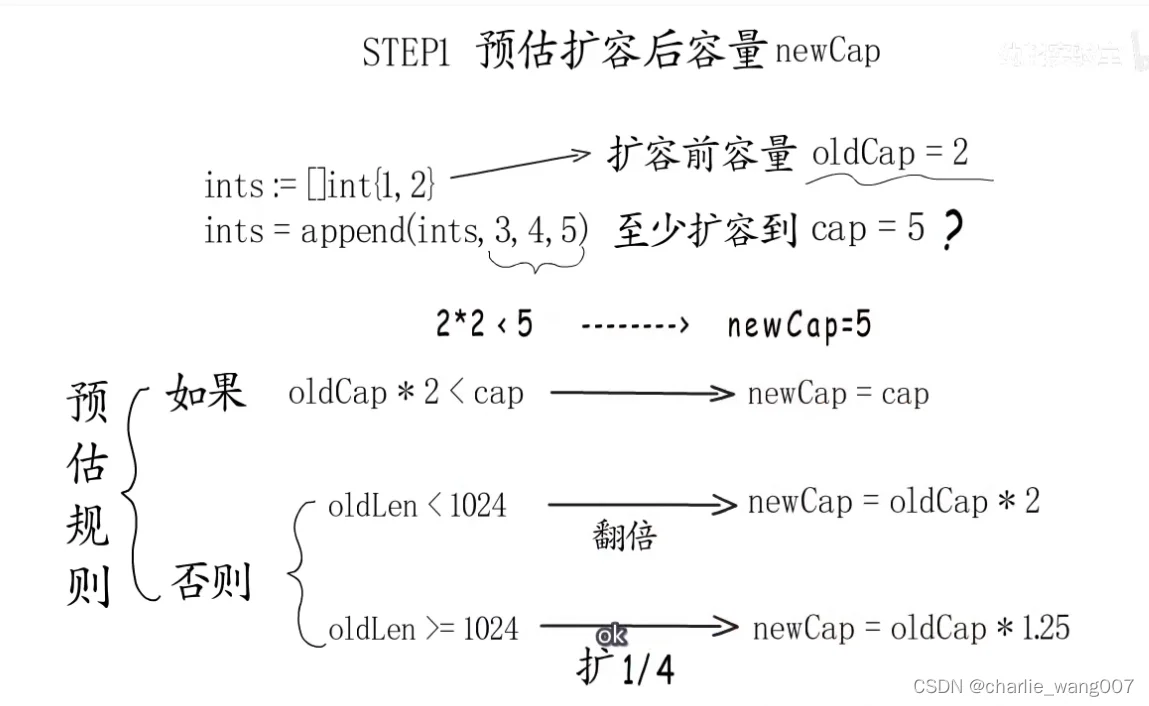
扩容规则:
分配内存:

一般以预估容量*字节数为准,但是操作系统的内存是划分成固定的块的,操作系统的内存管理单元MMU给程序申请到合适大小的内存
一 map存储方式
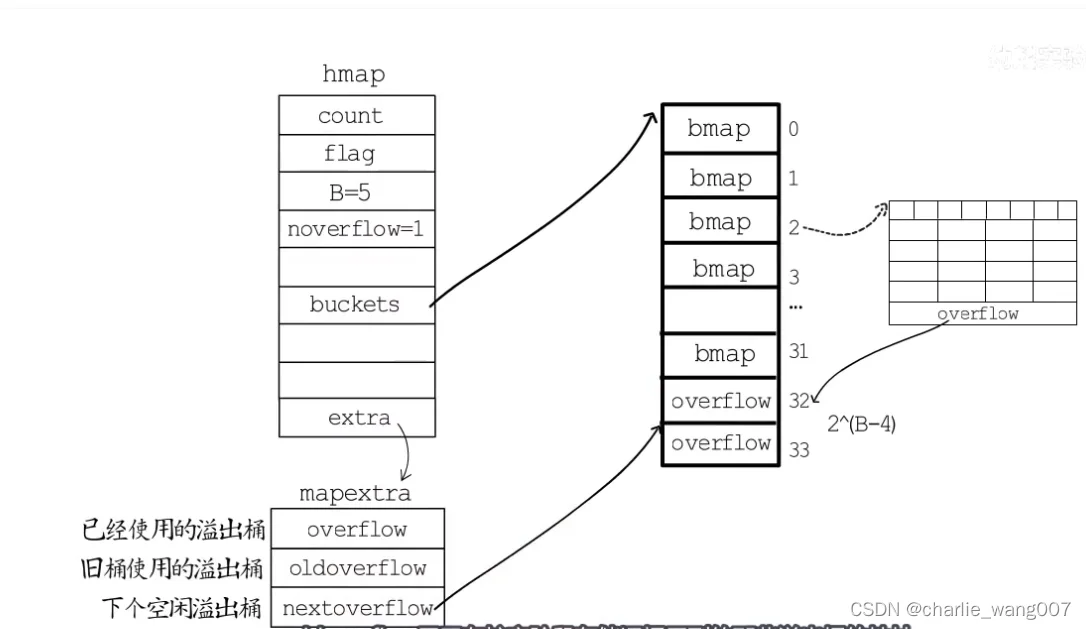
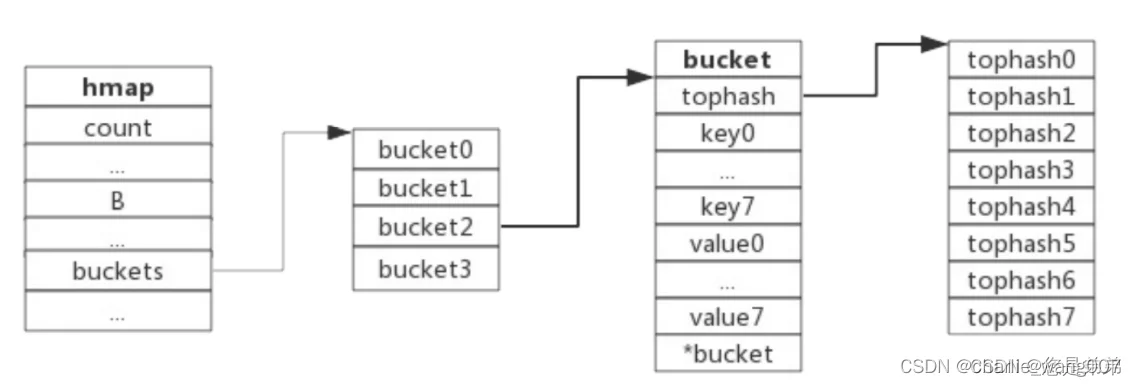
1)桶的选择(取模,与运算)
如何选择存储到哪个桶?
1取模法-key通过hash运算,与桶个数m取模
2与运算–hash处理后的桶与通个数m-1与运算,但要保证桶个数为m的值必须是2的整数次幂,否则会出现空桶
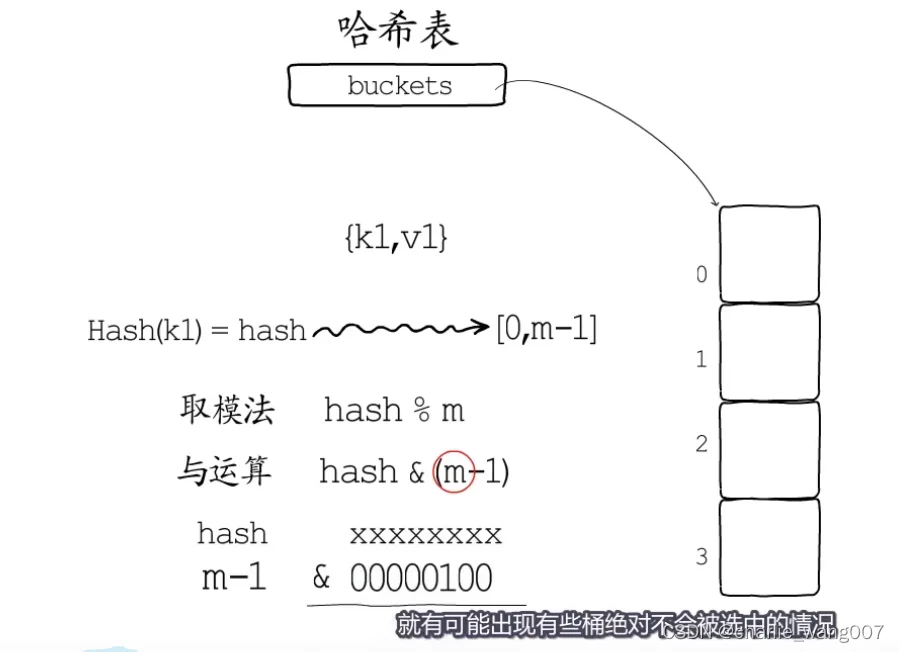
2)哈希冲突的解决(开放地址,拉链法)
以上也不能保证不会发生hash冲突,解决办法:
1开放地址法-定位到第二个桶,若桶2不为空,则向后找空桶存储,get的时候找到2对比key不相等,就向下查找
2拉链法-定位到2但是2号桶不为空,就在2后面链一个桶存储,get时从2的链表向后对比key
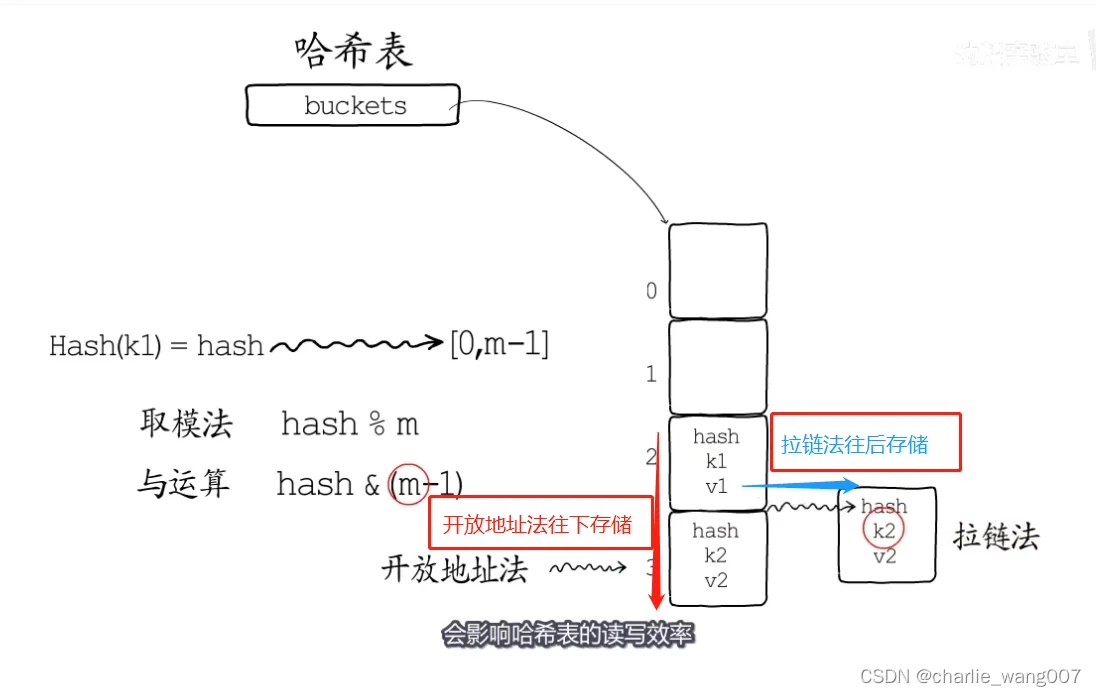
二 hmap结构体
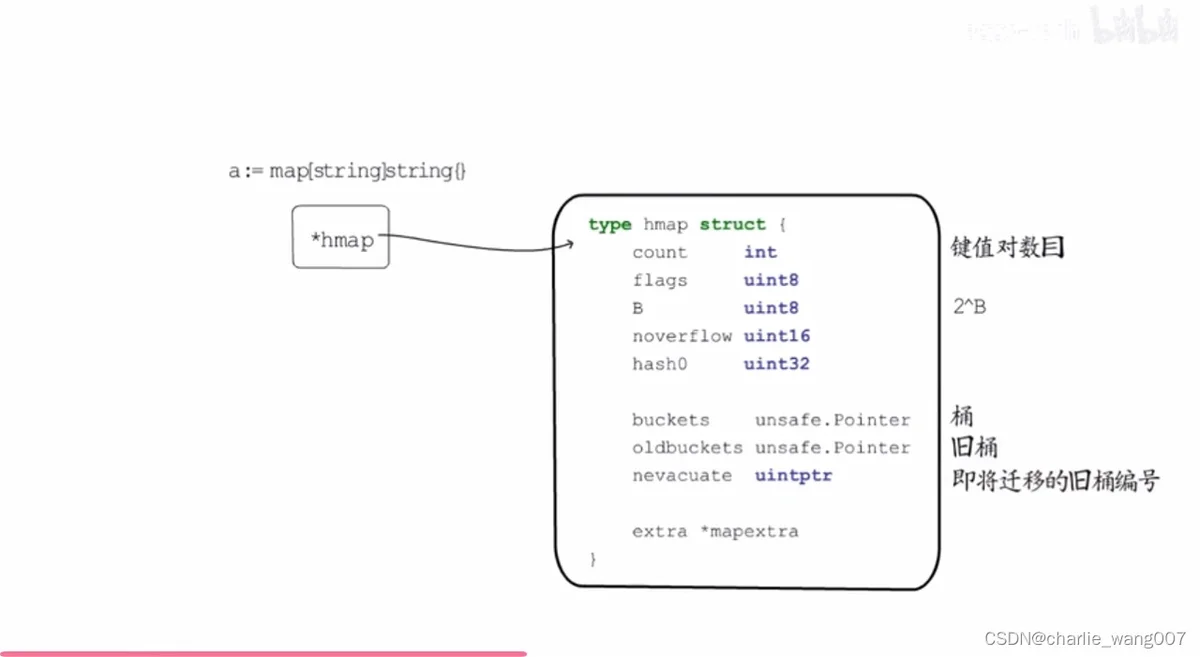
三 bmap结构体
bmap表示桶
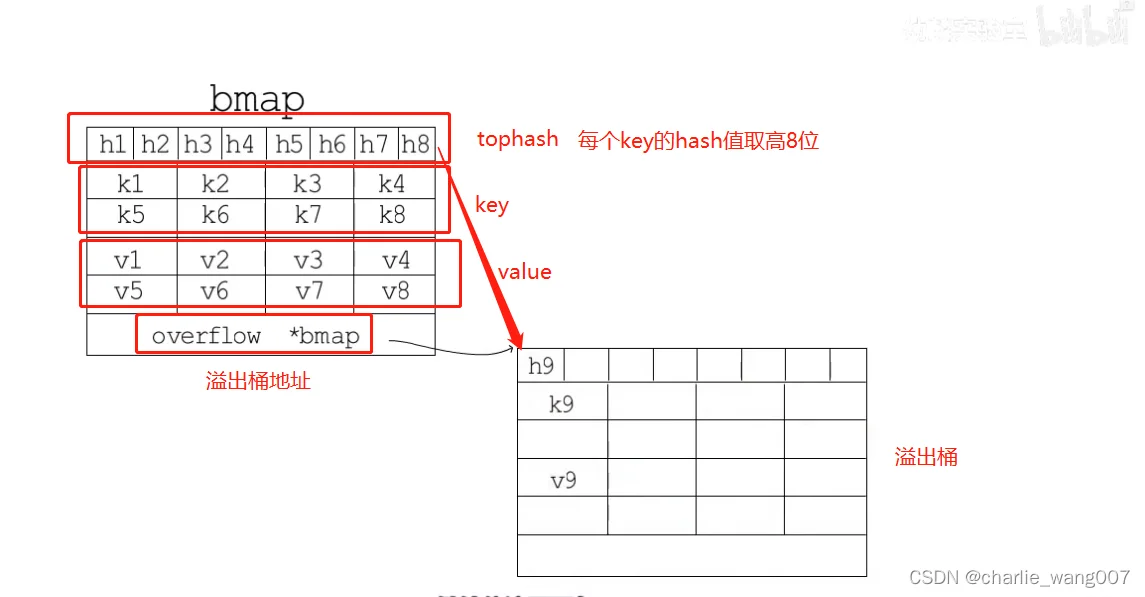
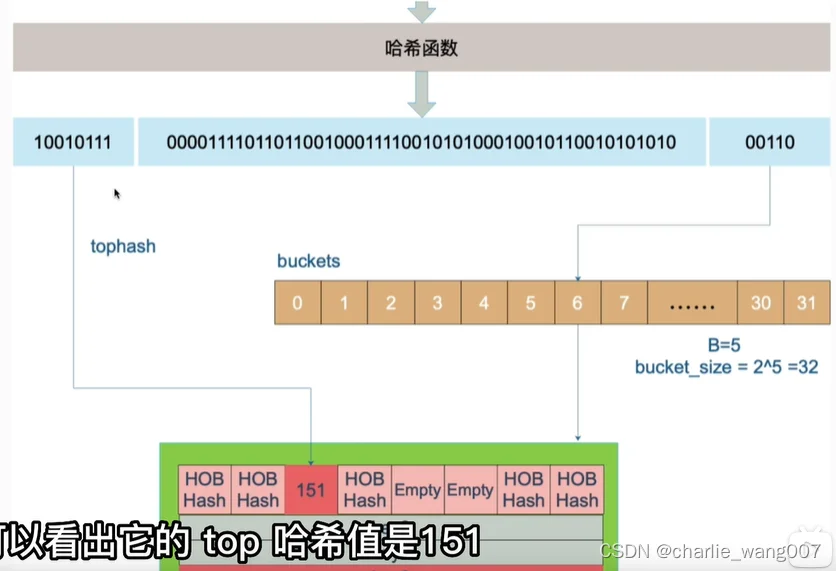
tophash:每个key的hash值 取高8位,如key是string,占16字节,取前8位(第一个字节)
1 一个bmap结构存放8个键值对
2 存储的时候key放在一起,value放在一起
3 当一个map的桶存满时,下一个键值对存入溢出桶,overflow记录溢出桶的地址
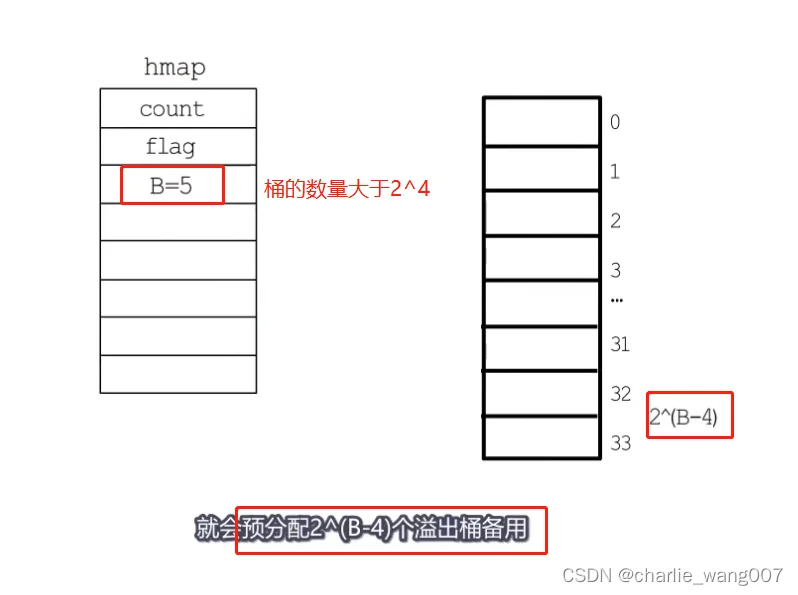
4 当一个map的分配的同数量大于2^4,那么会认为使用溢出桶的概率比较大,
会预先分配2^(b-4)个溢出桶,常规桶和溢出桶在内存地址上是连续的,
只是前2^4个时常规桶,后面则是溢出桶
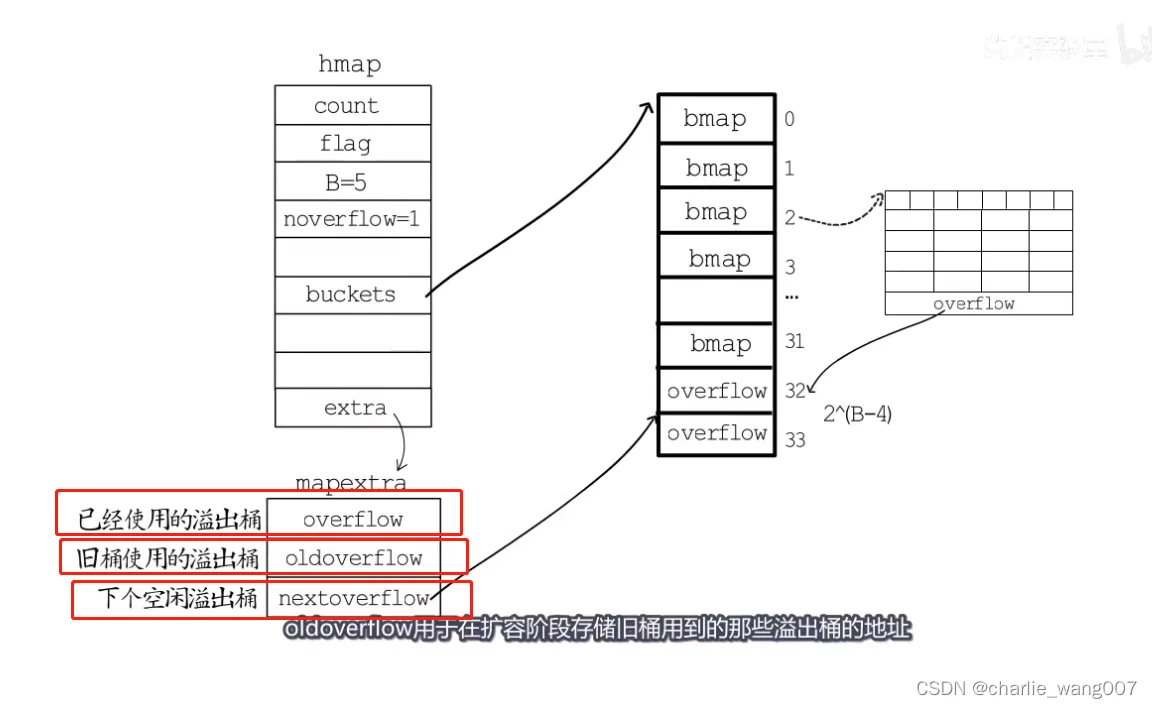
5 溢出桶的元数据在extra字段,
- overflow:已经使用的溢出桶;
- oldoverflow:旧桶的溢出桶,是一个数组
- nextoverflow:下一个溢出桶的地址
6.使用一个溢出桶,此时已使用的溢出桶数量noverflow+1,这个溢出桶的地址append到extre字段的overflow,
四 扩容
扩容方式-渐进式扩容
Go采用逐步搬迁策略:即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
1)扩容条件: 负载因子
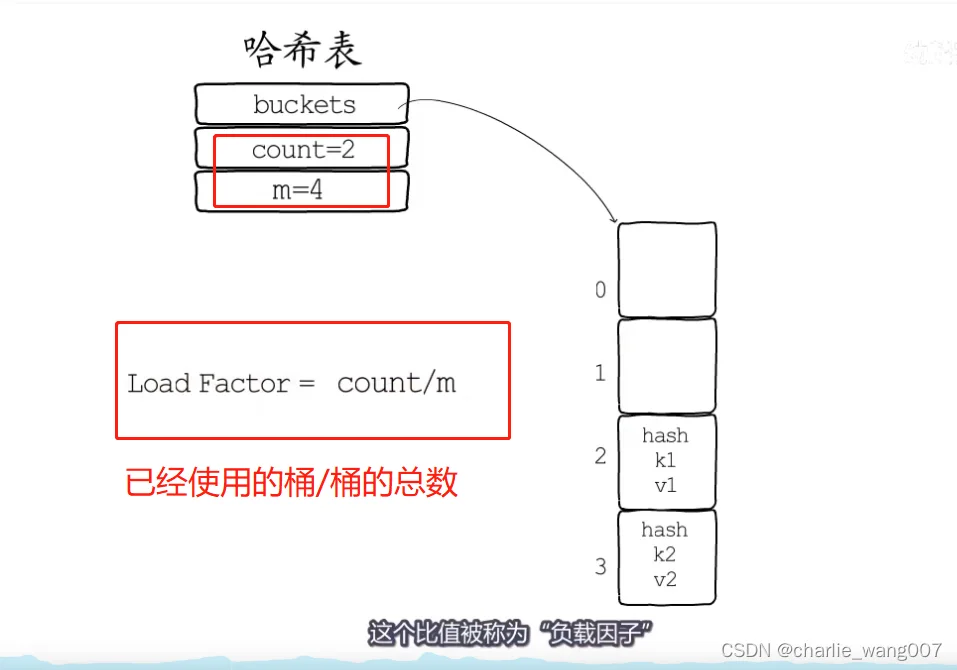
注意实际桶的数量是2的m次方个
2)扩容步骤:
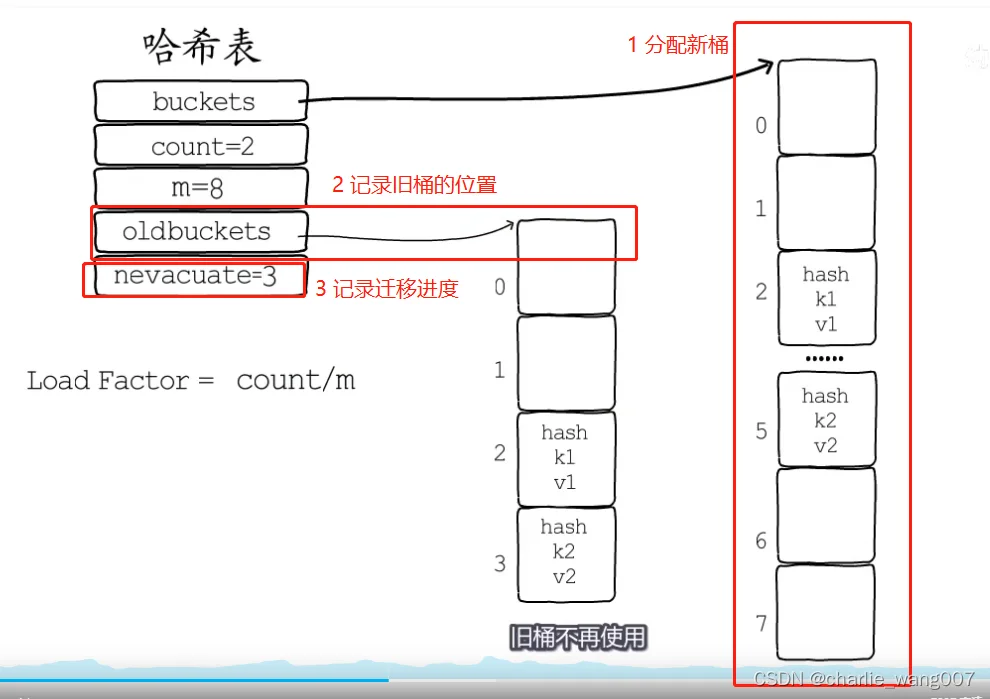
扩容有关字段:
Oldbuckets-旧桶位置
Nevacuate-迁移进度

渐进式扩容,避免了一次性扩容引起的性能抖动
扩容规则
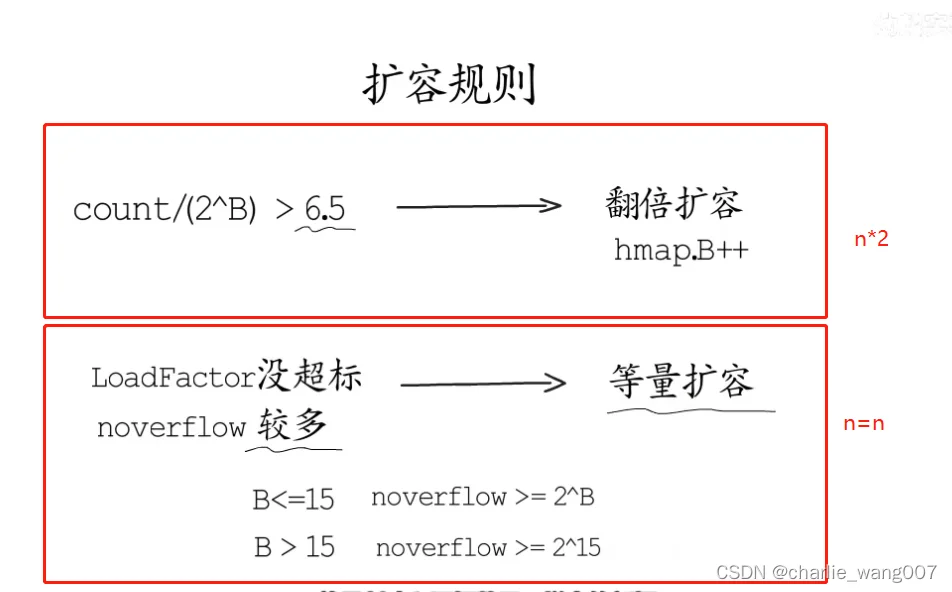
1)翻倍扩容
条件: 负载因子count/(2^B)>6.5
规则:翻倍
eg:
步骤:
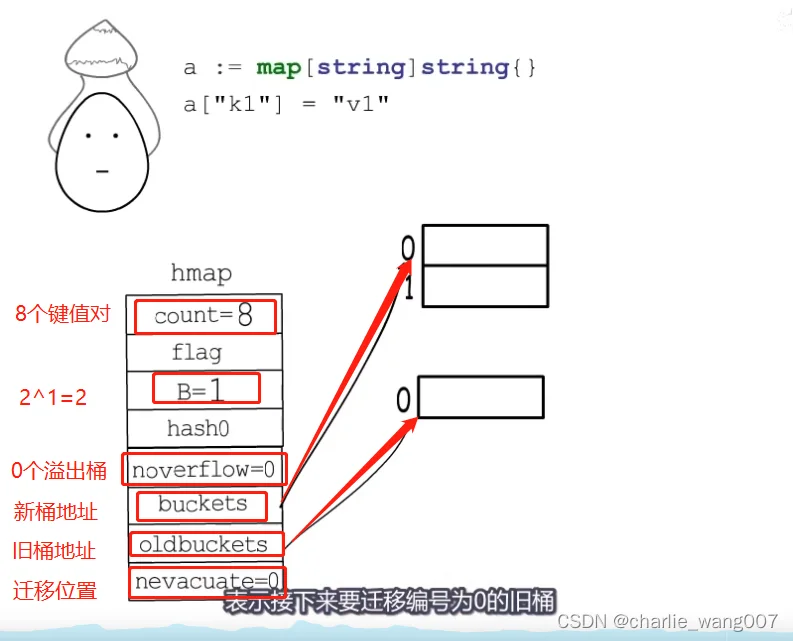
1 分配2倍的新桶,渐进式的扩容
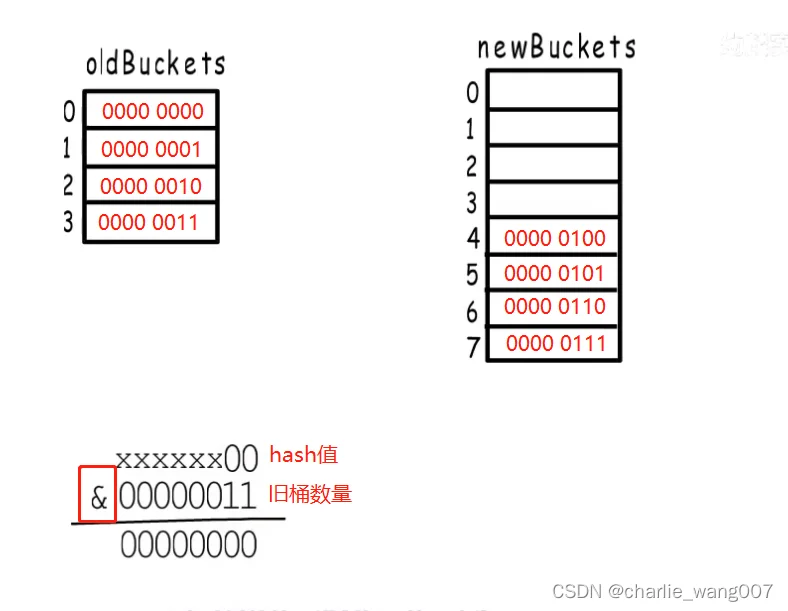
2 桶位置选择:hash值与桶数量与运算

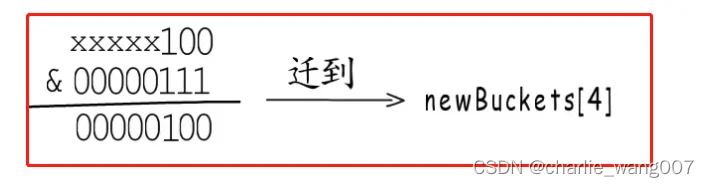
2)等量扩容
条件:负载因子没有超标,但使用的溢出桶较多
- 常规桶不到 2 15 2^{15} 215,但溢出桶超过 2 15 2^{15} 215
- 常规桶超过 2 15 2^{15} 215,但溢出桶一旦超过 2 15 2^{15} 215
等量扩容,扩容后和扩容前桶数量一样多,那为什么叫扩容呢?
其实是当我们在使用map的时候,大量的删除key,导致桶中的空闲地址比较多,造成资源浪费
等量扩容,实际是借助扩容时重新选择存储位置,而将键值存储的更紧密,避免内存浪费,实际是较少内存碎片的过程
五 查找key
1)go的hash函数
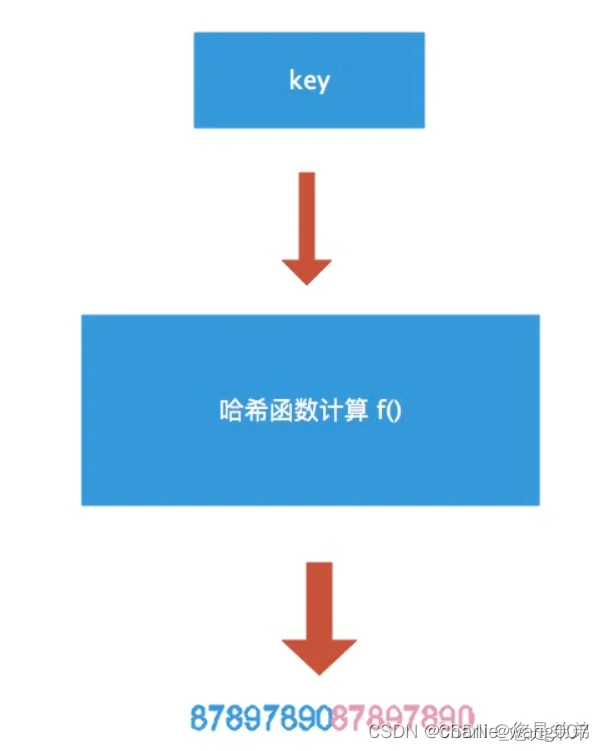
2)tophash的作用

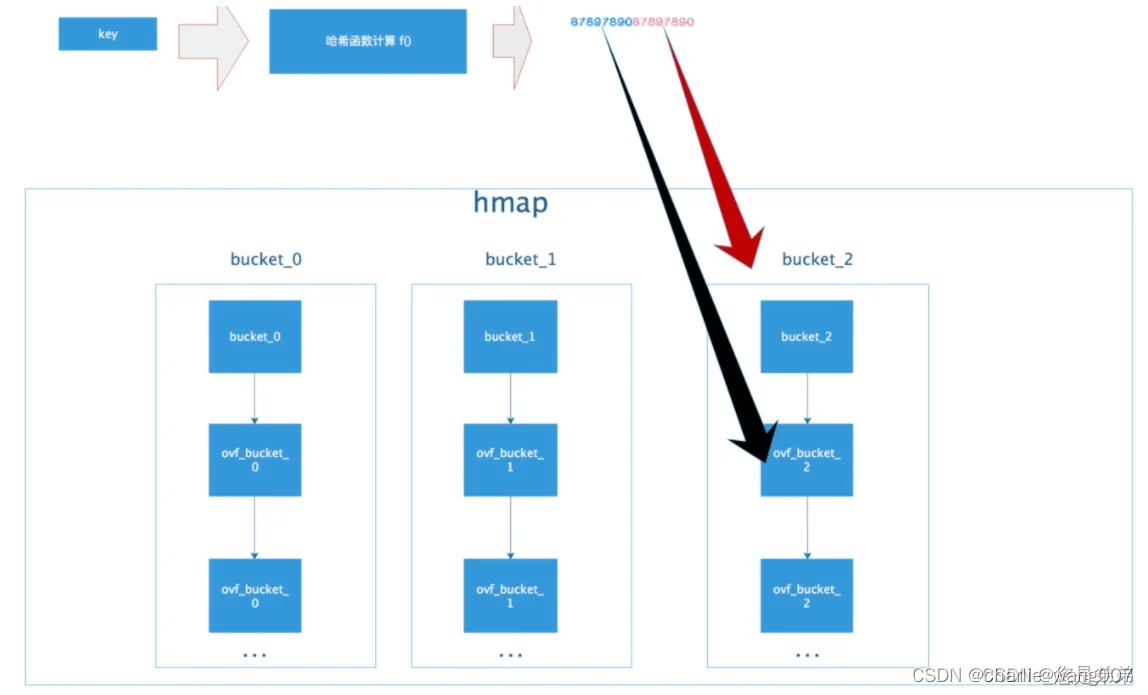
总结:
1 hmap管理着桶,包括桶的扩容以及溢出桶
2 bmap管理着键值对,数据类型上相当于链表,键与键存储在一起,值与值存储在一起,tophash相当于key的索引
3 与其他语言一样,在选择桶时使用取模和与运算,解决hash冲突采用开放地址和拉链法
4 go的扩容采用渐进式扩容,每次访问map时触发桶的迁移,这样减少了一次性扩容带来的性能抖动
5 翻倍扩容是桶数量的增加,等量扩容是内存碎片的整理
6 go的hash函数计算出的值有分出了高位tophash和低位,低位用来定位桶,高位用来定位key
经过一段时间的基础知识的吸收,再回过头来发现自己以前了解的不够精确不够深入,再次整理,方便以后巩固