
spider/craw 爬取
golang 爬虫框架
- net/http
- Colly
- Goquery
import (
"fmt"
"io/ioutil"
"net/http"
)
func fech(url string) string{
client := &http.Client{}
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", "Mozilla........")
req.Header.Add("Cookie", "_gads=..........")
I
resp, err := client.Do(req)
if err != nil {
fmt.Println("Http get err:", err)
return ""
}
if resp.StatusCode != 200 {
fmt.Println("Http status code:", resp.StatusCode)
return ""
}
defer resp.Body.Close()
body, err := ioutifl.ReadAll (resp. Body)
if err != nil {
fmt.Println("Read error", err)
return ""
}
return string(body)
func parse(ntml string) {
html = strings.Replace(html, "\n", "", -1)
re_sidebar := regexp.MustCompile(``<aside id="sidebar" role="navigation">(.*?)</aside>`)
//
sidebar := re_sidebar.FindString(html)
//
re_link := regexp.MustCompile(`href="(.*?)">`)
// TRENT A ERE
link := re_link.FindAllString(sidebar, -1)
base_url := "https://gorm.io/zh_CN/docs/"
for _, v := range links {
s := v[6 : len(v)-1]
url := base_url +s
fmt.Printf("url: %v\n", url)
body := fetch(url)
go parse2(body)
}
}
func parse2(body string) {
body = strings.Replace(body, "\n", "", -1)
re_content := regexp.MustCompile(`<div class="article">(.*?)</div>`)
content := re_content.FindString(body)
// fmt.Printf("content: %v\n", content)
re_title := regexp.MustCompile(`<h1 class="article-title" itemprop="name">(.*?)</h1>`)
title := re_title.FindString(content)
fint.Printf("title: %v\n", title)
title = title[42 : len(title)-5]
fint.Printf("title: %v\n", title)
}
func main() {
url := "https://gorm.io/zh_CN/docs/"
fetch(url)
}
// "io/ioutil"
func save(title string, content string) {
err := os.WriteFile("./"+title+".html", []byte(content), 0644)
if err != nil {
panic(err)
}
}
xorm框架
go mod init learn_craw
go get xorm.io/xorm
go get github.com/go-sql-driver/mysql
var engine *xorm.Engine
var err error
func init() { // init 代码会自动执行
engine, err = xorm.NewEngine("mysql", "root:123456@/test_xorm?charset=utf8")
if err != nil {
fmt.Printf("err: %v\n", err)
} else {
err2 := engine.Ping()
if err2 != nil {
fmt.Print®("err2: %v\n", err2)
} else {
print("连接成功")
}
}
}
type GormPage struct {
Id int64
Title string
Content string `xorm:"text"`
Created time.Time `xorm:"created"`
Updated time.Time `xorm:"updated"`
}
func savetoDB(title string, content string) {
engine.Sync(new(GormPage) )
page := GormPage{
Title: title,
Content: content,
}
affected, err := engine.Insert(&page)
if err != nil {
fmt.Printf("err: %v\n", err)
}
fmt .Println("save:" + string(affected))
}
// mysql
mysql -uroot -p
use test_xorm;
show tables
drop table gorm_page;
select * from gorm_page;
快速分析页面并且提取内容
colly也是基于goquery
go get -u github.com/PuerkitoBio/goquery
// pkgm tys
package main
import (
“fmt”
"log"
"github. com/PuerkitoBio/goquery"
)
func main() {
url := "https://gorm.io/zh_CN/docs/"
dom, err := goquery.NewDocument(url)
if err != nil {
log.Fatalln(err)
}
dom.Find(".sidebar-link").Each(func(i int, s *goquery.Selection) {
href, _ := s.Attr("href")
text := s.Text()
fmt.Println(i, href, text)
})
}
// 重用api
NewDocument(url)
NewDocumentFromResponse(resp)
func getDoc2() {
client := &http.Client{}
url := "https://gorm.io/zh_CN/docs/"
req, _ := http.NewRequest("GET", url, nil)
resp, err := client.Do(req)
dom, err := goquery.NewDocumentFromResponse(resp)
if err != nil {
log.Fatalln(err)
}
dom.Find("")
}
newDocumentFrom Reader
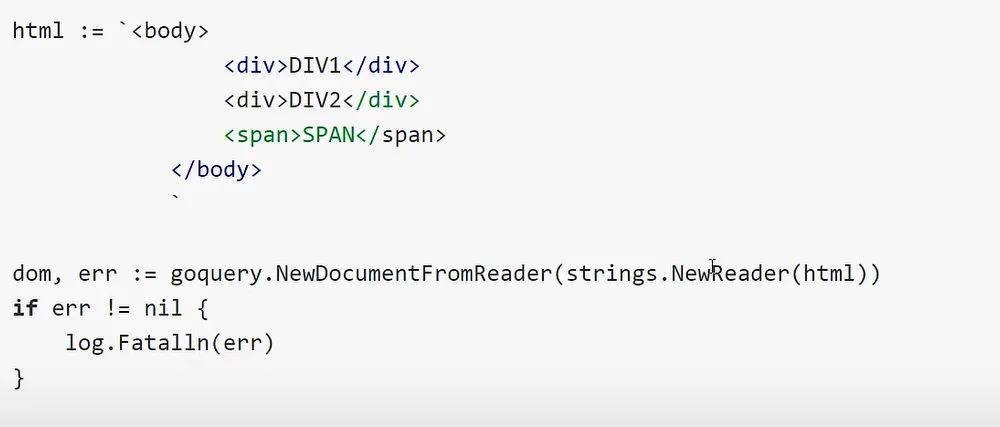
标签选择器

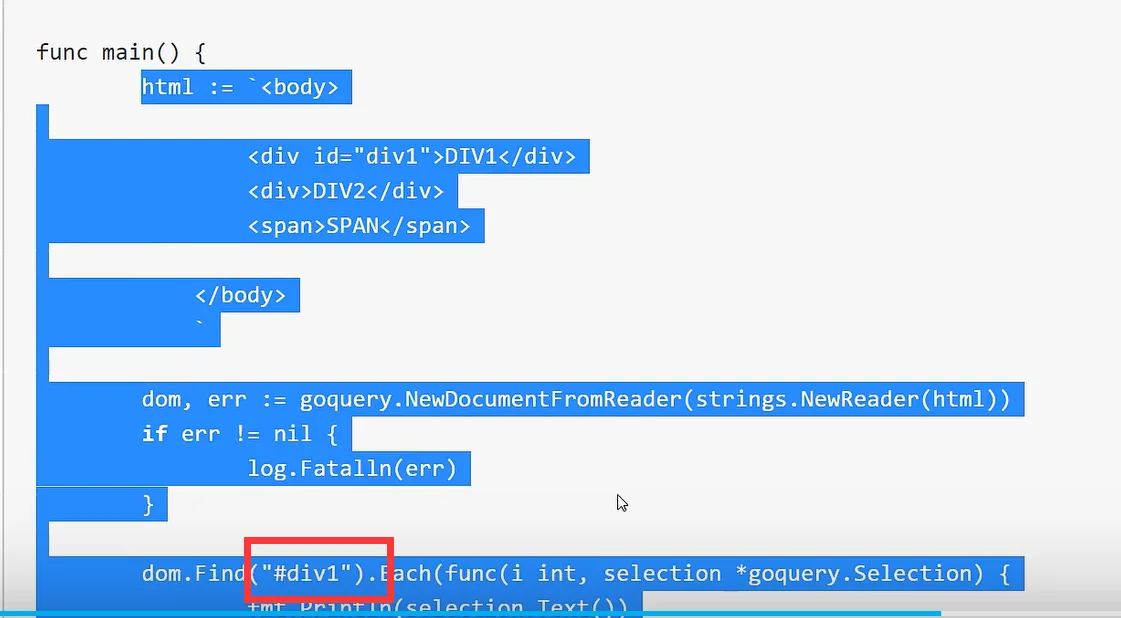
id选择器
class 选择器
.className
package main
import (
"fmt"
"log"
"github.com/PuerkitoBio/goquery"
)
func main() {
url := "https://gorm.io/zh_CN/docs/"
d, err := goquery.NewDocument(url)
if err != nil {
log.Fatalln(err)
}
d.Find(".sidebar-link").Each(func(i int, s *goquery.Selection) {
link, _ := s.Attr("href")
base_url := "https://gorm.io/zh_CN/docs/"
detail_url := base_url + link
fmt.Printf("detail_url: %v\n", detail_url)
d, _ = goquery.NewDocument(detail_url)
title := d.Find(".article-title").Text()
content, _ := d.Find(".article").Html()
fmt.Printf("title: %v\n", title)
fmt.Printf("content: %v\n", content[0:23])
})
}
go get -u github.com/gocolly/colly
package main
import "github.com/gocolly/colly"
func main() {
c := colly.NewCollector()
// goquery selector class
c.OnHTML(".sidebar-link", func(e *colly.HTMLElement) {
e.Request.Visit(e.attr("href"))] I
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("url", r.URL)
})
// 注意顺序,先设置回调再调用这里
c.Visit("https://gorm.io/zh_CN/docs/")
}
func main() {
c := colly.NewCollector()
c.OnRequest(func(r *colly.Request) {
fmt. Print1n("before request:onRequest")
})
c.OnError(func(_ *colly.Response, err error) {
fmt. Printin ("ON error:OnError")
})
c.OnResponse(func(r *colly.Response) {
fmt .Print1n ("on response:OnResponse")
})
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
| fmt. Printin("after get PAGE:ONHTML" )
})
c.OnXML("//h1", func(e *colly.XMLElement) {
fmt. Print1n("OnResponse for XML:OnXML")
})
c.OnScraped(func(r *colly.Response) {
fmt.Println("结束", r.Request.URL)
})
c.Visit("https://gorm.io/zh_CN/docs/")
}