
按照规矩,这里应该介绍一下golang和分库表,懒得写,跳过。
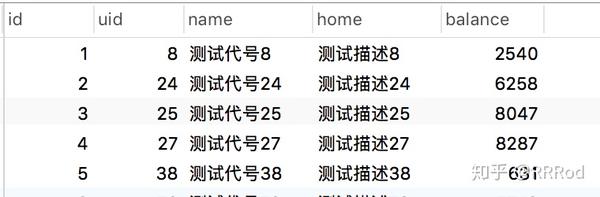
本文主要介绍两种分表方式,hash和range,对应不同对业务特性,假设有这样一个user表,字段id,name,home,balance:
数量大概1000w条:
一个查询大概耗时是这样的:


加索引肯定快多了,但是今天咱们讨论的主题不是索引,而是分表,就不给加索引了。
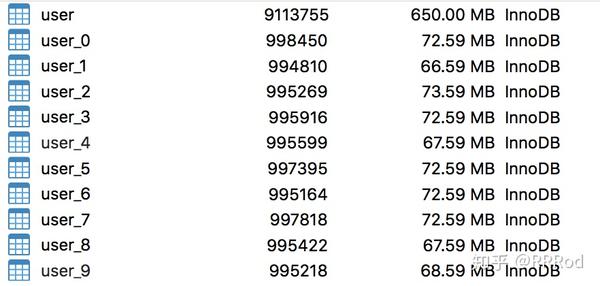
接下来是分表了,先假定业务逻辑是用户用昵称登陆,获取用户信息,那么就要用到hash分表了,先创建10张表,名字用user0-user9,结构一样,多一行uid:
然后填充数据,代码如下:
具体逻辑是先取出数据,然后对name字段进行hash--crc32运算,得到结果对10求余,然后插入到对应对表中,循环插入比较费时间,可另起方法存10w条插一次,再多估计不能插入,生成测试数据时候100w插入一次都不行,'max_allow_package'调到8g都插不进去,只好10w一次搞100次。看结果:
接下来就是愉快的测试时间了,开始pk,先上代码:
喜闻乐见的结果:




大概有9倍左右的性能提升,还是不错的,当然hash运算也是要耗时的,这里没统计。
接下来是range分表,上代码:
简单易懂,id/1000000得到表名,存入之,可另起逻辑一次插很多。
进入性能pk环节:
第一发:精确查找
结果:


分表完胜,但是分表要对结果进行循环组装,所幸开销不大。
第二发:范围查找
结果pk:


对你没有看错,不分表全胜,具体原理我还要再查查,可能和int这个数据类型有关。
第三发:id索引下查询:
结果:


分表微弱优势取胜。
第四发:未分表查询,分表协程查询,分表循环查询性能对比


总结如下:
- mysql对分表策略一定要和业务逻辑紧密结合,本文所用例子,如果用户登陆使用id,则以range分,使用name,则用hash分,某订单表日增量感人,则用date分。
- 分表后性能,也会根据业务逻辑是否合适而提升或者降低,如在range分表中进行name查询,性能会很差,但是使用id查询,性能有明显提升,随着数据量继续增大,优势会逐步扩大。
- 在数据库规模较大情况下,分表并发查询效率高于循环串行查询,考虑到单服务器创建连接开销,通信,处理能力及io效率,如应用于分布式服务器集群,并发查询的效率优势会更巨大。
- hash分表对于有排序需求对业务逻辑不太合适,即使可取出数据,大量计算也会造成很大开销。
- 数据库架构设计要根据业务量,确保安全,循序渐进,大概是 数据结构->查询语句->索引->分表->分库->主从->分布式。
- 对于分库分表后对数据库,业务逻辑会发生较大变化,建议根据分库表策略,编写中间件,以实现业务层和数据层的解藕。
- 不足之处,请多赐教,有需要测试代码和数据库文件的,待我上传后放出连接。