golang对excel的下载和读取,批量插入、go并发处理
1.下载Excel文档并读取
由于我的excel文档在阿里云里,所以需要先用链接把excel下载到本地来,代码如下
func Download(url, excelName string) {
res, err := http.Get(url) //下载excel
if err != nil {
return
}
defer res.Body.Close()
fileName := fmt.Sprintf("%v.%s", time.Now().Format("2006-01-02_15:04:05"), excelName)
path := fmt.Sprintf("temp/%s", fileName)
localFile, err := os.Create(path) //在相对路径./temp下创建一个空excel文档
if err != nil {
return
}
_, err = io.Copy(localFile, res.Body) //把body里的内容复制到本地excel文件
if err != nil {
return
}
}
//读取excel的函数
func CsvReadAll(csvFileName string) ([]string, [][]string, error) {
csvFile, err := os.Open(csvFileName)
if err != nil {
return nil, nil, err
}
defer csvFile.Close()
hdr := make([]string, 0)
lines := make([][]string, 0)
reader := csv.NewReader(csvFile)
for {
record, err := reader.Read()
if err == io.EOF {
break
} else if err != nil {
return nil, nil, err
}
if len(hdr) == 0 {
hdr = record
} else {
lines = append(lines, record)
}
}
return hdr, lines, nil
}
2.批量插入
每次批量插入100条数据到数据库
func InsertBatch(temp [][]string, length int) error {
db := modelUtils.GetDB() //gorm库
sqlStr := "INSERT INTO other_sn_mac(a, b, c) VALUES"
for i := 0; i < length; i++ { // 批量插入
if i == 0 {
sqlStr += fmt.Sprintf("('%s', '%s', '%s')", temp[i][0], temp[i][1], temp[i][2])
} else {
sqlStr += fmt.Sprintf(",('%s', '%s', '%s')", temp[i][0], temp[i][1], temp[i][2])
}
}
if err := db.Exec(sqlStr).Error; err != nil {
return err
}
return nil
}
3.并发调用
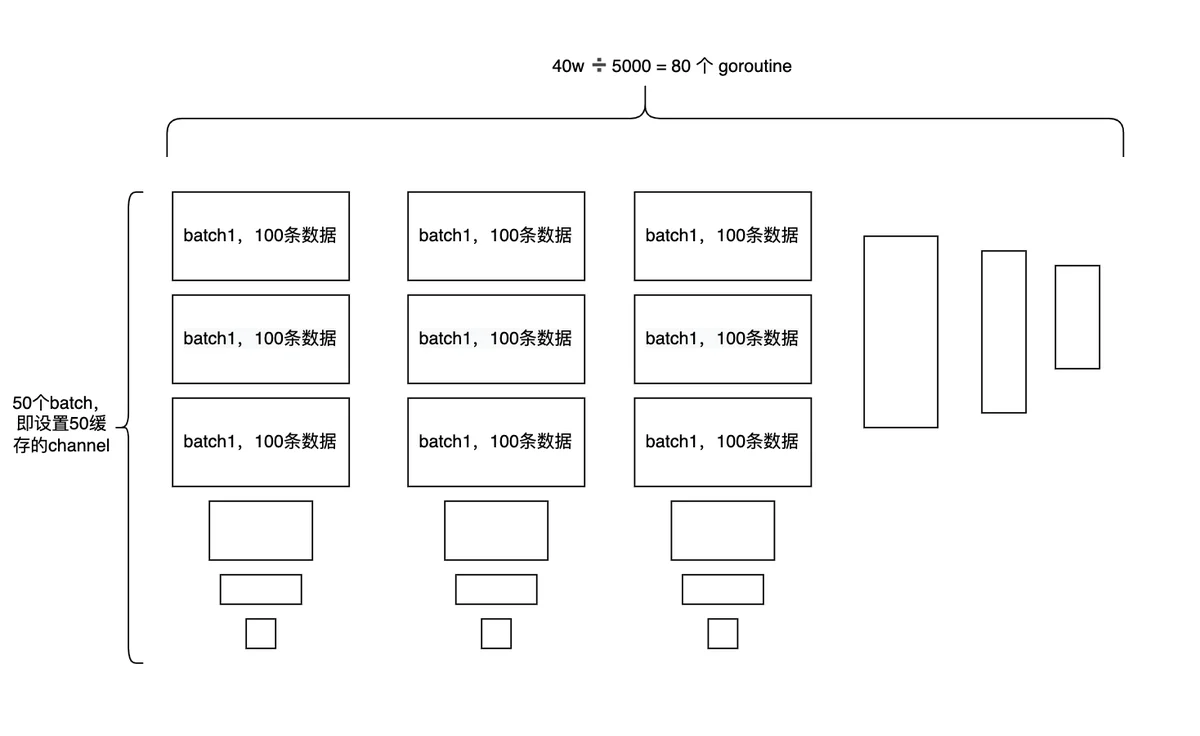
每100个批量插入就放进channel中成为一个缓存,channel的缓存大小为50,每50个channel开启一个goroutine去并发执行,所以没5000条数据就开启一个goroutine并发执行
func ExcelBatchProcess(path string) {
_, data, err := csvUtils.CsvReadAll(path) //从excel读数据,data里存放的就是excel里除去顶部标题的数据
if err != nil {
return
}
tempData := make(map[int][][]string, 50)
go func() {
for j := 0; j < getModSecond; j++ {
s <- tempData[j]
}
close(s)
}()
GoConcurrency(s)
}
func GoConcurrency(s chan [][]string) {
wg.Add(1)
go func() {
defer wg.Done()
for {
z, ok := <-s
if !ok {
break
}
err := model.InsertBatch(z, 100)
if err != nil {
log.Println("db insert err: ", err)
return
}
}
}()
wg.Wait()
}
代码里我省去了业务逻辑代码,也省去了边角数据的处理逻辑
最终结果:
大概有40多万条数据,每5000条数据一个goroutine,那么大概需要80多个goroutine,总共花费的时间大概是1分钟,因为阿里云服务器为2核4G的性能,所以主要的性能瓶颈在于服务器上的数据库,虽然开启的数据库池,但是单条数据的插入时间是固定的
我还试了一下把同样40多万的数据插入到亚马逊云的数据库,要16分钟左右,因为服务器在国外,所以受网络影响较大