
字符串处理我们可以使用strings包来进行搜索(Contains、Index)、替换(Replace)和解析(Split、Join)等操作,但是这些都是简单的字符串操作,他们的搜索都是大小写敏感,而且固定的字符串,如果我们需要匹配可变的那种就没办法实现了,当然如果strings包能解决你的问题,那么就尽量使用它来解决。因为他们足够简单、而且性能和可读性都会比正则好。
1. 语法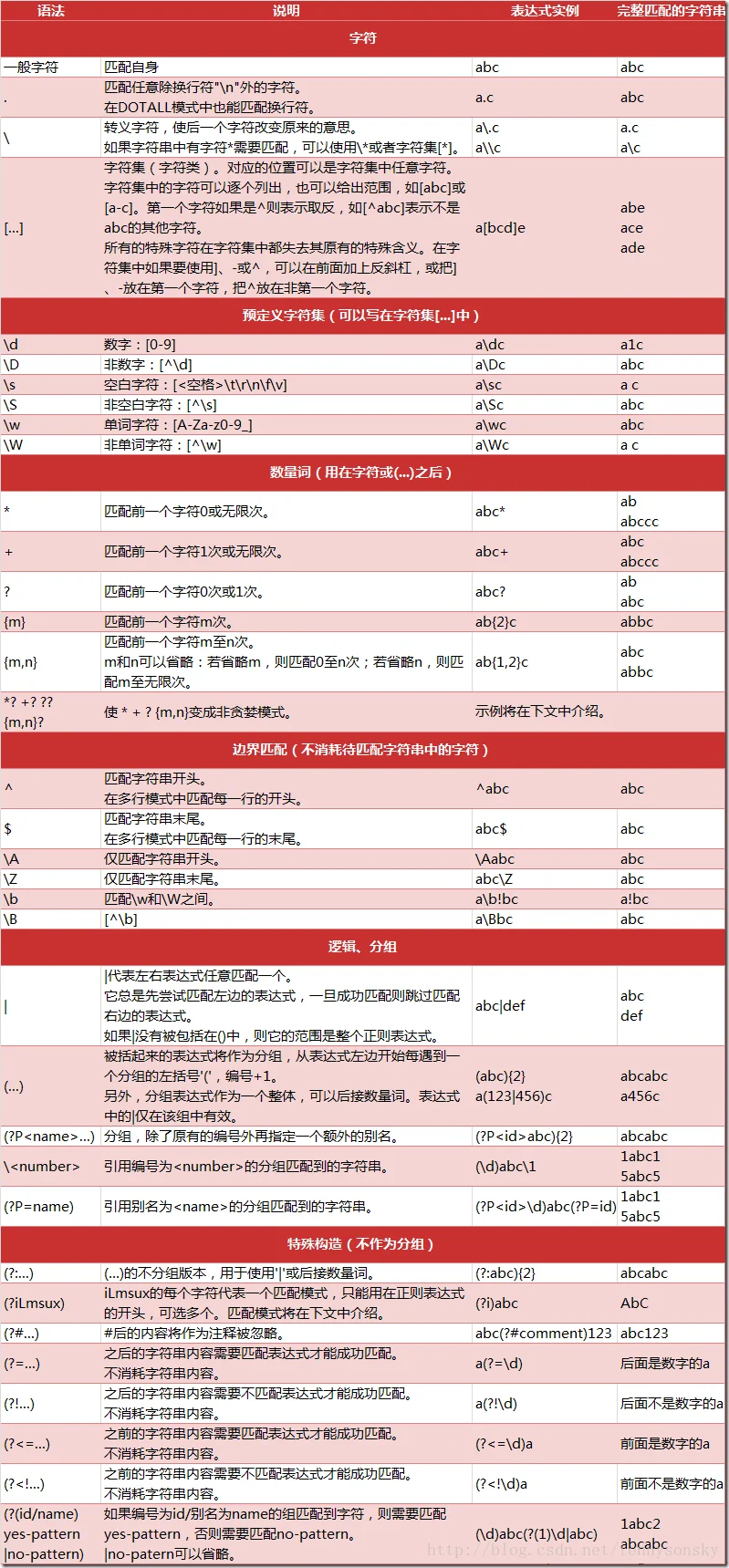
package main
import (
"fmt"
"regexp"
)
func main() {
context1 := "3.14 123123 .68 haha 1.0 abc 6.66 123."
//MustCompile解析并返回一个正则表达式。如果成功返回,该Regexp就可用于匹配文本。
//解析失败时会产生panic
// \d 匹配数字[0-9],d+ 重复>=1次匹配d,越多越好(优先重复匹配d)
exp1 := regexp.MustCompile(`\d+\.\d+`)
//返回保管正则表达式所有不重叠的匹配结果的[]string切片。如果没有匹配到,会返回nil。
//result1 := exp1.FindAllString(context1, -1) //[3.14 1.0 6.66]
result1 := exp1.FindAllStringSubmatch(context1, -1) //[[3.14] [1.0] [6.66]]
fmt.Printf("%v\n", result1)
for _, resu := range result1 {
fmt.Printf("%s\n", resu)
}
fmt.Printf("\n------------------------------------\n\n")
context2 := `
<title>标题</title>
<div>你过来啊</div>
<div>hello mike</div>
<div>你大爷</div>
<body>呵呵</body>
`
//(.*?)被括起来的表达式作为分组
//匹配<div>xxx</div>模式的所有子串
exp2 := regexp.MustCompile(`<div>(.*?)</div>`)
result2 := exp2.FindAllStringSubmatch(context2, -1)
//[[<div>你过来啊</div> 你过来啊] [<div>hello mike</div> hello mike] [<div>你大爷</div> 你大爷]]
fmt.Printf("%v\n", result2)
fmt.Printf("\n------------------------------------\n\n")
context3 := `
<title>标题</title>
<div>你过来啊</div>
<div>hello
mike
go</div>
<div>你大爷</div>
<body>呵呵</body>
`
exp3 := regexp.MustCompile(`<div>(.*?)</div>`)
result3 := exp3.FindAllStringSubmatch(context3, -1)
//[[<div>你过来啊</div> 你过来啊] [<div>你大爷</div> 你大爷]]
fmt.Printf("%v\n", result3)
fmt.Printf("\n------------------------------------\n\n")
context4 := `
<title>标题</title>
<div>你过来啊</div>
<div>hello
mike
go</div>
<div>你大爷</div>
<body>呵呵</body>
`
exp4 := regexp.MustCompile(`<div>(?s:(.*?))</div>`) //让 . 匹配 \n (默认为 false)
result4 := exp4.FindAllStringSubmatch(context4, -1)
/*
[[<div>你过来啊</div> 你过来啊] [<div>hello
mike
go</div> hello
mike
go] [<div>你大爷</div> 你大爷]]
*/
fmt.Printf("%v\n", result4)
fmt.Printf("\n------------------------------------\n\n")
for _, text := range result4 {
fmt.Println(text[0]) //带有div
fmt.Println(text[1]) //不带带有div
fmt.Println("================\n")
}
}