
其实不知道取这个标题表达的准不准确,有些文章会说是延迟绑定问题
闭包定义
闭包是由函数和与其相关的引用环境组合而成的实体 。
函数,指的是在闭包实际实现的时候,往往通过调用一个外部函数返回其内部函数来实现的。内部函数可能是内部实名函数、匿名函数或者一段lambda表达式。用户得到一个闭包,也等同于得到了这个内部函数,每次执行这个闭包就等同于执行内部函数。
环境,具体地说,在实际中引用环境是指外部函数的环境,闭包保存/记录了它产生时的外部函数的所有环境。
举例说明
func incr() func() int {
var x int
return func() int {
x++
return x
}
}
i := incr()println(i()) // 1
println(i()) // 2
println(i()) // 3
但是这段代码却不会递增:
println(incr()()) // 1
println(incr()()) // 1
println(incr()()) // 1
这是因为这里调用了三次 incr(),返回了三个闭包,这三个闭包引用着三个不同的 x,它们的状态是各自独立的。
循环体中闭包变量的延迟绑定问题
个人认为延迟绑定这个描述不太合适,因为其实是个解引用的过程
举例说明
func t1(x int) []func() {
var fs []func()
values := []int{1, 2, 3, 5}
for _, val := range values {
fmt.Printf("outer val = %d, addr = %v\n", x+val, &val)
fs = append(fs, func() {
//这里传入的实际上是val的引用
fmt.Printf("inner val = %d, addr = %v\n", x+val, &val)
})//这里只是声明,不会立刻执行,调用内部函数时才会真正执行
}
return fs
}
func main(){
funcs := t1(11)
fmt.Println("declare done")
for _, f := range funcs {
f()//这里才会执行
}
}
//out:
outer val = 12, addr = 0xc0000ac058
outer val = 13, addr = 0xc0000ac058
outer val = 14, addr = 0xc0000ac058
outer val = 16, addr = 0xc0000ac058
declare done
inner val = 16, addr = 0xc0000ac058
inner val = 16, addr = 0xc0000ac058
inner val = 16, addr = 0xc0000ac058
inner val = 16, addr = 0xc0000ac058
解释:闭包保存/记录了它产生时的外部函数的所有环境。如同普通变量/函数的定义和实际赋值/调用或者说执行,是两个阶段。闭包也是一样,for-loop内部仅仅是声明了一个闭包,t1()返回的也仅仅是一段闭包的函数定义,只有在外部执行了f()时才真正执行了闭包,在执行这个闭包的时候,会去其外部环境解引用,说这四个函数引用的都是同一个变量val的地址,所以之后val改变,解引用得到的值也会改变,所以这四个函数都会输出最后的最新的值。
插播一下: 在for range里面val的地址为什么始终没有改变,也就是始终是同一个变量,可以看一下这里的文章:Go语言设计与实现
ha := a //a是原切片
hv1 := 0
hn := len(ha)
v1 := hv1
v2 := nil
for ; hv1 < hn; hv1++ {
tmp := ha[hv1]
v1, v2 = hv1, tmp
...
}
简单来说就是,golang的for range机制相当于对for循环做了优化,会额外创建一个新的 v2 变量存储切片中的元素,循环中使用的这个变量 v2的值 会在每一次迭代被重新赋值而覆盖,赋值时也会触发拷贝,而其本身地址不会变,因为始终是同一变量;也就引出了另一个需要注意的for range用法中的指针问题:【获取 range 返回变量的地址并保存到另一个数组】
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
fmt.Printf("addr:%v\n", &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
//out:
addr:0xc0000a6010
addr:0xc0000a6010
addr:0xc0000a6010
3
3
3
//正确写法
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for i, _ := range arr {
newArr = append(newArr, &arr[i])
}
for _, v := range newArr {
fmt.Println(*v)
}
}
//out
1
2
3
再举个栗子加深一下印象
func t2() func() {
x := 1
f := func() {
fmt.Printf("t2 val = %d\n", x)
}
x = 11
fmt.Println("declare done")
return f//这里返回这个函数之后才会执行该内部函数
}
func main(){
t2()()//第二个括号代表执行返回的内部函数
}
//out
declare done
t2 val = 11
goroutine延迟绑定-在循环迭代器的变量上使用 goroutines
举例说明
func show3(v interface{}) {
fmt.Printf("t3 val = %v\n", v)
}
func t3() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go show3(val) //正常打印,等效于:
// go func(val interface{}) {
// fmt.Println(val)
// }(val)
//将 val 作为参数添加到闭包中,val在每次迭代时评估并放置在 goroutine 的堆栈中
}
fmt.Println("t3 declare done")
}
type myType int
func (v *myType) show4() {
fmt.Printf("t4 val = %v\n", *v)
}
func t4() {
values := []myType{1, 2, 3, 5}
for _, val := range values {
//解决方法:newVal := val
go val.show4() //t5原理相同,绑定的是同一个val,但值不确定,因为
//for循环是运行在主协程中的,负责改变val值,当前子协程运行时val为多少就输出多少,
//由于for循环很快就跑完了,而子协程可能还没被调度。所以一般会输出最后的val值
}
fmt.Println("t4 declare done")
}
func t5() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go func() {//这个匿名函数就是一个闭包
fmt.Printf("t5 val = %v\n", val)//和t4原理相同
}()//当程序执行到这里时,只是声明,还没被调度
//time.Sleep(time.Duration(1) * time.Millisecond)
//主协程如果能等等,这个子协程被调度执行后再继续就可以了,但肯定不能这么搞,太慢了
}
fmt.Println("t5 declare done")
}//val的生命周期在闭包内部被延长了
func main(){
t3()
t4()
t5()
//hold住,等待其他协程执行完
time.Sleep(time.Second)
}
输出结果
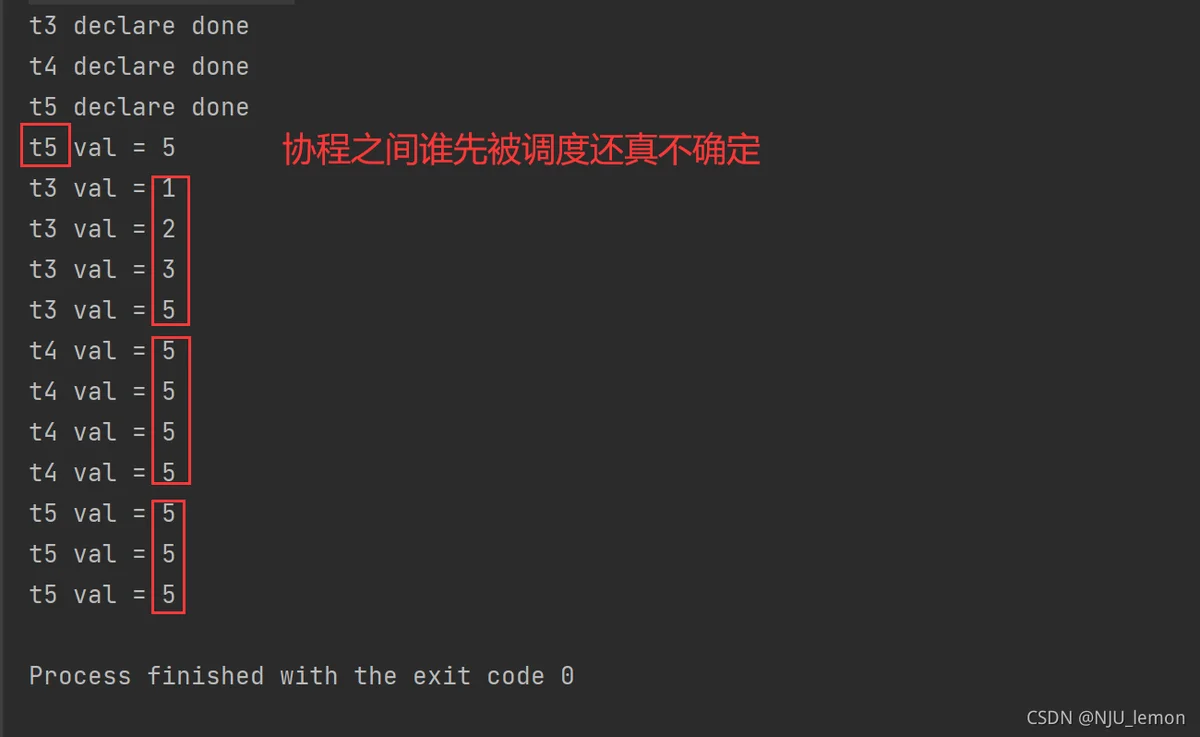
上面的t4和t5的注释写的很清楚,出现打印的全是最后一个值也就是5的情况是因为主协程【暂且这么叫,或者叫第一个协程,并协程之间是平等的,没有主次之分】和子协程是可以一起操作val这个变量的,但很明显主协程先被调度,for循环也跑得很快,以至于子协程还没被调度,for循环就已经跑完了,val的值已经变成了5…
良好实践
至于t3,就是一个良好的实践,再举一个栗子说明这种实践:将内部函数所用到的变量作为外部函数的入参传进去,这样相当于每轮循环中形成的闭包中的i都是不同的i
//修改前
func main(){
var funcSlice []func()
for i := 0; i < 3; i++ {
funcSlice = append(funcSlice, func() {
fmt.Printf("addr: %v,value %v \n", &i, i)
})
}
for j := 0; j < 3; j++ {
funcSlice[j]()
}
}
//out
addr: 0xc00000a088,value 3
addr: 0xc00000a088,value 3
addr: 0xc00000a088,value 3
//修改后
func main(){
var funcSlice []func()
for i := 0; i < 3; i++ {
func(i int) {
funcSlice = append(funcSlice, func() {
fmt.Printf("addr: %v,value %v \n", &i, i)
})
}(i)
}
for j := 0; j < 3; j++ {
funcSlice[j]() // 0, 1, 2
}
}
//out
addr: 0xc00000a088,value 0
addr: 0xc00000a0a0,value 1
addr: 0xc00000a0a8,value 2
或者像t4的注释中写的那种解决方法,每轮循环都新建一个变量传进去
我再举个栗子
func main(){
for i := 0; i < 10; i++ {
go func() {
fmt.Println(i)
}()
}
time.Sleep(time.Second)//hold住主协程【第一个协程】,等待剩下的协程执行完
}
输出:下面的2就是启动的比较快的一个子协程 ,此时主协程的for循环i才跑到2;
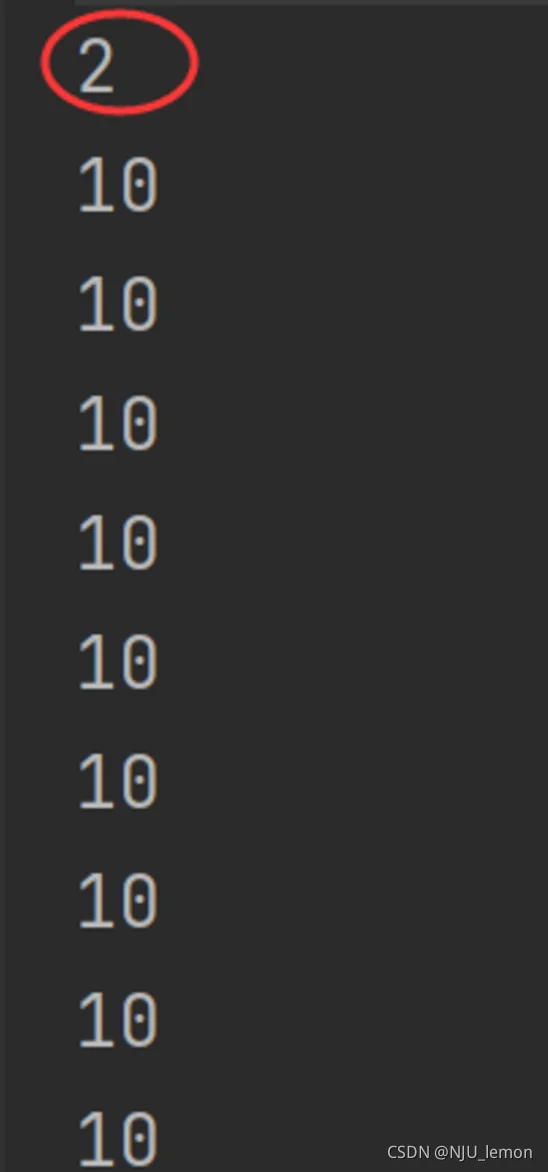
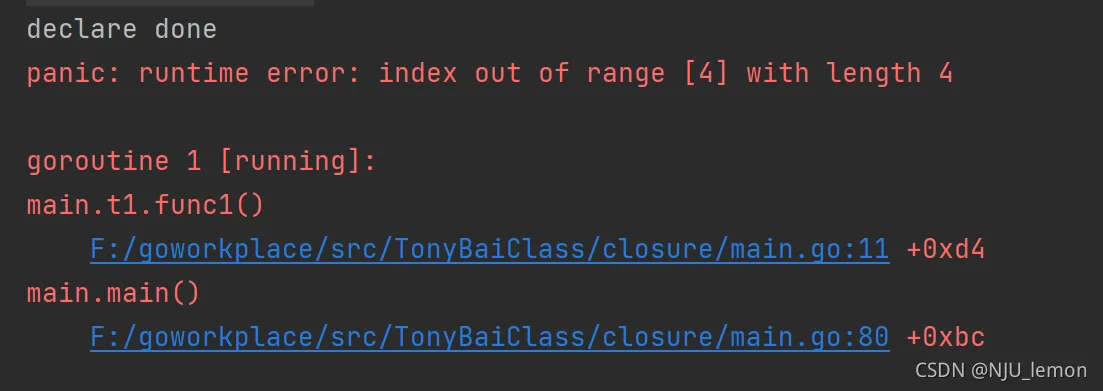
另外值得注意的是,此时i的最新值为10而不是9,也就是说,注意! 上面的t1如果改成这样遍历切片会报错:
func t1(x int) []func() {
var fs []func()
values := []int{1, 2, 3, 5}
for i := 0; i < len(values); i++{
fs = append(fs, func() {
fmt.Printf("val = %d\n", x+values[i])
})
}
return fs
}
func main(){
funcs := t1(11)
fmt.Println("declare done")
for _, f := range funcs {
f()//这里才会执行
}
}
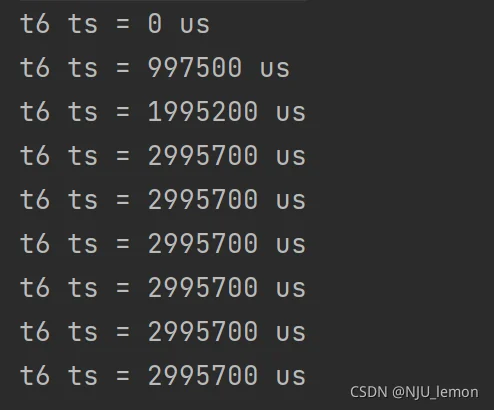
测试一下go func从声明到被调度执行需要的时间
func t6() {
for i := 1; i < 10; i++ {
curTime := time.Now().UnixNano()
go func(t1 int64) {
t2 := time.Now().UnixNano()
fmt.Printf("t6 ts = %d us \n", t2-t1)
}(curTime)
}
}
func main() {
go t6()
}
我电脑好像有点拉垮了
再插播一下
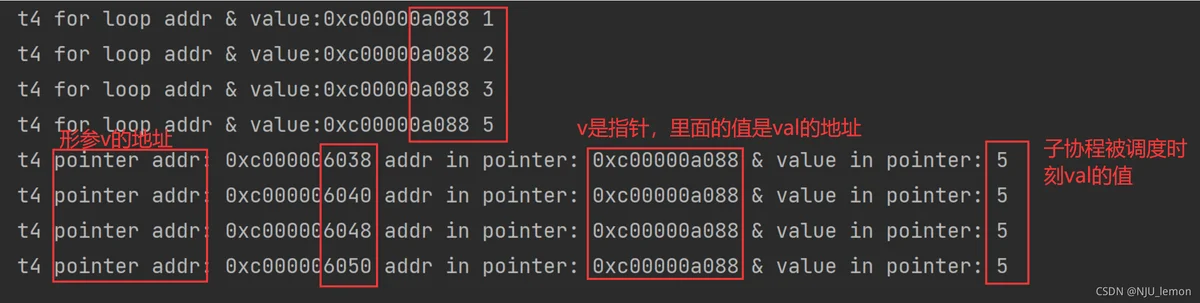
在测试t4的时候顺便看了下地址,复习了一下指针
func (v *myType) show4() {
fmt.Printf("t4 pointer addr: %v addr in pointer: %v & value in pointer: %v \n", &v,v,*v)
}
func t4() {
values := []myType{1, 2, 3, 5}
for _, val := range values {
fmt.Printf("t4 for loop addr & value:%v %v\n", &val, val)
go val.show4()
}
}
参考文章:
https://zhuanlan.zhihu.com/p/92634505
https://segmentfault.com/a/1190000022798222