
18 质量保证:Go 语言如何通过测试保证质量?
从这节课开始,我会带你学习本专栏的第四模块:工程管理。现在项目的开发都不是一个人可以完成的,需要多人进行协作,那么在多人协作中如何保证代码的质量,你写的代码如何被其他人使用,如何优化代码的性能等, 就是第四模块的内容。
这一讲首先来学习 Go 语言的单元测试和基准测试。
单元测试
在开发完一个功能后,你可能会直接把代码合并到代码库,用于上线或供其他人使用。但这样是不对的,因为你还没有对所写的代码进行测试。没有经过测试的代码逻辑可能会存在问题:如果强行合并到代码库,可能影响其他人的开发;如果强行上线,可能导致线上 Bug、影响用户使用。
什么是单元测试
顾名思义,单元测试强调的是对单元进行测试。在开发中,一个单元可以是一个函数、一个模块等。一般情况下,你要测试的单元应该是一个完整的最小单元,比如 Go 语言的函数。这样的话,当每个最小单元都被验证通过,那么整个模块、甚至整个程序就都可以被验证通过。
单元测试由开发者自己编写,也就是谁改动了代码,谁就要编写相应的单元测试代码以验证本次改动的正确性。
Go 语言的单元测试
虽然每种编程语言里单元测试的概念是一样的,但它们对单元测试的设计不一样。Go 语言也有自己的单元测试规范,下面我会通过一个完整的示例为你讲解,这个例子就是经典的斐波那契数列。
斐波那契数列是一个经典的黄金分隔数列:它的第 0 项是 0;第 1 项是 1;从第 2 项开始,每一项都等于前两项之和。所以它的数列是:0、1、1、2、3、5、8、13、21……
说明:为了便于总结后面的函数方程式,我这里特意写的从第 0 项开始,其实现实中没有第 0 项。
根据以上规律,可以总结出它的函数方程式。
-
F(0)=0
-
F(1)=1
-
F(n)=F(n - 1)+F(n - 2)
有了函数方程式,再编写一个 Go 语言函数来计算斐波那契数列就比较简单了,代码如下:
ch18/main.go
func Fibonacci(n int) int {
if n < 0 {
return 0
}
if n == 0 {
return 0
}
if n == 1 {
return 1
}
return Fibonacci(n-1) + Fibonacci(n-2)
}
也就是通过递归的方式实现了斐波那契数列的计算。
Fibonacci 函数已经编写好了,可以供其他开发者使用,不过在使用之前,需要先对它进行单元测试。你需要新建一个 go 文件用于存放单元测试代码。刚刚编写的 Fibonacci 函数在ch18/main.go文件中,那么对 Fibonacci 函数进行单元测试的代码需要放在ch18/main_test.go中*,*测试代码如下:
ch18/main_test.go
func TestFibonacci(t *testing.T) {
//预先定义的一组斐波那契数列作为测试用例
fsMap := map[int]int{}
fsMap[0] = 0
fsMap[1] = 1
fsMap[2] = 1
fsMap[3] = 2
fsMap[4] = 3
fsMap[5] = 5
fsMap[6] = 8
fsMap[7] = 13
fsMap[8] = 21
fsMap[9] = 34
for k, v := range fsMap {
fib := Fibonacci(k)
if v == fib {
t.Logf("结果正确:n为%d,值为%d", k, fib)
} else {
t.Errorf("结果错误:期望%d,但是计算的值是%d", v, fib)
}
}
}
在这个单元测试中,我通过 map 预定义了一组测试用例,然后通过 Fibonacci 函数计算结果。同预定义的结果进行比较,如果相等,则说明 Fibonacci 函数计算正确,不相等则说明计算错误。
然后即可运行如下命令,进行单元测试:
➜ go test -v ./ch18
这行命令会运行 ch18 目录下的所有单元测试,因为我只写了一个单元测试,所以可以看到结果如下所示:
➜ go test -v ./ch18
=== RUN TestFibonacci
main_test.go:21: 结果正确:n为0,值为0
main_test.go:21: 结果正确:n为1,值为1
main_test.go:21: 结果正确:n为6,值为8
main_test.go:21: 结果正确:n为8,值为21
main_test.go:21: 结果正确:n为9,值为34
main_test.go:21: 结果正确:n为2,值为1
main_test.go:21: 结果正确:n为3,值为2
main_test.go:21: 结果正确:n为4,值为3
main_test.go:21: 结果正确:n为5,值为5
main_test.go:21: 结果正确:n为7,值为13
--- PASS: TestFibonacci (0.00s)
PASS
ok gotour/ch18 (cached)
在打印的测试结果中,你可以看到 PASS 标记,说明单元测试通过,而且还可以看到我在单元测试中写的日志。
这就是一个完整的 Go 语言单元测试用例,它是在 Go 语言提供的测试框架下完成的。Go 语言测试框架可以让我们很容易地进行单元测试,但是需要遵循五点规则。
-
含有单元测试代码的 go 文件必须以 _test.go 结尾,Go 语言测试工具只认符合这个规则的文件。
-
单元测试文件名 _test.go 前面的部分最好是被测试的函数所在的 go 文件的文件名,比如以上示例中单元测试文件叫 main_test.go,因为测试的 Fibonacci 函数在 main.go 文件里。
-
单元测试的函数名必须以 Test 开头,是可导出的、公开的函数。
-
测试函数的签名必须接收一个指向 testing.T 类型的指针,并且不能返回任何值。
-
函数名最好是 Test + 要测试的函数名,比如例子中是 TestFibonacci,表示测试的是 Fibonacci 这个函数。
遵循以上规则,你就可以很容易地编写单元测试了。单元测试的重点在于熟悉业务代码的逻辑、场景等,以便尽可能地全面测试,保障代码质量。

单元测试覆盖率
以上示例中的 Fibonacci 函数是否被全面地测试了呢?这就需要用单元测试覆盖率进行检测了。
Go 语言提供了非常方便的命令来查看单元测试覆盖率。还是以 Fibonacci 函数的单元测试为例,通过一行命令即可查看它的单元测试覆盖率。
➜ go test -v --coverprofile=ch18.cover ./ch18
这行命令包括 --coverprofile 这个 Flag,它可以得到一个单元测试覆盖率文件,运行这行命令还可以同时看到测试覆盖率。Fibonacci 函数的测试覆盖率如下:
PASS
coverage: 85.7% of statements
ok gotour/ch18 0.367s coverage: 85.7% of statements
可以看到,测试覆盖率为 85.7%。从这个数字来看,Fibonacci 函数应该没有被全面地测试,这时候就需要查看详细的单元测试覆盖率报告了。
运行如下命令,可以得到一个 HTML 格式的单元测试覆盖率报告:
➜ go tool cover -html=ch18.cover -o=ch18.html
命令运行后,会在当前目录下生成一个 ch18.html 文件,使用浏览器打开它,可以看到图中的内容:
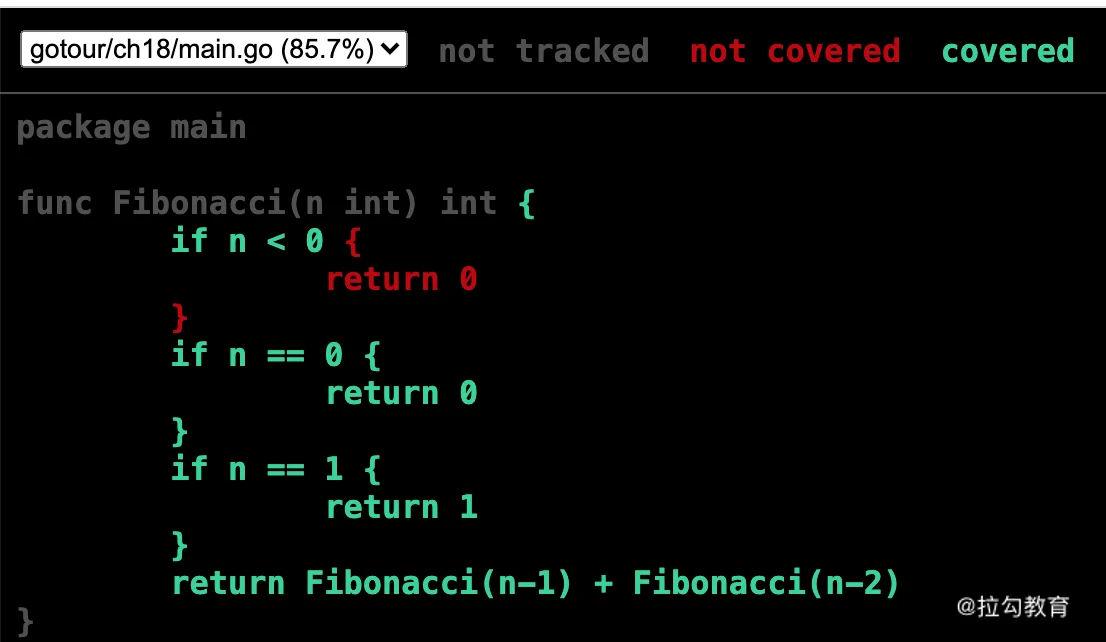
红色标记的部分是没有测试到的,绿色标记的部分是已经测试到的。这就是单元测试覆盖率报告的好处,通过它你可以很容易地检测自己写的单元测试是否完全覆盖。
根据报告,我再修改一下单元测试,把没有覆盖的代码逻辑覆盖到,代码如下:
fsMap[-1] = 0
也就是说,由于图中 n<0 的部分显示为红色,表示没有测试到,所以我们需要再添加一组测试用例,用于测试 n<0 的情况。现在再运行这个单元测试,查看它的单元测试覆盖率,就会发现已经是 100% 了。
基准测试
除了需要保证我们编写的代码的逻辑正确外,有时候还有性能要求。那么如何衡量代码的性能呢?这就需要基准测试了。
什么是基准测试
基准测试(Benchmark)是一项用于测量和评估软件性能指标的方法,主要用于评估你写的代码的性能。
Go 语言的基准测试
Go 语言的基准测试和单元测试规则基本一样,只是测试函数的命名规则不一样。现在还以 Fibonacci 函数为例,演示 Go 语言基准测试的使用。
Fibonacci 函数的基准测试代码如下:
ch18/main_test.go
func BenchmarkFibonacci(b *testing.B){
for i:=0;i<b.N;i++{
Fibonacci(10)
}
}
这是一个非常简单的 Go 语言基准测试示例,它和单元测试的不同点如下:
-
基准测试函数必须以 Benchmark 开头,必须是可导出的;
-
函数的签名必须接收一个指向 testing.B 类型的指针,并且不能返回任何值;
-
最后的 for 循环很重要,被测试的代码要放到循环里;
-
b.N 是基准测试框架提供的,表示循环的次数,因为需要反复调用测试的代码,才可以评估性能。
写好了基准测试,就可以通过如下命令来测试 Fibonacci 函数的性能:
➜ go test -bench=. ./ch18
goos: darwin
goarch: amd64
pkg: gotour/ch18
BenchmarkFibonacci-8 3461616 343 ns/op
PASS
ok gotour/ch18 2.230s
运行基准测试也要使用 go test 命令,不过要加上 -bench 这个 Flag,它接受一个表达式作为参数,以匹配基准测试的函数,"."表示运行所有基准测试。
下面着重解释输出的结果。看到函数后面的 -8 了吗?这个表示运行基准测试时对应的 GOMAXPROCS 的值。接着的 3461616 表示运行 for 循环的次数,也就是调用被测试代码的次数,最后的 343 ns/op 表示每次需要花费 343 纳秒。
基准测试的时间默认是 1 秒,也就是 1 秒调用 3461616 次、每次调用花费 343 纳秒。如果想让测试运行的时间更长,可以通过 -benchtime 指定,比如 3 秒,代码如下所示:
go test -bench=. -benchtime=3s ./ch18
计时方法
进行基准测试之前会做一些准备,比如构建测试数据等,这些准备也需要消耗时间,所以需要把这部分时间排除在外。这就需要通过 ResetTimer 方法重置计时器,示例代码如下:
func BenchmarkFibonacci(b *testing.B) {
n := 10
b.ResetTimer() //重置计时器
for i := 0; i < b.N; i++ {
Fibonacci(n)
}
}
这样可以避免因为准备数据耗时造成的干扰。
除了 ResetTimer 方法外,还有 StartTimer 和 StopTimer 方法,帮你灵活地控制什么时候开始计时、什么时候停止计时。
内存统计
在基准测试时,还可以统计每次操作分配内存的次数,以及每次操作分配的字节数,这两个指标可以作为优化代码的参考。要开启内存统计也比较简单,代码如下,即通过 ReportAllocs() 方法:
func BenchmarkFibonacci(b *testing.B) {
n := 10
b.ReportAllocs() //开启内存统计
b.ResetTimer() //重置计时器
for i := 0; i < b.N; i++ {
Fibonacci(n)
}
}
现在再运行这个基准测试,就可以看到如下结果:
➜ go test -bench=. ./ch18
goos: darwin
goarch: amd64
pkg: gotour/ch18
BenchmarkFibonacci-8 2486265 486 ns/op 0 B/op 0 allocs/op
PASS
ok gotour/ch18 2.533s
可以看到相比原来的基准测试多了两个指标,分别是 0 B/op 和 0 allocs/op。前者表示每次操作分配了多少字节的内存,后者表示每次操作分配内存的次数。这两个指标可以作为代码优化的参考,尽可能地越小越好。
小提示:以上两个指标是否越小越好?这是不一定的,因为有时候代码实现需要空间换时间,所以要根据自己的具体业务而定,做到在满足业务的情况下越小越好。
并发基准测试
除了普通的基准测试外,Go 语言还支持并发基准测试,你可以测试在多个 goroutine 并发下代码的性能。还是以 Fibonacci 为例,它的并发基准测试代码如下:
func BenchmarkFibonacciRunParallel(b *testing.B) {
n := 10
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
Fibonacci(n)
}
})
}
可以看到,Go 语言通过 RunParallel 方法运行并发基准测试。RunParallel 方法会创建多个 goroutine,并将 b.N 分配给这些 goroutine 执行。
基准测试实战
相信你已经理解了 Go 语言的基准测试,也学会了如何使用,现在我以一个实战帮你复习。
还是以 Fibonacci 函数为例,通过前面小节的基准测试,会发现它并没有分配新的内存,也就是说 Fibonacci 函数慢并不是因为内存,排除掉这个原因,就可以归结为所写的算法问题了。
在递归运算中,一定会有重复计算,这是影响递归的主要因素。解决重复计算可以使用缓存,把已经计算好的结果保存起来,就可以重复使用了。
基于这个思路,我将 Fibonacci 函数的代码进行如下修改:
//缓存已经计算的结果
var cache = map[int]int{}
func Fibonacci(n int) int {
if v, ok := cache[n]; ok {
return v
}
result := 0
switch {
case n < 0:
result = 0
case n == 0:
result = 0
case n == 1:
result = 1
default:
result = Fibonacci(n-1) + Fibonacci(n-2)
}
cache[n] = result
return result
}
这组代码的核心在于采用一个 map 将已经计算好的结果缓存、便于重新使用。改造后,我再来运行基准测试,看看刚刚优化的效果,如下所示:
BenchmarkFibonacci-8 97823403 11.7 ns/op
可以看到,结果为 11.7 纳秒,相比优化前的 343 纳秒,性能足足提高了 28 倍。
总结
单元测试是保证代码质量的好方法,但单元测试也不是万能的,使用它可以降低 Bug 率,但也不要完全依赖。除了单元测试外,还可以辅以 Code Review、人工测试等手段更好地保证代码质量。
在这节课的最后给你留个练习题:在运行 go test 命令时,使用 -benchmem 这个 Flag 进行内存统计。
下一讲我将介绍“性能优化:Go 语言如何进行代码检查和优化?”记得来听课!
19 性能优化:Go 语言如何进行代码检查和优化?
在上节课中,我为你留了一个小作业:在运行 go test 命令时,使用 -benchmem 这个 Flag 进行内存统计。该作业的答案比较简单,命令如下所示:
➜ go test -bench=. -benchmem ./ch18
运行这一命令就可以查看内存统计的结果了。这种通过 -benchmem 查看内存的方法适用于所有的基准测试用例。
今天要讲的内容是 Go 语言的代码检查和优化,下面我们开始本讲内容的讲解。
在项目开发中,保证代码质量和性能的手段不只有单元测试和基准测试,还有代码规范检查和性能优化。
-
代码规范检查是对单元测试的一种补充,它可以从非业务的层面检查你的代码是否还有优化的空间,比如变量是否被使用、是否是死代码等等。
-
性能优化是通过基准测试来衡量的,这样我们才知道优化部分是否真的提升了程序的性能。
代码规范检查
什么是代码规范检查
代码规范检查,顾名思义,是从 Go 语言层面出发,依据 Go 语言的规范,对你写的代码进行的静态扫描检查,这种检查和你的业务无关。
比如你定义了个常量,从未使用过,虽然对代码运行并没有造成什么影响,但是这个常量是可以删除的,代码如下所示:
ch19/main.go
const name = "飞雪无情"
func main() {
}
示例中的常量 name 其实并没有使用,所以为了节省内存你可以删除它,这种未使用常量的情况就可以通过代码规范检查检测出来。
再比如,你调用了一个函数,该函数返回了一个 error,但是你并没有对该 error 做判断,这种情况下,程序也可以正常编译运行。但是代码写得不严谨,因为返回的 error 被我们忽略了。代码如下所示:
ch19/main.go
func main() {
os.Mkdir("tmp",0666)
}
示例代码中,Mkdir 函数是有返回 error 的,但是你并没有对返回的 error 做判断,这种情况下,哪怕创建目录失败,你也不知道,因为错误被你忽略了。如果你使用代码规范检查,这类潜在的问题也会被检测出来。
以上两个例子可以帮你理解什么是代码规范检查、它有什么用。除了这两种情况,还有拼写问题、死代码、代码简化检测、命名中带下划线、冗余代码等,都可以使用代码规范检查检测出来。
golangci-lint
要想对代码进行检查,则需要对代码进行扫描,静态分析写的代码是否存在规范问题。
小提示:静态代码分析是不会运行代码的。
可用于 Go 语言代码分析的工具有很多,比如 golint、gofmt、misspell 等,如果一一引用配置,就会比较烦琐,所以通常我们不会单独地使用它们,而是使用 golangci-lint。
golangci-lint 是一个集成工具,它集成了很多静态代码分析工具,便于我们使用。通过配置这一工具,我们可以很灵活地启用需要的代码规范检查。
如果要使用 golangci-lint,首先需要安装。因为 golangci-lint 本身就是 Go 语言编写的,所以我们可以从源代码安装它,打开终端,输入如下命令即可安装。
➜ go get github.com/golangci/golangci-lint/cmd/golangci-lint@v1.32.2
使用这一命令安装的是 v1.32.2 版本的 golangci-lint,安装完成后,在终端输入如下命令,检测是否安装成功。
➜ golangci-lint version
golangci-lint has version v1.32.2
小提示:在 MacOS 下也可以使用 brew 来安装 golangci-lint。
好了,安装成功 golangci-lint 后,就可以使用它进行代码检查了,我以上面示例中的常量 name 和 Mkdir 函数为例,演示 golangci-lint 的使用。在终端输入如下命令回车:
➜ golangci-lint run ch19/
这一示例表示要检测目录中 ch19 下的代码,运行后可以看到如下输出结果。
ch19/main.go:5:7: `name` is unused (deadcode)
const name = "飞雪无情"
^
ch19/main.go:8:10: Error return value of `os.Mkdir` is not checked (errcheck)
os.Mkdir("tmp",0666)
通过代码检测结果可以看到,我上一小节提到的两个代码规范问题都被检测出来了。检测出问题后,你就可以修复它们,让代码更加符合规范。
golangci-lint 配置
golangci-lint 的配置比较灵活,比如你可以自定义要启用哪些 linter。golangci-lint 默认启用的 linter,包括这些:
deadcode - 死代码检查
errcheck - 返回错误是否使用检查
gosimple - 检查代码是否可以简化
govet - 代码可疑检查,比如格式化字符串和类型不一致
ineffassign - 检查是否有未使用的代码
staticcheck - 静态分析检查
structcheck - 查找未使用的结构体字段
typecheck - 类型检查
unused - 未使用代码检查
varcheck - 未使用的全局变量和常量检查
小提示:golangci-lint 支持的更多 linter,可以在终端中输入 golangci-lint linters 命令查看,并且可以看到每个 linter 的说明。
如果要修改默认启用的 linter,就需要对 golangci-lint 进行配置。即在项目根目录下新建一个名字为 .golangci.yml 的文件,这就是 golangci-lint 的配置文件。在运行代码规范检查的时候,golangci-lint 会自动使用它。假设我只启用 unused 检查,可以这样配置:
.golangci.yml
linters:
disable-all: true
enable:
- unused
在团队多人协作开发中,有一个固定的 golangci-lint 版本是非常重要的,这样大家就可以基于同样的标准检查代码。要配置 golangci-lint 使用的版本也比较简单,在配置文件中添加如下代码即可:
service:
golangci-lint-version: 1.32.2 # use the fixed version to not introduce new linters unexpectedly
此外,你还可以针对每个启用的 linter 进行配置,比如要设置拼写检测的语言为 US,可以使用如下代码设置:
linters-settings:
misspell:
locale: US
golangci-lint 的配置比较多,你自己可以灵活配置。关于 golangci-lint 的更多配置可以参考官方文档,这里我给出一个常用的配置,代码如下:
.golangci.yml
linters-settings:
golint:
min-confidence: 0
misspell:
locale: US
linters:
disable-all: true
enable:
- typecheck
- goimports
- misspell
- govet
- golint
- ineffassign
- gosimple
- deadcode
- structcheck
- unused
- errcheck
service:
golangci-lint-version: 1.32.2 # use the fixed version to not introduce new linters unexpectedly
集成 golangci-lint 到 CI
代码检查一定要集成到 CI 流程中,效果才会更好,这样开发者提交代码的时候,CI 就会自动检查代码,及时发现问题并进行修正。
不管你是使用 Jenkins,还是 Gitlab CI,或者 Github Action,都可以通过Makefile的方式运行 golangci-lint。现在我在项目根目录下创建一个 Makefile 文件,并添加如下代码:
Makefile
getdeps:
@mkdir -p ${GOPATH}/bin
@which golangci-lint 1>/dev/null || (echo "Installing golangci-lint" && go get github.com/golangci/golangci-lint/cmd/golangci-lint@v1.32.2)
lint:
@echo "Running $@ check"
@GO111MODULE=on ${GOPATH}/bin/golangci-lint cache clean
@GO111MODULE=on ${GOPATH}/bin/golangci-lint run --timeout=5m --config ./.golangci.yml
verifiers: getdeps lint
小提示:关于 Makefile 的知识可以网上搜索学习一下,比较简单,这里不再进行讲述。
好了,现在你就可以把如下命令添加到你的 CI 中了,它可以帮你自动安装 golangci-lint,并检查你的代码。
make verifiers
性能优化
性能优化的目的是让程序更好、更快地运行,但是它不是必要的,这一点一定要记住。所以在程序开始的时候,你不必刻意追求性能优化,先大胆地写你的代码就好了,写正确的代码是性能优化的前提。

堆分配还是栈
在比较古老的 C 语言中,内存分配是手动申请的,内存释放也需要手动完成。
-
手动控制有一个很大的好处就是你需要多少就申请多少,可以最大化地利用内存;
-
但是这种方式也有一个明显的缺点,就是如果忘记释放内存,就会导致内存泄漏。
所以,为了让程序员更好地专注于业务代码的实现,Go 语言增加了垃圾回收机制,自动地回收不再使用的内存。
Go 语言有两部分内存空间:栈内存和堆内存。
-
栈内存由编译器自动分配和释放,开发者无法控制。栈内存一般存储函数中的局部变量、参数等,函数创建的时候,这些内存会被自动创建;函数返回的时候,这些内存会被自动释放。
-
堆内存的生命周期比栈内存要长,如果函数返回的值还会在其他地方使用,那么这个值就会被编译器自动分配到堆上。堆内存相比栈内存来说,不能自动被编译器释放,只能通过垃圾回收器才能释放,所以栈内存效率会很高。
逃逸分析
既然栈内存的效率更高,肯定是优先使用栈内存。那么 Go 语言是如何判断一个变量应该分配到堆上还是栈上的呢?这就需要逃逸分析了。下面我通过一个示例来讲解逃逸分析,代码如下:
ch19/main.go
func newString() *string{
s:=new(string)
*s = "飞雪无情"
return s
}
在这个示例中:
-
通过 new 函数申请了一块内存;
-
然后把它赋值给了指针变量 s;
-
最后通过 return 关键字返回。
小提示:以上 newString 函数是没有意义的,这里只是为了方便演示。
现在我通过逃逸分析来看下是否发生了逃逸,命令如下:
➜ go build -gcflags="-m -l" ./ch19/main.go
# command-line-arguments
ch19/main.go:16:8: new(string) escapes to heap
在这一命令中,-m 表示打印出逃逸分析信息,-l 表示禁止内联,可以更好地观察逃逸。从以上输出结果可以看到,发生了逃逸,也就是说指针作为函数返回值的时候,一定会发生逃逸。
逃逸到堆内存的变量不能马上被回收,只能通过垃圾回收标记清除,增加了垃圾回收的压力,所以要尽可能地避免逃逸,让变量分配在栈内存上,这样函数返回时就可以回收资源,提升效率。
下面我对 newString 函数进行了避免逃逸的优化,优化后的函数代码如下:
ch19/main.go
func newString() string{
s:=new(string)
*s = "飞雪无情"
return *s
}
再次通过命令查看以上代码的逃逸分析,命令如下:
➜ go build -gcflags="-m -l" ./ch19/main.go
# command-line-arguments
ch19/main.go:14:8: new(string) does not escape
通过分析结果可以看到,虽然还是声明了指针变量 s,但是函数返回的并不是指针,所以没有发生逃逸。
这就是关于指针作为函数返回逃逸的例子,那么是不是不使用指针就不会发生逃逸了呢?下面看个例子,代码如下:
fmt.Println("飞雪无情")
同样运行逃逸分析,你会看到如下结果:
➜ go build -gcflags="-m -l" ./ch19/main.go
# command-line-arguments
ch19/main.go:13:13: ... argument does not escape
ch19/main.go:13:14: "飞雪无情" escapes to heap
ch19/main.go:17:8: new(string) does not escape
观察这一结果,你会发现「飞雪无情」这个字符串逃逸到了堆上,这是因为「飞雪无情」这个字符串被已经逃逸的指针变量引用,所以它也跟着逃逸了,引用代码如下:
func (p *pp) printArg(arg interface{}, verb rune) {
p.arg = arg
//省略其他无关代码
}
所以被已经逃逸的指针引用的变量也会发生逃逸。
Go 语言中有 3 个比较特殊的类型,它们是 slice、map 和 chan,被这三种类型引用的指针也会发生逃逸,看个这样的例子:
ch19/main.go
func main() {
m:=map[int]*string{}
s:="飞雪无情"
m[0] = &s
}
同样运行逃逸分析,你看到的结果是:
➜ gotour go build -gcflags="-m -l" ./ch19/main.go
# command-line-arguments
ch19/main.go:16:2: moved to heap: s
ch19/main.go:15:20: map[int]*string literal does not escape
从这一结果可以看到,变量 m 没有逃逸,反而被变量 m 引用的变量 s 逃逸到了堆上。所以被map、slice 和 chan 这三种类型引用的指针一定会发生逃逸的。
逃逸分析是判断变量是分配在堆上还是栈上的一种方法,在实际的项目中要尽可能避免逃逸,这样就不会被 GC 拖慢速度,从而提升效率。
小技巧:从逃逸分析来看,指针虽然可以减少内存的拷贝,但它同样会引起逃逸,所以要根据实际情况选择是否使用指针。
优化技巧
通过前面小节的介绍,相信你已经了解了栈内存和堆内存,以及变量什么时候会逃逸,那么在优化的时候思路就比较清晰了,因为都是基于以上原理进行的。下面我总结几个优化的小技巧:
第 1 个需要介绍的技巧是尽可能避免逃逸,因为栈内存效率更高,还不用 GC。比如小对象的传参,array 要比 slice 效果好。
如果避免不了逃逸,还是在堆上分配了内存,那么对于频繁的内存申请操作,我们要学会重用内存,比如使用 sync.Pool,这是第 2 个技巧。
第 3 个技巧就是选用合适的算法,达到高性能的目的,比如空间换时间。
小提示:性能优化的时候,要结合基准测试,来验证自己的优化是否有提升。
以上是基于 GO 语言的内存管理机制总结出的 3 个方向的技巧,基于这 3 个大方向基本上可以优化出你想要的效果。除此之外,还有一些小技巧,比如要尽可能避免使用锁、并发加锁的范围要尽可能小、使用 StringBuilder 做 string 和 [ ] byte 之间的转换、defer 嵌套不要太多等等。
最后推荐一个 Go 语言自带的性能剖析的工具 pprof,通过它你可以查看 CPU 分析、内存分析、阻塞分析、互斥锁分析,它的使用不是太复杂,你可以搜索下它的使用教程,这里就不展开介绍。
总结
这节课主要介绍了代码规范检查和性能优化两部分内容,其中代码规范检查是从工具使用的角度讲解,而性能优化可能涉及的点太多,所以是从原理的角度讲解,你明白了原理,就能更好地优化你的代码。
我认为是否进行性能优化取决于两点:业务需求和自我驱动。所以不要刻意地去做性能优化,尤其是不要提前做,先保证代码正确并上线,然后再根据业务需要,决定是否进行优化以及花多少时间优化。自我驱动其实是一种编码能力的体现,比如有经验的开发者在编码的时候,潜意识地就避免了逃逸,减少了内存拷贝,在高并发的场景中设计了低延迟的架构。
最后给你留个作业,把 golangci-lint 引入自己的项目吧,相信你的付出会有回报的。
下一讲我将介绍“协作开发:模块化管理为什么能够提升研发效能”,记得来听课!
20 协作开发:模块化管理为什么能够提升研发效能?
任何业务,都是从简单向复杂演进的。而在业务演进的过程中,技术是从单体向多模块、多服务演进的。技术的这种演进方式的核心目的是复用代码、提高效率,这一讲,我会为你介绍 Go 语言是如何通过模块化的管理,提升开发效率的。
Go 语言中的包
什么是包
在业务非常简单的时候,你甚至可以把代码写到一个 Go 文件中。但随着业务逐渐复杂,你会发现,如果代码都放在一个 Go 文件中,会变得难以维护,这时候你就需要抽取代码,把相同业务的代码放在一个目录中。在 Go 语言中,这个目录叫作包。
在 Go 语言中,一个包是通过package 关键字定义的,最常见的就是main 包,它的定义如下所示:
package main
此外,前面章节演示示例经常使用到的 fmt 包,也是通过 package 关键字声明的。
一个包就是一个独立的空间,你可以在这个包里定义函数、结构体等。这时,我们认为这些函数、结构体是属于这个包的。
使用包
如果你想使用一个包里的函数或者结构体,就需要先导入这个包,才能使用,比如常用的 fmt包,代码示例如下所示。
package main
import "fmt"
func main() {
fmt.Println("先导入fmt包,才能使用")
}
要导入一个包,需要使用 import 关键字;如果需要同时导入多个包,则可以使用小括号,示例代码如下所示。
import (
"fmt"
"os"
)
从以上示例可以看到,该示例导入了 fmt 和 os 这两个包,使用了小括号,每一行写了一个要导入的包。
作用域
讲到了包之间的导入和使用,就不得不提作用域这个概念,因为只有满足作用域的函数才可以被调用。
-
在Java 语言中,通过 public、private 这些修饰符修饰一个类的作用域;
-
但是在Go 语言中,并没有这样的作用域修饰符,它是通过首字母是否大写来区分的,这同时也体现了 Go 语言的简洁。
如上述示例中 fmt 包中的Println 函数:
-
它的首字母就是大写的 P,所以该函数才可以在 main 包中使用;
-
如果 Println 函数的首字母是小写的 p,那么它只能在 fmt 包中被使用,不能跨包使用。
这里我为你总结下 Go 语言的作用域:
-
Go 语言中,所有的定义,比如函数、变量、结构体等,如果首字母是大写,那么就可以被其他包使用;
-
反之,如果首字母是小写的,就只能在同一个包内使用。
自定义包
你也可以自定义自己的包,通过包的方式把相同业务、相同职责的代码放在一起。比如你有一个 util 包,用于存放一些常用的工具函数,项目结构如下所示:
ch20
├── main.go
└── util
└── string.go
在 Go 语言中,一个包对应一个文件夹,上面的项目结构示例也验证了这一点。在这个示例中,有一个 util 文件夹,它里面有一个 string.go 文件,这个 Go 语言文件就属于 util 包,它的包定义如下所示:
ch20/util/string.go
package util
可以看到,Go 语言中的包是代码的一种组织形式,通过包把相同业务或者相同职责的代码放在一起。通过包对代码进行归类,便于代码维护以及被其他包调用,提高团队协作效率。
init 函数
除了 main 这个特殊的函数外,Go 语言还有一个特殊的函数——init,通过它可以实现包级别的一些初始化操作。
init 函数没有返回值,也没有参数,它先于 main 函数执行,代码如下所示:
func init() {
fmt.Println("init in main.go ")
}
一个包中可以有多个 init 函数,但是它们的执行顺序并不确定,所以如果你定义了多个 init 函数的话,要确保它们是相互独立的,一定不要有顺序上的依赖。
那么 init 函数作用是什么呢? 其实就是在导入一个包时,可以对这个包做一些必要的初始化操作,比如数据库连接和一些数据的检查,确保我们可以正确地使用这个包。
Go 语言中的模块
如果包是比较低级的代码组织形式的话,那么模块就是更高级别的,在 Go 语言中,一个模块可以包含很多个包,所以模块是相关的包的集合。
在 Go 语言中:
-
一个模块通常是一个项目,比如这个专栏实例中使用的 gotour 项目;
-
也可以是一个框架,比如常用的 Web 框架 gin。
go mod
Go 语言为我们提供了 go mod 命令来创建一个模块(项目),比如要创建一个 gotour 模块,你可以通过如下命令实现:
➜ go mod init gotour
go: creating new go.mod: module gotour
运行这一命令后,你会看到已经创建好一个名字为 gotour 的文件夹,里面有一个 go.mod 文件,它里面的内容如下所示:
module gotour
go 1.15
-
第一句是该项目的模块名,也就是 gotour;
-
第二句表示要编译该模块至少需要Go 1.15 版本的 SDK。
小提示:模块名最好是以自己的域名开头,比如 flysnow.org/gotour,这样就可以很大程度上保证模块名的唯一,不至于和其他模块重名。
使用第三方模块
模块化为什么可以提高开发效率?最重要的原因就是复用了现有的模块,Go 语言也不例外。比如你可以把项目中的公共代码抽取为一个模块,这样就可以供其他项目使用,不用再重复开发;同理,在 Github 上也有很多开源的 Go 语言项目,它们都是一个个独立的模块,也可以被我们直接使用,提高我们的开发效率,比如 Web 框架 gin-gonic/gin。
众所周知,在使用第三方模块之前,需要先设置下 Go 代理,也就是 GOPROXY,这样我们就可以获取到第三方模块了。
在这里我推荐 goproxy.io 这个代理,非常好用,速度也很快。要使用这个代理,需要进行如下代码设置:
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.io,direct
打开终端,输入这一命令回车即可设置成功。
在实际的项目开发中,除了第三方模块外,还有我们自己开发的模块,放在了公司的 GitLab上,这时候就要把公司 Git 代码库的域名排除在 Go PROXY 之外,为此 Go 语言提供了GOPRIVATE 这个环境变量帮助我们达到目的。通过如下命令即可设置 GOPRIVATE:
# 设置不走 proxy 的私有仓库,多个用逗号相隔(可选)
go env -w GOPRIVATE=*.corp.example.com
以上域名只是一个示例,实际使用时你要改成自己公司私有仓库的域名。
一切都准备好就可以使用第三方的模块了,假设我们要使用 Gin 这个 Web 框架,首先需要安装它,通过如下命令即可安装 Gin 这个 Web 框架:
go get -u github.com/gin-gonic/gin
安装成功后,就可以像 Go 语言的标准包一样,通过 import 命令导入你的代码中使用它,代码如下所示:
package main
import (
"fmt"
"github.com/gin-gonic/gin"
)
func main() {
fmt.Println("先导入fmt包,才能使用")
r := gin.Default()
r.Run()
}
以上代码现在还无法编译通过,因为还没有同步 Gin 这个模块的依赖,也就是没有把它添加到go.mod 文件中。通过如下命令可以添加缺失的模块:
go mod tidy
运行这一命令,就可以把缺失的模块添加进来,同时它也可以移除不再需要的模块。这时你再查看 go.mod 文件,会发现内容已经变成了这样:
module gotour
go 1.15
require (
github.com/gin-gonic/gin v1.6.3
github.com/golang/protobuf v1.4.2 // indirect
github.com/google/go-cmp v0.5.2 // indirect
github.com/kr/text v0.2.0 // indirect
github.com/modern-go/concurrent v0.0.0-20180306012644-bacd9c7ef1dd // indirect
github.com/modern-go/reflect2 v1.0.1 // indirect
github.com/niemeyer/pretty v0.0.0-20200227124842-a10e7caefd8e // indirect
github.com/stretchr/testify v1.6.1 // indirect
golang.org/x/sys v0.0.0-20201009025420-dfb3f7c4e634 // indirect
golang.org/x/xerrors v0.0.0-20200804184101-5ec99f83aff1 // indirect
gopkg.in/check.v1 v1.0.0-20200227125254-8fa46927fb4f // indirect
gopkg.in/yaml.v2 v2.3.0 // indirect
)
所以我们不用手动去修改 go.mod 文件,通过 Go 语言的工具链比如 go mod tidy 命令,就可以帮助我们自动地维护、自动地添加或者修改 go.mod 的内容。
总结
在 Go 语言中,包是同一目录中,编译在一起的源文件的集合。包里面含有函数、类型、变量和常量,不同包之间的调用,必须要首字母大写才可以。
而模块又是相关的包的集合,它里面包含了很多为了实现该模块的包,并且还可以通过模块的方式,把已经完成的模块提供给其他项目(模块)使用,达到了代码复用、研发效率提高的目的。
所以对于你的项目(模块)来说,它具有模块 ➡ 包 ➡ 函数类型这样三层结构,同一个模块中,可以通过包组织代码,达到代码复用的目的;在不同模块中,就需要通过模块的引入,达到这个目的。
编程界有个谚语:不要重复造轮子,使用现成的轮子,可以提高开发效率,降低 Bug 率。Go 语言提供的模块、包这些能力,就可以很好地让我们使用现有的轮子,在多人协作开发中,更好地提高工作效率。
最后,为你留个作业:基于模块化拆分你所做的项目,提取一些公共的模块,以供更多项目使用。相信这样你们的开发效率会大大提升的。