
hash tableaesaes hashmemhash每个map的底层结构是hmap,是有若干个结构为bmap的bucket组成的数组。每个bucket底层都采用链表结构。
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的,关于key的定位我们在map的查询和赋值中详细说明。
在桶内,又会根据key计算出来的hash值的高8位来决定 key到底落入桶内的哪个位置(一个桶内最多有8个位置)。
当map的key和value都不是指针,并且 size都小于128字节的情况下,会把bmap标记为不含指针,这样可以避免gc时扫描整个hmap。
但是,我们看bmap其实有一个overflow的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把overflow移动到 hmap的extra 字段来。
这样随着哈希表存储的数据逐渐增多,我们会扩容哈希表或者使用额外的桶存储溢出的数据,不会让单个桶中的数据超过 8 个,不过溢出桶只是临时的解决方案,创建过多的溢出桶最终也会导致哈希的扩容。
哈希表作为一种数据结构,我们肯定要分析它的常见操作,首先就是读写操作的原理。哈希表的访问一般都是通过下标或者遍历进行的:
这两种方式虽然都能读取哈希表的数据,但是使用的函数和底层原理完全不同。
第一个需要知道哈希的键并且一次只能获取单个键对应的值,而第二个可以遍历哈希中的全部键值对,访问数据时也不需要预先知道哈希的键。
hash[key]OINDEXMAPcmd/compile/internal/gc.walkexprOINDEXMAP这里根据赋值语句左侧接受参数的个数会决定使用的运行时方法:
runtime.mapaccess1runtime.mapaccess2mapaccess1runtime.bucketMaskruntime.add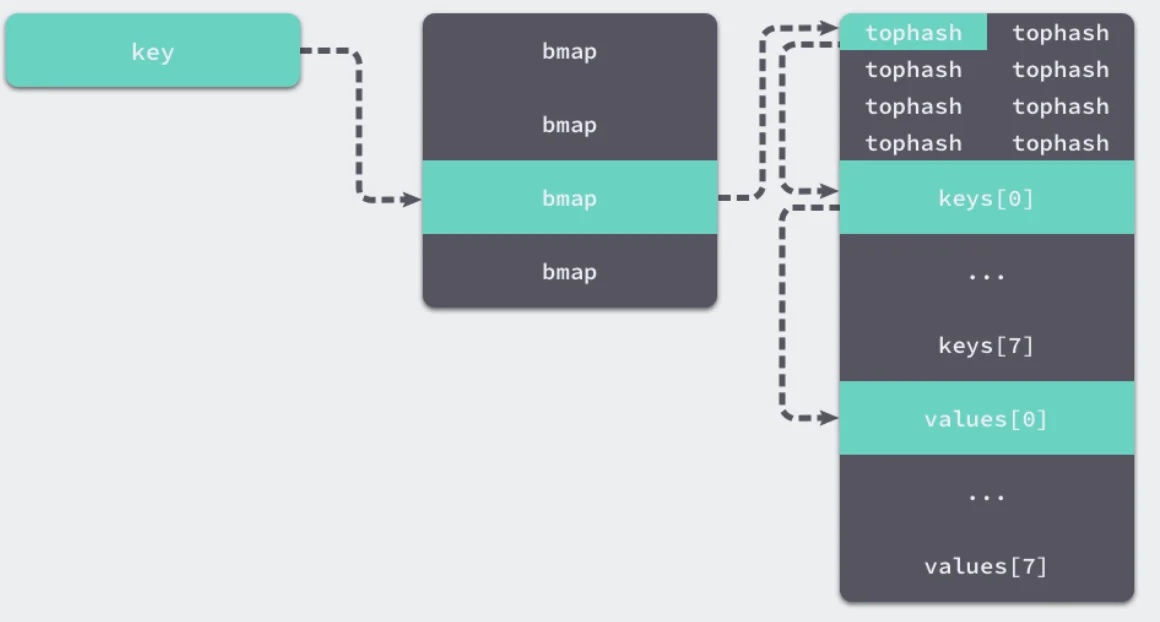
如果在bucket中没有找到,此时如果overflow不为空,那么就沿着overflow继续查找,如果还是没有找到,那就从别的key槽位查找,直到遍历所有bucket。
在 bucketloop 循环中,哈希会依次遍历正常桶和溢出桶中的数据,它先会比较哈希的高 8 位和桶中存储的 tophash,后比较传入的和桶中的值以加速数据的读写。用于选择桶序号的是哈希的最低几位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能。
unsafe.Pointer(b)+dataOffsetruntime.mapaccess2runtime.mapaccess1v, ok := hash[k]v == nil写入:
hash[k]mapassignmapaccess1tophashnewoverflowhmapnoverflownoverflowtypedmemmovemapassign扩容:
随着哈希表中元素的逐渐增加,哈希的性能会逐渐恶化,所以我们需要更多的桶和更大的内存保证哈希的读写性能,这个时候我们就需要用到扩容了.
mapassign- 装载因子已经超过 6.5;
- 哈希使用了太多溢出桶;
mapassignsameSizeGrowsameSizeGrowruntime: limit the number of map overflow bucketssameSizeGrowhashGrowmakeBucketArrayoldbuckets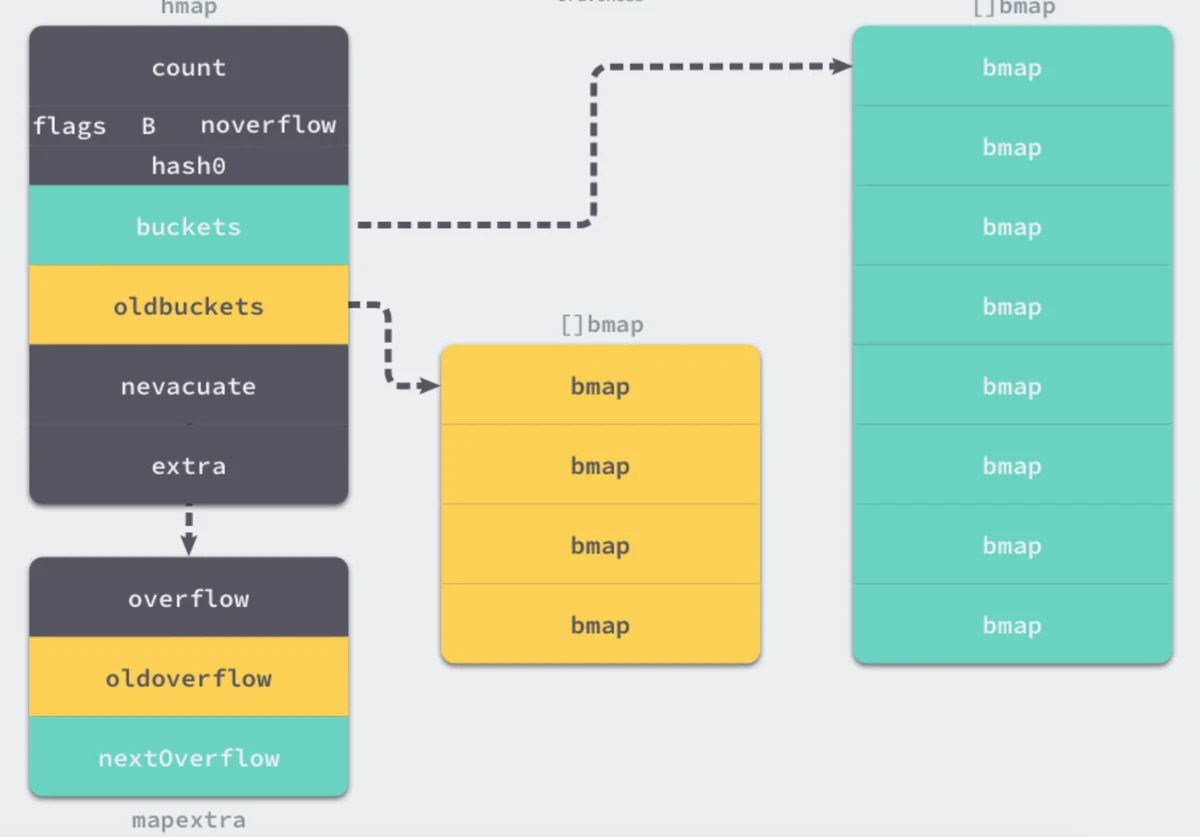
hashGrowevacuateevacuateevacDst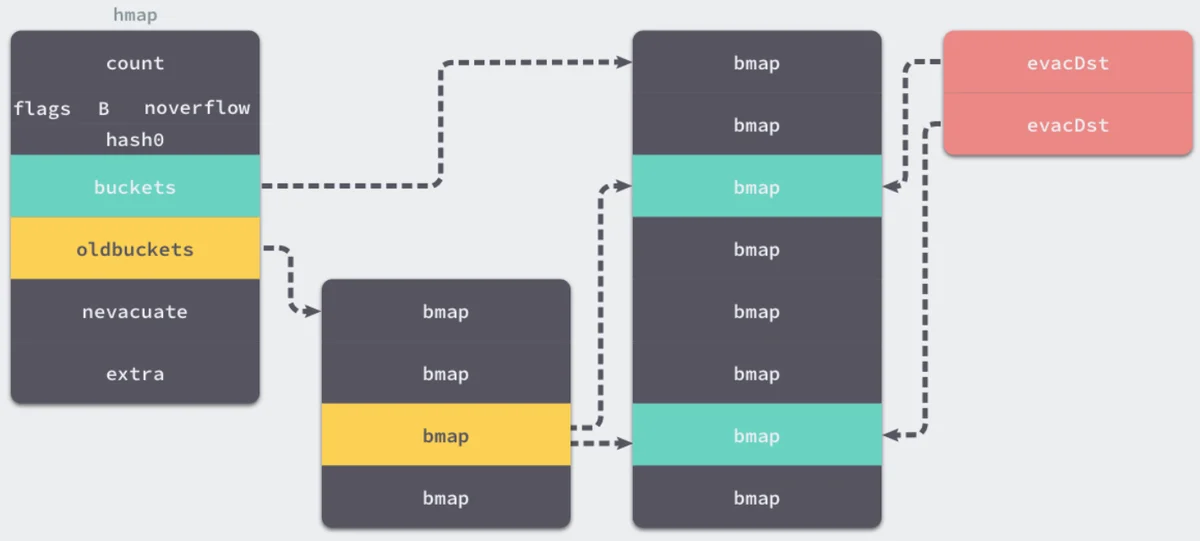
哈希表扩容目的:
evacDst只使用哈希函数是不能定位到具体某一个桶的,哈希函数只会返回很长的哈希,我们还需一些方法将哈希映射到具体的桶上。
那么如何定位key呢?
key 经过哈希计算后得到哈希值,共64个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。
2^5 = 32例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
01010再用哈希值的高 8 位,找到此 key 在bucket中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
buckets 编号就是桶编号,当两个不同的key落在同一个桶中,也就是发生了哈希冲突。
通常哈希冲突的解决手段是用链表法,在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
growWorksameSizeGrow删除:
如果想要删除哈希中的元素,就需要使用 Go 语言中的 delete 关键字,这个关键字的唯一作用就是将某一个键对应的元素从哈希表中删除,无论是该键对应的值是否存在,这个内建的函数都不会返回任何的结果。
因此呢Go采用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。
tophash哈希表的每个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会存储到哈希的溢出桶中。
随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大损耗。