
1、初始化一个map变量
m1 := make(map[string]interface{})
m2 := make(map[string]interface{}, 10)2、上面两个make,会调用对应的实现方法。
当我们使用make来初始化一个map变量时,
1、如果不指定数量,会执行makemap_small()并返回一个hmap的地址,
2、如果指定数量,会调用makemap64()并返回一个hmap地址,
//以下方法均来自源码runtime/map.go文件
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
func makemap64(t *maptype, hint int64, h *hmap) *hmap {
if int64(int(hint)) != hint {
hint = 0
}
return makemap(t, int(hint), h)
}
func makemap(t *maptype, hint int, h *hmap) *hmap {
//````省略一些代码
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
//````省略一些代码
return h
}3、看一下makemap()函数中做了哪些动作
暂时我们先记住,当make一个map时,它会去new一个hmap给我们,现在我们看一下makemap()方法的完整代码。
源码中的B,就是bucket,可以称之为“桶”,桶的意思就是存储数据的,每个桶都可以装8个键值对。
如果我们在make一个指定数量的map时,就会调用makemap()函数,并且根据指定的数量,在 overLoadFactor(hint, B)时,计算出来应该生成多少个桶,并且在makeBucketArray(t, h.B, nil)方法开始分配内存,生成对应数量的桶。
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
// 这个只是校验,并不关键,这个校验如果数量超过最大值,就给它重置为0不分配桶了
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}4、研究一下hmap结构体
我们在第2步得知,当make一个map时,它会去new一个hmap给我们,hmap实际上就是哈希map,下面我们再来研究一下这个hmap。
在runtime/map.go这个源码文件中,可以找到hmap这个结构体的定义
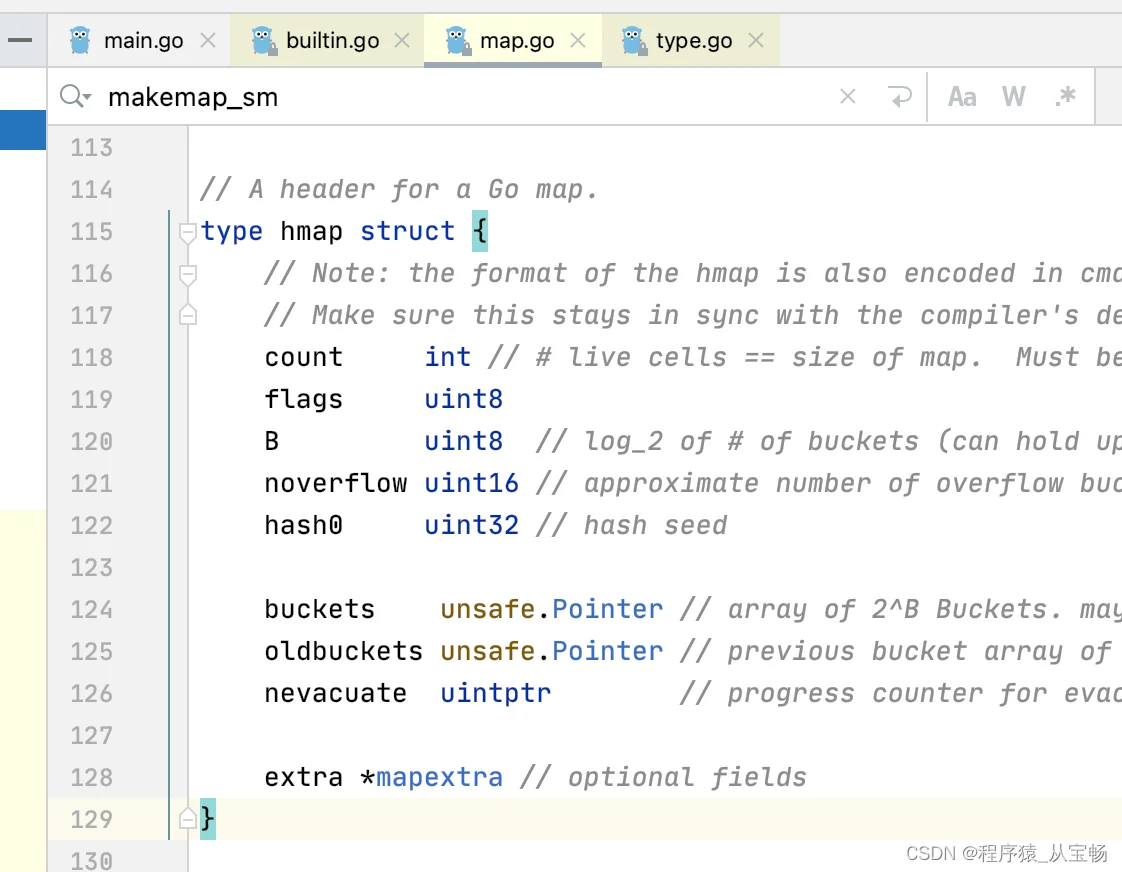
hmap结构体中,几个关键字段:
count:是存储了多少个数据
B:桶的数量是log_2的多少。如果是B=0,桶的数量对应的就是2^0 = 1个,B=1,那2^1 = 2个,以此类推。
noverflow: 溢出桶的数量
buckets:是桶的地址
oldbuckets:旧桶的地址(如果桶满了会产生扩容,数据会从旧桶迁移到新桶)
nevacuate: 迁移新桶时记录的下一个要被迁移的旧桶编号
extra:里面会记录一些溢出桶的信息(当一个桶满了,hash运算还往桶里装数据时会放进溢出桶)
5、谈一谈存储过程
5.1、普通存储:
5.2、触发扩容条件:
5.3、桶满了但没触发扩容条件:
普通存储:
假设我们在make的初始化的时候,B=2,也就是说分配了4个桶,那么4个桶的编号分别是0,1,2,3。当我们添加一个键值对时,应该把这个数据放在哪个桶里呢?
这就设计到hash内在的算法了。比如取模法,先把键值对的key进行hash运算,hash%桶的数量取模,得到应该放到哪个桶里。取值的时候也是一样。
触发扩容条件:
map的扩容是翻倍扩容,比如现在B=2,相对应有4个桶,当触发扩容机制的条件时overLoadFactor(hint, B),存储数量/桶的数量>6.5,就会翻倍扩容分配8个新桶。此时hmap中的oldbucket就会记录原来的桶的地址,bucket记录新桶的地址,并且旧桶的数据开始往新桶迁移,迁移的进度会被nevacuate记录,但要注意,map迁移时是用的渐进式迁移,不会一下子全部迁移,那样数据量过大时会有性能影响,所以每次只会迁移一两个桶。
桶满了但没触发扩容条件:
有时候会有这样的情况,当hash运算时,总是往某一个桶里增加数据,以至于桶都满了。这时候溢出桶就会起作用了。当新的数据存储到某个满桶时,这个桶就会链出一个新桶,新桶还可以继续链出新新桶,形成一个链条式的。当查询时也是,经过hash算法找到这个桶发现没有那个key,通过链条找一下溢出桶对比key值是否存在,一直把它找到。