
noi项目中,涉及多个模型(数据表)的多种计数(count值),目前主要包含:
- 习题:题解数、提交数、通过数
- 评论:点赞数、回复数
- 题解:浏览数、点赞数、评论数
用户在使用过程中,会频繁地操作这些计数,比如:点赞、取消点赞、评论、回复、写题解、做题等等,包括读取、写入,写入主要包含递增和递减,如果每次操作都等主业务流程结束后,同步去修改数据库,一是会影响性能,二是会增加数据库锁竞争的开销,所以,将这些琐碎、零散的操作单独提取出来,使用redis作为中间缓存,异步更新数据库是很有必要的。
注意:
- redis使用的是集群模式
- 数据库中,每张表有存储这些计数的字段
由于对这些计数的操作都很简单,要么是读取、要么是递增或递减,不会涉及到业务的处理,所以可以很好地结合redis的incr和decr两个命令来保存这些计数,并通过定时任务,将变化的数据更新到数据库,但是存在以下问题:
- 针对多个模型、不同种类的计数,redis中的key如何设计,才方便业务上识别
- 一次请求,需要同时获取多个计数时,如何只请求一次redis
- 如何判断哪些数据是脏数据,哪些数据需要修改
- 对于缓存中的数据,怎么判断哪些是已经同步到数据库的
- redis故障或数据丢失,如何保证每次操作数据的正确性
key设计
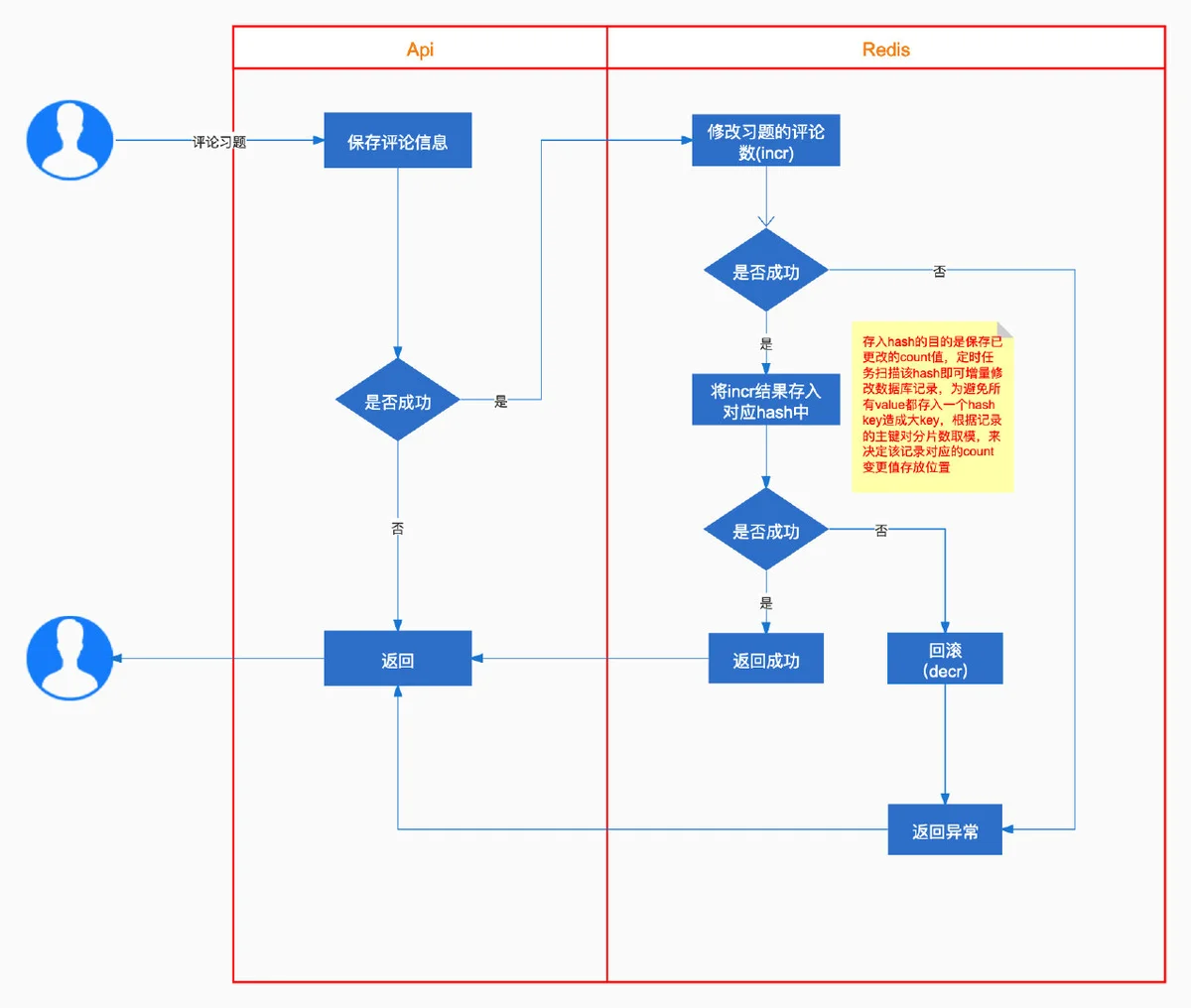
由于涉及到多个模型,并且每个模型含有多种计数需要缓存,只能通过key来做区分,所以可以在key中包含模型名、计数类型、主键id,比如:problems:1001:like_count,这样设计之后,就可以对应上problems表中,id为1001这条记录的like_count字段的值,当页面发起点赞或取消点赞的操作时,只需要incr或decr这个key即可。
但是存在一个问题,查询时,需要同时查询多个count值,比如同时查询一个习题的点赞数、评论数,就要从redis查询两次,key分别为:problems:1001:like_count、problems:1001:comment_count,这两个key经过计算,会被分配到不同的槽位,集群模式下如果跨槽位进行mget的话是不允许的,会报错:
MGET : CROSSSLOT Keys in request don't hash to the same slot
redis中有一个机制,Hash Tag机制:允许用key的部分字符串来计算hash,当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash,所以我们的key可以这么设计:{模型名:模型主键id}:计数类型,这样就可以保证同一条数据对应的不同计数都分配到同一个槽位,在查询是就可以使用mget了。
同步机制
刚开始想的同步机制是通过定时任务,分批扫描数据库,遍历扫描的数据库记录,mget这条记录对应的缓存,对比每一个count值,相同则跳过,不同则认为是脏数据。但是这种方案太重,不管缓存数据有无变化、变化多少,都需要全量扫描数据库,并且在扫描过程中,还会产生新的脏数据。
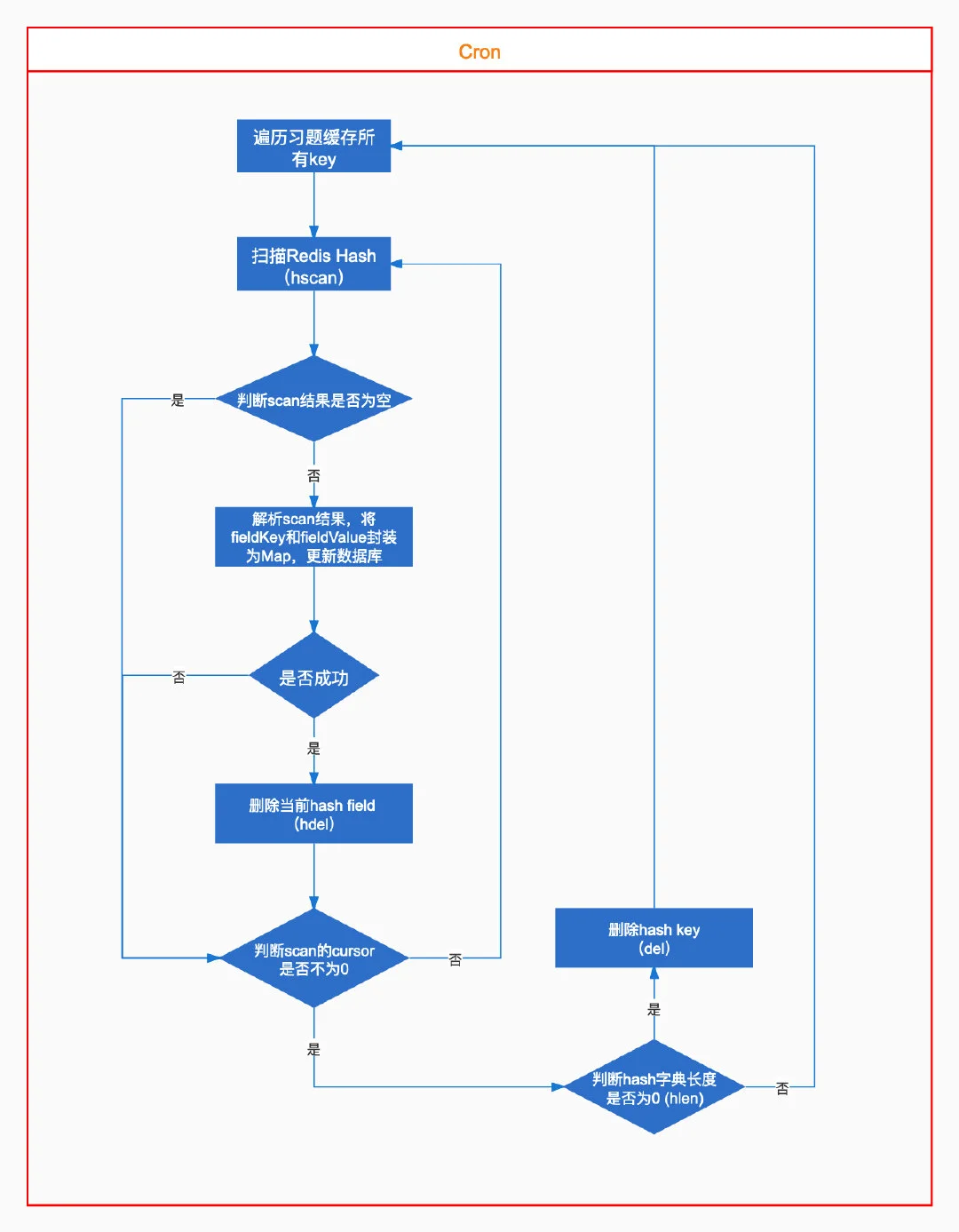
最后采取的方案是:针对每个模型,在redis中再缓存一份数据,使用hash结构,用来记录该模型哪些数据的计数发生了变更,避免一个模型的数据都存到一个hash内成为大key,对每个模型使用的hash key进行分片,比如一个模型分成16个hash key,用模型主键id取模分片数,决定分配到哪个分片
hash中存储的数据结构为:模型主键id-计数类型:count值
总体hash存储的结构举例如下:
problems_1: {
1001-like_count=12,
1001-comment_count=12,
1002-like_count=10
}
这样一来,每次定时任务就遍历所有的hash key,然后对每个hash内的数据进行scan,解析scan的结果,修改数据库即可,每次完成同步操作之后,删除对应的key,这样就保证下次定任务再scan时,不会再重复操作。
如果redis故障或者数据丢失,由于项目内对所有计数都修改都会在查询操作之后,所以统一在查询的时候,如果在缓存中查不到缓存的count值,就将数据库中的count值通过setnx设置到缓存中。
流程图写缓存
定时任务
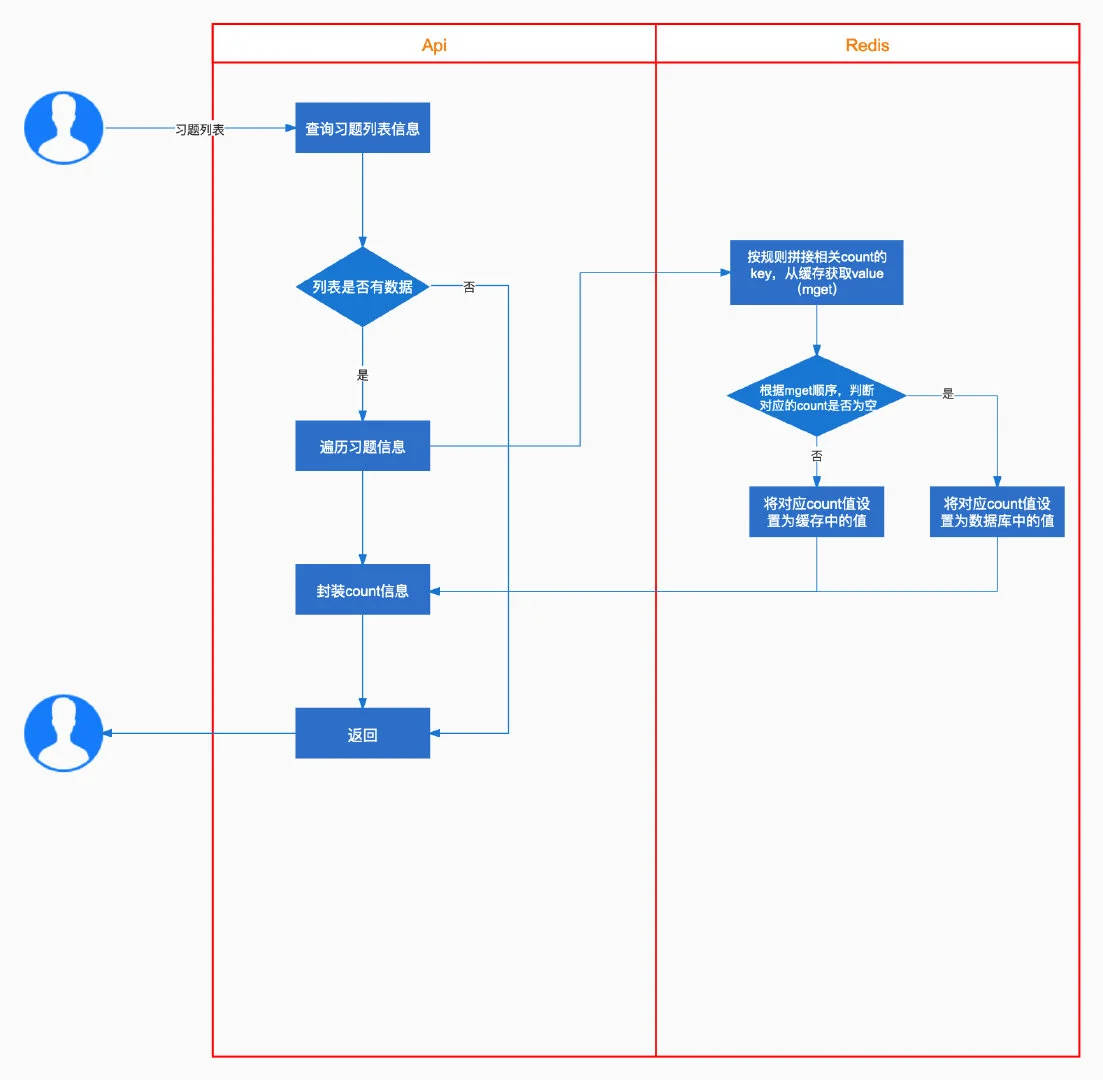
读缓存
相关约定
这里申明了所有模型、计数类型(字段名)的常量,key的生成规则等。
const (
//涉及到count的模型
Problems = "problems"
Solutions = "solutions"
Comments = "comments"
//count相关的字段
LikeCount = "like_count"
DislikeCount = "dislike_count"
CommentCount = "comment_count"
SolutionCount = "solution_count"
PassedCount = "passed_count"
SubmissionCount = "submission_count"
ViewCount = "view_count"
AwesomeCount = "awesome_count"
ConfusedCount = "confused_count"
ReplyCount = "reply_count"
//操作类型
Add = 1 //加
Sub = -1 //减
)
var (
//缓存count的key模板,eg:{problems:1001}:like_count
keyPattern = "{%s:%d}:%s"
//hash字典key模板,eg:problems_1
hashKeyPattern = "%s_%d"
//hash字典域名模板,eg:1001-like_count
hashFieldPattern = "%d-%s"
//redis hash key分片数(避免大key)
KeySliceSize = 16
)
func GetKeyName(modelName string, modelId uint, fieldName string) string {
return fmt.Sprintf(keyPattern, modelName, modelId, fieldName)
}
func GetHashKeyName(modelName string, keySlice int) string {
return fmt.Sprintf(hashKeyPattern, modelName, keySlice)
}
func GetHashFieldName(modelId uint, fieldName string) string {
return fmt.Sprintf(hashFieldPattern, modelId, fieldName)
}
写缓存
这里主要是根据约定将count值,set到对应的key,并记录到hash中
func updateCachedCount(ctx context.Context, modelName, fieldName string, modelId uint, operatorType int) (int64, error) {
var key = types.GetKeyName(modelName, modelId, fieldName)
var resultCount int64
var err error
//1.修改缓存中count的值
if operatorType == types.Add {
resultCount, err = db.Incr(ctx, key)
} else {
resultCount, err = db.Decr(ctx, key)
}
if err != nil {
return resultCount, err
}
//2.count修改成功后,修改对应的hash字典,该字典就用来表示发生变化的数据
//2.1.根据id,找到hash字典的分片key
var hashKey = types.GetHashKeyName(modelName, int(modelId)%types.KeySliceSize)
var hashFieldName = types.GetHashFieldName(modelId, fieldName)
//eg: hset problems_1 1001-like_count 10
_, err = db.HSet(ctx, hashKey, hashFieldName, resultCount)
if err != nil {
//手动回滚(没用redis事务:redis的事务只是将命令打包执行,并不能保证原子性)
var e1 error
if operatorType == types.Add {
resultCount, e1 = db.Decr(ctx, key)
} else {
resultCount, e1 = db.Incr(ctx, key)
}
if e1 != nil {
return resultCount, err
}
return resultCount, err
}
return resultCount, err
}
定时任务
在main函数中开启定时任务:
// scan redis count to mysql
go task.ExecuteCron(context.Background())
定时任务:使用github.com/robfig/cron/v3实现
func ExecuteCron(ctx context.Context) {
c := newWithSeconds()
//定时任务:如果没有配置,默认每小时执行一次
spec := configs.Config.Cron.Spec
if spec == "" {
spec = "@every 1h"
}
var e error
//习题相关
_, e = c.AddFunc(spec, func() {
service.ScanChangedCountAndUpdateDB(ctx, types.Problems)
})
if e != nil {
klog.Error(e)
}
//题解相关
_, e = c.AddFunc(spec, func() {
service.ScanChangedCountAndUpdateDB(ctx, types.Solutions)
})
if e != nil {
klog.Error(e)
}
//评论相关
_, e = c.AddFunc(spec, func() {
service.ScanChangedCountAndUpdateDB(ctx, types.Comments)
})
if e != nil {
klog.Error(e)
}
c.Start()
}
//在linux环境下,cron表达式不支持秒级别的,需要设置下
func newWithSeconds() *cron.Cron {
secondParser := cron.NewParser(cron.Second | cron.Minute |
cron.Hour | cron.Dom | cron.Month | cron.DowOptional | cron.Descriptor)
return cron.New(cron.WithParser(secondParser), cron.WithChain())
}
扫描hash key
func ScanChangedCountAndUpdateDB(ctx context.Context, modelName string) {
var hashKey string
//遍历每个分片
klog.Infof("Scan redis count cache of [%s] starting...", modelName)
start := time.Now()
for i := 0; i < types.KeySliceSize; i++ {
hashKey = types.GetHashKeyName(modelName, i)
var cursor uint64
for {
fields, cur, err := db.HScan(ctx, hashKey, cursor, "*-*_count", 10)
cursor = cur
if err != nil {
klog.Errorf("HScan Error:%q", err)
break
}
handleScannedData(fields, modelName, ctx, hashKey)
if cursor == 0 {
break
}
}
//key对应的缓存都scan完毕后,删除key
size, _ := db.HLen(ctx, hashKey)
if size != 0 {
_, e := db.Del(ctx, hashKey)
if e != nil {
klog.Errorf("删除key失败:%s , [error]:%q", hashKey, e)
}
}
}
cost := time.Now().Sub(start).Seconds()
klog.Infof("Scan redis count cache of [%s] finished,cost: [%.2f] second", modelName, cost)
}
解析扫描的数据
func handleScannedData(fields []string, modelName string, ctx context.Context, hashKey string) {
var id int
var fieldName string
var fieldValue int
var param = make(map[string]interface{})
for i, key := range fields {
//所有的k-v会封装为[]string返回:当前index为key index+1就为value
if strings.Contains(key, "count") {
split := strings.Split(key, "-")
id, _ = strconv.Atoi(split[0])
fieldName = split[1]
//val, _ := db.HGet(ctx, hashKey, fieldName)
fieldValue, _ = strconv.Atoi(fields[i+1])
//封装为Map,更新数据库
param[fieldName] = fieldValue
err := updateDB(modelName, uint(id), param)
if err != nil {
klog.Errorf("更新数据库Count失败,表名:%s, ID:%d, 参数:%s , [error]:%q", modelName, id, param, err)
return
}
//如果没有发生异常,删除hash的field
_, _ = db.HDel(ctx, hashKey, fieldName)
}
}
}
修改数据库(这一步违反了开闭原则,可优化)
func updateDB(modelName string, id uint, param map[string]interface{}) error {
var err error
switch modelName {
case types.Problems:
var problem = &model.Problem{ID: id}
err = problem.UpdateByMap(param)
case types.Solutions:
var solution = &model.Solution{ID: id}
err = solution.UpdateByMap(param)
case types.Comments:
var comment = &model.Comment{ID: id}
err = comment.UpdateByMap(param)
}
return err
}
gorm部分举例:
func (cmt *Comment) UpdateByMap(params map[string]interface{}) error {
conn := db.GetDBConnection()
return conn.Model(cmt).Updates(params).Error
}
读缓存
该方案不足的点,每次读取时,去查询缓存时,需要交互多次
var data []interface{}
var likeCountKey string
var replyCountKey string
//list为从数据库查询的列表
for i, value := range list {
likeCountKey = types.GetKeyName(types.Comments, value.ID, types.LikeCount)
replyCountKey = types.GetKeyName(types.Comments, value.ID, types.ReplyCount)
//点赞数、回复数
ret, err := db.MGet(ctx, likeCountKey, replyCountKey)
if err != nil {
klog.Errorf("QueryCommentByConditionPage.MGet Error:%q", err)
} else {
list[i].LikeCount = uint(db.CheckRedisExist(ctx, likeCountKey, ret[0], int(value.LikeCount)))
list[i].ReplyCount = db.CheckRedisExist(ctx, replyCountKey, ret[1], value.ReplyCount)
}
data = append(data, list[i])
}
判断缓存中是否有值,没有则以数据库中的为准
func CheckRedisExist(ctx context.Context, key string, redisValue interface{}, dbValue int) int {
var count int
//如果缓存中没有,将数据库中的值set到缓存
if redisValue == nil {
_, _ = SetStrNxCacheTtl(ctx, key, dbValue, 0)
count = dbValue
} else {
c, _ := strconv.Atoi(redisValue.(string))
count = c
}
return count
}