
靠人终究靠不住
不知道大家是怎么处理开头提到的那种问题的呢?最简单粗暴的办法就是把相关人员集中到一个会议室里面对数据,怎么对呢?
客户端开发人员:我查了日志,客户端的请求过程一共用了5s,请求是从几点几分几秒发起的,你们查下服务端的日志;
交易系统开发人员:我这边是几点几分几秒收到的请求,交易系统一共花了4s多一些,其中调用支付网关花了将近4s,网关那边看下日志吧;
网关开发人员:我这边是几点几分几秒收到的请求,网关一共花了3s多一点,大部分时间都花在了调用第三方上;
估计大多数人最开始都是这么处理此类问题的,简单粗暴。但如果三天两头给你来这么一下子你还受得了吗?每天给你几百个上千个订单号让你对数据,你还能抽时间写代码吗?估计连带薪上厕所的时间都没了吧。最后这个问题可能传到了领导那里,领导一般喜欢要全局报表数据,你怎么给他出这个报表?是不是束手无策,突然有点想换工作了,哈哈。我们还真是接到过这种需求,一堆人在那里awk然后就没有然后了。
“当一件事情成为一件常态,那意味着我们可能需要一件工具来解放自己了,靠人终究是靠不住的”,就在这种背景之下我们决定引入一个调用链追踪的工具来解放我们,也就是今天的主角jaeger。关于jaeger的说明网上很多,推荐去官网系统的了解一下 https://www.jaegertracing.io,我这里只是把搭建过程和使用上的一些心得分享出来和大家一起交流。
背景
随着应用容器化和微服务的兴起,借由Docker和 Kubernetes 等工具, 服务的快速开发和部署成为可能,构建微服务应用变得越来越简单。但是随着大型单体应用拆分为微服务,服务之间的依赖和调用变得极为复杂,这些服务可能是不同团队开发的,可能基于不同的语言,微服务之间可能是利用RPC, RESTful API, 也可能是通过消息队列实现调用或通讯。如何理清服务依赖调用关系,如何在这样的环境下快速debug, 追踪服务处理耗时,查找服务性能瓶颈, 合理对服务的容量评估都变成一个棘手的事情。
Tracing在微服务中的作用
和传统单体服务不同, 微服务通常部署在一个分布式的系统中, 并且一个请求可能会经过好几个微服务的处理, 这样的环境下错误和性能问题就会更容易发生, 所以观察(Observe)尤为重要,
这就是Tracing的用武之地, 它收集调用过程中的信息并可视化, 让你知道在每一个服务调用过程的耗时等情况, 以便及早发现问题.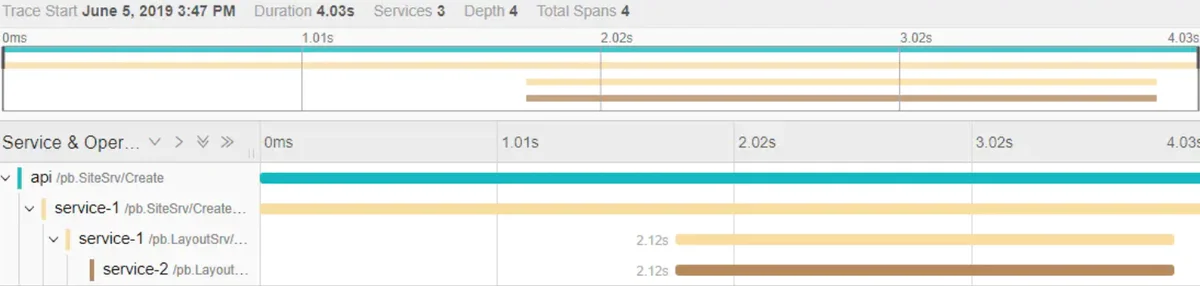
在上图可以看到api层一共花了4.03s, 然后其中调用其他服务: 'service-1'花了2.12s, 而service-1又调用了'service-2'花费了2.12s, 用这样的图示很容易就能排查到系统存在的问题. 在这里我只展示了时间, 如果需要追踪其他信息(如错误信息)也是可以实现的.
为什么是Jaeger
OpenTracingserverjaegerjaegergolang特点
golangjaeger能够解决以下问题
- 分布式事务监控
- 性能分析与性能优化
- 调用链,找到根源问题
- 服务依赖分析(需大数据分析)
安装需了解的技术栈:
- OpenTracing
- Golang
- ElasticSearch
- Kafka (可选)
OpenTracing 标准
云原生基金会(CNCF) 推出了 OpenTracing 标准,推进Tracing协议和工具的标准化, 统一 Trace 数据结构和格式。 OpenTracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。比如从Zipkin替换成Jaeger/Skywalking等后端。
在OpenTracing中,有两个主要概念:
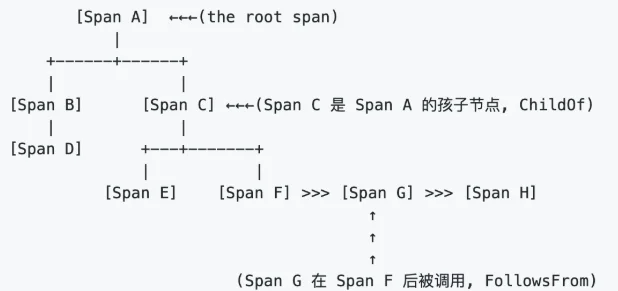
1、Trace(调用链): OpenTracing中的Trace(调用链)通过归属于此调用链的Span来隐性的定义。一条Trace(调用链)可以被认为是一个由多个Span组成的有向无环图(DAG图), Span与Span的关系被命名为References。
2、Span(跨度):可以被理解为一次方法调用, 一个程序块的调用, 或者一次RPC/数据库访问. 只要是一个具有完整时间周期的程序访问,都可以被认为是一个Span。
单个Trace中,Span间的因果关系如下图:
这里使用目前比较流行的Tracing开源方案Jaeger进行实践,使用jaeger-client-go这个库作为client
github地址:GitHub - jaegertracing/jaeger-client-go: Jaeger Bindings for Go OpenTracing API.
jaeger架构
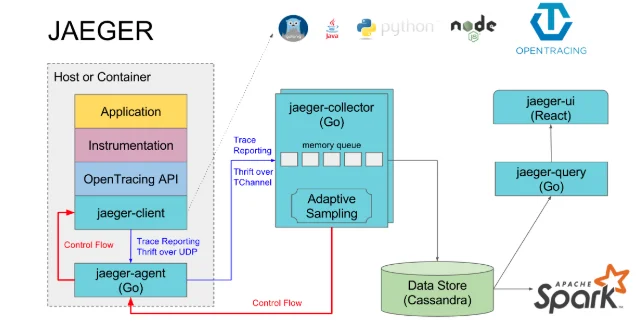
jaeger组件介绍:
jaeger-client:jaeger 的客户端,实现了opentracing协议;
jaeger-agent:jaeger client的一个代理程序,client将收集到的调用链数据发给agent,然后由agent发给collector;
jaeger-collector:负责接收jaeger client或者jaeger agent上报上来的调用链数据,然后做一些校验,比如时间范围是否合法等,最终会经过内部的处理存储到后端存储;
jaeger-query:专门负责调用链查询的一个服务,有自己独立的UI;
jaeger-ingester:中文名称“摄食者”,可用从kafka读取数据然后写到jaeger的后端存储,比如Cassandra和Elasticsearch;
spark-job:基于spark的运算任务,可以计算服务的依赖关系,调用次数等;
其中jaeger-collector和jaeger-query是必须的,其余的都是可选的,我们没有采用agent上报的方式,而是让客户端直接通过endpoint上报到collector。
官方文档的demo:example
首先,本地起一个jaeger服务作为测试用的服务端,官方提供了”All in One”的docker镜像, 启动Jaeger服务只需要一行代码:
本人使用下载好的golang二进制文件启动的,jaeger官网地址:https://www.jaegertracing.io/downlo
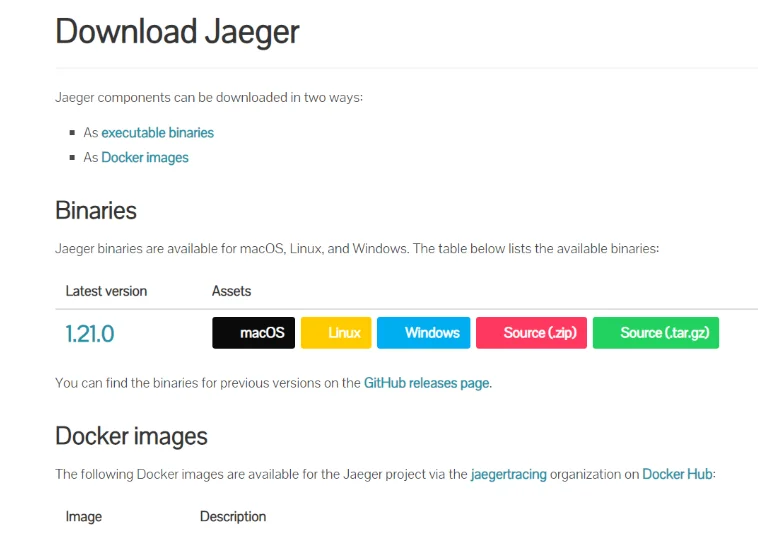
jaeger的二进制发行包包含五个二进制文件:
- jaeger-agent
- jaeger-collector
- jaeger-query
- jaeger-standalone
- jaeger-ingester
如果没有执行权限,可以使用
- chmod a+x jaeger-*
选择存储
ESCanssandrastart-collector.sh
- export SPAN_STORAGE_TYPE=elasticsearch
start-agent.sh
- export SPAN_STORAGE_TYPE=elasticsearch
- nohup .\jaeger-agent.exe --reporter.grpc.host-port=192.168.1.234:14250 --log-level=debug > agent.log 2>&1 &
start-query.sh
- export SPAN_STORAGE_TYPE=elasticsearch
- nohup ./jaeger-query --span-storage.type=elasticsearch --es.server-urls=http://10.66.177.152:9200/ > query.log 2>&1 &
部署方式
jaeger有两种部署方式。下面一一介绍。如果你的数据量特别多,使用kafka缓冲一下也是可以的(所以就引入了另外一个组件jaeger-ingester),不多做介绍。
简易环境
这种方式一般用在dev环境或者其他测试环境。只需要部署一个单一节点即可。我们的app,需要手动填写agent的地址,这个地址一般都是固定的。
这些环境的流量很小,一个agent是足够的。
生产环境
上面这种部署方式,适合生产环境。agent安装在每一台业务机器上。Client端的目标agent只需要填写localhost即可。
这种方式的好处是生产环境的配置非常的简单。即使你的机器是混合部署的,也能正常收集trace信息。
调用关系图
jaeger的调用关系图是使用spark任务进行计算的。项目地址为:
https://github.com/jaegertracing/spark-dependencies
端口整理
Agent
- 5775 UDP协议,接收兼容zipkin的协议数据
- 6831 UDP协议,接收兼容jaeger的兼容协议
- 6832 UDP协议,接收jaeger的二进制协议
- 5778 HTTP协议,数据量大不建议使用
它们之间的传输协议都是基于thrift封装的。我们默认使用5775作为传输端口
Collector
- 14267 tcp agent发送jaeger.thrift格式数据
- 14250 tcp agent发送proto格式数据(背后gRPC)
- 14268 http 直接接受客户端数据
- 14269 http 健康检查
Query
- 16686 http jaeger的前端,放给用户的接口
- 16687 http 健康检查
至此,我们的jaeger就安装完毕。
以上,就是我们的环境准备。有了一个server接收数据,调用链的主要工作就在于客户端开发
接下来,代码时间, 参考项目的Readme和搜索引擎不难写出以下代码
1,最简单的使用模式
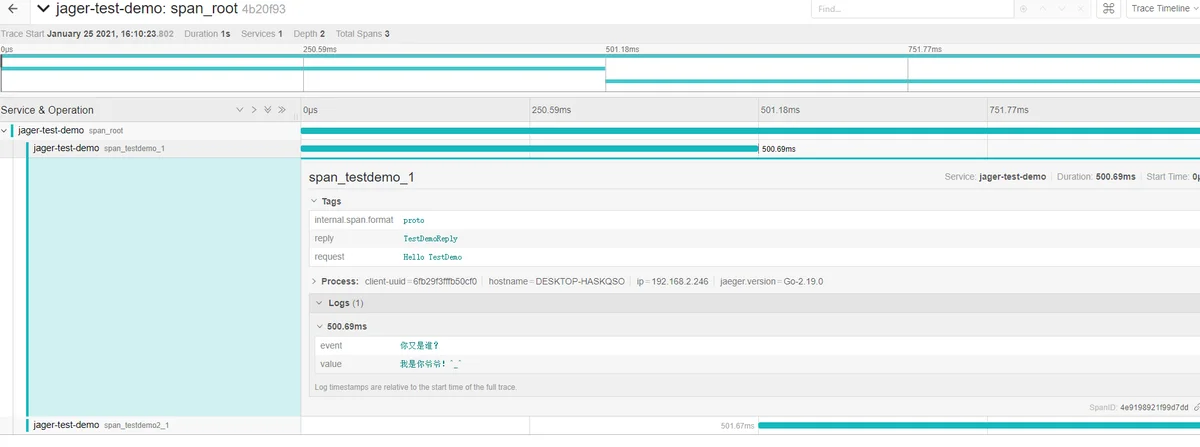
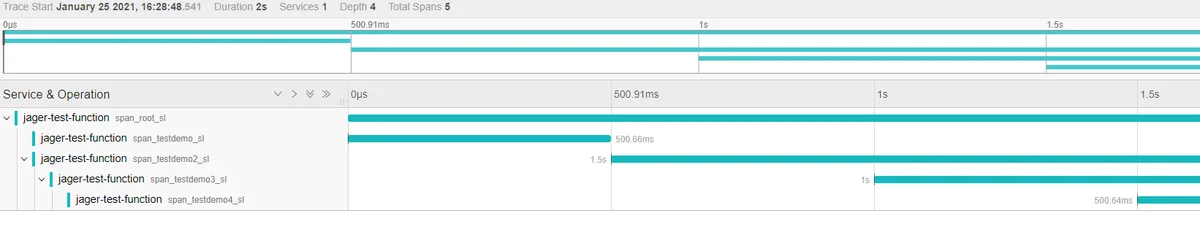
2,多个函数之间调用
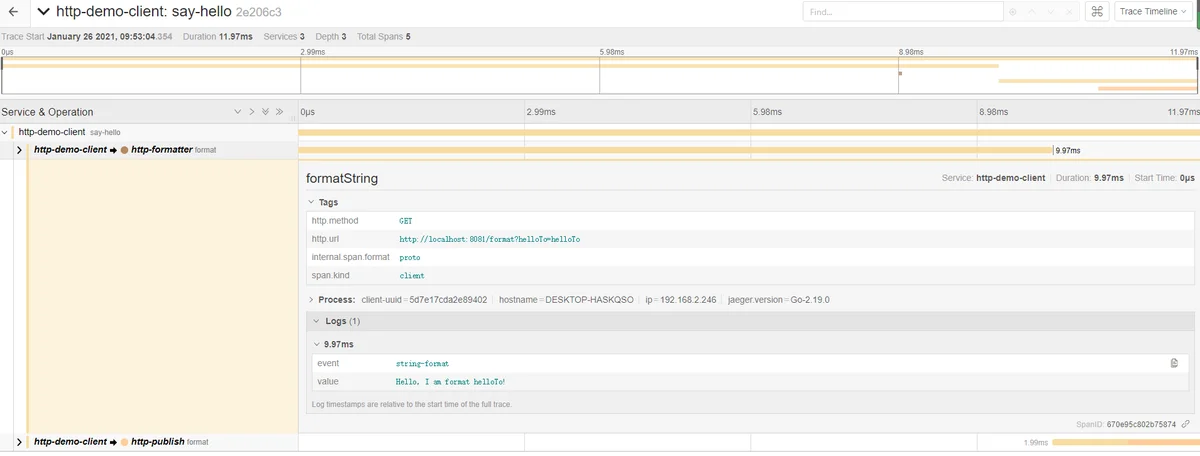
3,http请求

clinet中同步请求:8081/format,:8088/publish
4,grpc请求-追踪网络调用
在上面例子中,http之间的链路追踪,我们发现是通过header传递traceI的,但是在grpc中怎么传递呢?
grpc底层采用http2协议也是支持传递数据的,采用的是metadata,
Metadata 对于 gRPC 本身来说透明, 它使得 client 和 server 能为对方提供本次调用的信息。
就像一次 http 请求的 RequestHeader 和 ResponseHeader,http header 的生命周期是一次 http 请求, Metadata 的生命周期则是一次 RPC 调用。
Prod.proto
gprc-客户端:
生成文件:
gprc-服务端
生成文件
运行客户端:
运行服务端:
最终显示查询结果:
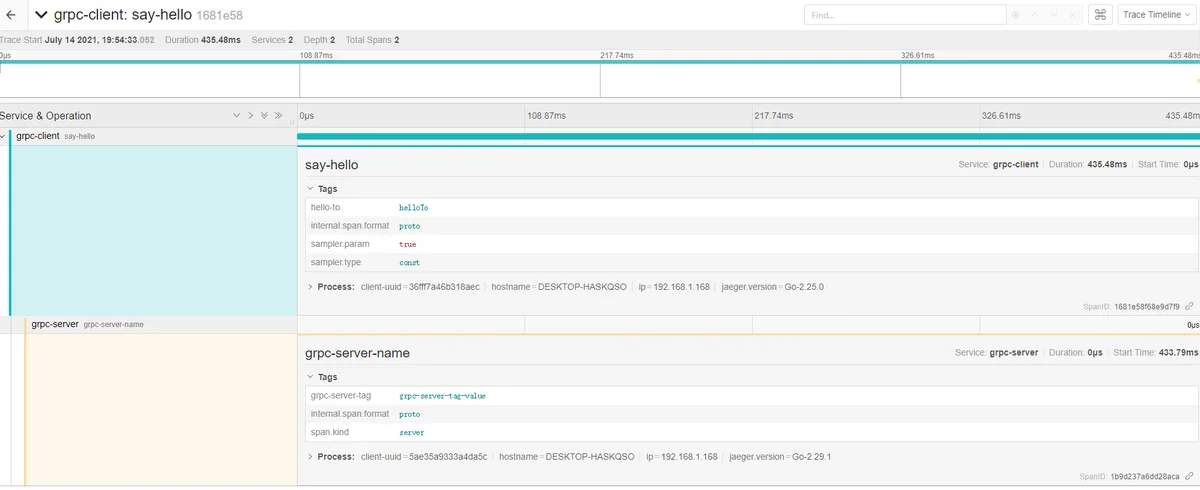
gin中间件中链路追踪http中间件 gprc中间件待完善中