
前言
平时使用 Golang 开发的小伙伴一定知道,Go 语言在进行高并发变成是极其容易的,因为 Go 语言自身就支持了多协程。但是 Go 语言的数据结构大多都不具备 scalable,无论是使用锁+hmap,还是使用并发安全的 sync.Map,在高并发场景下,程序都会随着协程数量的增加导致性能下降。所以编写支持高并发且具备 scalable 的数据结构就显得尤为重要。
并发安全问题
当多个 goroutine(协程) 同时访问相同的变量且具有写操作时,就会发生未定义行为,也就是会产生 data race。
Golang 也为解决 data race 提供了两种解决方案:
- atomic 库,迫使写入操作变为原子操作,就不会发生错误。
- 互斥锁-sync.Mutex,通过访问限制,来实现并发安全。
在不同场景下,会对应到不同的解决方案:
- 单变量,一写多读 -> atomic
- 单变量,多写多读 -> sync.Mutex
- 多变量,多谢多读 -> sync.Mutex
Go 提供了一个 data race 的检测工具,即在运行或编译时使用 -race 参数,程序运行后如果有 data race 的行为,就会打印日志提示开发者改进代码。
有序链表的并行化
从本次实现的有序链表对于并发数据结构的理念和思想出发,并发数据结构的目标为:
- 并发安全,不会产生 data race。
- 随着 CPU 核数的增加,性能会越来越高。
对于有序链表且要求并发安全,直观的想法是使用 sync.Mutex 来防止 data race。但是在大多场景下,链表的读操作都是远大于写操作的,所以可以使用 sync.RWMutex 读写锁来代替互斥锁,提高读的性能。
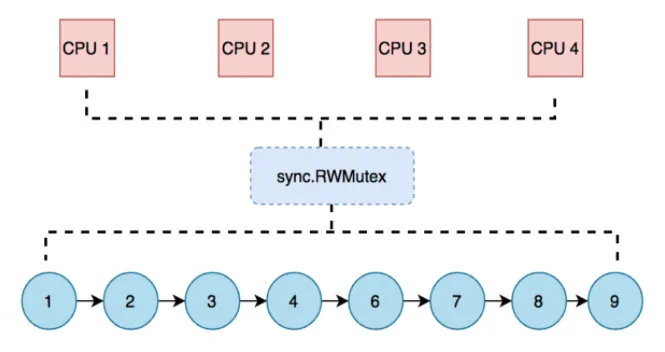
但是根据上图来看,仅仅只是并发读时,可以利用多核性能;但是在并发写时,还是多个协程争抢一把锁,性能还是没有提升。
区域猜想
在上面的场景中,整个数据结构共享一把读写锁,在全局只有一个 CPU 可以进行写入操作,那么就可以猜想一下,是否可以有一种方法,使不同的 CPU 负责不同的区域,写操作由负责该区域的 CPU 负责,那么就可以多个 CPU 并发写了,就提高性能了。
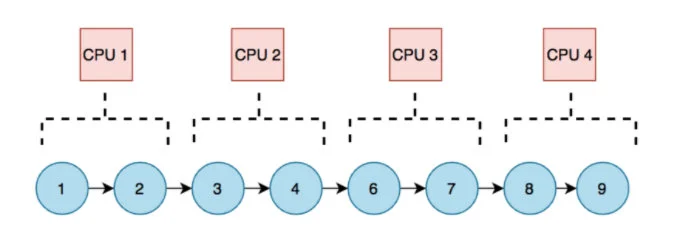
对于这种猜想,有个关键性的问题:怎么才能确定哪个 CPU 负责哪个区域呢?
并且,如果按照数量或大小分区,平均让每个 CPU 负责一个区域是行不通的。如果分配后某个 CPU 一直都是插入操作,而另一个 CPU 一个负责删除操作呢?那就会造成区域的负载分布不均,可能需要复杂的 rebalancing。
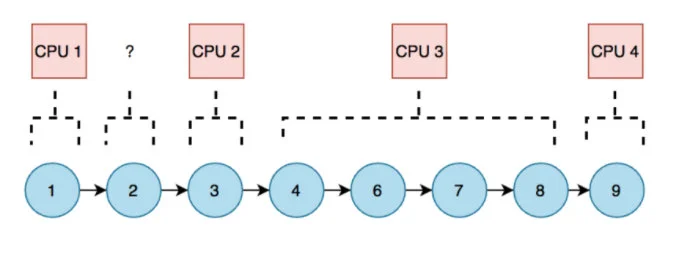
所以,我们希望分割区域最好的动态抢占的,并且区域间有明显的分割。
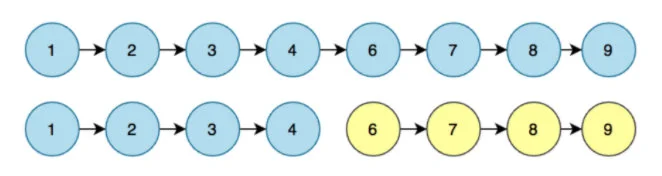
其实可以从单链表的特性出发,我们可以发现,单链表某个节点的后继指针是链表两端区域的唯一联系,也就是说:
- 某节点的后继指针置空,则可以产生两个完成且毫无关联的链表。
- 链表的后半部分是无法感知前半部分的。
对于第一点,我们认为节点及其后续指针这个区域是这个链表的最小不可分割区域,其特点为:
- 有明显界限。后继指针在节点内,且后继指针是前后节点的唯一联系。
- 可动态组合,即可动态抢占。
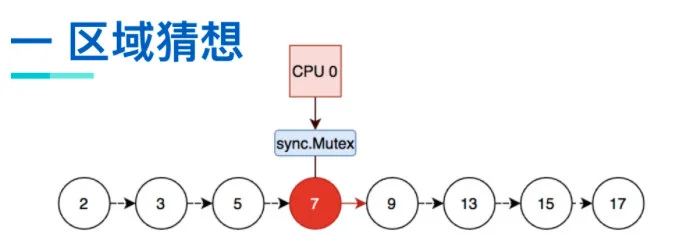
那么此时我们就可以得出猜想,如果一个 CPU 锁定了一个节点及其后继指针,那么他就控制了这个节点和其后继指针,此时只有该 CPU 有权限在这个区域内进行写操作。
并发插入
对于上述猜想,我们来设计一下插入操作。
version 1
- 找到节点 A 和 B ,不存在则直接返回。
- 锁定节点 A。
- 创建节点 X。
- X.next = B; A.next = X
- 解锁节点
对于 version 1 插入版本,会有一个不太明显的问题。第一步时先找到节点 A 和 B,那么在上锁之前的这段时间,如果 A 节点被删除、B 节点被前插入新的节点等等其他情况时,那么这次插入就是错误的。
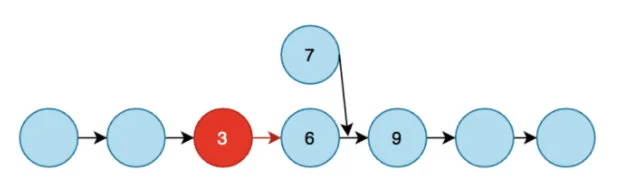
比如上图,假设有两个协程同时找到了 A:3 B:9 ,协程 1 在 A 和 B 之间插入了 7,组成 3->7->9,协程 2 又会插入 6,组成 3->6->9。这就导致了错误。所以 version 1 的插入方式是不合理的。
我们应该在上锁之后进行一次 double check,检查是否满足 A.next == B ,如果不满足,需要跳转到步骤 1,重新寻找 A 和 B。
version 2
- 找到节点 A 和 B ,不存在则直接返回。
- 锁定节点 A,检查 A.next == B, 为假则返回步骤 1。
- 创建节点 X。
- X.next = B; A.next = X
- 解锁节点
并发删除
并发删除稍微比并发插入复杂一点点~
老样子,还是先看一个简单的版本:
version 1
- 找到节点 A 和 B,不存在则直接返回。
- 锁定节点 A,检查 A.next == B,为假则返回步骤 1 。
- A.next = B.next
- 解锁节点 A 。
最直观的一点是,虽然我们锁定了节点 A,但是并没有锁定节点 B,那么在执行 A.next = B.next 的时候,B.next 的值是不确定的,赋值给 A.next 的值居然是一个不确定的值,那么这是不可接受的。所以我们也需要锁定 B 节点。
version 2
- 找到节点 A 和 B,不存在则直接返回。
- 锁定节点 B。
- 锁定节点 A,检查 A.next == B,为假则返回步骤 1 。
- A.next = B.next
- 解锁节点 A 和 B。
先锁定 B 节点是因为我们需要保证 B.next 不会被其他协程改变。但是 version 2 依然存在问题,我们考虑以下场景:
- A1,B1 为执行删除操作的Goroutine1(G1)需要占领的区域
- A2,B2 为执行删除操作的Goroutine2(G2)需要占领的区域
- 两个待删除的节点B1,B2相邻,故B1和A2重合,用B1(A2)表示该节点

若G2优先拿到了锁B1(A2),B2,则程序能正确删除。
但如果G1先拿到了B1(A2)节点的锁,A1节点执行A1.next = B1.next,此时A1的后继指针指向B2。G1执行完释放A1,B1(A2)后,G2获取B1(A2),B2的锁,执行A2.next = B2.next,可以看到此时B1已经脱离了链表了,B2无法正确删除,而我们程序执行预期是同时删除B1和B2。
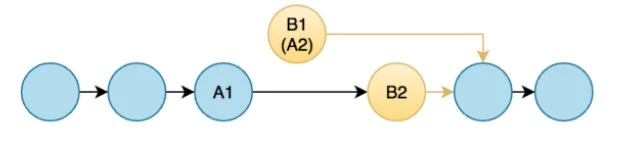
为了避免上个问题,我们需要对节点引入一个标记位,在删除B1(A2)时先对其进行标记删除,链表在并发执行其他操作(增、删、读)时需要先对标志位进行校验,防止我们在找节点A,B的时候找到错误的已经被删除的节点。
version 3
- 找到节点 A 和 B,不存在则直接返回。
- 锁定节点 B,检查 B.marked == true ,如果为真,则解锁 B,返回步骤 1。
- 锁定节点 A,检查 A.next != B or A.marked,为真则解锁 A 和 B返回步骤 1 。
- B.marked = true; A.next = B.next
- 解锁节点 A 和 B。
并发读
在实现完并发写操作后,并发读的实现就变得很容易了。
我们只需要在可能发生一写多读的区域,使用atomic.Load读取值,atmoic.Store存储值即可保证并发读的正确性。
叮~🔔