1. 背景
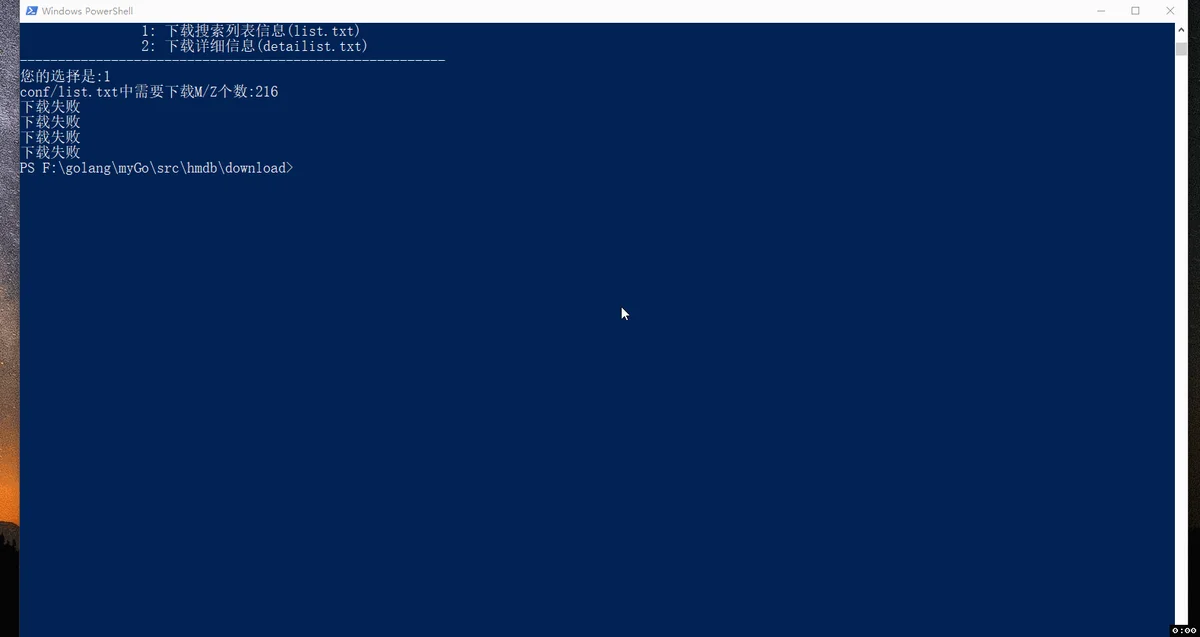
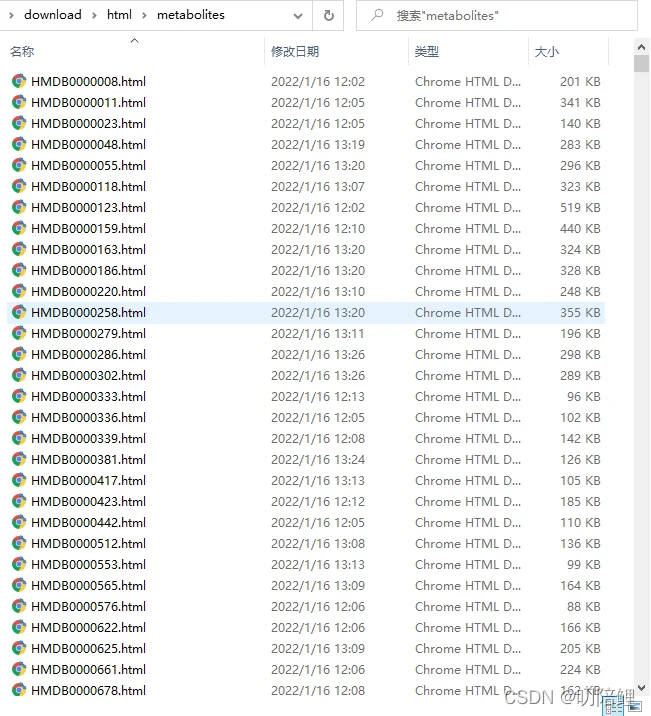
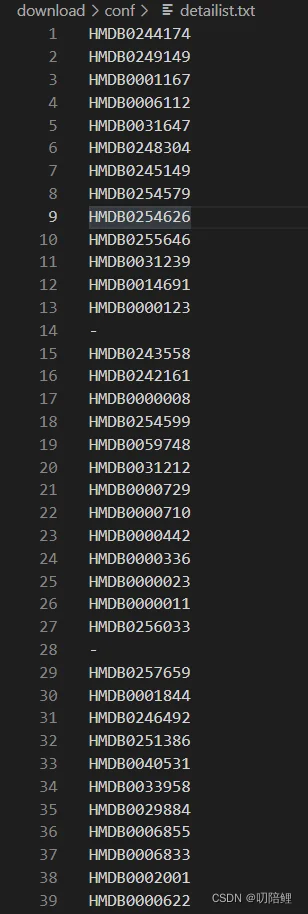
周末花了两天写了一个爬取、并解析HMDB数据库的工具,为了能够根据下载定义HMDB-ID的数据信息,我特意将涉及到的HMDB-ID存储到一个list.txt文件中,然后逐行读取list.txt文件,将读取到的接口拼接完成的URL后进行访问、下载。 文件中可以根据需要放很多ID,几百上千条是没有问题的。
2. 实现
以下代码中创建了很多的gorouting, 通过chan来判断是否结束。不过今天看书,书上说推荐使用WaitGroup变量来解决这种问题。有时间再试试waitgroup看看效果
func ReadFile(fileName string) {
fileName = "conf/" + fileName
chanNum := GetFileLines(fileName)
f, err := os.Open(fileName) <------------------
if err != nil {
fmt.Println(err.Error())
return
}
buf := bufio.NewScanner(f) <------------------
chs := make([]chan int, chanNum)
for i := 0; i < chanNum; i++ {
if !buf.Scan() { <------------------
break
}
line := buf.Text() <------------------
chs[i] = make(chan int)
switch fileName {
case "conf/list.txt":
go Gethtml(line, chs[i])
case "conf/detailist.txt":
go GetHmdbDetail(line, chs[i])
default:
fmt.Println("文件名称有误")
return
}
time.Sleep(500 * time.Millisecond)
}
for _, ch := range chs {
<-ch
}
}
3. HMDB爬虫工具效果