
声明:面经从网络上搜集,自己补充了答案,不保证准确。
最近秋招启动的公司越来越多了。现在开始每天刷刷面经。欢迎点击此处关注公众号。
这里还有一个米哈游大数据开发一二面面经。
米哈游大数据开发一二面面经
1、自我介绍
2、你这些实习好像都很短啊,原因是什么?
3、讲一下 xxx 公司实习的内容吧。
- oncall:就是查 bug,线上出问题了会找到你。怎么查这个 bug 呢,这就是追溯,可以后面写文章详细讨论。
- 重构:以前的表换了,比如 dwd 层一张表换成了另一张表,你下游的 dws、app 是不是都得变。这里就会产生数据一致性问题,面试经常问数据一致性,这里后面详细讨论。
- 开发迭代需求:在已有的需求基础上迭代,修改一些原来已经存在的代码。这里就需要你读懂前人的代码逻辑…
- 开发新需求:这个工作周期长,难度大,需要和 PM、QA、RD、UI 等等很多人合作。这里后面细说。
- 回溯:这个工作占比很大,比如你产出了 app 层的表,修改了其中的口径(可以理解为字段的计算逻辑),那么修改完后是不是的重跑历史数据,这并不是点一下运行就能完事的。后面再详细讨论。
- 同步:怎么把 Hive 的数据推导 Elasticsearch 或者 ClickHouse 让线上能够使用?
- 看书:《Hive 编程指南》
4、Spark 的宽窄依赖了解么?
- 定义:在 DAG 调度中需要对计算过程划分 stage,而划分依据就是 RDD 之间的依赖关系。针对不同的转换函数, RDD 之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency)。
- 窄依赖是指父 RDD 的每个分区只被子 RDD 的一个分区所使用,子 RDD 分区通常对应常数个父 RDD 分区(O(1),与数据规模无关)
- 宽依赖是指父 RDD 的每个分区都可能被多个子 RDD 分区所使用,子 RDD 分区通常对应所有的父 RDD 分区(O(n),与数据规模有关)
- 如何划分:有 Shuffle 的是宽依赖。
5、Spark 中的 RDD、DataFrame、DataSet 的区别?
| 标准 | Spark Datasets | Spark Dataframes | Spark RDDs |
|---|---|---|---|
| 数据表示 | Spark Datasets 是 Dataframe 和 RDD 的组合,具有静态类型安全和面向对象接口等特性。 | Spark Dataframe 是组织成命名列的分布式数据集合。 | Spark RDD 是一个没有模式的分布式数据集合。 |
| 优化 | Datasets 使用催化剂优化器进行优化。 | Dataframes 使用催化剂优化器进行优化。 | 没有内置的优化引擎。 |
| 模式投影 | Datasets 使用 SQL 引擎自动查找模式。 | Dataframes 也会自动找到模式。 | Schema 需要在 RDD 中手动定义。 |
| 聚合速度 | 数据集聚合比 RDD 快,但比 Dataframes 慢。 | 由于提供了简单而强大的 API,Dataframe 中的聚合速度更快。 | 在执行数据分组等简单操作时,RDD 比数据帧和数据集都慢。 |
6、Spark 中的 map 和 flatMap 的区别是什么?
- map 的作用是对 rdd 之中的元素进行逐一进行函数操作映射为另外一个 rdd。即对每一条输入进行指定的操作,然后为每一条输入返回一个对象;
- flatMap 的操作是将函数应用于 rdd 之中的每一个元素,将返回的迭代器的所有内容构成新的 rdd。即先映射后扁平化,最后合并成一个对象。
rdd=sc.parallelize([1,2,3])
rdd.collect()
# [1,2,3]
rdd1=rdd.map(lambda:range(x,3))
rdd1.collect()
# [[1,2],[2],[]]
rdd2=rdd.flatMap(lambda:range(x,3))
rdd2.collect()
# [1,2,2]
7、Spark 中的 groupByKey、reduceByKey、aggregateByKey 的区别?
groupByKey 和 reduceByKey:
- 从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
- 从功能的角度:reduceByKey 其实包含分组和聚合的功能。groupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey。
reduceByKey 和 aggregateByKey:
- reduceByKey 可以认为是 aggregateByKey的简化版;
- aggregateByKey 分为三个参数,多提供了一个函数 Seq Function,可以控制如何对每个 partition 中的数据进行先聚合,然后才是对所有partition中的数据进行全局聚合。
8、一个完整的 MapReduce 整个有哪些过程?这些过程中哪些会用到排序呢?
过程:
- Map 阶段:提交待处理文本,任务规划,提交到Yarn,算出 MapTask 数量,TextInputFormat 读数据,在 Maptask 中进行逻辑运算,把输入变成 kv 键值对,分区方法将数据标记好分区,outputCollector 把数据输出到环形缓冲区。
- shuffle 阶段:环形缓冲区达到 80% 溢写,溢写前对 key 的索引快排,溢写文件归并排序,也可 combiner,最后按分区存到磁盘。
- Reduce 阶段:拉取分区的数据,先存到内存,不够再存磁盘,拉完后归并排序。这里拉取数据是按照 key 进行 hash,相同的 key 会进入同一个 reduceTask,大量热点 key 进入同一个 reducetask 可能产生数据倾斜。
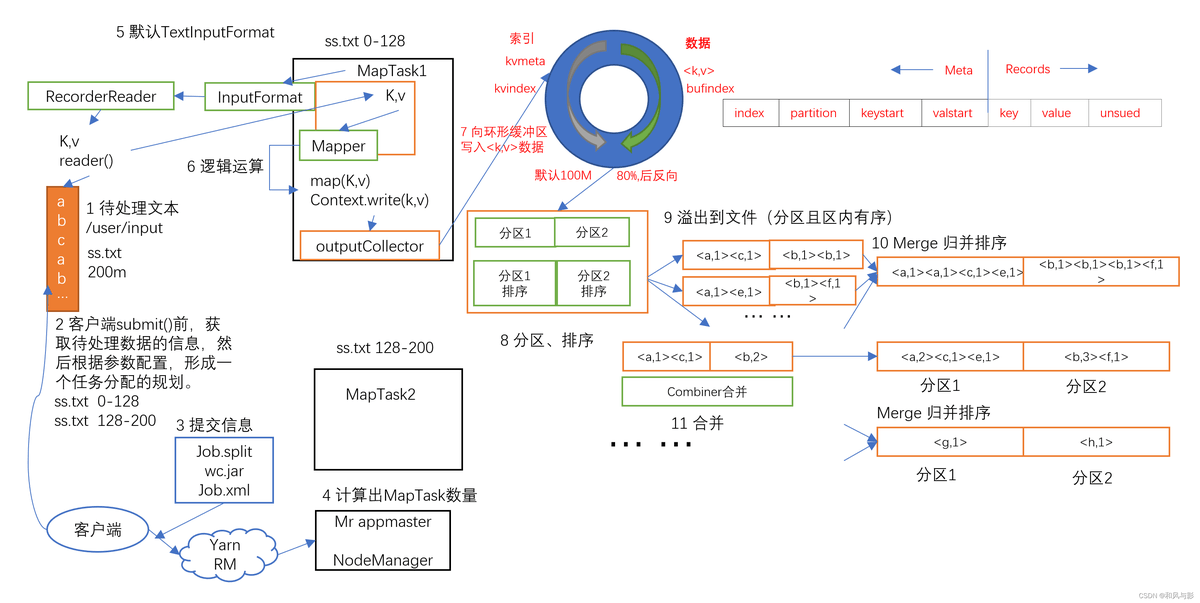
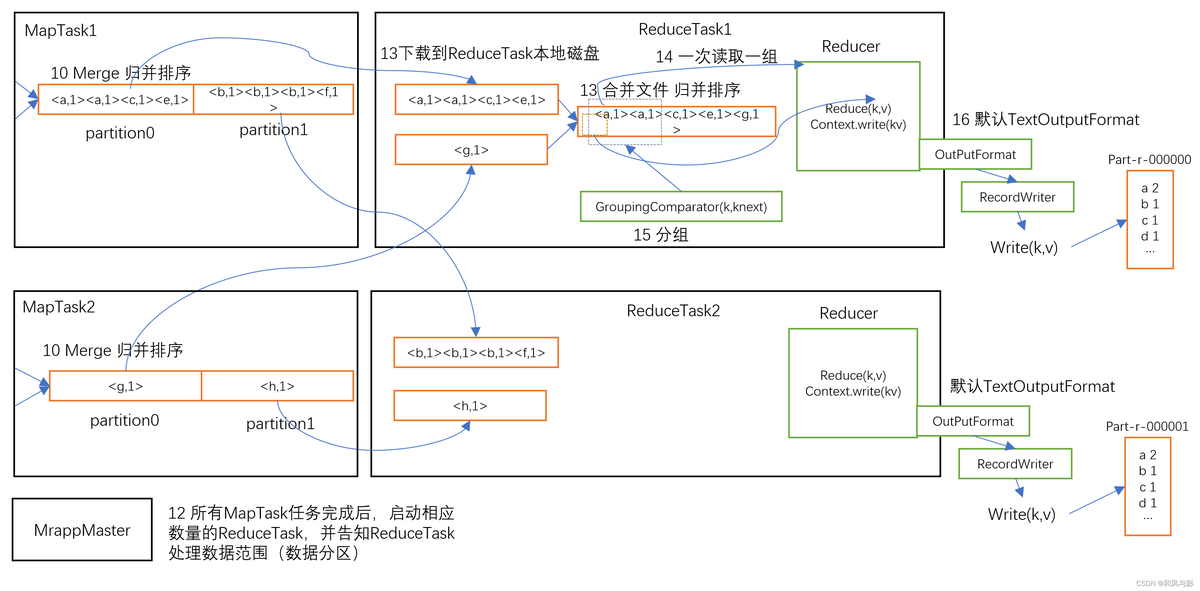
排序:一次快速排序,两次归并排序。
9、Hadoop 里面的 SecondaryNameNode 的作用是什么?具体恢复过程了解么?
- 作用:SecondaryNameNode 每隔一段时间对 NameNode 元数据备份。
- 恢复:删除 NameNode 存储的数据。拷贝 SecondaryNameNode 中数据到原 NameNode 存储数据目录。重新启动 NameNode。
10、Hive 里面的 join 分哪些类型呢?Hive 的 join 的优化一般会怎么优化?除了 mapjoin 还知道别的么?
分类:
包括 inner join、left outer join、right outer join、full outer join 类似其他数据库的操作。
还有下面讲一些使用较少的:
left semi join:返回左表的记录,前提是该记录在右表存在。例如:
# 例如下面的语法,Hive 中是不支持的
select s.ymd,s.symbol,s.price_close from stocks s
where s.ymd,s.symbol in
(select d.ymd, d.symbol from dividends d);
# Hive 中实现
select s.ymd,s.symbol,s.price_close
from stocks s left semi join dividends
on s.ymd = d.ymd and s.symbol=d.symbol;
hive.mapred.modmap-side join:设置开启 map-side join,并设置使用这个优化时小表的大小:
# 开启 map-side join
set hive.auto.convert.join=true;
# 设置小表大小
set hive.mapjoin.smalltable.filesize=25000000
# 分桶存储的大表也是可以使用的
set hive.optimize.bucketmapJOIN=true;
如果所有的表有相同的分桶数,且数据是按照连接键或桶的键排序的,那么可以使用更快的分类-合并连接(sort-merge JOIN):
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
set hive.optimize.bucektmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
优化:
- left semi join 代替 in。
- mapjoin:将数据量比较小的表,直接缓存在内存,然后在map段完成join,性能提高不少。
11、kafka接触过吗?实时计算的 Spark Streaming、Flink 了解过吗?
12、数仓分层一般分为哪几层?数仓建模时用到的雪花模型和星型模型的区别?
分层:
- 操作数据层 ODS:把操作系统数据几乎无处理地存放在数据仓库系统中;
- 公共维度模型层 CDM:存放明细事实数据、维表数据及公共指标汇总数据 , 其中明细事实数据、维表数据一般根据 ODS 层数据加工生成,CDM 层又细分为明细数据层 DWD 和汇总数据层 DWS ,采用维度模型方法作为理论基础,更多地采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联,提高明细数据表的易用性:同时在汇总数据层,加强指标的维度退化,采取更多的宽表化手段构建公共指标数据层,提升公共指标的复用性。
- 应用数据层 APP:存放数据产品个性化的统计指标数据,根据 CDM 层与 ODS 层加工生成 (个性化指标:排名型、比值型等)。
- 维度 DIM:商品维度表(维度整合)、地区维度表(维度整合)、日期维度表、优惠券维度表、活动维度表(整合)。
13、主要开发语言是什么?
14、讲一下 JVM 的内存模型吧。
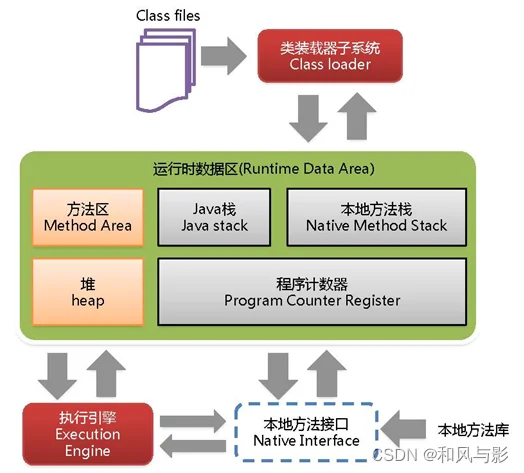
java 虚拟机主要分为以下几个区:
- 方法区:
a. 有时候也成为永久代,在该区内很少发生垃圾回收,但是并不代表不发生 GC,在这里进行的 GC 主要是对方法区里的常量池和对类型的卸载
b. 方法区主要用来存储已被虚拟机加载的类的信息、常量、静态变量和即时编译器编译后的代码等数据。
c. 该区域是被线程共享的。
d. 方法区里有一个运行时常量池,用于存放静态编译产生的字面量和符号引用。该常量池具有动态性,也就是说常量并不一定是编译时确定,运行时生成的常量也会存在这个常量池中。
- 虚拟机栈:
a. 虚拟机栈也就是我们平常所称的栈内存,它为 java 方法服务,每个方法在执行的时候都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息。
b. 虚拟机栈是线程私有的,它的生命周期与线程相同。
c. 局部变量表里存储的是基本数据类型、returnAddress 类型(指向一条字节码指令的地址)和对象引用,这个对象引用有可能是指向对象起始地址的一个指针,也有可能是代表对象的句柄或者与对象相关联的位置。局部变量所需的内存空间在编译器间确定
d. 操作数栈的作用主要用来存储运算结果以及运算的操作数,它不同于局部变量表通过索引来访问,而是压栈和出栈的方式
e. 每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接.动态链接就是将常量池中的符号引用在运行期转化为直接引用。
-
本地方法栈:
本地方法栈和虚拟机栈类似,只不过本地方法栈为 Native 方法服务。 -
堆:
java 堆是所有线程所共享的一块内存,在虚拟机启动时创建,几乎所有的对象实例都在这里创建,因此该区域经常发生垃圾回收操作。
5) 程序计数器:
内存空间小,字节码解释器工作时通过改变这个计数值可以选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理和线程恢复等功能都需要依赖这个计数器完成。该内存区域是唯一一个java虚拟机规范没有规定任何OOM情况的区域。
15、常用的 GC 算法有哪些?怎么判断一个对象是否可以被回收?分代内存回收了解么?年轻代的继续划分?如果我要分配一个对象,这个对象已经超过了 Eden 区的大小,这时会发生什么情况?
1.GC 算法:
- 引用计数法 应用于:微软的COM/ActionScrip3/Python等
- 如果对象没有被引用,就会被回收,缺点:需要维护一个引用计算器
- 复制算法 年轻代中使用的是Minor GC,这种GC算法采用的是复制算法(Copying)
- 效率高,缺点:需要内存容量大,比较耗内存
- 使用在占空间比较小、刷新次数多的新生区
- 标记清除 老年代一般是由标记清除或者是标记清除与标记整理的混合实现
- 效率比较低,会差生碎片。
- 标记压缩 老年代一般是由标记清除或者是标记清除与标记整理的混合实现
- 效率低速度慢,需要移动对象,但不会产生碎片。
- 标记清除压缩标记清除-标记压缩的集合,多次GC后才Compact
- 使用于占空间大刷新次数少的养老区,是3 4的集合体
2.如何判断对象是否可以被回收:
- 引用计数法
- 可达性算法(引用链法)
3.内存回收
-
对象优先在堆的Eden区分配。
-
大对象直接进入老年代。
-
长期存活的对象将直接进入老年代。
当 Eden 区没有足够的空间进行分配时,虚拟机会执行一次 Minor GC. Minor GC 通常发生在新生代的 Eden 区,在这个区的对象生存期短,往往发生 GC 的频率较高,回收速度比较快;Full Gc/Major GC 发生在老年代,一般情况下,触发老年代GC的时候不会触发Minor GC,但是通过配置,可以在Full GC之前进行一次Minor GC这样可以加快老年代的回收速度。
16、常用的垃圾收集器,CMS 和 G1了解吗?
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器,基于并发“标记清理”实现,在标记清理过程中不会导致用户线程无法定位引用对象。仅作用于老年代收集。
- 初始标记(CMS initial mark):独占CPU,stop-the-world, 仅标记GCroots能直接关联的对象,速度比较快;
- 并发标记(CMS concurrent mark):可以和用户线程并发执行,通过GCRoots Tracing 标记所有可达对象;
- 重新标记(CMS remark):独占CPU,stop-the-world, 对并发标记阶段用户线程运行产生的垃圾对象进行标记修正,以及更新逃逸对象;
- 并发清理(CMS concurrent sweep):可以和用户线程并发执行,清理在重复标记中被标记为可回收的对象。
G1 收集器弱化了 CMS 原有的分代模型(分代可以是不连续的空间),将堆内存划分成一个 个Region 1MB~32MB,默认 2048 个分区),这么做的目的是在进行收集时不必在全堆范围内进行。它主要特点在于达到可控的停顿时间,用户可以指定收集操作在多长时间内完成,即 G1提供了接近实时的收集特性。它的步骤如下:
- 初始标记(Initial Marking):标记一下GC Roots能直接关联到的对象,伴随着一次普通的Young GC发生,并修改NTAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的Region中创建新对象,此阶段是stop-the-world操作。
- 根区间扫描,标记所有幸存者区间的对象引用,扫描 Survivor到老年代的引用,该阶段必须在下一次Young GC 发生前结束。
- 并发标记(Concurrent Marking):是从GC Roots开始堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行,该阶段可以被Young GC中断。
- 最终标记(Final Marking):是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程Remembered Set Logs里面,最终标记阶段需要把Remembered Set Logs的数据合并到Remembered Set中,此阶段是stop-the-world操作,使用snapshot-at-the-beginning (SATB) 算法。
- 筛选回收(Live Data Counting and Evacuation):首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,回收没有存活对象的Region并加入可用Region队列。这个阶段也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅提高收集效率。
17、Java 的双亲委派模型了解么?
JVM 中提供了三层的 ClassLoader:
-
Bootstrap classLoader:主要负责加载核心的类库(java.lang.*等),构造 ExtClassLoader 和 APPClassLoader。
-
ExtClassLoader:主要负责加载 jre/lib/ext 目录下的一些扩展的 jar。
-
AppClassLoader:主要负责加载应用程序的主函数类。
当一个类收到了类加载请求,它不会尝试自己去加载,而是把这个请求委派给父类完成。每一层都是如此。只有当父类加载器反馈自己无法完成这个请求的时候子类加载器才会尝试自己去加载。
优点:防止核心库被随意篡改;避免类的重复加载。
18、Java 里面支持多继承么?接口和抽象类的区别是什么?
不支持。
区别:
抽象类:
- 构造方法:有构造方法,用于子类实例化使用。
- 成员变量:可以是变量,也可以是常量。
- 成员方法:可以是抽象的,也可以是非抽象的。
- 继承:只能单继承。
接口:
- 构造方法:没有构造方法
- 成员变量:只能是常量。默认修饰符:public static final
- 成员方法:jdk1.7只能是抽象的。默认修饰符:public abstract (推荐:默认修饰符请自己永远手动给出)
jdk1.8可以写以default和static开头的具体方法。 - 实现:可以实现多个接口。
19、HashMap 和 ConcurrentHashMap 的区别是什么?ConcurrentHashMap 具体是怎么实现线程安全的,了解么?HashMap底层的数据结构了解么?二叉搜索树和平衡二叉树有什么区别?如何将一个二叉搜索树变成一个平衡二叉树?
HashMap:
- 数据结构:数组 + 链表 + 红黑树。
- 安全性:非线程安全,因为底层代码操作数组时未加锁。
ConcurrentHashMap:
- 数据结构:分段数组 + 链表 + 红黑树
- 安全性:线程安全,因为底层代码在操作每一个segment时都会对segment加锁,保证线程安全。
二叉搜索树:根节点的值大于其左子树任意节点的值,小于其右子树任意节点的值。这一规则适用于二叉查找树中的每一个节点。且没有键值相等的节点。
平衡二叉树:每个节点的左右子树的高度差的绝对值最大为1。平衡二叉搜索树,又被称为AVL树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
二叉搜索树变成一个平衡二叉树:通过左右旋转来实现。
20、常用八大排序算法的时间复杂度?堆排序的时间复杂度是多少?建堆的时间复杂度?堆调整的时间复杂度?哪些排序是稳定的,哪些排序是不稳定的?如果一个数组是基本有序的,那我们要用什么排序会比较好?假设我们要对某个公司所有员工的年龄进行排序,这个时候用什么排序算法比较好?
21、怎么判断两个链表是否相交?怎么优化?
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
int lenA = getLength(headA);
int lenB = getLength(headB);
ListNode a = headA, b = headB;
int k = lenA - lenB;
if (k > 0) a = move(a, k);
else if (k < 0) b = move(b, -k);
while (a != null) {
if (a == b) return a;
a = a.next;
b = b.next;
}
return null;
}
private int getLength(ListNode head) {
int len = 0;
while (head !=null) {
len++;
head = head.next;
}
return len;
}
private ListNode move(ListNode head, int k) {
while (k-- > 0) head = head.next;
return head;
}
}
22、TCP 和 UDP 的区别是什么?
【网络八股文3】
| TCP/IP | UDP |
|---|---|
| 面向连接的协议 | 无连接协议 |
| 更可靠 | 不太可靠 |
| 传输速度较慢 | 更快的传输 |
| 数据包顺序可以保留或重新排列 | 数据包顺序不固定,数据包相互独立 |
| 使用三种方式握手模型进行连接 | 无需握手即可建立连接 |
| TCP 数据包是重量级的 | UDP数据包是轻量级的 |
| 提供错误检查机制 | 没有错误检查机制 |
| HTTP、FTP、Telnet、SMTP、HTTPS 等协议在传输层使用 TCP | DNS、RIP、SNMP、RTP、BOOTP、TFTP、NIP 等协议在传输层使用 UDP |
23、HTTP和HTTPS有什么区别?
HTTP 是超文本传输协议,它定义了有关如何在万维网 (WWW) 上传输信息的规则和标准。它有助于网络浏览器和网络服务器进行通信。这是一个“无状态协议”,其中每个命令相对于前一个命令是独立的。HTTP 是建立在 TCP 之上的应用层协议。它默认使用端口 80。
HTTPS 是超文本传输协议安全或安全 HTTP。它是 HTTP 的高级和安全版本。在 HTTP 之上,SSL/TLS 协议用于提供安全性。它通过加密通信来实现安全交易,还有助于安全地识别网络服务器。它默认使用端口 443。
24、子网掩码有什么用?
子网是通过称为子网划分的过程实现的网络内部的网络,该过程有助于将网络划分为子网。用于获得更高的路由效率,增强网络的安全性。它减少了从路由表中提取主机地址的时间。
子网掩码(subnet mask)用来指明一个 IP 地址的哪些位标识的是主机所在的子网,以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
25、进程和线程的区别?进程间通信的方式?
进程:资源分配的基本单位。进程基本上是一个当前正在执行的程序。操作系统的主要功能是管理和处理所有这些进程。当一个程序被加载到内存中并成为一个进程时,它可以分为四个部分——堆栈、堆、文本和数据。
线程:独立调度的基本单位。线程是由程序计数器、线程 ID、堆栈和进程内的一组寄存器组成的执行路径。它是 CPU 利用率的基本单位,它使通信更加有效和高效,使多处理器体系结构的利用率能够达到更大的规模和更高的效率,并减少上下文切换所需的时间。它只是提供了一种通过并行性来改进和提高应用程序性能的方法。线程有时被称为轻量级进程,因为它们有自己的堆栈但可以访问共享数据。
在一个进程中运行的多个线程共享进程的地址空间、堆、静态数据、代码段、文件描述符、全局变量、子进程、待定警报、信号和信号处理程序。
每个线程都有自己的程序计数器、寄存器、堆栈和状态。
| 进程 | 线程 |
|---|---|
| 它是一个正在执行的计算机程序。 | 它是进程的组件或实体,是最小的执行单元。 |
| 重量级。 | 轻量级。 |
| 它有自己的内存空间。 | 它使用它们所属进程的内存。 |
| 与创建线程相比,创建进程更难。 | 与创建进程相比,创建线程更容易。 |
| 与线程相比,它需要更多资源。 | 与流程相比,它需要更少的资源。 |
| 与线程相比,创建和终止进程需要更多时间。 | 与进程相比,创建和终止线程所需的时间更少。 |
| 它通常运行在单独的内存空间中。 | 它通常运行在共享内存空间中。 |
| 它不共享数据。 | 它彼此共享数据。 |
| 它可以分为多个线程。 | 不能再细分了。 |
IPC(进程间通信) 是一种需要使用共享资源(如在进程或线程之间共享的内存)的机制。通过 IPC,操作系统允许不同的进程相互通信。它仅用于在一个或多个程序或进程中的多个线程之间交换数据。在这种机制中,不同的进程可以在操作系统的批准下相互通信。
不同的 IPC 机制:
- 管道
- 消息队列
- 信号量
- 套接字
- 共享内存
- 信号
26、什么是死锁,死锁产生的必要条件有哪些?
死锁通常是一组进程被阻塞的情况,因为每个进程都持有资源并等待获取另一个进程持有的资源。在这种情况下,两个或多个进程只是尝试同时执行并等待每个进程完成它们的执行,因为它们相互依赖。
死锁的必要条件
死锁的必要条件基本上有以下四个:
- 互斥
- 请求并保持
- 不可抢占
- 循环等待或资源等待
27、数据库的事务?事务的特性?分别指的是什么含义?
定义:事务是逻辑上的一组数据库操作,要么都执行,要么都不执行。
特性:
-
原子性:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;例如转账的这两个关键操作(将张三的余额减少200元,将李四的余额增加200元)要么全部完成,要么全部失败。
-
一致性: 确保从一个正确的状态转换到另外一个正确的状态,这就是一致性。例如转账业务中,将张三的余额减少200元,中间发生断电情况,李四的余额没有增加200元,这个就是不正确的状态,违反一致性。又比如表更新事务,一部分数据更新了,但一部分数据没有更新,这也是违反一致性的;
-
隔离性:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
-
持久性:一个事务被提交之后,对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
28、数据库的索引,比如MySQL的索引有了解么?B树和B+树有什么区别?聚簇索引和稀疏索引的区别?
B树和B+树:
- B Tree(平衡树。平衡树是一颗查找树,并且所有叶子节点位于同一层。)
- B+ Tree (是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能,顺序读取不需要进行磁盘寻道。B+ 树访问磁盘数据有更高的性能,数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。B+树1-3层,双向链表,建议使用自增主键)
聚簇索引和非聚集索引:
- 聚集索引的顺序就是数据的物理存储顺序。它会根据聚集索引键的顺序来存储表中的数据,即对表的数据按索引键的顺序进行排序,然后重新存储到磁盘上。因为数据在物理存放时只能有一种排列方式,所以一个表只能有一个聚集索引。
- 非聚集索引: 索引顺序与物理存储顺序不同。非聚集索引的使用场合为: 查询所获数据量较少时; 某字段中的数据的唯一性比较高时。
- 例:比如字典中,用‘拼音’查汉字,就是聚集索引。因为正文中字都是按照拼音排序的。而用‘偏旁部首’查汉字,就是非聚集索引,因为正文中的字并不是按照偏旁部首排序的,我们通过检字表得到正文中的字在索引中的映射,然后通过映射找到所需要的字。
稠密索引和稀疏索引:
- 稠密索引:每个索引键值都对应有一个索引项。稠密索引能够比稀疏索引更快的定位一条记录。但是,稀疏索引相比于稠密索引的优点是:它所占空间更小,且插入和删除时的维护开销也小。
- 稀疏索引:相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的搜索码值的索引项,然后从该记录开始向后顺序查询直到找到为止。
29、MySQL的两个引擎InnoDB和MyISAM的区别是什么?
MyISAM:
- 用途:访问的速度快,以 SELECT、INSERT 为主的应用
- 索引:B tree,FullText,R-tree
- 锁:表锁
- 事务:不支持事务
- 其他:不支持外键。每个 MyISAM 在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。 .frm文件存储表定义。数据文件的扩展名为 .MYD (MYData)。索引文件的扩展名是 .MYI (MYIndex)。
InnoDB:
- 用途:大部分情况下选择 InnoDB,除非需要用到某些 InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该优先选择 InnoDB 引擎。
- 索引:B+ tree,hash(引擎自适应,无法人为干预),FullText(5.6开始)
- 锁:行锁
- 事务:支持
- 其他:对比 MyISAM 的存储引擎,InnoDB 写的处理效率差一些,并且会占用更多的磁盘空间以保存数据和索引。InnoDB 所有的表都保存在同一个数据文件中,InnoDB 表的大小只受限于操作系统文件的大小限制。MyISAM 只缓存索引,不缓存真实数据;InnoDB 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响。
30、memchache 和 redis 有了解过吗?
Redis 与 Memchache 都是分布式缓存系统。
-
数据存储介质: Memchache缓存的数据都是存放在内存中,一旦内存失效,数据就丢失,无法恢复;Redis缓存的数据存放在内存和硬盘中,能够达到持久化存储,Redis能够利用快照和AOF把数据存放到硬盘中,当内存失效,也可以从磁盘中抽取出来,调入内存中,当物理内存使用完毕后,也可以自动的持久化的磁盘中。
-
数据存储方式:Redis与Memchache都是以键值对的方式存储,而Redis对于值 使用比较丰富,支持Set,Hash,List,Zet(有序集合)等数据结构的存储,Memchache只支持字符串,不过Memchache也可以缓存图片、视频等非结构化数据。
-
从架构层次:Redis支持Master-Slave(主从)模式的应用,应用在单核上, Memchache支持分布式,应用在多核上
-
存储数据大小:对于Redis单个Value存储的数据最大为1G,而Memchache存储的最大为1MB,而存储的Value数据值大于100K时,性能会更好
-
Redis只支持单核,而Memchache支持多核。
31、一致性 Hash 有了解过吗?
简单 Hash 的缺点:当机器数量发生变动的时候,几乎所有的数据都会移动。
需求:当增加或者删除节点时,对于大多数记录,保证原来分配到的某个节点,现在仍然应该分配到那个节点,将数据迁移量的降到最低。
一致性 Hash:
- 将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数 H 的值空间为 0-2^32-1(即哈希值是一个 32 位无符号整形),整个哈希环如下,从 0 ~ 2^32-1 代表的分别是一个个的节点,这个环也叫哈希环。
- 将我们的节点进行一次哈希,按照一定的规则,比如按照 ip 地址的哈希值,让节点落在哈希环上。
- 通过数据 key 的哈希值落在哈希环上的节点,如果命中了机器节点就落在这个机器上,否则落在顺时针直到碰到第一个机器。
- 当节点宕机时,数据记录会被定位到下一个节点上,当新增节点的时候 ,相关区间内的数据记录就需要重新哈希。
问题:一致性 Hash 算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题。比如只有 2 台机器,这 2 台机器离的很近,那么顺时针第一个机器节点上将存在大量的数据,第二个机器节点上数据会很少。
虚拟节点解决数据倾斜问题:
- 为了避免出现数据倾斜问题,一致性 Hash 算法引入了虚拟节点的机制,也就是每个机器节点会进行多次哈希,最终每个机器节点在哈希环上会有多个虚拟节点存在,使用这种方式来大大削弱甚至避免数据倾斜问题。
- 数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。
32、linux常用的命令,我们要看操作系统中有哪些进程,用什么命令?如果看端口被哪些程序占用了,用什么看?
常用命令:
| 命令 | 命令解释 |
|---|---|
| top | 查看内存 |
| df -h | 查看磁盘存储情况 |
| iotop | 查看磁盘IO读写(yum install iotop安装) |
| iotop -o | 直接查看比较高的磁盘读写程序 |
| netstat -tunlp | grep 端口号 | 查看端口占用情况 |
| uptime | 查看报告系统运行时长及平均负载 |
| ps -ef | 查看进程 |
33、常用的 vim 命令,如何跳到第一行?怎么跳到最后一行?如何删除一行?
nggnGn100gg100GggGdd34、sed 和 awk 用过么,用这两个实现把一个文件中的空行进行删除。
35、正则表达式中的贪婪匹配和非贪婪匹配了解吗?这个具体写的时候怎么写了解么?
如:
String str="abcaxc";
Patter p="ab*c";
贪婪匹配: 正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c)。
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab*c)。
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
String rule1="content:\".+\""; //贪婪模式
String rule2="content:\".+?\""; //非贪婪模式