
非零基础自学Golang
第17章 HTTP编程(上)
17.3 爬虫框架gocolly
我们在之前学习了如何使用标准库实现HTTP爬虫【其实也不算,就实现了简单的请求,但是爬虫不就是这样嘛,拿到数据下去再进行解析】,在实际项目中,我们往往会使用一些第三方的爬虫框架来编写爬虫程序,这是因为框架是基于标准库的封装,本身会提供非常丰富且功能强大的API调用,我们只需编写简短的代码就能实现一个高性能爬虫,这里推荐使用colly爬虫框架。
colly是用Go语言实现的网络爬虫框架。colly快速优雅,在单核上每秒可以发起1K以上请求;以回调函数的形式提供了一组接口,可以实现任意类型的爬虫。
17.3.1 gocolly简介
colly的代码托管在GitHub上,官方网站为http://go-colly.org/。
colly使用起来简洁高效,有着如下特性:
- 非常清晰的API。
- 快速(单核上>1K请求/秒)。
- 管理请求延迟和每个域的最大并发数。
- 自动Cookie和会话处理。
- 同步/异步/并行抓取。
- 高速缓存。
- 自动处理非Unicode的编码。
- Robots.txt支持。
- 分布式抓取。
- 通过环境变量配置。
- 可扩展。
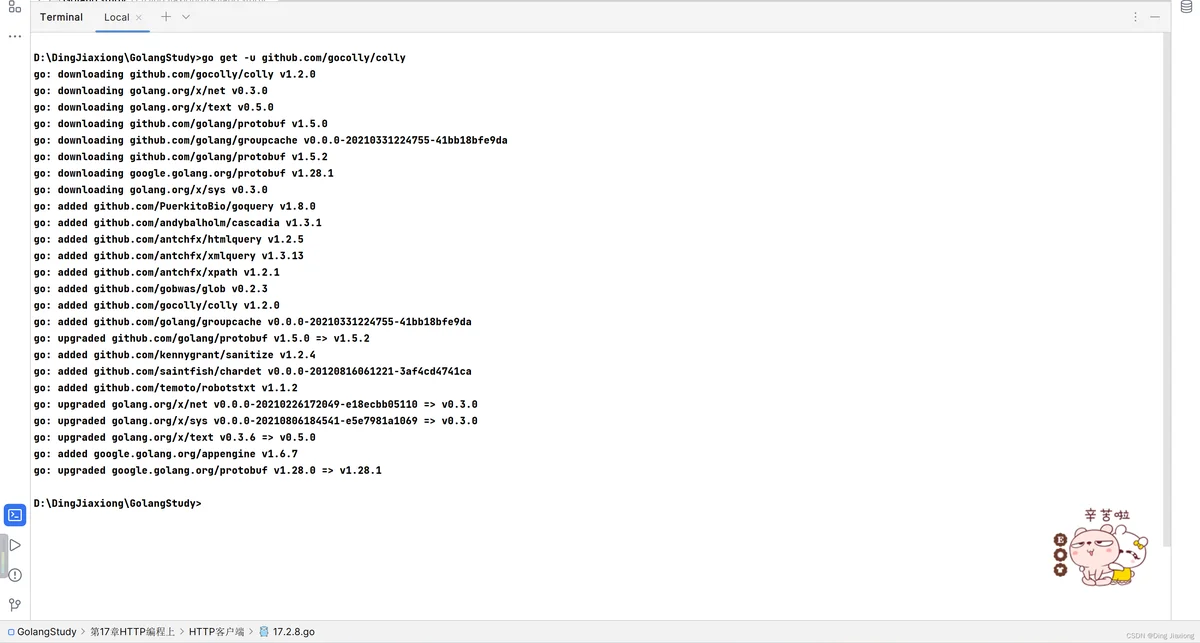
下载安装colly框架只需使用如下命令:
go get -u github.com/gocolly/colly
colly的主要实体是一个Collector对象。Collector在收集器作业运行时管理网络通信并负责执行附加的回调。
要使用colly,必须先初始化Collector。
c := colly.NewCollector()
一旦得到一个colly对象,就可以向colly附加各种不同类型的回调函数(回调函数在colly中广泛使用)来控制收集作业或获取信息,回调函数如下:
// 请求发送前所运行的函数
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
// 遇到错误时所运行的函数
c.OnError(func(_ *colly.Response, err error) {
log.Println("Something went wrong:", err)
})
// 接收到响应后所运行的函数
c.OnResponse(func(r *colly.Response) {
fmt.Println("Visited", r.Request.URL)
})
// 接收到HTML网页后所运行的函数
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
e.Request.Visit(e.Attr("href"))
})
c.OnHTML("tr td:nth-of-type(1)", func(e *colly.HTMLElement) {
fmt.Println("First column of a table row:", e.Text)
})
// 接收到XML格式的响应内容后所运行的函数
c.OnXML("//h1", func(e *colly.XMLElement) {
fmt.Println(e.Text)
})
// 请求完成后所运行的函数
c.OnScraped(func(r *colly.Response) {
fmt.Println("Finished", r.Request.URL)
})
colly的回调函数非常清晰,比如OnRequest表示在请求之前所需要做的事情,OnResponse表示在获取到响应后所做的事情。我们来看一个最简单的例子:
[ 动手写 17.3.1 ]
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// 查找和访问所有的链接
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
e.Request.Visit(e.Attr("href"))
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("Visiting", r.URL)
})
c.Visit("http://go-colly.org/")
}
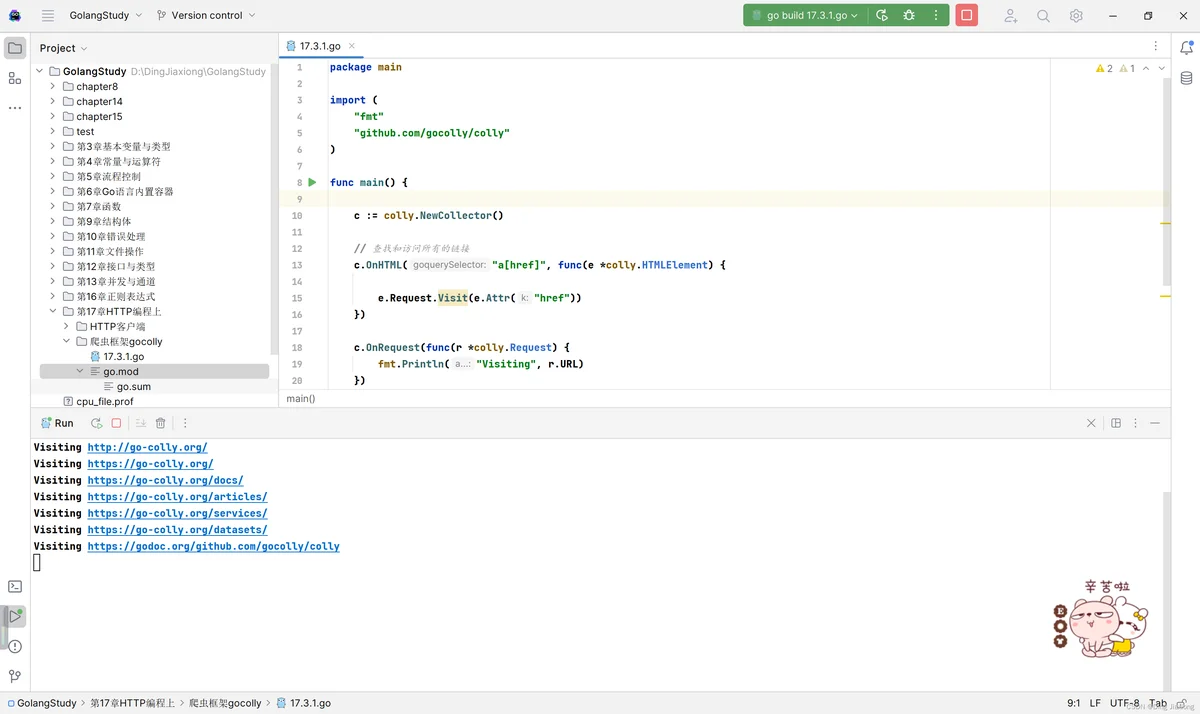
动手写17.3.1使用NewCollector创建了一个Collector对象,每当colly获取到HTML网页时,就会查找网页中的所有链接,并添加到访问队列中。
OnRequest在发起请求前就会打印输出访问的URL。c.Visit表示初始访问链接为http://go-colly.org/,这段程序的作用是访问全站链接。
程序运行的结果如下:
NewCollector在初始化时,可以传入colly.UserAgent来设置请求的UA,绕过网站的反爬策略。
OnRequest一般会在请求前设置一些模拟真实浏览器的Header头,举个例子:
[ 动手写 17.3.2]
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
// NewCollector(options ...func(*Collector)) *Collector
// 声明初始化NewCollector对象时可以指定Agent,连接递归深度,URL过滤以及domain限制等
c := colly.NewCollector(
colly.UserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121Safari/537.36"))
// 发出请求时 附的回调
c.OnRequest(func(r *colly.Request) {
// Request 头部设定
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "")
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN, zh;q=0.9")
//r.Headers.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36")
fmt.Println("Visiting", r.URL)
})
// 打印状态响应码
c.OnResponse(func(r *colly.Response) {
fmt.Println("response received ", r.StatusCode)
})
// 对响应的HTML 元素处理
c.OnHTML("title", func(e *colly.HTMLElement) {
fmt.Println("title:", e.Text)
})
c.Visit("https://www.baidu.com")
}
动手写17.3.2设置了大量请求头信息,User-Agent也可以在请求头中设置,运行结果如下:
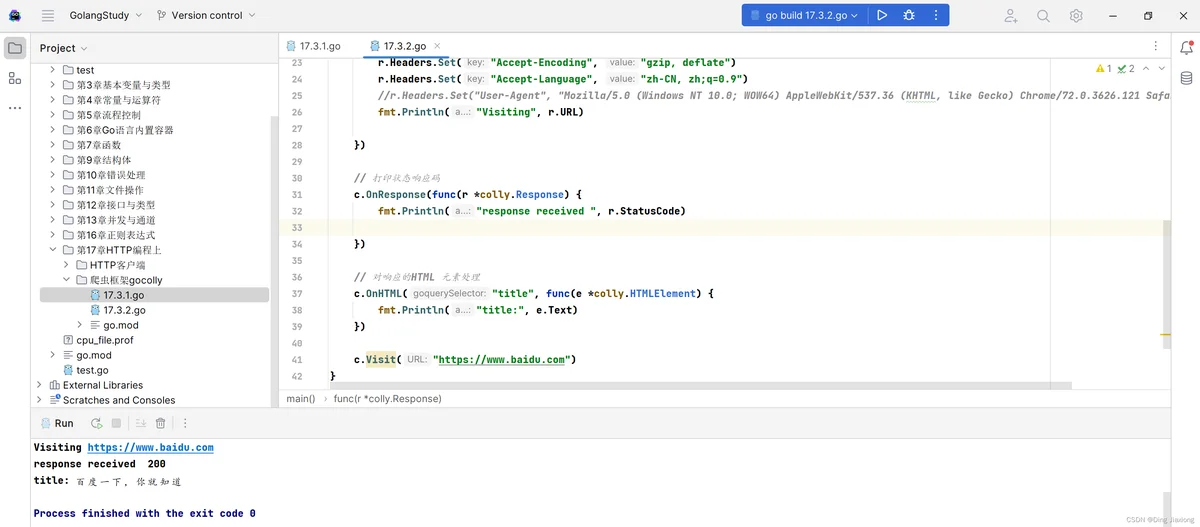
没毛病。