
一.前言一句话总结:保存和复用临时对象,减少内存分配,降低 GC 压力。
Go 语言标准库也大量使用了 sync.Pool,例如 fmt 和 encoding/json。
1.1 要解决的问题
一个新技术亦或是一个新名词,总是为了解决一些问题才出现的,所以先搞明白解决什么问题是第一步。
核心来说,我们的代码中会各种创建对象,比如new一个结构体、创建一个连接、甚至创建一个int都属于对象。那么假设在某些场景下,你的代码会频繁的创建某一种对象,那么这种操作可能会影响你程序的性能,原因是什么呢?
- 我们知道创建对象肯定是需要申请内存的
- 频繁的创建对象,会对GC造成较大的压力,其实主要是GC压力较大,golang的官方库sync.pool就是为了解决它,看名字就是池的方法。
1.2 池和缓存
sync.pool的思想很简单就是对象池,由于最近一直在做相关的事情,这里我们说个题外话,关于池和缓存说下我的一些看法。
- 工作中遇到过很多池:连接池,线程池,协程池,内存池等,会发现这些所谓池,都是解决同一个类型的问题,创建连接、线程等比较消耗资源,所以用池化的思想来解决这些问题,直接复用已经创建好的。
- 其实缓存也是,用到缓存的地方比如说,本地缓存、容灾缓存,性能缓存等名词,这些缓存的思想无非就是把计算好的存起来,真正的流量过来的时候,直接使用缓存好的内容,能提服务响应高速度。
1.3 总结下来就是
- 复用之前的内容,不用每次新建
- 提前准备好,不用临时创建
- 采用性能高的存储做缓存,更加提高响应速度 其实看下来跟我们的对象池,没什么区别,我们对象池也就是复用之前创建好的对象。
最后发散下思想,影响我们的程序性能的有以下几个,存储、计算、网络等,其实都可以做缓存,或者提前准备好,亦或者复用之前的结果。我们程序中很多init的东西不就是提前准备好的存储吗,我们很多做的local cache其实就是减少网络传输时间等,以后优化服务性能可以从这个角度考虑。
二. 工作原理我们先看下如何使用如下结构体
package mainimport ("fmt""sync"
)type item struct {value int
}func main() {pool := sync.Pool{New: func() interface{} {return item{}},}pool.Put(item{value: 1})data := pool.Get()fmt.Println("data = ",data)
}
看起来使用方式很简单,创建一个对象池的方式传进去一个New对象的函数,然后就是两个函数获取对象Get和放入对象Put。
想彻底搞明白原理,莫过于直接去读源码。 先瞅一眼结构体
2.1 Pool
Pool是一个可以分别存取的临时对象的集合。Pool中保存的任何item都可能随时不做通告的释放掉。如果Pool持有该对象的唯一引用,这个item就可能被回收。
Pool可以安全的被多个线程同时使用。Pool的目的是缓存申请但未使用的item用于之后的重用,以减轻GC的压力。也就是说,让创建高效而线程安全的空闲列表更容易。但Pool并不适用于所有空闲列表。
Pool的合理用法是管理一组被多个独立并发线程共享并可能重用的临时item。Pool提供了让多个线程分摊内存申请消耗的方法。
Pool的一个好例子在fmt包里。该Pool维护一个动态大小的临时输出缓存仓库。该仓库会在过载(许多线程活跃的打印时)增大,在沉寂时缩小。另一方面,管理着短寿命对象的空闲列表不适合使用Pool,因为这种情况下内存申请消耗不能很好的分配。**这时应该由这些对象自己实现空闲列表。第一次使用后不得复制池。
// A Pool is a set of temporary objects that may be individually saved and
// retrieved.
//
// Any item stored in the Pool may be removed automatically at any time without
// notification. If the Pool holds the only reference when this happens, the
// item might be deallocated.
//
// A Pool is safe for use by multiple goroutines simultaneously.
//
// Pool's purpose is to cache allocated but unused items for later reuse,
// relieving pressure on the garbage collector. That is, it makes it easy to
// build efficient, thread-safe free lists. However, it is not suitable for all
// free lists.
//
// An appropriate use of a Pool is to manage a group of temporary items
// silently shared among and potentially reused by concurrent independent
// clients of a package. Pool provides a way to amortize allocation overhead
// across many clients.
//
// An example of good use of a Pool is in the fmt package, which maintains a
// dynamically-sized store of temporary output buffers. The store scales under
// load (when many goroutines are actively printing) and shrinks when
// quiescent.
//
// On the other hand, a free list maintained as part of a short-lived object is
// not a suitable use for a Pool, since the overhead does not amortize well in
// that scenario. It is more efficient to have such objects implement their own
// free list.
//
// A Pool must not be copied after first use.
type Pool struct {noCopy noCopylocal unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocallocalSize uintptr // size of the local arrayvictim unsafe.Pointer // local from previous cyclevictimSize uintptr // size of victims array// New optionally specifies a function to generate// a value when Get would otherwise return nil.// It may not be changed concurrently with calls to Get.New func() interface{}
}
- local :指向的是poolLocal的数组的指针,[P]poolLocal 数组长度是调度器中P的数量,也就是说每一个P有自己独立的poolLocal。通过P.id来获取每个P自己独立的poolLocal。在poolLocal中有一个poolChain
- localSize:local数组的长度
- victim :victim 和 victimSize 这个是在 poolCleanup 流程里赋值了,赋值的内容就是 local 和 localSize 。victim 机制是把 Pool 池的清理由一轮 GC 改成 两轮 GC,进而提高对象的复用率,减少抖动;
- New func() interface{}:当池中没有对象时,get方法将使用New方法来返回一个对象,如果你不设置New方法的话,将会返回nil
那么看下这个本地资源池的结构.一层套一层
// Local per-P Pool appendix.
type poolLocalInternal struct {private interface{} // Can be used only by the respective P.shared poolChain // Local P can pushHead/popHead; any P can popTail.
}type poolLocal struct {poolLocalInternal// Prevents false sharing on widespread platforms with// 128 mod (cache line size) = 0 .pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
- poolChain:是一个双端队列链,缓存对象。 1.12版本中对于这个字段的并发安全访问是通过mutex加锁实现的;1.14优化后通过poolChain(无锁化)实现的。
2.2 pool.put
// Put adds x to the pool.
func (p *Pool) Put(x interface{}) {if x == nil {return}if race.Enabled {if fastrand()%4 == 0 {// Randomly drop x on floor.return}race.ReleaseMerge(poolRaceAddr(x))race.Disable()}l, _ := p.pin()if l.private == nil {l.private = xx = nil}if x != nil {l.shared.pushHead(x)}runtime_procUnpin()if race.Enabled {race.Enable()}
}
Put函数主要逻辑是
(1)先调用p.pin() 函数,这个函数会将当前 goroutine与P绑定,并设置当前g不可被抢占(也就不会出现多个协程并发读写当前P上绑定的数据);
- 在p.pin() 函数里面还会check per P的[P]poolLocal数组是否发生了扩容(P 扩张)。
- 如果发生了扩容,需要调用pinSlow()来执行具体扩容。扩容获取一个调度器全局大锁allPoolsMu,然后根据当前最新的P的数量去执行新的扩容。这里的成本很高,所以尽可能避免手动增加P的数量。
(2)拿到per P的poolLocal后,优先将val put到private,如果private已经存在,就通过调用shared.pushHead(x) 塞到poolLocal里面的无锁双端队列的chain中。Put函数对于双端队列来说是作为一个Producer角色,所以这里的调用是无锁的。
(3)最后解除当前goroutine的禁止抢占。
// pin pins the current goroutine to P, disables preemption and
// returns poolLocal pool for the P and the P's id.
// Caller must call runtime_procUnpin() when done with the pool.
func (p *Pool) pin() (*poolLocal, int) {pid := runtime_procPin()// In pinSlow we store to local and then to localSize, here we load in opposite order.// Since we've disabled preemption, GC cannot happen in between.// Thus here we must observe local at least as large localSize.// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).s := runtime_LoadAcquintptr(&p.localSize) // load-acquirel := p.local // load-consumeif uintptr(pid) < s {return indexLocal(l, pid), pid}return p.pinSlow()
}func (p *Pool) pinSlow() (*poolLocal, int) {// Retry under the mutex.// Can not lock the mutex while pinned.runtime_procUnpin()allPoolsMu.Lock()defer allPoolsMu.Unlock()pid := runtime_procPin()// poolCleanup won't be called while we are pinned.s := p.localSizel := p.localif uintptr(pid) < s {return indexLocal(l, pid), pid}if p.local == nil {allPools = append(allPools, p)}// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.size := runtime.GOMAXPROCS(0)local := make([]poolLocal, size)atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-releaseruntime_StoreReluintptr(&p.localSize, uintptr(size)) // store-releasereturn &local[pid], pid
}
2.3 pool.get
// Get selects an arbitrary item from the Pool, removes it from the
// Pool, and returns it to the caller.
// Get may choose to ignore the pool and treat it as empty.
// Callers should not assume any relation between values passed to Put and
// the values returned by Get.
//
// If Get would otherwise return nil and p.New is non-nil, Get returns
// the result of calling p.New.
func (p *Pool) Get() interface{} {if race.Enabled {race.Disable()}l, pid := p.pin()x := l.privatel.private = nilif x == nil {// Try to pop the head of the local shard. We prefer// the head over the tail for temporal locality of// reuse.x, _ = l.shared.popHead()if x == nil {x = p.getSlow(pid)}}runtime_procUnpin()if race.Enabled {race.Enable()if x != nil {race.Acquire(poolRaceAddr(x))}}if x == nil && p.New != nil {x = p.New()}return x
}
Get函数主要逻辑:
- 设置当前 goroutine 禁止抢占(race竞态检查);
- 从 poolLocal的private取,如果private不为空直接return;
- 从 poolLocal.shared这个双端队列chain里面无锁调用去取,如果取得到也直接return;
- 上面都去不到,调用getSlow(pid)去取
a. 首先会通过 steal 算法,去别的P里面的poolLocal去取,这里的实现是无锁的cas。如果能够steal一个过来,就直接return;
b. 如果steal不到,则从 victim 里找,和 poolLocal 的逻辑类似。最后,实在没找到,就把 victimSize 置 0,防止后来的“人”再到 victim 里找。 - 最后还拿不到,就通过New函数来创建一个新的对象。
这里是一个很明显的多层级缓存优化 + GPM调度结合起来。
private -> shared -> steal from other P -> victim cache -> New
func (p *Pool) getSlow(pid int) interface{} {// See the comment in pin regarding ordering of the loads.size := runtime_LoadAcquintptr(&p.localSize) // load-acquirelocals := p.local // load-consume// Try to steal one element from other procs.for i := 0; i < int(size); i++ {l := indexLocal(locals, (pid+i+1)%int(size))if x, _ := l.shared.popTail(); x != nil {return x}}// Try the victim cache. We do this after attempting to steal// from all primary caches because we want objects in the// victim cache to age out if at all possible.size = atomic.LoadUintptr(&p.victimSize)if uintptr(pid) >= size {return nil}locals = p.victiml := indexLocal(locals, pid)if x := l.private; x != nil {l.private = nilreturn x}for i := 0; i < int(size); i++ {l := indexLocal(locals, (pid+i)%int(size))if x, _ := l.shared.popTail(); x != nil {return x}}// Mark the victim cache as empty for future gets don't bother// with it.atomic.StoreUintptr(&p.victimSize, 0)return nil
}
2.4 victim cache优化与GC
对于Pool来说并不能够无上限的扩展,否则对象占用内存太多了,会引起内存溢出。
几乎所有的池技术中,都会在某个时刻清空或清除部分缓存对象,那么在 Go 中何时清理未使用的对象呢?
这里是使用GC。在pool.go里面的init函数 会注册清理函数:
func init() {runtime_registerPoolCleanup(poolCleanup)
}// mgc.go
//go:linkname sync_runtime_registerPoolCleanup sync.runtime_registerPoolCleanup
func sync_runtime_registerPoolCleanup(f func()) {poolcleanup = f
}
编译器会把 runtime_registerPoolCleanup 函数调用链接到 mgc.go 里面的 sync_runtime_registerPoolCleanup函数调用,实际上注册到poolcleanup函数。
在 Golang GC 开始的时候 gcStart 调用 clearpools() 函数就会调用到 poolCleanup 函数。也就是说,每一轮 GC 都是对所有的 Pool 做一次清理。
整个调用链如下:
- gcStart() -> clearpools() -> poolcleanup() 也就是每一轮GC开始都会执行pool的清除操作。
这个是定期执行的,在 sync package init 的时候注册,由 runtime 后台执行,内容就是批量清理 allPools 里的元素。
func poolCleanup() {// This function is called with the world stopped, at the beginning of a garbage collection.// It must not allocate and probably should not call any runtime functions.// Because the world is stopped, no pool user can be in a// pinned section (in effect, this has all Ps pinned).// Drop victim caches from all pools.for _, p := range oldPools {p.victim = nilp.victimSize = 0}// Move primary cache to victim cache.for _, p := range allPools {p.victim = p.localp.victimSize = p.localSizep.local = nilp.localSize = 0}// The pools with non-empty primary caches now have non-empty// victim caches and no pools have primary caches.oldPools, allPools = allPools, nil
}
poolCleanup 会在 STW 阶段被调用。整体看起来,比较简洁。主要是将 local 和 victim 作交换,这样也就不致于让 GC 把所有的 Pool 都清空了,有 victim 在“兜底”。
- 如果 sync.Pool 的获取、释放速度稳定,那么就不会有新的池对象进行分配。如果获取的速度下降了,那么对象可能会在两个 GC 周期内被释放,而不是以前的一个 GC 周期。
在Go1.13之前的poolCleanup比较粗暴,直接清空了所有 Pool 的 p.local 和poolLocal.shared。
通过两者的对比发现,新版的实现相比 Go 1.13 之前,GC 的粒度拉大了,由于实际回收的时间线拉长,单位时间内 GC 的开销减小。所以 p.victim 的作用其实就是次级缓存。
2.5 poolChain
这里我们先重点分析一下poolChain 是怎么实现并发无锁编程的。
// poolChain is a dynamically-sized version of poolDequeue.
//
// This is implemented as a doubly-linked list queue of poolDequeues
// where each dequeue is double the size of the previous one. Once a
// dequeue fills up, this allocates a new one and only ever pushes to
// the latest dequeue. Pops happen from the other end of the list and
// once a dequeue is exhausted, it gets removed from the list.
type poolChain struct {// head is the poolDequeue to push to. This is only accessed// by the producer, so doesn't need to be synchronized.head *poolChainElt// tail is the poolDequeue to popTail from. This is accessed// by consumers, so reads and writes must be atomic.tail *poolChainElt
}type poolChainElt struct {poolDequeue// next and prev link to the adjacent poolChainElts in this// poolChain.//// next is written atomically by the producer and read// atomically by the consumer. It only transitions from nil to// non-nil.//// prev is written atomically by the consumer and read// atomically by the producer. It only transitions from// non-nil to nil.next, prev *poolChainElt
poolChain是一个动态大小的双向链接列表的双端队列。每个出站队列的大小是前一个队列的两倍。也就是说poolChain里面每个元素poolChainElt都是一个双端队列。
- head指向的poolChainElt,是用于Producer去Push元素的,不需要做同步处理。
- tail指向的poolChainElt,是用于Consumer从tail去pop元素的,这里的读写需要保证原子性
简单来说,poolChain是一个单Producer,多Consumer并发访问的双端队列链。
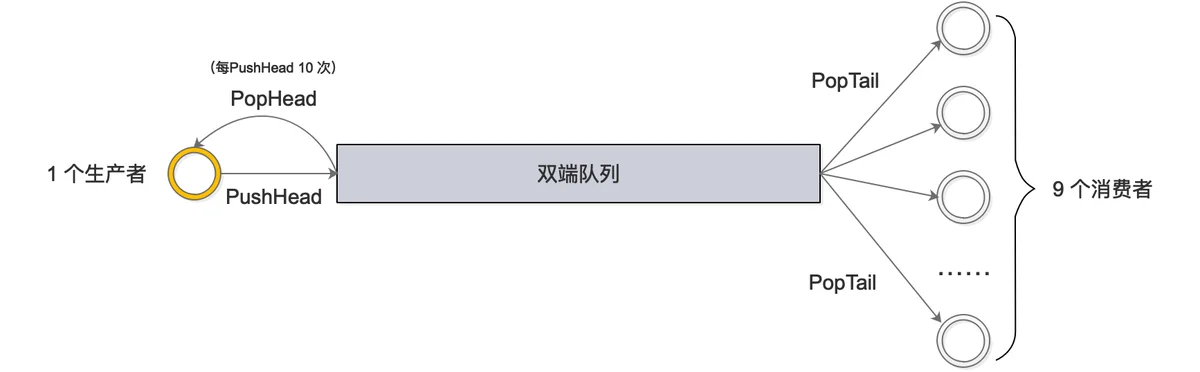
对于poolChain中的每一个双端队列 poolChainElt,包含了双端队列实体poolDequeue 一起前后链接的指针。
poolChain 主要方法有:
- popHead()(interface{},bool);
- pushHead(val interface{})
- popTail()(interface{},bool)
其中,popHead和pushHead函数是给Producer调用的;popTail是给Consumer并发调用的。
2.5.1 poolChain.popHead()
前面我们说了,poolChain的head 指针的操作是单Producer的。
func (c *poolChain) popHead() (interface{}, bool) {d := c.headfor d != nil {if val, ok := d.popHead(); ok {return val, ok}// There may still be unconsumed elements in the// previous dequeue, so try backing up.d = loadPoolChainElt(&d.prev)}return nil, false
}
poolChain要求,popHead函数只能被Producer调用。看一下逻辑:
- 获取头结点 head;
- 如果头结点非空就从头节点所代表的双端队列poolDequeue中调用popHead函数。注意这里poolDequeue的popHead函数和poolChain的popHead函数并不一样。poolDequeue是一个固定size的ring buffer。
- 如果从head中拿到了value,就直接返回;
- 如果从head中拿不到value,就从head.prev再次尝试获取;
- 最后都获取不到,就返回nil。
2.5.2 poolChain.pushHead()
func (c *poolChain) pushHead(val interface{}) {d := c.headif d == nil {// Initialize the chain.const initSize = 8 // Must be a power of 2d = new(poolChainElt)d.vals = make([]eface, initSize)c.head = dstorePoolChainElt(&c.tail, d)}if d.pushHead(val) {return}// The current dequeue is full. Allocate a new one of twice// the size.newSize := len(d.vals) * 2if newSize >= dequeueLimit {// Can't make it any bigger.newSize = dequeueLimit}d2 := &poolChainElt{prev: d}d2.vals = make([]eface, newSize)c.head = d2storePoolChainElt(&d.next, d2)d2.pushHead(val)
}
poolChain要求,pushHead函数同样只能被Producer调用。看一下逻辑:
- 首先还是获取头结点 head;
- 如果头结点为空,需要初始化chain
- 创建poolChainElt 节点,作为head, 当然也是tail。
- poolChainElt 其实也是固定size的双端队列poolDequeue,size必须是2的n次幂。
- 调用poolDequeue的pushHead函数将 val push进head的双端队列poolDequeue。
- 如果push失败了,说明双端队列满了,需要重新创建一个双端队列d2,新的双端队列的size是前一个双端队列size的2倍;
- 更新poolChain的head指向最新的双端队列,并且建立双链关系;
- 然后将val push到最新的双端队列。
这里需要注意一点的是head其实是指向最后chain中最后一个结点(poolDequeue),chain执行push操作是往最后一个节点push。 所以这里的head的语义不是针对链表结构,而是针对队列结构。
2.5.3 poolChain.popTail()
func (c *poolChain) popTail() (interface{}, bool) {d := loadPoolChainElt(&c.tail)if d == nil {return nil, false}for {// It's important that we load the next pointer// *before* popping the tail. In general, d may be// transiently empty, but if next is non-nil before// the pop and the pop fails, then d is permanently// empty, which is the only condition under which it's// safe to drop d from the chain.d2 := loadPoolChainElt(&d.next)if val, ok := d.popTail(); ok {return val, ok}if d2 == nil {// This is the only dequeue. It's empty right// now, but could be pushed to in the future.return nil, false}// The tail of the chain has been drained, so move on// to the next dequeue. Try to drop it from the chain// so the next pop doesn't have to look at the empty// dequeue again.if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {// We won the race. Clear the prev pointer so// the garbage collector can collect the empty// dequeue and so popHead doesn't back up// further than necessary.storePoolChainElt(&d2.prev, nil)}d = d2}
}
2.6 poolDequeue
poolChain中每一个结点都是一个双端队列poolDequeue。
poolDequeue是一个无锁的、固定size的、单Producer、多Consumer的deque。只有一个Producer可以从head去push或则pop;多个Consumer可以从tail去pop。
type poolDequeue struct {// 用高32位和低32位分别表示head和tail// head是下一个fill的slot的index;// tail是deque中最老的一个元素的index// 队列中有效元素是[tail, head)headTail uint64vals []eface
}type eface struct {typ, val unsafe.Pointer
}
这里通过一个字段 headTail 来表示head和tail的index。headTail是8个字节64位。
- 高32位表示head;
- 低32位表示tail。
- head和tail自加溢出时是安全的。
vals是一个固定size的slice,其实也就是一个 ring buffer,size必须是2的次幂(为了做位运算);
今天,我们一起讨论了另一个比较有用的同步工具——sync.Pool类型,它的值被我称为临时对象池。
临时对象池有一个New字段,我们在初始化这个池的时候最好给定它。临时对象池还拥有两个方法,即:Put和Get,它们分别被用于向池中存放临时对象,和从池中获取临时对象。
临时对象池中存储的每一个值都应该是独立的、平等的和可重用的。我们应该既不用关心从池中拿到的是哪一个值,也不用在意这个值是否已经被使用过。
要完全做到这两点,可能会需要我们额外地写一些代码。不过,这个代码量应该是微乎其微的,就像fmt包对临时对象池的用法那样。所以,在选用临时对象池的时候,我们必须要把它将要存储的值的特性考虑在内。
在临时对象池的内部,有一个多层的数据结构支撑着对临时对象的存储。它的顶层是本地池列表,其中包含了与某个 P 对应的那些本地池,并且其长度与 P 的数量总是相同的。
在每个本地池中,都包含一个私有的临时对象和一个共享的临时对象列表。前者只能被其对应的 P 所关联的那个 goroutine 中的代码访问到,而后者却没有这个约束。从另一个角度讲,前者用于临时对象的快速存取,而后者则用于临时对象的池内共享。
正因为有了这样的数据结构,临时对象池才能够有效地分散存储压力和性能压力。同时,又因为临时对象池的Get方法对这个数据结构的妙用,才使得其中的临时对象能够被高效地利用。比如,该方法有时候会从其他的本地池的共享临时对象列表中,“偷取”一个临时对象。
这样的内部结构和存取方式,让临时对象池成为了一个特点鲜明的同步工具。它存储的临时对象都应该是拥有较长生命周期的值,并且,这些值不应该被某个 goroutine 中的代码长期的持有和使用。
因此,临时对象池非常适合用作针对某种数据的缓存。从某种角度讲,临时对象池可以帮助程序实现可伸缩性,这也正是它的最大价值。
用一张图完整描述sync.Pool的数据结构
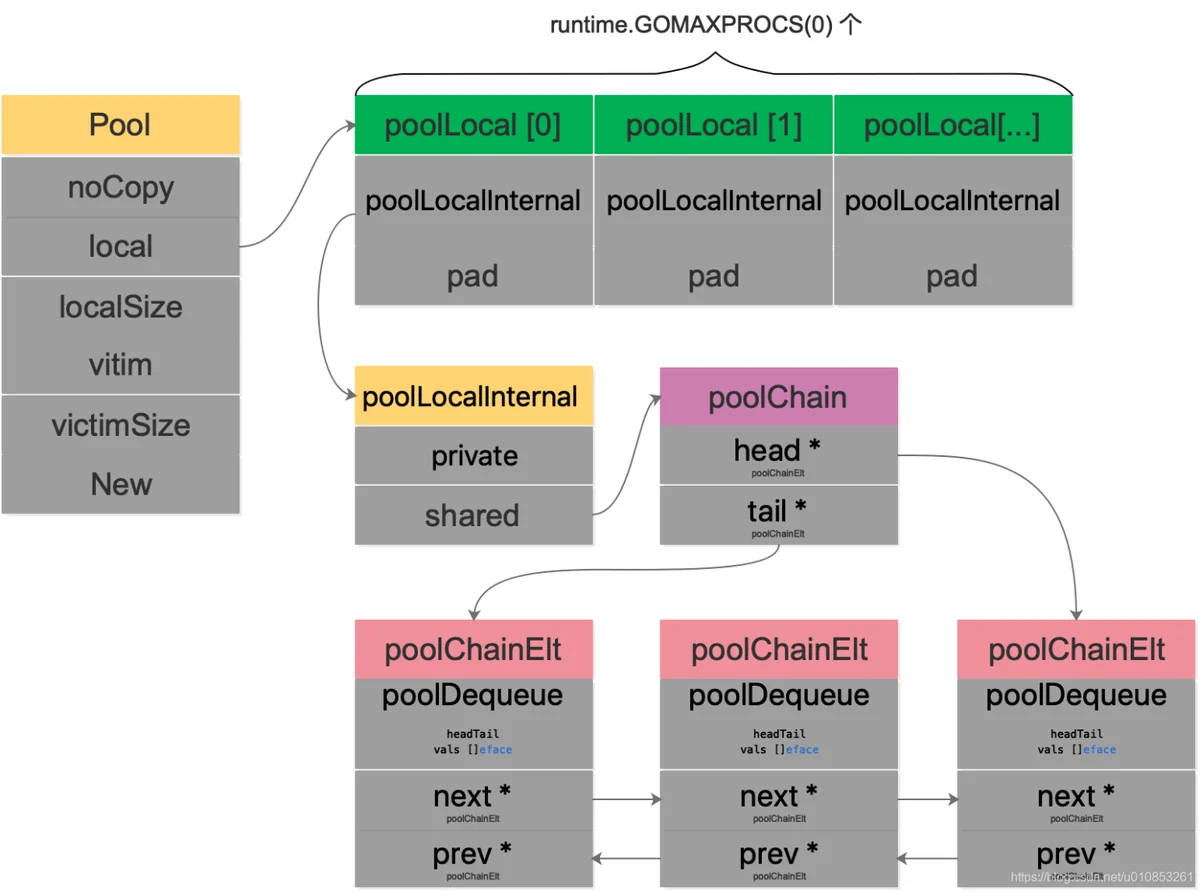
强调一点:
- head的操作只能是local P;
- tail的操作是任意P;
知识点总结
- Pool 本质是为了提高临时对象的复用率;
- Pool 使用两层回收策略(local + victim)避免性能波动;
- Pool 本质是一个杂货铺属性,啥都可以放。把什么东西放进去,预期从里面拿出什么类型的东西都需要业务使用方把控,Pool 池本身不做限制;
- Pool 池里面 cache 对象也是分层的,一层层的 cache,取用方式从最热的数据到最冷的数据递进;
- Pool 是并发安全的,但是内部是无锁结构,原理是对每个 P 都分配 cache 数组( poolLocalInternal 数组),这样 cache 结构就不会导致并发;
- 永远不要 copy 一个 Pool,明确禁止,不然会导致内存泄露和程序并发逻辑错误;
- 代码编译之前用 go vet 做静态检查,能减少非常多的问题;
- 每轮 GC 开始都会清理一把 Pool 里面 cache 的对象,注意流程是分两步,当前 Pool 池 local 数组里的元素交给 victim 数组句柄,victim 里面 cache 的元素全部清理。换句话说,引入 victim 机制之后,对象的缓存时间变成两个 GC 周期;
- 不要对 Pool 里面的对象做任何假定,有两种方案:要么就归还的时候 memset 对象之后,再调用 Pool.Put ,要么就 Pool.Get 取出来的时候 memset 之后再使用;
简言之
- 对象是get的时候生产的,调用new时初始化
- 对象是调用put的时候cache的,对象只有put之后才可能被复用
- 使用victim机制防止性能抖动
- cache的临时对象至少要经过两轮的GC
相关材料
- Go 并发编程 — sync.Pool 源码级原理剖析
- Go sync.Pool