
原理分析
1.1 结构依赖关系图
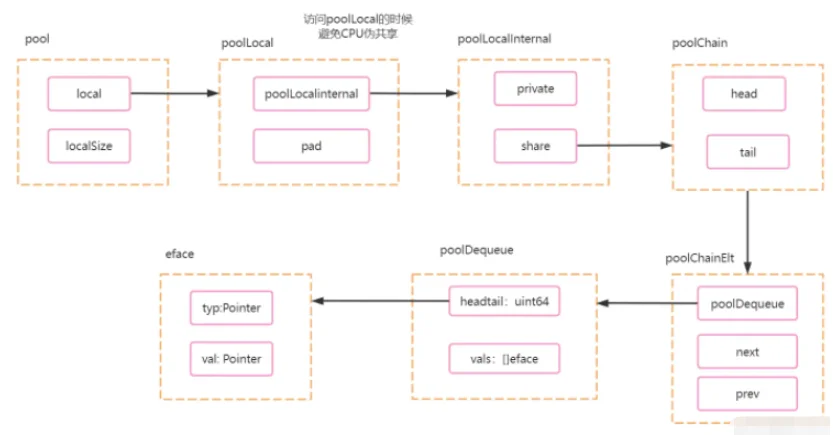
下面是相关源代码,不过是已经删减了对本次分析没有用的代码.
type Pool struct {
// GMP中,每一个P(协程调度器)会有一个数组,数组大小位localSize.
local unsafe.Pointer
// p 数组大小.
localSize uintptr
New func() any
}
// poolLocal 每个P(协程调度器)的本地pool.
type poolLocal struct {
poolLocalInternal
// 保证一个poolLocal占用一个缓存行
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}
type poolLocalInternal struct {
private any // Can be used only by the respective P. 16
shared poolChain // Local P can pushHead/popHead; any P can popTail. 8
}
type poolChain struct {
head *poolChainElt
tail *poolChainElt
}
type poolChainElt struct {
poolDequeue
next, prev *poolChainElt
}
type poolDequeue struct {
// head 高32位,tail低32位.
headTail uint64
vals []eface
}
// 存储具体的value.
type eface struct {
typ, val unsafe.Pointer
}1.2 用图让代码说话
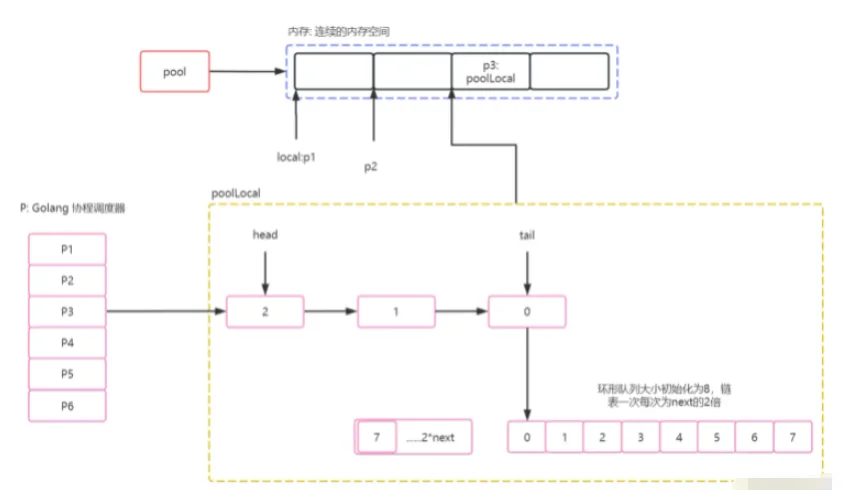
1.3 Put过程分析
Put 过程分析比较重要,因为这里会包含pool所有依赖相关分析.
总的分析学习过程可以分为下面几个步骤:
PpoolLocalvalpoolLocalpoolDequeuePpoolLocal4.读写内存优化.
数组直接操作内存,而不经过Golang
uint64headtail获取P对应的poolLocal
sync.Pool.localPutpidlocalfunc (p *Pool) pin() (*poolLocal, int) {
// 返回运行当前协程的P(协程调度器),并且设置禁止抢占.
pid := runtime_procPin()
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
// pid < 核心数. 默认走该逻辑.
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
// 设置的P大于本机CPU核心数.
return p.pinSlow()
}
// indexLocal 获取当前P的poolLocal指针.
func indexLocal(l unsafe.Pointer, i int) *poolLocal {
// l p.local指针开始位置.
// 我猜测这里如果l为空,编译阶段会进行优化.
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{}))
// uintptr真实的指针.
// unsafe.Pointer Go对指针的封装: 用于指针和结构体互相转化.
return (*poolLocal)(lp)
}runtime_procPinPut 进入poolDequeue队列:
headtailpoolChainEltpoolChain.headnextprev通过下面代码,我们可以看到,Go通过逻辑运算判断队列是否满的设计时非常巧妙的,如果后续我们去开发组件,也是可以这么进行设计的。
func (c *poolChain) pushHead(val any) {
d := c.head
// 初始化.
if d == nil {
// Initialize the chain.
const initSize = 8 // Must be a power of 2
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
// 将新构建的d赋值给tail.
storePoolChainElt(&c.tail, d)
}
// 入队.
if d.pushHead(val) {
return
}
// 队列满了.
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// 队列大小默认为2的30次方.
newSize = dequeueLimit
}
// 赋值链表前后节点关系.
// prev.
// d2.prev=d1.
// d1.next=d2.
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
// next .
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
// 入队poolDequeue
func (d *poolDequeue) pushHead(val any) bool {
ptrs := atomic.LoadUint64(&d.headTail)
head, tail := d.unpack(ptrs)
// head 表示当前有多少元素.
if (tail+uint32(len(d.vals)))&(1<Get实现逻辑:
其实我们看了Put相关逻辑之后,我们可能很自然的就想到了Get的逻辑,无非就是遍历链表,并且如果队列中最后一个元素不为空,则会将该元素返回,并且将该插槽赋值为空值.