
本文可以作为上一篇《mysql/mariadb 实现全文检索》的补充,实现对字符串分词的逻辑
什么是自然语言,什么是自然语言分词及例子
什么是自然语言
什么是自然语言分词及例子
实现自然语言分词的一些框架
SnowNLP, Thulac, HanLP,LTP,CoreNLP
hanLP介绍以及优点
java应用程序集成hanLP实现自然语言分词
代码结构
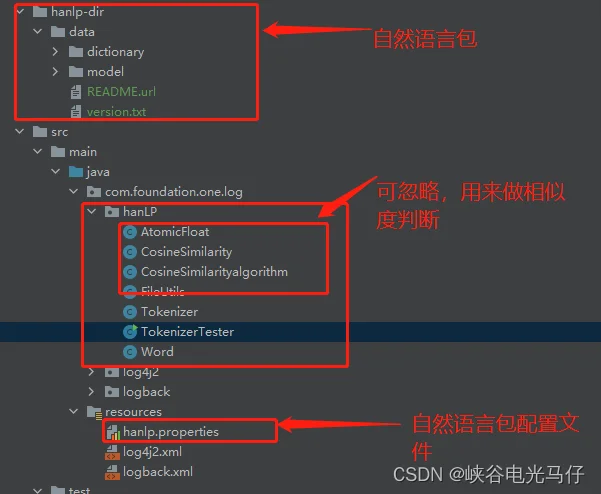
自然语言包下载
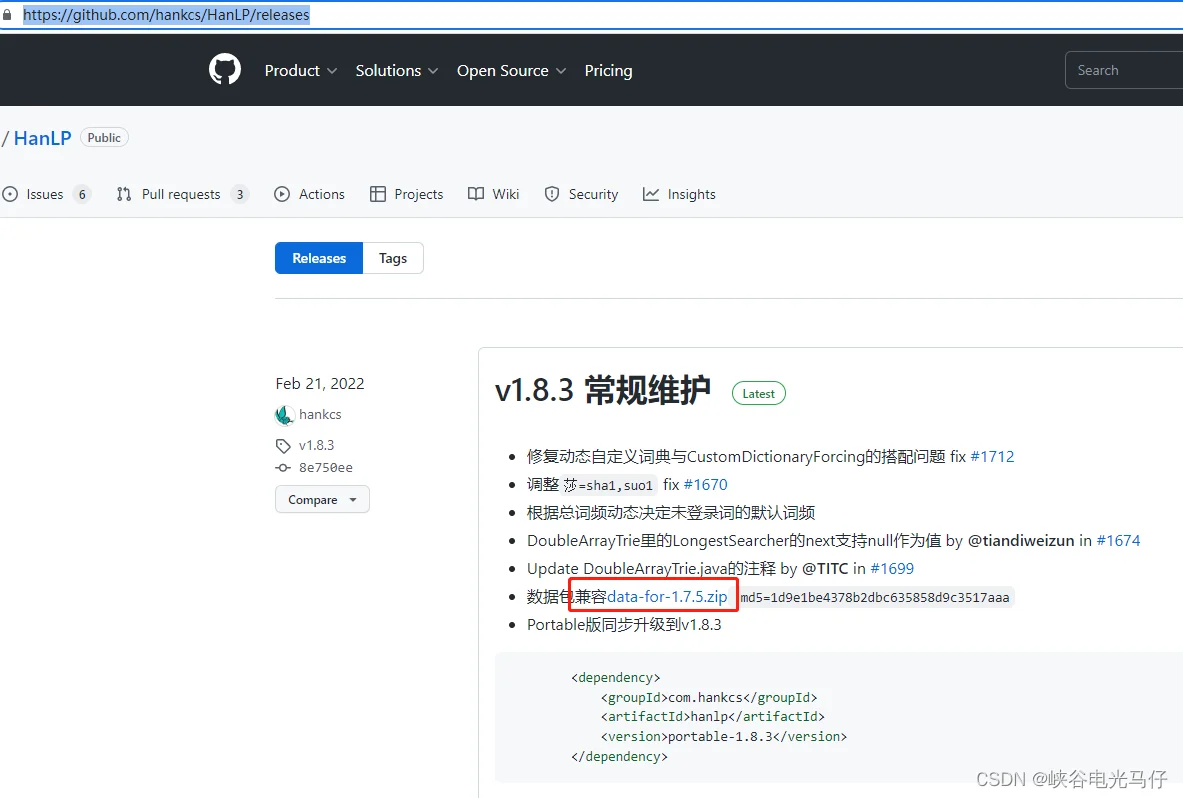
自然语言包配置
resource资源文件夹下新建hanlp.perperties ,如下图:
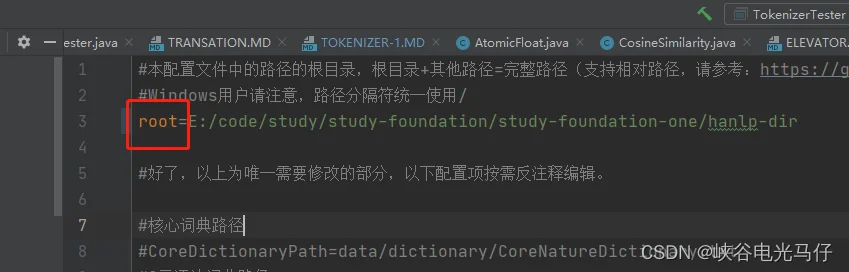
hanlp.properties 配置文件内容如下:
#本配置文件中的路径的根目录,根目录+其他路径=完整路径(支持相对路径,请参考:https://github.com/hankcs/HanLP/pull/254)
#Windows用户请注意,路径分隔符统一使用/
root=E:/code/study/study-foundation/study-foundation-one/hanlp-dir#好了,以上为唯一需要修改的部分,以下配置项按需反注释编辑。#核心词典路径
#CoreDictionaryPath=data/dictionary/CoreNatureDictionary.txt
#2元语法词典路径
#BiGramDictionaryPath=data/dictionary/CoreNatureDictionary.ngram.txt
#自定义词典路径,用;隔开多个自定义词典,空格开头表示在同一个目录,使用“文件名 词性”形式则表示这个词典的词性默认是该词性。优先级递减。
#所有词典统一使用UTF-8编码,每一行代表一个单词,格式遵从[单词] [词性A] [A的频次] [词性B] [B的频次] ... 如果不填词性则表示采用词典的默认词性。
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns;data/dictionary/person/nrf.txt nrf;
#停用词词典路径
#CoreStopWordDictionaryPath=data/dictionary/stopwords.txt
#同义词词典路径
#CoreSynonymDictionaryDictionaryPath=data/dictionary/synonym/CoreSynonym.txt
#人名词典路径
#PersonDictionaryPath=data/dictionary/person/nr.txt
#人名词典转移矩阵路径
#PersonDictionaryTrPath=data/dictionary/person/nr.tr.txt
#繁简词典根目录
#tcDictionaryRoot=data/dictionary/tc
#HMM分词模型
#HMMSegmentModelPath=data/model/segment/HMMSegmentModel.bin
#分词结果是否展示词性
#ShowTermNature=true
#IO适配器,实现com.hankcs.hanlp.corpus.io.IIOAdapter接口以在不同的平台(Hadoop、Redis等)上运行HanLP
#默认的IO适配器如下,该适配器是基于普通文件系统的。
#IOAdapter=com.hankcs.hanlp.corpus.io.FileIOAdapter
#感知机词法分析器
#PerceptronCWSModelPath=data/model/perceptron/pku1998/cws.bin
#PerceptronPOSModelPath=data/model/perceptron/pku1998/pos.bin
#PerceptronNERModelPath=data/model/perceptron/pku1998/ner.bin
#CRF词法分析器
#CRFCWSModelPath=data/model/crf/pku199801/cws.txt
#CRFPOSModelPath=data/model/crf/pku199801/pos.txt
#CRFNERModelPath=data/model/crf/pku199801/ner.txt
#更多配置项请参考 https://github.com/hankcs/HanLP/blob/master/src/main/java/com/hankcs/hanlp/HanLP.java#L59 自行添加
java 代码明细
Word.java
public class Word implements Comparable {// 词名private String name;// 词性private String pos;// 权重,用于词向量分析private Float weight;public Word(String name, String pos) {this.name = name;this.pos = pos;}@Overridepublic int hashCode() {return Objects.hashCode(this.name);}@Overridepublic boolean equals(Object obj) {if (obj == null) {return false;}if (getClass() != obj.getClass()) {return false;}final Word other = (Word) obj;return Objects.equals(this.name, other.name);}@Overridepublic String toString() {StringBuilder str = new StringBuilder();if (name != null) {str.append(name);}if (pos != null) {str.append("/").append(pos);}return str.toString();}@Overridepublic int compareTo(Object o) {if (this == o) {return 0;}if (this.name == null) {return -1;}if (o == null) {return 1;}if (!(o instanceof Word)) {return 1;}String t = ((Word) o).getName();if (t == null) {return 1;}return this.name.compareTo(t);}public String getName() {return name;}public void setName(String name) {this.name = name;}public String getPos() {return pos;}public void setPos(String pos) {this.pos = pos;}public Float getWeight() {return weight;}public void setWeight(Float weight) {this.weight = weight;}
}
Tokenizer.java
public class Tokenizer {/*** 分词*/public static List<Word> segment(String sentence) {//1、 采用HanLP中文自然语言处理中标准分词进行分词List<Term> termList = HanLP.segment(sentence);//打印分词结果。
// System.out.println(termList.toString());//2、重新封装到Word对象中(term.word代表分词后的词语,term.nature代表改词的词性)return termList.stream().map(term -> new Word(term.word, term.nature.toString())).collect(Collectors.toList());}
}
TokenizerTester.java
/*** @Author alan.wang*/
public class TokenizerTester {public static void main(String[] args){String text = "你好美丽的祖国大地,你好美丽的大好河山";
// String text = "HanLP采用的数据预处理与拆分比例与流行方法未必相同,比如HanLP采用了完整版的MSRA命名实体识别语料,而非大众使用的阉割版;HanLP使用了语法覆盖更广的Stanford Dependencies标准,而非学术界沿用的Zhang and Clark (2008)标准;HanLP提出了均匀分割CTB的方法,而不采用学术界不均匀且遗漏了51个黄金文件的方法。HanLP开源了一整套语料预处理脚本与相应语料库,力图推动中文NLP的透明化。\n" +
// "\n" +
// "总之,HanLP只做我们认为正确、先进的事情,而不一定是流行、权威的事情。";List<Word> words = Tokenizer.segment(text);String wordStr = words.stream().map(word -> word.getName()).collect(Collectors.joining(" "));System.out.println(wordStr);}
}验证分词结果
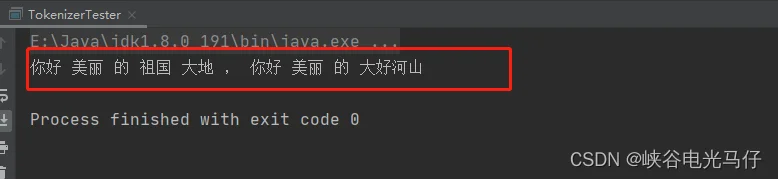
我们先输入字符串:你好美丽的祖国大地,你好美丽的大好河山
输出结果如下:
我们再输入字符串:HanLP采用的数据预处理与拆分比例与流行方法未必相同,比如HanLP采用了完整版的MSRA命名实体识别语料,而非大众使用的阉割版;HanLP使用了语法覆盖更广的Stanford Dependencies标准,而非学术界沿用的Zhang and Clark (2008)标准;HanLP提出了均匀分割CTB的方法,而不采用学术界不均匀且遗漏了51个黄金文件的方法。HanLP开源了一整套语料预处理脚本与相应语料库,力图推动中文NLP的透明化。总之,HanLP只做我们认为正确、先进的事情,而不一定是流行、权威的事情。
输出结果如下:

结语
从输入输出来看,基本上是按照我们自然语言进行分词的,达到了我们人类可以理解的中文分词需求,hanlp 还支持个人主动训练词库,如果自己有特殊分词需要可以按照自己定制化训练方式去训练自己的词库,然后放入词库