

此文整理的基础是建立在hanlp较早版本的基础上的,虽然hanlp的最新1.7版本已经发布,但对于入门来说差别不大!分享一篇比较早的“旧文”给需要的朋友!
安装HanLP
HanLP将数据与程序分离,给予用户自定义的自由。 HanLP由三部分组成:HanLP = .jar + data + .properties ,请前往 项目主页 下载这三个部分。
1、下载jar
放入classpath并添加依赖。
2、下载数据集
HanLP 中的数据分为 词典 和 模型 ,其中 词典 是词法分析必需的, 模型 是句法分析必需的,data目录结构如下:
data
│
├─dictionary
└─model
用户可以自行增删替换,如果不需要句法分析功能的话,随时可以删除model文件夹。
可选数据集
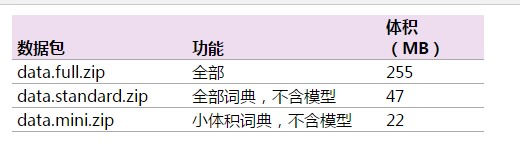
3、配置文件
示例配置文件:
#本配置文件中的路径的根目录,根目录+其他路径=绝对路径
#Windows用户请注意,路径分隔符统一使用/
root=E:/JavaProjects/HanLP/
#核心词典路径
CoreDictionaryPath=data/dictionary/CoreNatureDictionary.txt
#2元语法词典路径
BiGramDictionaryPath=data/dictionary/CoreNatureDictionary.ngram.txt
#停用词词典路径
CoreStopWordDictionaryPath=data/dictionary/stopwords.txt
#同义词词典路径
CoreSynonymDictionaryDictionaryPath=data/dictionary/synonym/CoreSynonym.txt
#人名词典路径
PersonDictionaryPath=data/dictionary/person/nr.txt
#人名词典转移矩阵路径
PersonDictionaryTrPath=data/dictionary/person/nr.tr.txt
#繁简词典路径
TraditionalChineseDictionaryPath=data/dictionary/tc/TraditionalChinese.txt
#自定义词典路径,用;隔开多个自定义词典,空格开头表示在同一个目录,使用“文件名 词性”形式则表示这个词典的词性默认是该词性。优先级递减。
#另外data/dictionary/custom/CustomDictionary.txt是个高质量的词库,请不要删除
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns;data/dictionary/person/nrf.txt nrf
配置文件的作用是告诉HanLP数据包的位置,只需修改第一行
root=usr/home/HanLP/
为data的 父目录 即可,比如data目录是 /Users/hankcs/Documents/data ,那么 root=/Users/hankcs/Documents/ 。
l 如果选用mini数据包的话,则需要修改配置文件:
CoreDictionaryPath=data/dictionary/CoreNatureDictionary.mini.txt
BiGramDictionaryPath=data/dictionary/CoreNatureDictionary.ngram.mini.txt
最后将HanLP.properties放入classpath即可:
对于Eclipse来讲
project/bin
对于IntelliJ IDEA来讲
project/target/classes
或者
project/out/production/project
Web项目的话可以放在如下位置:
Webapp/WEB-INF/lib
Webapp/WEB-INF/classes
Appserver/lib
JRE/lib
快速上手
HanLP 几乎所有的功能都可以通过工具类 HanLP 快捷调用,当你想不起来调用方法时,只需键入 HanLP. ,IDE应当会给出提示,并展示HanLP完善的文档。
推荐用户始终通过工具类 HanLP 调用,这么做的好处是,将来 HanLP 升级后,用户无需修改调用代码。
所有Demo都位于 com.hankcs.demo 下。
第一个Demo:
System.out.println(HanLP.segment("你好,欢迎使用HanLP!"));
l 内存要求
1.HanLP 对词典的数据结构进行了长期的优化,可以应对绝大多数场景。哪怕 HanLP 的词典上百兆也无需担心,因为在内存中被精心压缩过。
2.如果内存非常有限,请使用小词典。 HanLP 默认使用大词典,同时提供小词典,请参考配置文件章节。
3.在一些句法分析场景中,需要加载几百兆的模型。如果发生 java.lang.OutOfMemoryError ,则建议使用JVM option -Xms1g -Xmx1g -Xmn512m。
l 写给正在编译 HanLP 的开发者
1.如果你正在编译运行从Github检出的 HanLP 代码,并且没有下载data,那么首次加载词典/模型会发生一个 自动缓存 的过程。
2.自动缓存 的目的是为了加速词典载入速度,在下次载入时,缓存的词典文件会带来毫秒级的加载速度。由于词典体积很大, 自动缓存 会耗费一些时间,请耐心等待。
3.自动缓存 缓存的不是明文词典,而是双数组Trie树、DAWG、AhoCorasickDoubleArrayTrie等数据结构。
如果一切正常,您会得到类似于如下的输出:
[你好/vl, ,/w, 欢迎/v, 使用/v, HanLP/nx, !/w]
如果出现了问题,一般是由路径配置不对而引发的,请根据控制台输出的警告调整。比如:
核心词典
/Users/hankcs/JavaProjects/HanLP/data/data/dictionary/CoreNatureDictionary.txt加载失败
说明HanLP.properties中的root项配置不对,应当去掉后缀 data/,改为:
root=/Users/hankcs/JavaProjects/HanLP/