
Hanlp中文自然语言处理中的分词方法有标准分词、NLP分词、索引分词、N-最短路径分词、CRF分词以及极速词典分词等。下面就这几种分词方法进行说明。
1) 标准分词
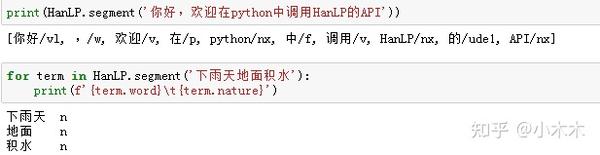
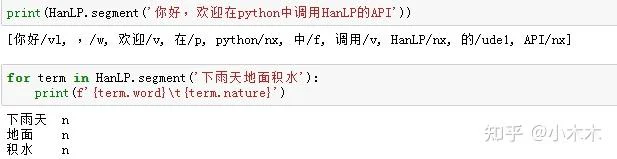
标准分词也是最短路分词,最短路求解采用Viterbi算法。Hanlp中有一系列“开箱即用”的静态分词器,以Tokenizer结尾。HanLP.segment其实是对StandardTokenizer.segment的包装. (ViterbiSegment,DijkstraSegment)
2) NLP分词
NLP分词NLPTokenizer会执行全部命名实体识别和词性标注。()
3) 索引分词
索引分词IndexTokenizer是面向搜索引擎的分词器,能够对长词全切分,另外通过term.offset可以获取单词在文本中的偏移量。
4) N-最短路径分词
NShortSegmentDijkstraSegment5)CRF分词(条件随机场分词)
基于CRF模型和BEMS标注训练得到的分词器。也不支持命名实体识别,应用场景仅限于新词识别。(CRFSegment)
6) 极速词典分词
极速分词是词典最长分词,速度极其快,精度一般。(AhoCorasickSegment)
7)繁体分词
TraditionalChineseTokenizer