
1 安装Anaconda
版本: python3.7
2 安装python IDE
我安装的是wingide,按照安装步骤下载即可。
将wingide与python关联:Project->Project Properties
点击custom,Browse选择Anaconda3安装地址下的python.exe,点击OK
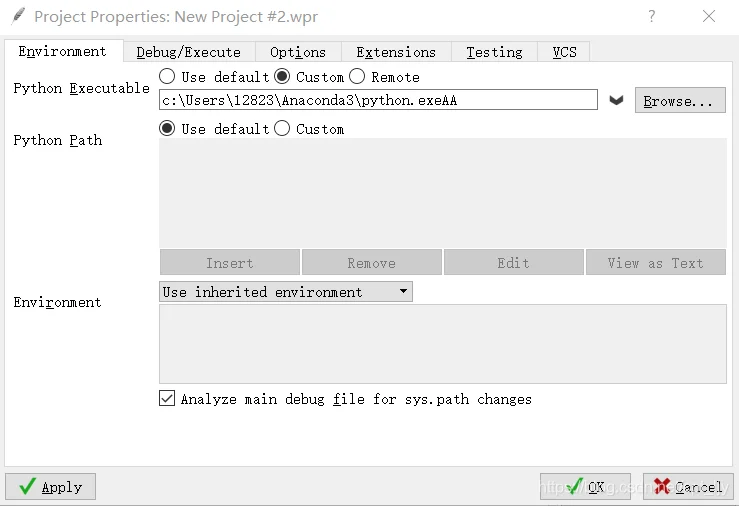
ps:因为与wingide关联的是Anaconda下的python,后续所有安装包均在Anaconda Prompt环境下安装,非cmd环境。否则,若存在不通过Anaconda下载的其他python版本,cmd环境下pip install的安装包将下载到其他python下,报错:XXX not defined/found
3 安装HanLP
(1)安装 Microsoft Visual C++插件
(2)在Anaconda Prompt中安装jpype和pyhanlp:
conda install -c conda-forge jpype1
pip install pyhanlp
若安装jpype失败,可手动安装安装包:jpype安装包地址
pip install JPype1‑0.7.0‑cp37‑cp37m‑win_amd64.whl
ps:注意python版本对应关系,cp37---->python3.7 cp27---->python2.7
下载完pyhanlp后不能立即使用,
(3)在命令行中import pyhanlp,它会自动下载jar包、data文件和properties文件到默认的目录,data文件比较大1个G左右。
(4)配置Java环境:因为hanlp是java开发的虽然有python的API但是还是需要java环境,所以需要安装JDK。
(5)设置java环境变量:

C:\Program Files\Java\jdk1.8.0_221
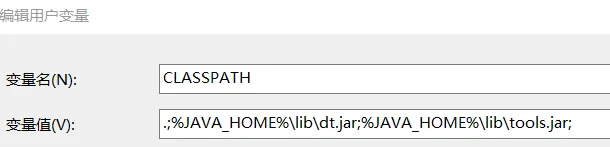
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
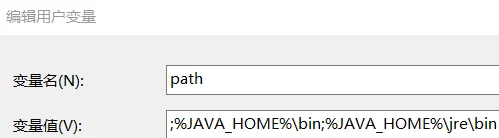
;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
(6)在wingide中验证 pyhanlp是否安装成功:
#encoding=utf8
from pyhanlp import *
print(HanLP.segment("您好,欢迎使用HanLP"))
若报错:builtins.ValueError: 配置错误: 数据包 C:/Users/Adminstrate/Anaconda3/lib/site-packages/pyhanlp/static\data 不存在,请修改配置文件中的root
说明import pyhanlp时下载data文件失败,可手动下载配置
(1)下载data,将data文件放到提示目录Anaconda3\Lib\site-packages\pyhanlp\static下
(2) 打开Anaconda3\Lib\site-packages\pyhanlp\static目录下的hanlp.properties,修改root=C:/Users/Adminstrate/Anaconda3/lib/site-packages/pyhanlp/static. (root=存放data的父目录)
解决方案:
4 HanLP各种分词方法
#encoding=utf8
from pyhanlp import *
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
PerceptronLexicalAnalyzer = JClass('com.hankcs.hanlp.model.perceptron.PerceptronLexicalAnalyzer')
analyzer = PerceptronLexicalAnalyzer()
print(analyzer.analyze("上海华安工业(集团)公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观"))
print("="*30+"HanLP分词"+"="*30)
HanLP = JClass('com.hankcs.hanlp.HanLP')
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))
print('-'*70)
print("="*30+"标准分词"+'='*30)
StandardTokenizer = JClass('com.hankcs.hanlp.tokenizer.StandardTokenizer')
print(StandardTokenizer.segment('上海华安工业(集团)公司董事长谭旭光和秘书胡花蕊来到美国纽约现代艺术博物馆参观'))
print('-'*70)
#NLP分词NLPTokenizer会执行全部命名实体识别和词性标注
print('='*30+'NLP分词'+'='*70)
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment('中国科学院计算技术研究所得宗成庆教授正在教授自然语言处理课程'))
print('-'*70)
print('='*30+"索引分词"+'='*30)
IndexTokenizer = JClass('com.hankcs.hanlp.tokenizer.IndexTokenizer')
termlist = IndexTokenizer.segment("主副食品")
for term in termlist:
print(str(term)+"["+str(term.offset)+":"+str(term.offset+len(term.word))+"]")
print('-'*70)
print('='*30+"CRF分词"+'='*30)
print('-'*70)
print('='*30+"急速词典分词"+'='*30)
SpeedTokenizer = JClass('com.hankcs.hanlp.tokenizer.SpeedTokenizer')
print(NLPTokenizer.segment('江西鄱阳湖干枯,中国最大淡水湖变成大草原'))
print('-'*70)
print('='*30+"自定义分词"+'='*30)
customDictionary = JClass('com.hankcs.hanlp.dictionary.CustomDictionary')
customDictionary.add('攻城狮')
customDictionary.add('单身狗')
print(HanLP.segment('攻城狮逆袭单身狗,迎娶白富美,走上人生巅峰'))
print('-'*70)
document = "水利部水资源司司长陈明聪9月29日在国务院新闻办举行的新闻发布会上透露."\
"根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标。"\
"有部分省接近了红线的指标。对一些超过红线的地方,陈明忠表示,对一些取水项目进行区域的限批,"\
"严格的进行水资源论证和取水许可的批准。"
print('='*30+"关键词提取"+'='*30)
print(HanLP.extractKeyword(document,8))
print('-'*70)
print('='*30+"自动摘要"+'='*30)
print(HanLP.extractSummary(document,3))
print('-'*70)
text = r"算法工程师\n算法(Algorithm)是一系列解决问题的指令,也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出,"
print('='*30+"短语提取"+'='*30)
print(HanLP.extractPhrase(text,10))
print('-'*70)