
本部分只对相关概念做服务于差分隐私介绍的简单介绍,并非细致全面的介绍。
1.1 随机化算法随机化算法指,对于特定输入,该算法的输出不是固定值,而是服从某一分布。
单纯形(simplex):一个\(k\)维单纯形是指包含\(k+1\)个顶点的凸多面体,一维单纯形是一条线段,二维单纯形是一个三角形,三维单纯形是一个四面体,以此类推推广到任意维。“单纯”意味着基本,是组成更复杂结构的基本构件。
概率单纯形(probability simplex):是一个数学空间,上面每个点代表有限个互斥事件之间的概率分布。该空间的每条坐标轴代表一个互斥事件,\(k-1\)维单纯形上的每个点在\(k\)维空间中的坐标就是其\(k\)个互斥事件上的概率分布。每一点的坐标(向量)包含\(k\)个元素,各元素非负且和为1。
如下图所示,三个事件发生的概率分布形成一个二维的概率单纯形,上面每个点在三个事件上发生的概率之和为1。
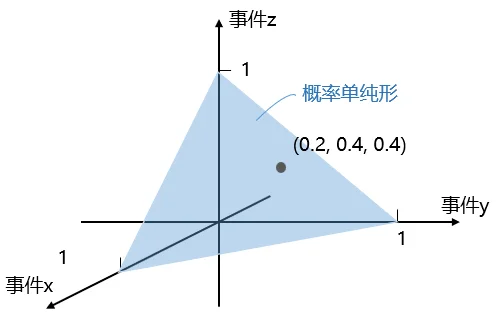
形式化定义:给定一个离散集\(B\),\(B\)上的概率单纯形\(\Delta(B)\)被定义为
\[\Delta(B)=\left\{x \in \mathbb{R}^{|B|}\left|x_{i} \geq 0, i=1,2, \cdots,\right| B \mid ; \sum_{i=1}^{|B|} x_{i}=1\right\} \]\(\Delta(B)\)是一个集合,集合中每一个元素是一个\(|B|\)维向量,该向量代表了一个离散型随机变量的概率分布。\(\Delta(B)\)代表了一个有\(|B|\)种取值的离散型随机变量的所有可能的概率分布。
随机化算法(randomized algorithm):一个随机化算法\(\cal{M}\)有定义域\(A\)、离散的值域\(B\)。一个输入\(a\in A\),算法\(\cal{M}\)的输出\(\mathcal{M}(a)\)是一个随机变量,服从概率分布\(p(x)=\operatorname{Pr}(\mathcal{M}(a)=x),x\in B\),并且\(p(x)\in \Delta(B)\)。
例如,\(A=\{2,3,4\}\),\(B=\{1,2,3,4,5\}\),设\(\Delta(B)\)中包含三个元素,分别为\((\frac{1}{3},\frac{1}{3},\frac{1}{3},0,0)\)、\((0,\frac{1}{3},\frac{1}{3},\frac{1}{3},0)\)、\((0,0,\frac{1}{3},\frac{1}{3},\frac{1}{3})\),即
\[\Delta(B)=\left\{ (\frac{1}{3},\frac{1}{3},\frac{1}{3},0,0), (0,\frac{1}{3},\frac{1}{3},\frac{1}{3},0), (0,0,\frac{1}{3},\frac{1}{3},\frac{1}{3}) \right\} \]每个元素均代表算法输出的随机变量取值为1,2,3,4,5的概率分布,现可以规定映射\(\cal{M}\)为
\[\mathcal{M}(2)\sim \left(\frac{1}{3}, \frac{1}{3}, \frac{1}{3}, 0,0\right), \mathcal{M}(3)\sim \left(0, \frac{1}{3}, \frac{1}{3}, \frac{1}{3}, 0\right), \mathcal{M}(4)\sim \left(0,0, \frac{1}{3}, \frac{1}{3}, \frac{1}{3}\right) \]也就是说,一个特定输入\(a\in A\)经过随机化算法\(\cal{M}\)得到的不是一个具体值\(b\in B\),而是一个随机变量\(\mathcal{M}(a) \sim p(x),p(x)\in \Delta(B)\),又或者说,算法将以一定概率输出某一个值。
1.2 KL散度(KL-Divergence)上述情况是在离散概率空间中讨论的,有时,算法将从连续分布中的采样,但最后将以适当的精度进行离散化。
KL散度(Kullback Leible-Divergence)概念来源于概率论与信息论,又被称作相对熵、互熵。从统计学意义上来说,KL散度可以用来衡量两个分布之间的差异程度,差异越小,KL散度越小。
熵(entropy):信息论中熵定义首次被香农提出:无损编码事件信息的最小平均编码长度。通俗理解,如果熵比较大,即对该信息进行编码的最小平均编码长度较长,意味着该信息具有较多可能的状态,即有着较大的信息量/混乱程度/不确定性。从某种角度上看,熵描述了一个概率分布的不确定性。
一个离散的随机变量\(X\)可能取值为\(X=x_1,x_2,...,x_n\),即取值空间为\(\cal{X}=\{x_1,x_2,...,x_n\}\),概率分布律为\(p(x)=\operatorname{Pr}(X=x),x\in \cal{X}\),则随机变量的熵定义为
\[\begin{aligned} H(X)&=-\sum_{x\in \cal{X}} p \left(x\right) \log p \left(x\right) \\ &=\mathbb{E}_{x \sim p}\left[-\log p(x)\right] \end{aligned} \]规定当\(p(x)=0\)时,\(p(x)\log p(x)=0\)。
其中,\(-\log p(x)\)表示状态\(X=x\)的最小编码长度。
\(\operatorname{Pr}(A)\)也即\(\operatorname{P}(A)\),表示事件\(A\)发生的概率,只是书写习惯不同,避免与其他\(P\)混淆。
有时也将上面的量记为\(H(p)\);
公式中的\(\mathbb{E}_{x \sim p}\)表示使用概率分布\(p\)来计算期望;
其中\(\log\)以2为底时,熵单位为bit,以e为底时,熵单位为nat;
上述的对熵的讨论也只是针对离散随机变量进行讨论的,\(p(x)\)在离散型随机变量中为概率分布律,在连续型随机变量中为概率密度函数;
交叉熵(cross-entropy):熵的计算是已知各状态的概率分布求其理论上最小平均编码长度。如果不知道各状态真实的概率分布\(p(x)\),只有预估的概率分布\(q(x)\),我们只好根据预估的概率分布\(q(x)\)给事件编码,得到事件各状态\(x\)的预估最小编码长度\(-\log q(x)\)。假如经过观测后我们得到了真实概率分布\(p(x)\),那么在计算预估最小编码长度\(-\log q(x)\)的期望时就可以采用真实概率分布\(p(x)\),得到交叉熵。
对于同一取值空间\(\cal{X}=\{x_1,x_2,...,x_n\}\)下的离散随机变量\(P,Q\),概率分布分别为\(p(x)=\operatorname{Pr}(P=x),q(x)=\operatorname{Pr}(Q=x),x\in \cal{X}\),交叉熵定义为
\[\begin{aligned} H(P, Q)&=\sum_{x\in \cal{X}} p(x) \log \frac{1}{q(x)} \\ &=-\sum_{x\in \cal{X}} p(x) \log q(x) \\ &=\mathbb{E}_{x \sim p}\left[-\log q(x)\right] \end{aligned} \]即用预估概率分布\(q(x)\)计算每个状态的最小编码长度,用真实概率分布\(p(x)\)求期望。可见,\(H(P,Q)\neq H(Q,P),H(P,Q)\geqslant H(P)\)。
上述定义也可写作:对于取值空间\(\cal{X}\)的离散随机变量\(X\),有两个分布\(p(x),q(x),x\in \cal{X}\),这也是《信息论基础(原书第二版)》的表达方式;但考虑到一个随机变量对应一个分布更严谨些,便分成了同一取值空间的两个随机变量进行解释,这是《The Algorithmic Foundations of Differential Privacy》的表达方式。二者意思是一样的。
相对熵(relative entropy)/KL散度(KL-divergence):用来衡量交叉熵与熵之间的差距的,也是两个随机分布之间距离的度量。
对于同一取值空间\(\cal{X}=\{x_1,x_2,...,x_n\}\)下的离散随机变量\(P,Q\),概率分布分别为\(p(x)=\operatorname{Pr}(P=x),q(x)=\operatorname{Pr}(Q=x),x\in \cal{X}\),则\(P\)相对\(Q\)的相对熵为\(P,Q的交叉熵-P的熵\):
\[\begin{aligned} D_{K L}(P \| Q) &=H(P, Q)-H(P) \\ &=-\sum_{x\in \cal{X}} p(x) \log q(x)-\sum_{x\in \cal{X}}-p(x) \log p(x) \\ &=-\sum_{x\in \cal{X}} p(x)(\log q(x)-\log p(x)) \\ &=-\sum_{x\in \cal{X}} p(x) \log \frac{q(x)}{p(x)} \\ &=\sum_{x\in \cal{X}} p(x) \log \frac{p(x)}{q(x)} \\ &=\mathbb{E}_{x \sim p}\left[-\log q(x)\right]-\mathbb{E}_{x \sim p}\left[-\log p(x)\right]\\ &=\mathbb{E}_{x \sim p}\left[\log \frac{p(x)}{q(x)}\right] \end{aligned} \]可见,KL散度也可以用来衡量两个分布\(P,Q\)的差异程度,另外,\(D_{K L}(P \| Q) \neq D_{K L}(Q \| P)\geqslant 0\)。
最大散度(Max Divergence):KL散度是从整体上衡量两个分布的距离,最大散度是两个分布比值的最大值,从两个分布比值的最大值角度衡量了两个分布的差异。
对于同一取值空间\(\cal{X}=\{x_1,x_2,...,x_n\}\)下的离散随机变量\(P,Q\),概率分布分别为\(p(x)=\operatorname{Pr}(P=x),q(x)=\operatorname{Pr}(Q=x),x\in \cal{X}\),最大散度为
\[\begin{aligned} D_{\infty}(P \| Q)&=\max _{x\in \cal{X}}\left[\log \frac{\operatorname{Pr}[P=x]}{\operatorname{Pr}[Q=x]}\right] \\ &=\max _{x\in \cal{X}}\left[\log \frac{p(x)}{q(x)}\right] \end{aligned} \]2 差分隐私定义差分隐私是Dwork在2006年首次提出的一种隐私定义,函数的输出结果对数据集中任何特定记录都不敏感。
假设对于一个考试成绩数据集\(D\),通过查询操作得知有\(x\)个同学不及格,现加入一条新纪录得到新数据集\(D'\),通过查询得知有\(x+1\)个同学不及格,便可推理出新加入的同学成绩不及格,如此一来,攻击者便通过这样的手段推理出了一些知识。
应对上述攻击,差分隐私通过往查询结果\(f(D),f(D')\)中加入随机噪声\(r\)最终得到查询结果\(\mathcal{M}(D)=f(D)+r,\mathcal{M}(D')=f(D')+r\),使得\(D\)与\(D'\)经过同一查询后的结果并非确定的具体值,而是服从两个很接近的概率分布,这样攻击者无法辨别查询结果来自哪一个数据集,保障了个体级别的隐私性。
2.1 形式化定义邻接数据集(neighbor datasets):仅有一条记录不同的两个数据集\(D\),\(D'\)。
随机化算法\(\cal{M}\):随机化算法指,对于特定输入,该算法的输出不是固定值,而是服从某一分布。
隐私预算\(\epsilon\)(privacy budget):\(\epsilon\)用于控制算法的隐私保护程度,\(\epsilon\)越小,则算法保护效果越好。
隐私损失(privacy loss):对于任意的输出结果\(S\),\(\ln \frac{\operatorname{Pr}[\mathcal{M}(\mathrm{D}) \in \mathrm{S}]}{\operatorname{Pr}\left[\mathcal{M}\left(\mathrm{D}^{\prime}\right) \in \mathrm{S}\right]}\)或\(\ln \frac{\operatorname{Pr}[\mathcal{M}(\mathrm{D}) = \mathrm{\xi}]}{\operatorname{Pr}\left[\mathcal{M}\left(\mathrm{D}^{\prime}\right) = \mathrm{\xi}\right]}\),其描述了算法\(\cal{M}\)在邻接数据集上输出同一个值的概率差别大小,差分隐私机制将算法的隐私损失控制在一个有限范围\(\epsilon\)内。
隐私损失可正可负,越正和越负都表示隐私损失很大,因此严格来说隐私损失应加个绝对值,为
\[Privacyloss=\left |\ln \frac{\operatorname{Pr}[\mathcal{M}(\mathrm{D}) \in \mathrm{S}]}{\operatorname{Pr}\left[\mathcal{M}\left(\mathrm{D}^{\prime}\right) \in \mathrm{S}\right]}\right | \]当然,如没有加绝对值的地方默认\(\operatorname{Pr}[\mathcal{M}(\mathrm{D}) \in \mathrm{S}] \geqslant \operatorname{Pr}[\mathcal{M}(\mathrm{D'}) \in \mathrm{S}]\)。
\(\epsilon-\)差分隐私:对于只有一个记录不同的邻接数据集\(D\)、\(D'\),给这两个数据集施加一个随机化算法(机制)\(\cal{M}\),对于所有的\(S\subseteq \operatorname{Range}(\mathcal{M})\),若有
\[\operatorname{Pr}[\mathcal{M}(D) \in S] \leqslant \operatorname{Pr}\left[\mathcal{M}\left(D' \right) \in S\right] \times \mathrm{e}^{\epsilon} \]即
\[\max _{S}\left[\ln \frac{\operatorname{Pr}[\mathcal{M} (D) \in S]}{\operatorname{Pr}\left[\mathcal{M}\left(D' \right) \in S\right]}\right] \leqslant \epsilon \]成立,则称算法\(\cal{M}\)满足\(\epsilon-\)差分隐私。
其中\(\operatorname{Range}(\mathcal{M})\)是随机算法\(\cal{M}\)映射结果随机变量的取值空间,\(S\)是其子集;对于所有的\(S\subseteq \operatorname{Range}(\mathcal{M})\)即对于\(\operatorname{Range}(\mathcal{M})\)的所有子集。
另种写法:
\[\operatorname{Pr}[\mathcal{M}(D) =x] \leqslant \operatorname{Pr}\left[\mathcal{M}\left(D' \right) =x\right] \times \mathrm{e}^{\epsilon},x\in S \]即
\[\max _{x\in S}\left[\log \frac{\operatorname{Pr}[\mathcal{M}(D)=x]}{\operatorname{Pr}[\mathcal{M}(D')=x]}\right] \leqslant \epsilon \]
\((\epsilon,\sigma)-\)差分隐私:上面描述的是严格的差分隐私的定义,为了算法的实用性,Dwork后面引入了松弛的差分隐私,加入一个小常数\(\delta\)(称作失败概率):
\[\operatorname{Pr}[\mathcal{M}(D) \in S] \leqslant \operatorname{Pr}\left[\mathcal{M}\left(D' \right) \in S\right] \times \mathrm{e}^{\epsilon}+\delta \]2.2 该定义是如何得来的差分隐私的目的是使\(\mathcal{M}(D),\mathcal{M}(D')\)的分布尽可能接近,便可用Max Divergence衡量两个分布的差异:
\[\begin{aligned} D_{\infty}(\mathcal{M}(D) \| \mathcal{M}(D')) &=\max _{x\in S}\left[\log \frac{\operatorname{Pr}[\mathcal{M}(D)=x]}{\operatorname{Pr}[\mathcal{M}(D')=x]}\right] \\ &=\max _{S}\left[\log \frac{\operatorname{Pr}[\mathcal{M}(D) \in S]}{\operatorname{Pr}[\mathcal{M}(D') \in S]}\right] \end{aligned} \]其中\(S\subseteq \operatorname{Range}(\mathcal{M})\),\(\operatorname{Range}(\mathcal{M})\)是随机算法\(\cal{M}\)映射结果随机变量的取值空间,\(S\)是其子集。
对于\(\operatorname{Range}(\mathcal{M})\)的所有子集,即对于任意的\(S\subseteq \operatorname{Range}(\mathcal{M})\),两个分布的差异都被限制在隐私预算\(\epsilon\)以内:
\[\max _{x\in S}\left[\log \frac{\operatorname{Pr}[\mathcal{M}(D)=x]}{\operatorname{Pr}[\mathcal{M}(D')=x]}\right] =\max _{S}\left[\log \frac{\operatorname{Pr}[\mathcal{M}(D) \in S]}{\operatorname{Pr}[\mathcal{M}(D') \in S]}\right] \leqslant \epsilon \]可见,上述的Max Divergence就是隐私损失。
取\(\log\)的底为\(e\),并两边同时利用指数运算、乘以分母变形得:
\[\operatorname{Pr}[\mathcal{M}(D) =x] \leqslant \operatorname{Pr}\left[\mathcal{M}\left(D' \right) =x\right] \times \mathrm{e}^{\epsilon},x\in S \]或
\[\operatorname{Pr}[\mathcal{M}(D) \in S] \leqslant \operatorname{Pr}\left[\mathcal{M}\left(D' \right) \in S\right] \times \mathrm{e}^{\epsilon} \]3 差分隐私中常用的随机化算法(机制)常用的随机化机制有:
- 拉普拉斯机制(Laplace mechanism)
- 指数机制(Exponential mechanism)
- 高斯机制(Gaussian mechanism)
这些机制中,噪声发现取决于算法的敏感度。
敏感度(sensitivity):对于只有一个记录不同的两个数据集\(D,D'\),对于一个函数\(\mathcal{M}:\cal{D} \rightarrow \cal{R^d}\),则\(\cal{M}\)的敏感度为接收所有可能的输入后,得到输出的最大变化值:
\[\Delta \mathcal{M}=\max _{D, D^{\prime}}\left\|\mathcal{M}(D)-\mathcal{M}\left(D^{\prime}\right)\right\| \]其中,\(\|\cdot\|\)表示向量的范数。\(l_1-\)敏感度和\(l_2-\)敏感度分别适用于\(l_1\)范数和\(l_2\)范数。
参考资料:
- 概率单纯形 https://zhuanlan.zhihu.com/p/479892005
- 【数学知识】KL散度 https://zhuanlan.zhihu.com/p/365400000
- 一文搞懂熵(Entropy),交叉熵(Cross-Entropy) https://zhuanlan.zhihu.com/p/149186719
- 差分隐私Differential Privacy介绍 https://zhuanlan.zhihu.com/p/40760105
- 差分隐私(一) Differential Privacy 简介 https://zhuanlan.zhihu.com/p/139114240
- 差分隐私的算法基础 第二章 第三节 形式化差分隐私 https://zhuanlan.zhihu.com/p/502656652
- 《联邦学习》杨强.et al 电子工业出版社
- 机器学习的隐私保护研究综述. 刘俊旭 孟小峰 doi: 10.7544/issn1000-1239.2020.20190455
- 《The Algorithmic Foundations of Differential Privacy》Dwork.et al 3.5.1
- 《信息论基础(原书第2版)》Thomas.et al 机械工业出版社