
内容:背景/隐私/差分隐私的概念/怎样实现拉普拉斯机制/怎样在机器学习中运用差分隐私
0.背景
- 企业需要利用用户数据提升产品和服务质量,用户希望从产品和服务中受益但不希望自己的数据被泄露。
- 欧盟《通用数据保护条例》(General Data Protection Regulation,GDPR)已于2018年5月25日正式生效,谷歌、Facebook等多个产品就隐私问题被投诉。
- 2019年5月28日,国家互联网信息办公室发布了《数据安全管理办法(征求意见稿)》,提出在中华人民共和国境内利用网络开展数据收集、存储、传输、处理、使用等活动,以及数据安全的保护和监督管理,均适用于本方法。
1.隐私
行业内对隐私没有统一的概念定义,较为一致的解释是将“特定个体的某种或某些属性”称为隐私。也就是说只有牵涉到某特定个体的信息才可以称之为隐私,一个群体的某种或某些属性并不能称之为隐私。
举个例子:高德地图曾在《2016年度中国主要城市交通分析报告》中统计了各类车型车主最爱去的场所,结果显示奔驰车主住别墅,宝马车主爱购物,沃尔沃车主很文艺,…,而凯迪拉克车主偏爱去洗浴中心。


很多人认为这一统计结果暴露了隐私。这不算,因为这其中并没有牵涉到任何特定个体,这一统计结果只是发布了一个趋势。考虑以下场景:
场景一:小a是一位凯迪拉克车主,他爱去洗浴中心。
这属于隐私泄露。
场景二:假设我们已经得知了凯迪拉克车主爱去洗浴中心这一统计结果,然后又知道小a是一名凯迪拉克车主,因此我们猜测小a爱去洗浴中心。
这属于隐私泄露吗?不是,因为小a爱不爱去是我们通过某个统计结果猜测出来的,真实的信息我们并不能确定。
2.差分隐私的概念
差分隐私(Differential Privacy)是一个框架,用于评估一个旨在保护隐私的机制(算法)所提供的隐私保证。
它的数学定义[1]如下:
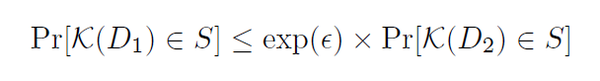
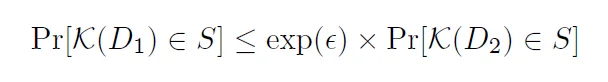
我们不需要现在去理解它的数学意义,暂且跳过这个公式也不会影响接下来的理解。它的核心思想就是说,对于相差一条记录的两个数据集(D1,D2),查询它们获得相同结果的概率(Pr)是非常接近的,对于非常接近的衡量是由公式中的 ε 决定的,称其为隐私预算(privacy budget)。
进一步来说,如果能设计一种算法,让攻击者在查询100条信息和去掉任意一条信息的其它99条信息时,获得的结果是一致的,那攻击者就没办法确定出第100条信息了,这样我们就说第100条信息对应的个体得到了隐私保护。
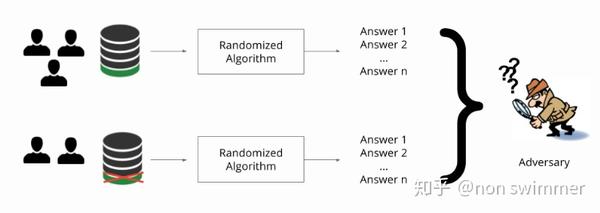
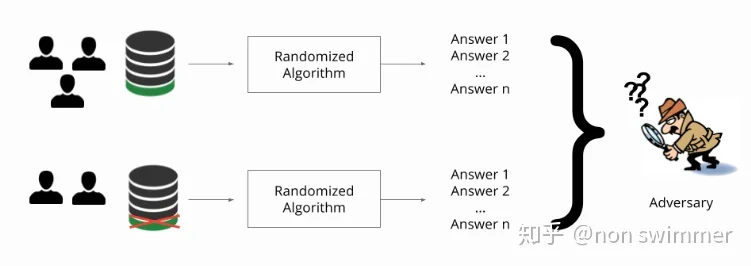
为了满足差分隐私的思想,通常的做法是向查询结果中引入随机性。对于数值型的查询结果,常用的方法是向查询结果中加入服从拉普拉斯分布的噪声,这种方法被称为拉普拉斯机制。
3.怎样实现拉普拉斯机制?
对于一般的count查询,我们这样实现拉普拉斯机制:
其中 ε 是上述公式中的privacy budget,可以自己设置其取值,越小意味着隐私保证越强。
是不是很简单呐,你现在还不需要深入理解差分隐私的数学意义,就能够进行一个简单的实现了。


Python在numpy模块里已经封装好了laplace函数,位置参数loc和尺度参数scale控制拉普拉斯分布的shape,数组型参数size控制从该分布中抽取的样本数,将参数设置好直接调用即可。
下面是以Adult数据集为例,向属性Age的count查询结果加入噪声前后的Age分布直方图。
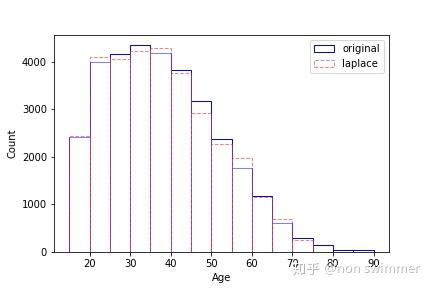
4.怎样在机器学习中运用差分隐私?
在机器学习的许多应用中,比如医学领域的机器学习研究,我们并不希望机器学习算法记住训练集的敏感信息,比如某个病人的特定病史。
前面提到,差分隐私是一个框架,用于度量一个旨在保护隐私的机制(算法)所提供的隐私保证。基于此,机器学习方面的研究者也可以为隐私保护的机器学习方法做贡献,即使他们不是差分隐私方面的专家。
目前训练差分隐私的机器学习模型的关键方法有两种,典型的代表是DP-SGD和PATE。DP-SGD[2]是对随机梯度下降算法进行改进而能够实现差分隐私机器学习的方法。PATE是一个通过联合多个机器学习算法实现从隐私数据上训练机器学习模型的框架。
这里只展示DP-SGD的一个片段,目的是让读者感受一下它的精妙之处,对其具体实现方法有一个初步的了解。后续会对两种方法做独立成文的介绍。
我们知道随机梯度下降是机器学习中很多optimizer的基础,用tensorflow实现设计一个梯度下降优化器的代码片段如下:
这是一个不具有差分隐私的版本。如果我们希望将其改进成具有差分隐私的版本,做法如下:
optimizers.dp_optimizer是tensorflow privacy[3]提供的模块,站在巨人的肩膀上,我们很容易的就实现了差分隐私版本的optimizer。同样地,差分隐私版本的adam optimizer的实现方法就是将对应位置替换成DPAdamGaussianOptimizer()。具体的参数解释及方法要义后续再与大家分享。
注:本文是结合个人理解对差分隐私的一个简单介绍,需要说明的是实现差分隐私的机制有拉普拉斯机制和指数机制两种,这里只简单介绍了拉普拉斯机制。同时,差分隐私在不同场景下被分为交互式和非交互式两种,用于单纯数据发布场景的通常是非交互式的,即数据发布出去后就切断了与发布方的联系,因此也叫去中心化的差分隐私;交互式的差分隐私的典型案例就是Google的Chrome浏览器收集用户行为数据的技术。
欢迎相关领域的researchers交流指正。
部分参考资料
[1] Dwork C. Differential Privacy[C]// International Colloquium on Automata, Languages, & Programming. 2006.
[2] Abadi, M., Chu, A., Goodfellow, I.J., McMahan, H.B., Mironov, I., Talwar, K.,Zhang, L.: Deep learning with differential privacy. In Weippl, E.R., Katzen-beisser, S., Kruegel, C., Myers, A.C., Halevi, S., eds.: Proceedings of the 2016ACM SIGSAC Conference on Computer and Communications Security, Vienna,Austria, October 24-28, 2016, ACM (2016) 308–318