
一、关于连接池
一个数据库服务器只拥有有限的资源,如果这些资源没有被充分使用,我们可以通过使用更多的连接来提高吞吐量。一旦所有的资源都在使用,我们就不能通过增加更多的连接来提高吞吐量。事实上,吞吐量在连接负载较大时就开始下降了。通常可以通过限制与可用的资源相匹配的数据库连接数量来提高延迟和吞吐量。
如果不使用连接池,那么每次传输数据,我们都需要进行创建连接,收发数据,关闭连接。在并发量不高的场景,基本上不会有什么问题,一旦并发量上去了,一般就会遇到下面几个常见问题:
性能普遍上不去
CPU 大量资源被系统消耗
网络一旦抖动,会有大量 TIME_WAIT 产生,不得不定期重启服务或定期重启机器
服务器工作不稳定,QPS 忽高忽低
要想解决这些问题,我们就要用到连接池了。连接池的思路很简单,在初始化时,创建一定数量的连接,先把所有长连接存起来,谁需要使用,从这里取走,干完活立马放回来。 如果请求数超出连接池容量,那么就排队等待、退化成短连接或者直接丢弃掉。
二、使用连接池遇到的坑
最近在一个项目中,我需要实现一个简单的 web server 提供 Redis 的 HTTP interface,提供 JSON 形式的返回结果。我考虑用 Go 来实现。
首先,我去看了一下 Redis 官方推荐的 Go Redis driver。官方 Star 的项目有两个:Radix.v2 和 Redigo。经过简单的比较后,我选择了更加轻量级和实现更加优雅的 Radix.v2。
Radix.v2 包根据功能划分成一个个 sub-package,每一个 sub-package 在一个独立的子目录中,结构非常清晰。我的项目中会用到的 sub-package 有 redis 和 pool。
由于我想让这种被 fork 的进程简单点,做的事情单一一些,所以,在没有深入看 Radix.v2 的 pool 实现之前,我选择了自己实现一个 Redis pool。这里就不贴代码了。(后来发现自己实现的 Redis pool 与 radix.v2 实现的 Redis pool 的原理是一样的,都是基于 channel 实现的, 遇到的问题也是一样的。)
不过在测试过程中,我发现了一个诡异的问题。请求过程中经常会报 EOF 错误。而且是概率性出现,一会有问题,一会又好了。通过反复测试,发现 bug 是有规律的,当程序空闲一会后,再进行连续请求,会发生 3 次失败,之后的请求都能成功,而我的连接池大小设置是 3 。进一步分析,程序空闲 300 秒后,再请求就会失败,发现我的 redis-server 配置了 timeout 300,至此,问题就清楚了。是连接超时 redis-server 主动断开了连接。客户端这边从一个超时的连接请求就会得到 EOF 错误。
然后我看了一下 radix.v2 的 pool 包源码,发现这个库本身并没有检测坏的连接并替换为新的连接的机制。也就是说我每次从连接池里面 Get 的连接有可能是坏的连接。我当时临时的解决方案是通过增加失败后自动重试来解决。不过,这样的处理方案,连接池的作用就没有了。技术债能早点还的还是早点还上。
三、使用连接池的正确姿势
想到我们的 ngx_lua 项目里面也大量使用 redis 连接池,他们怎么没有遇到这个问题呢。只能去看看源码了。
经过抽象分离, ngx_lua 里面使用 redis 连接池部分的代码大致是这样的

发现有个 set_keepalive 的方法,查了一下官方文档,方法的原型是 syntax: ok, err = red:set_keepalive(max_idle_timeout, pool_size) 貌似 max_idle_timeout 这个参数,就是我们所缺少的东西,然后进一步跟踪源码,看看里面是怎么保证连接有效的。

至此,已经清楚了,程序使用了 tcp 的 keepalive 心跳机制。
于是,通过与 radix.v2 的作者一些讨论,选择自己在 redis 这层使用心跳机制,来解决这个问题。
四、最后的解决方案
在创建连接池之后,起一个 goroutine,每隔一段 idleTime 发送一个 PING 到 redis-server。其中,idleTime 略小于 redis-server 的 timeout 配置。
连接池初始化部分代码如下:
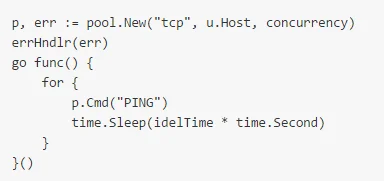
使用 redis 传输数据部分代码如下:

其中,radix.v2 连接池内部进行了连接池内连接的获取和放回,代码如下:

这样,我们就有了 keepalive 的机制,不会出现 timeout 的连接了,从 redis 连接池里面取出的连接都是可用的连接了。看似简单的代码,却完美的解决了连接池里面超时连接的问题。同时,就算 redis-server 重启等情况,也能保证连接自动重连。
