

0,Go 学习资料
https://golang.google.cn/https://go.dev/Go 语言不是面向对象语言。
Go 语言的三位创始人:

(从左到右分别是Robert Griesemer、Rob Pike和Ken Thompson)
Go 语言历史年表
| 时间 | 事件 |
|---|---|
| 2007年9月 | 三位创始人进行了一次讨论会 |
| 2008年 | 肯·汤普森实现了第一版 Go 编译器 |
| 2009年11月10日 | 谷歌宣布开源 Go 语言,这一天为 Go 诞生日 |
| 2012年3月 | Go 1.0 发布,并宣布 Go 编译器永远兼容旧代码 |
| 2014年 | Go 1.4 发布,最后一个编译器和运行时由 C 语言实现的版本 |
| 2015年 | Go 1.5 发布,实现自举,大幅降低 GC 延迟 |
| 2018年 | Go 1.11 发布,引入新的包管理机制:go module |
| 2021年 | Go 1.16 发布,go module 称为默认包管理机制 |
| 2022年3月 | Go 1.18 发布,支持泛型 |
如今,Go 语言基本每年发布两个版本,一般在 2 月和 8 月。
1,Go 下载
去下载页面下载:

解压后得到名为 go 的目录:
/usr/local/$HOME/.profileexport PATH=$PATH:/usr/local/go/binsource ~/.profilego versionC:\apt-get installsudo apt-get remove golang-go
sudo apt-get remove --auto-remove golang-go
Vim Go 插件
2,Go Module 模式
一个 Go Module 是一个 Go 包的集合。module 是有版本的,所以 module 下的包也就有了版本属性。这个 module 与这些包会组成一个独立的版本单元,它们一起打版本、发布和分发。
每个 go.mod 文件会定义唯一一个 module,所以 Go Module 与 go.mod 是一一对应的。
1,Go Module 创建项目的步骤
- 通过 go mod init 创建 go.mod 文件,将当前项目变为一个 Go Module
- 通过 go mod tidy 命令自动更新当前 module 的依赖信息
- 执行 go build,执行新 module 的构建
~/go_testmain.gopackage main
import "github.com/sirupsen/logrus"
func main() {
logrus.Println("hello, go module")
}
依次执行命令:
$ go mod init go_test
go: creating new go.mod: module go_test
go: to add module requirements and sums:
go mod tidy
$ go mod tidy
go: finding module for package github.com/sirupsen/logrus
go: found github.com/sirupsen/logrus in github.com/sirupsen/logrus v1.9.0
$ go build
$ ls
go.mod go.sum go_test main.go
$ ./go_test
INFO[0000] hello, go module
- go.mod 中的 go directive,不是指你当前使用的 Go 版本,而是指你的代码所需的 Go 的最低版本
2,为当前 module 添加依赖
github.com/google/uuidpackage main
import (
"github.com/google/uuid"
"github.com/sirupsen/logrus"
)
func main() {
logrus.Println("hello, go module")
logrus.Println(uuid.NewString())
}
go build$ go build
main.go:4:2: no required module provides package github.com/google/uuid; to add it:
go get github.com/google/uuid
go get$ go get github.com/google/uuid
go: downloading github.com/google/uuid v1.3.0
go get: added github.com/google/uuid v1.3.0
go getgo mod tidy3,使用指定版本的依赖
一般一个依赖会有非常多的发布版本,比如 logrus :
$ go list -m -versions github.com/sirupsen/logrus
github.com/sirupsen/logrus v0.1.0 v0.1.1 v0.2.0 v0.3.0 v0.4.0 v0.4.1 v0.5.0 v0.5.1 v0.6.0 v0.6.1 v0.6.2 v0.6.3 v0.6.4 v0.6.5 v0.6.6 v0.7.0 v0.7.1 v0.7.2 v0.7.3 v0.8.0 v0.8.1 v0.8.2 v0.8.3 v0.8.4 v0.8.5 v0.8.6 v0.8.7 v0.9.0 v0.10.0 v0.11.0 v0.11.1 v0.11.2 v0.11.3 v0.11.4 v0.11.5 v1.0.0 v1.0.1 v1.0.3 v1.0.4 v1.0.5 v1.0.6 v1.1.0 v1.1.1 v1.2.0 v1.3.0 v1.4.0 v1.4.1 v1.4.2 v1.5.0 v1.6.0 v1.7.0 v1.7.1 v1.8.0 v1.8.1 v1.9.0
如果要使用某个特定版本的 logrus,则使用下面命令:
$ go get github.com/sirupsen/logrus@v1.7.0
go: downloading github.com/sirupsen/logrus v1.7.0
go get: downgraded github.com/sirupsen/logrus v1.8.1 => v1.7.0
go get4,使用版本号大于 1 的依赖
在 Go Module 构建模式下,当依赖的主版本号为 0 或 1 的时候,我们在 Go 源码中导入依赖包,不需要在包的导入路径上增加版本号,也就是:
import github.com/user/repo/v0 等价于 import github.com/user/repo
import github.com/user/repo/v1 等价于 import github.com/user/repo
当我们需要使用版本大于 1 的依赖时,需要类似下面的导入:
import "github.com/go-redis/redis/v7"
然后再使用 go get 获取相应版本的依赖:
$ go get github.com/go-redis/redis/v7
go: downloading github.com/go-redis/redis/v7 v7.4.1
go: downloading github.com/go-redis/redis v6.15.9+incompatible
go get: added github.com/go-redis/redis/v7 v7.4.1
5,从项目中删除一个依赖
从项目中删除依赖:
- 从代码中删除指定的 import
- 执行 go mod tidy
- 执行 go build
6,Go Module 模式下的项目典型布局
project-name
├── cmd/
│ ├── app1/
│ │ └── main.go
│ └── app2/
│ └── main.go
├── go.mod
├── go.sum
├── internal/
│ ├── pkga/
│ │ └── pkg_a.go
│ └── pkgb/
│ └── pkg_b.go
├── pkg1/
│ └── pkg1.go
├── pkg2/
└── pkg2.go
- cmd 目录:存放项目要编译构建的可执行文件所对应的 main 包的源码文件
- pkgN 目录:每个项目下的非 main 包都平铺在项目的根目录下,每个目录对应一个 Go 包
- internal 目录:存放仅项目内部引用的 Go 包,这些包无法被项目之外引用
3,Go 环境变量
$HOME/.cache/go-build$HOME/go/pkg/modhttps://proxy.golang.org,directhttps://goproxy.cn,direct4,常用 Go 命令
0,go fmt // 格式化代码
1,go run main.go // 运行 go 程序
2,go build main.go // 编译构建项目
3,go install // 将可执行程序安装在当前工作区的 bin 目录,或 GOBIN 包含的目录
4,go env // 查看 go 配置项
5,go help environment // 查看 go 配置项详细信息
6,go mod init // 初始化 go module
7,go mod tidy // 添加相关依赖
8,go list -m -versions github.com/sirupsen/logrus // 查看某个依赖的所有版本
9,go get github.com/go-redis/redis/v7 // 获取依赖
10,go list -m all // 查看当前 module 的所有依赖
5,Go 代码的执行顺序
Go 程序的入口函数是 main.main,即 main 包中的 main 函数。
package main
func init() {
}
func main() {
// 用户层执行逻辑
... ...
}
- main 函数是 Go 程序的入口函数
- init 函数与 main 函数都是无参数无返回值的函数
- init 函数比 main 函数先执行,一般用于包的初始化
- init 函数不能被开发者手工调用,只能被 Go 程序默认调用
- 一个包中可以有多个同名的 init 函数,它们的执行顺序是根据其声明次序依次调用
Go 包的初始化次序如下:
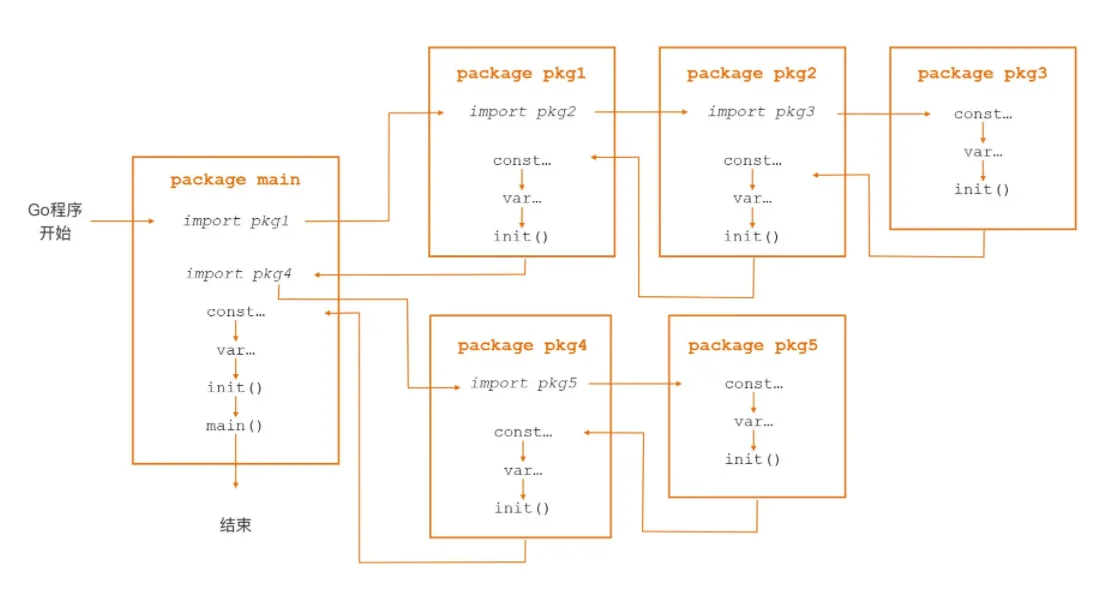
- Go 会根据包的导入顺序依次的初始化每个包
- 包的初始化过程中,采用深度优先原则
- 每个包中,除了 import 之外,会按照“常量->变量->init函数”的顺序进行初始化
- 如果某个包被多个包 import,那么该包只会被初始化一次
6,常量与变量
在 Go 语言中,常量和变量在使用之前,必须要先进行声明。
Go 语言的变量可以分为两类:
- 包级变量,是在包级别可见的变量。如果是导出变量(大写字母开头),那么这个包级变量也可以被视为全局变量
- 局部变量,是 Go 函数或方法体内声明的变量,仅在函数或方法体内可见
常量的声明方式
const a = 1
const Pi float64 = 3.14159265358979323846 // 单行常量声明
// 以const代码块形式声明常量
const (
size int64 = 4096
i, j, s = 13, 14, "bar" // 单行声明多个常量
)
iota // go 中的特殊常量,常用于枚举
变量的声明方式
var a int // 显示指定类型,不进行初始化,值为类型的默认值
var a int = 3 // 显示指定类型,并进行初始化
var a = 3 // 不显示指定类型,具体类型由 GO 自行推断
// 整型值的默认类型 int
// 浮点值的默认类型为 float64
// 复数值的默认类型为 complex128
// 布尔值的默认类型是 bool
// 字符值默认类型是 rune
// 字符串值的默认类型是 string
a := 3 // 短变量声明,只允许出现在函数内部
// 变量声明块
var (
a int = 128
b int8 = 6
s string = "hello"
c rune = 'A'
t bool = true
)
// 一行中声明多个变量
var a, b, c int = 5, 6, 7
var (
a, b, c int = 5, 6, 7
c, d, e rune = 'C', 'D', 'E'
)
// 声明多个不同类型的变量
var a, b, c = 12, 'A', "hello"
a, b, c := 12, 'A', "hello" // 短变量声明方式
7,Go 内建数据类型
基本数据类型
boolFALSEstring""[]rune(s)sstrconv.Itoastrconv.Atoi0byteruneint32type rune = int32int/uintint8/uint8[-128, 127]/[0, 255]int16/uint16[-32768, 32767]/[0, 65535]int32/uint32[-2147483648, 2147483647]/[0, 4294967295]int64/uint64[-9223372036854775808, 9223372036854775807]/[0, 18446744073709551615]0.0float32float64complex64complex128nilarrayslicemapchannelstructinterface*Xxx,unsafe.Pointer,uintptrfunctionmap[key_type]bool整数溢出问题:
var s int8 = 127
s += 1 // 预期128,实际结果-128
var u uint8 = 1
u -= 2 // 预期-1,实际结果255
字符串类型是不可变的:
var s string = "hello"
s[0] = 'k' // 错误:字符串的内容是不可改变的
s = "gopher" // ok
1,数组
Go 中的数组结构:
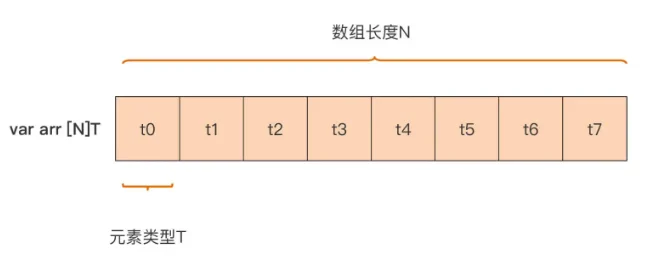
数组的定义:
// N 必须是整型数字面值或常量表达式,其值必须是确定的
var arr [N]T
// a 与 b 是不同的类型
var a [3]int // 如果不进行显示初始化,那么值就是 0 值
var b [5]int
len(a) // len 函数用于计算数组的长度
unsafe.Sizeof(a) // 用于计算 a 所占空间大小
// 显示初始化数组的三种方式
var arr2 = [6]int {
11, 12, 13, 14, 15, 16,
} // [11 12 13 14 15 16]
var arr3 = [...]int { // 可以将 N 用 ... 替代,Go 会自己推算长度
21, 22, 23,
} // [21 22 23]
fmt.Printf("%T\n", arr3) // [3]int
var arr4 = [...]int{
99: 39, // 将第100个元素(下标值为99)的值赋值为39,其余元素值均为0
}
fmt.Printf("%T\n", arr4) // [100]int
Go 值传递的机制让数组在各个函数间传递起来比较“笨重”,开销较大,且开销随数组长度的增加而增加。为了解决这个问题,Go 引入了切片这一不定长同构数据类型。
数组的遍历
// 方法 1
for i := 0; i < len(arr); i++ {
// arr[i]
}
// 方法 2
for index, value := range arr {
}
// index 可省略
for _, value := range arr {
}
数组的截取:
arr[i, j]iji, jarr := [...]{1, 2, 3, 4, 5}
arr[1:2] // 2
arr[1:3] // 2, 3
arr[1:len(arr)] // 2,3,4,5
arr[1:] // 2,3,4,5
arr[:3] // 1,2,3
arr[:] // 1,2,3,4,5
2,切片
切片可以提供比指针更为强大的功能,比如下标访问、边界溢出校验、动态扩容等。而且,指针本身在 Go 语言中的功能也受到的限制,比如不支持指针算术运算。
Go 中的切片类型:
type slice struct {
array unsafe.Pointer
len int
cap int
}
- array: 是指向底层数组的指针
- len: 是切片的长度,即切片中当前元素的个数
- 当访问下标大于等于 len 时的元素时,会报数组越界
- cap: 是底层数组的长度,也是切片的最大容量,cap 值永远大于等于 len 值
切片的定义:
// 与数组的不同是,切片不需要显示的长度,但切片也有长度
// 切片的长度是变化的,可以用 len() 函数计算切片的长度
var n = []int{1, 2, 3, 4, 5}
// 使用 append 函数向切片中添加元素
n = append(n, 6) // 切片变为[1 2 3 4 5 6]
切片的底层是一个数组,其结构如下:
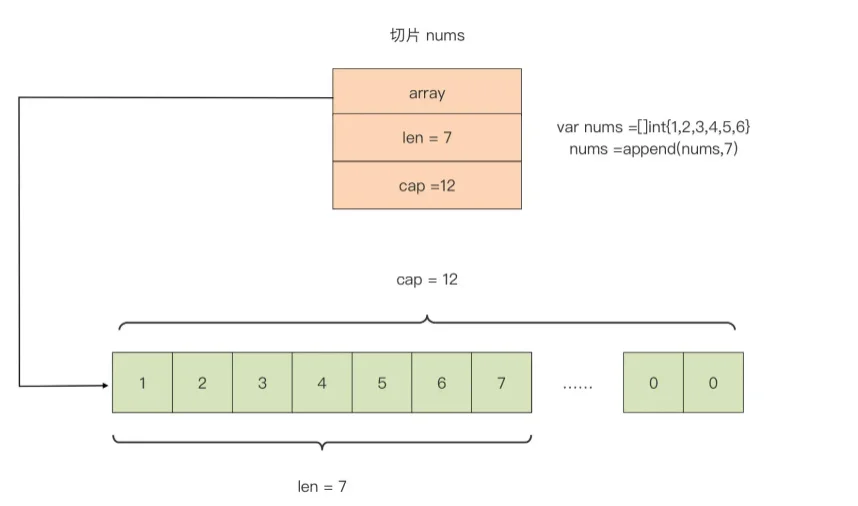
创建切片的其它方式:
makesl := make([]byte, 6, 10) // 其中10为cap值,即底层数组长度,6为切片的初始长度
// 切片中前 6 个元素的值是 byte 类型的零值,未初始化的元素不能访问
// 如果没有在 make 中指定 cap 参数,那么底层数组长度 cap 就等于 len
sl := make([]byte, 6) // cap = len = 6
array[low : high : max]我们在进行数组切片化的时候,通常省略 max,而 max 的默认值为数组的长度。
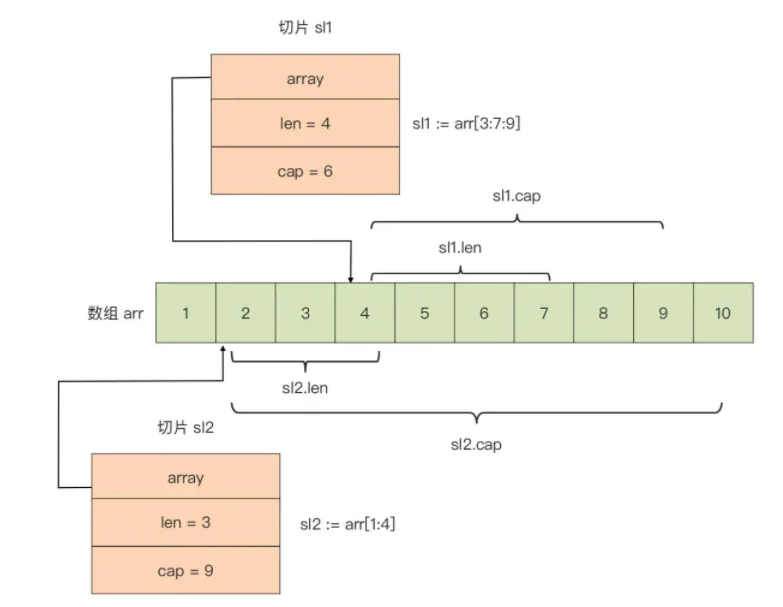
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
sl := arr[3:7:9]
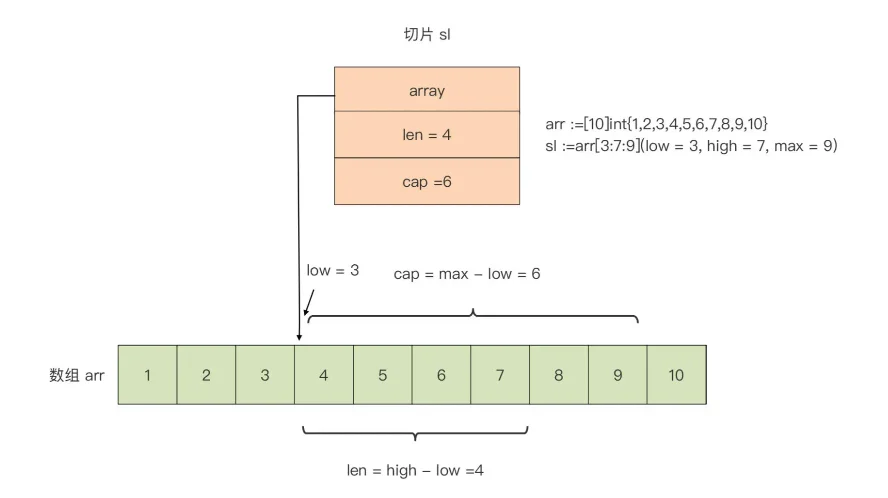
基于数组创建的切片:
- 它的起始元素从 low 所标识的下标值开始
- 切片的长度(len)是 high - low
- 它的容量是 max - low
由于切片 sl 的底层数组就是数组 arr,对切片 sl 中元素的修改将直接影响数组 arr 变量。比如,将切片的第一个元素加 10,那么数组 arr 的第四个元素将变为 14:
sl[0] += 10
fmt.Println("arr[3] =", arr[3]) // 14
切片好比打开了一个访问与修改数组的“窗口”,通过这个窗口,我们可以直接操作底层数组中的部分元素。
这类似于操作文件之前打开的“文件描述符”,通过文件描述符我们可以对底层的真实文件进行相关操作。
可以说,切片之于数组就像是文件描述符之于文件。
针对一个已存在的数组,可以建立多个操作数组的切片,这些切片共享同一底层数组,切片对底层数组的操作也同样会反映到其他切片中。
下面是为数组 arr 建立的两个切片的内存表示:
切片的动态扩容
“动态扩容”指的是,当通过 append 操作向切片追加数据的时候,如果这时切片的 len 值和 cap 值是相等的,也就是说切片底层数组已经没有空闲空间再来存储追加的值了,Go 运行时就会对这个切片做扩容操作,来保证切片始终能存储下追加的新值。
动态扩容时,会新建一个更大的数组,append 会把旧数组中的数据拷贝到新数组中,之后新数组便成为了切片的底层数组,旧数组会被垃圾回收掉。
如果在 for-loop 里对某个 slice 使用 append(),请先把 slice的容量很扩充到位,这样可以避免内存重新分享以及系统自动按2的N次方幂进行扩展但又用不到,从而浪费内存。
正因为 append 会动态扩容,并创建新的内存空间,所以 append 的正确使用姿势是:
sl = append(s1, item) // 要接收返回值
错误的使用姿势:
append(s1, item) // 不接收返回值是错误的
基于数组的切片的动态扩容问题
基于一个已有数组建立的切片,一旦追加的数据操作触碰到切片的容量上限(也是数组容量的上界),切片就会和原数组解除“绑定”,此时,会新创建一个底层数组,并将切片的元素拷贝到新数组中,后续对切片的任何修改都不会反映到原数组中了。
切片的遍历
// 方法 1
for i := 0; i < len(slice); i++ {
//slice[i]
}
// 方法 2
for index, value := range slice {
}
// index 可省略
for _, value := range slice {
}
一道思考题
下面两个切片的区别:
var s1 []int // len(s1) == cap(s1) == 0
var s2 = []int{} // len(s2) == cap(s2) == 0
println(s1 == nil) // true
println(s2 == nil) // false
- s1是声明,还没初始化,是nil值,底层没有分配内存空间
- 这意味着针对 s1 做操作的时候同时初始化
- 例如sl1 = append(sl1, 1),这个语句的操作就是先初始化一个长度为1的空间,然后把 “1”填入这个空间中
- s2初始化了,不是nil值,底层分配了内存空间,有地址
- 例如,sl2 = append(sl2, 2),这个语句就是直接将“2”这个值填入到已初始化的空间中
- go官方推荐使用 var sl1 []int
- 在 goland 开发时,第二种声明方式会出现黄色下划线,提示需要改动
3,map
Go 中 map 的定义方式:
// 包含了 key 类型和 value 类型
map[key_type]value_type
如果两个 map 类型的 key 元素类型相同,value 元素类型也相同,那么我们可以说它们是同一个 map 类型,否则就是不同的 map 类型。
map[string]string // key 与 value元素的类型相同
map[int]string // key 与 value元素的类型不同
==!=在 Go 语言中,函数类型、map 类型自身,以及切片只支持与 nil 的比较,而不支持同类型两个变量的比较。如下所示:
s1 := make([]int, 1)
s2 := make([]int, 2)
f1 := func() {}
f2 := func() {}
m1 := make(map[int]string)
m2 := make(map[int]string)
println(s1 == s2) // 错误:invalid operation: s1 == s2 (slice can only be compared to nil)
println(f1 == f2) // 错误:invalid operation: f1 == f2 (func can only be compared to nil)
println(m1 == m2) // 错误:invalid operation: m1 == m2 (map can only be compared to nil)
因此,一定要注意:函数类型、map 类型自身,以及切片类型是不能作为 map 的 key 类型的。
map 的声明
如下:
var m map[string]int // 一个 map[string]int 类型的变量
和切片类型变量一样,如果我们没有显式地赋予 map 变量初值,map 类型变量的默认值为 nil。
初值为零值 nil 的切片类型变量,可以借助内置的 append 的函数进行操作,这种在 Go 语言中被称为“零值可用”。
但 map 类型,因为它内部实现的复杂性,无法“零值可用”。所以,如果我们对处于零值状态的 map 变量直接进行操作,就会导致运行时异常(panic),从而导致程序进程异常退出:
var m map[string]int // m = nil
m["key"] = 1 // 发生运行时异常:panic: assignment to entry in nil map
所以,必须对 map 类型变量进行显式初始化后才能使用。
map 的声明初始化
和切片一样,为 map 类型变量显式赋值有两种方式:
- 使用复合字面值
- 使用 make 函数
使用复合字面值
// 这里,显式初始化了 map 类型变量 m
// 此时 m 中没有任何键值对,但 m 也不等同于初值为 nil 的 map 变量
// 这时对 m 进行键值对的插入操作,不会引发运行时异常
m := map[int]string{} // 空 map
m1 := map[int]string{1:"a", 2:"b"} // 非空 map
使用 make 函数
通过 make 函数,可以指定 map 的初始容量,但无法进行具体的键值对赋值:
m1 := make(map[int]string) // 未指定初始容量
m2 := make(map[int]string, 8) // 指定初始容量为 8
map 类型的容量不会受限于它的初始容量值,当其中的键值对数量超过初始容量后,Go 运行时会自动增加 map 类型的容量,保证后续键值对的正常插入。
map 的插入操作
// map 的插入操作
m := make(map[int]string)
m[1] = "value1"
m[2] = "value2"
m[3] = "value3"
m[1] = "value5" // 会覆盖原来的 value1
len(m) // len 函数可以计算 map 的长度
// cap 函数不能用于 map 类型
获取 map 中的值
m := make(map[string]int)
// 获取 map 中的值
// 如果 key1 存在与 map 中,则返回其对应的 value
// 如果 key1 不存在,也不会报错,会返回 value 元素的 0 值
v := m["key1"]
// 下面方法可判断 key1 是否存在于 map 中
// 返回的 ok 是一个布尔类型
v, ok := m["key1"]
if !ok {
// "key1"不在map中
}
// "key1"在map中,v将被赋予"key1"键对应的value
// 如果不关心某个键对应的 value,而只关心某个键是否在于 map 中
// 我们可以使用空标识符替代变量 v,忽略可能返回的 value
_, ok := m["key1"]
map 的删除操作
// 使用 delete 函数进行删除
delete(m, "key1")
map 的遍历操作
// 使用 range 进行遍历
for k, v := range m {
fmt.Printf("[%d, %d] ", k, v)
}
// 如果不关心值,也可以这样
for k, _ := range m {
// 使用k
}
// 只遍历 key
for k := range m {
// 使用k
}
// 只关心 value
for _, v := range m {
// 使用v
}
对同一 map 做多次遍历的时候,每次遍历元素的次序都不相同。这是 Go 语言 map 类型的一个重要特点,所以一定要记住:程序逻辑千万不要依赖遍历 map 所得到的的元素次序。
如果 map 中的 key 或 value 的数据长度大于一定数值,那么运行时不会在 map 中直接存储数据,而是会存储 key 或 value 数据的指针。目前 Go 运行时定义的最大 key 和 value 的长度是这样的:
// $GOROOT/src/runtime/map.go
const (
maxKeySize = 128
maxElemSize = 128
)
map 与并发
map 实例不是并发写安全的,也不支持并发读写。如果对 map 实例进行并发读写,程序运行时就会抛出异常。
fatal error: concurrent map iteration and map write
这里的并发读写,指的是同时进行读和写,会出现异常
如果只是并发读,则不会发生异常
Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型
4,type
type 用于创建自定义数值类型。
本质上相同的两个类型,它们的变量可以通过显式转型进行相互赋值,相反,如果本质上是不同的两个类型,它们的变量间连显式转型都不可能,更不要说相互赋值了。
第一种:
// MyInt 的底层类型是 init32
// 它的数值性质与 int32 完全相同
// 但它们仍然是完全不同的两种类型
type MyInt int32
var m int = 5
var n int32 = 6
var a MyInt = m // 错误:在赋值中不能将m(int类型)作为MyInt类型使用
var a MyInt = n // 错误:在赋值中不能将n(int32类型)作为MyInt类型使用
// 需要经过显示转换
var a MyInt = MyInt(m) // ok
var a MyInt = MyInt(n) // ok
类型定义也支持通过 type 块的方式进行:
type (
T1 int
T2 T1
T3 string
)
第二种方式,类型别名(并没有定义出新的类型,而只是一个别名):
// MyInt 与 int32 完全等价,所以这个时候两种类型就是同一种类型
type MyInt = int32
var n int32 = 6
var a MyInt = n // ok
5,struct
Booktype Book struct {
Title string // 书名
Pages int // 书的页数
Indexes map[string]int // 书的索引
}
空结构体
一个空结构体,是没有包含任何字段的结构体:
type Empty struct{} // Empty是一个不包含任何字段的空结构体类型
空结构体的大小是 0:
var s Empty
println(unsafe.Sizeof(s)) // 0
基于空结构体类型内存零开销这样的特性,在 Go 开发中会经常使用空结构体类型元素,作为一种“事件”信息进行 Goroutine 之间的通信,如下:
var c = make(chan Empty) // 声明一个元素类型为Empty的channel
c<-Empty{} // 向channel写入一个“事件”
这种以空结构体为元素类建立的 channel,是目前能实现的、内存占用最小的 Goroutine 间通信方式。
来看下面这种代码:
// 自定义了 Person 类型
type Person struct {
Name string
Phone string
Addr string
}
// 自定义了 Book 类型
type Book struct {
Title string
Author Person // Person 类型为 Book 类型的内部元素
... ...
}
// 访问 Book 结构体字段 Author 中的 Phone 字段
var book Book
println(book.Author.Phone)
Go 还提供了以下方式来定义 Book:
type Book struct {
Title string
Person // 只有类型,而没有变量名
... ...
}
以这种方式定义的结构体字段,叫做嵌入字段。我们也可以将这种字段称为匿名字段,或者把类型名看作是这个字段的名字。
如果我们要访问 Person 中的 Phone 字段,我们可以通过下面两种方式进行:
var book Book
println(book.Person.Phone) // 将类型名当作嵌入字段的名字
println(book.Phone) // 支持直接访问嵌入字段所属类型中字段
结构体类型变量的声明
type Book struct {
...
}
// 四种声明方式
var book Book // 普通的声明方式,book为零值结构体变量
var book = Book{} // Go 自推断类型
book := Book{} // 短变量声明
// 也可以使用 new 函数来创建结构体对象,但这种方式很少使用
// 注意:new 返回的是指针类型
book := new(Book)
Go 结构体类型由若干个字段组成,当这个结构体的各个字段的值都是零值时,我们就说这个结构体类型变量处于零值状态。
用复合字面值初始化结构体变量
type Book struct {
Title string // 书名
Pages int // 书的页数
Indexes map[string]int // 书的索引
}
// 按照结构体中变量的顺序初始化
var book = Book{"The Go Programming Language", 700, make(map[string]int)}
field:value// 这种初始化方式,使得字段可以以任意次序出现
// 未显式出现在字面值中的字段(比如 F5)将采用它对应类型的零值
var t = T{
F2: "hello",
F1: 11,
F4: 14,
}
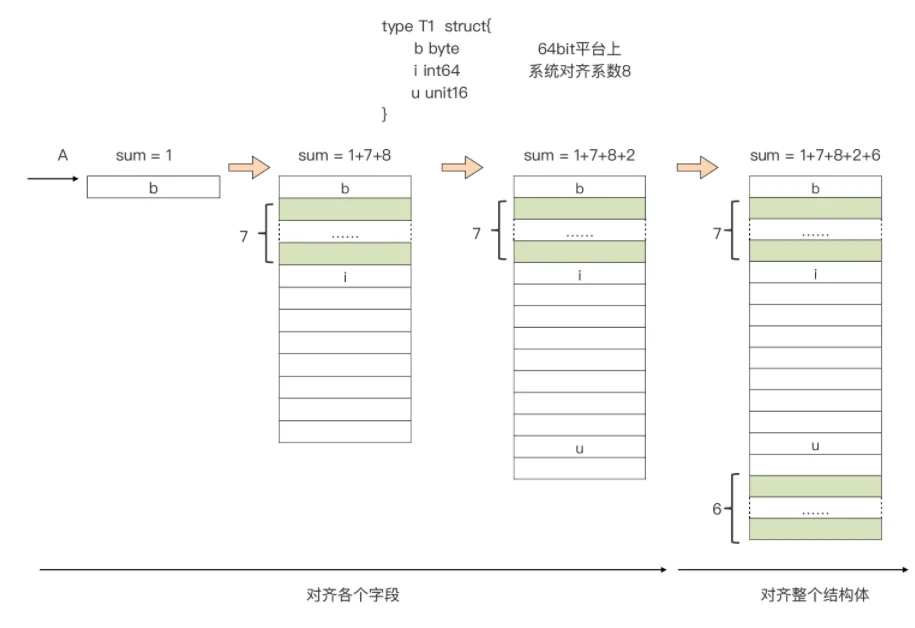
结构体中的内存对齐问题(跟 C语言一样)
由于内存对齐的要求,结构体类型各个相邻字段间可能存在“填充物”,结构体的尾部同样可能被 Go 编译器填充额外的字节,满足结构体整体对齐的约束。
正是因为这点,我们在定义结构体时,一定要合理安排字段顺序,要让结构体类型对内存空间的占用最小。
比如下面例子:
type T struct {
b byte
i int64
u uint16
}
该类型 T 的内存布局是这样的:
不同的排序顺序,导致了最终占用内存大小的不同:
type T struct {
b byte
i int64
u uint16
}
type S struct {
b byte
u uint16
i int64
}
func main() {
var t T
println(unsafe.Sizeof(t)) // 24
var s S
println(unsafe.Sizeof(s)) // 16
}
6,复杂类型的比较
reflect.DeepEqual()import (
"fmt"
"reflect"
)
func main() {
m1 := map[string]string{"one": "a","two": "b"}
m2 := map[string]string{"two": "b", "one": "a"}
fmt.Println("m1 == m2:",reflect.DeepEqual(m1, m2))
//prints: m1 == m2: true
s1 := []int{1, 2, 3}
s2 := []int{1, 2, 3}
fmt.Println("s1 == s2:",reflect.DeepEqual(s1, s2))
//prints: s1 == s2: true
}
8,Go 控制语句
1,if 语句
if boolean_expression {
}
if boolean_expression {
} else {
}
// 多分支
if boolean_expression1 {
} else if boolean_expression2 {
} else if boolean_expressionN {
} else {
}
Go 支持在 if 后的布尔表达式前,进行一些变量的声明,在 if 布尔表达式前声明的变量,叫它 if 语句的自用变量。顾名思义,这些变量只可以在 if 语句的代码块范围内使用,比如下面代码中的变量 a、b 和 c:
func main() {
// 中间要用分号隔开
if a, c := f(), h(); a > 0 {
println(a)
} else if b := f(); b > 0 {
println(a, b)
} else {
println(a, b, c)
}
}
2,for 循环
Go 中的 for 循环有多种写法:
var sum int
for i := 0; i < 10; i++ {
sum += i
}
println(sum)
for i := 0; i < 10; {
i++
}
i := 0
for ; i < 10; {
println(i)
i++
}
i := 0
for i < 10 {
println(i)
i++
}
// 无限循环,死循环的三种种形式
for { // 最简洁,推荐使用
// 循环体代码
}
for true {
// 循环体代码
}
for ; ; {
// 循环体代码
}
3,for-range 语句
// 对于一个切片,用 for 循环遍历
var sl = []int{1, 2, 3, 4, 5}
for i := 0; i < len(sl); i++ {
fmt.Printf("sl[%d] = %d\n", i, sl[i])
}
// 等价的 for-range 遍历方法
for i, v := range sl {
fmt.Printf("sl[%d] = %d\n", i, v)
}
// for-range 的几个变种
// 只遍历下标值
for i := range sl {
// ...
}
// 只遍历值,忽略下标
for _, v := range sl {
// ...
}
// 既不关心下标,也不关心值
for range sl {
// ...
}
遍历 string 类型:
var s = "中国人"
for i, v := range s {
fmt.Printf("%d %s 0x%x\n", i, string(v), v)
}
// 结果如下
0 中 0x4e2d
3 国 0x56fd
6 人 0x4eba
for-range 与 channel
当 channel 类型变量作为 for range 语句的迭代对象时,for range 会尝试从 channel 中读取数据:
var c = make(chan int)
for v := range c {
// ...
}
- for range 每次从 channel 中读取一个元素后,会把它赋值给循环变量 v,并进入循环体
- 当 channel 中没有数据可读的时候,for range 循环会阻塞在对 channel 的读操作上
- 直到 channel 关闭时,for range 循环才会结束,这也是 for range 循环与 channel 配合时隐含的循环判断条件
for range 与 Goroutine 的坑
比如下面代码:
func main() {
var m = []int{1, 2, 3, 4, 5}
for i, v := range m {
go func() {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}()
}
time.Sleep(time.Second * 10)
}
// 其实际输出是
4 5
4 5
4 5
4 5
4 5
//
func main() {
var m = []int{1, 2, 3, 4, 5}
for i, v := range m {
go func(i, v int) {
time.Sleep(time.Second * 3)
fmt.Println(i, v)
}(i, v)
}
time.Sleep(time.Second * 10)
}
// 输出的结果如下(具体的结果依赖于 CPU 调度)
0 1
1 2
2 3
3 4
4 5
4,continue 与 break 语句
Go 语言提供了 continue 语句和 break 语句。
Go 语言中的 continue 在 C 语言 continue 语义的基础上又增加了对 label 的支持。
带 label 的 continue 语句,通常出现于嵌套循环语句中,被用于跳转到外层循环并继续执行外层循环语句的下一个迭代,比如:
func main() {
var sl = [][]int{
{1, 34, 26, 35, 78},
{3, 45, 13, 24, 99},
{101, 13, 38, 7, 127},
{54, 27, 40, 83, 81},
}
outerloop:
for i := 0; i < len(sl); i++ {
for j := 0; j < len(sl[i]); j++ {
if sl[i][j] == 13 {
fmt.Printf("found 13 at [%d, %d]\n", i, j)
continue outerloop
}
}
}
}
5,switch-case 语句
func readByExtBySwitch(ext string) {
switch ext {
case "json":
println("read json file")
case "jpg", "jpeg", "png", "gif":
println("read image file")
case "txt", "md":
println("read text file")
case "yml", "yaml":
println("read yaml file")
case "ini":
println("read ini file")
default:
println("unsupported file extension:", ext)
}
}
如果 switch 表达式匹配到了某个 case 表达式,那么程序就会执行这个 case 对应的代码分支。这个分支后面的 case 表达式将不会再得到求值机会,即便后面的 case 表达式求值后也能与 switch 表达式匹配上,Go 也不会继续去对这些表达式进行求值了。
无论 default 分支出现在什么位置,它都只会在所有 case 都没有匹配上的情况下才会被执行的。
只要类型支持比较操作,都可以作为 switch 语句中的表达式类型。比如整型、布尔类型、字符串类型、复数类型、元素类型都是可比较类型的数组类型,甚至字段类型都是可比较类型的结构体类型,也可以。
6,type-switch 语句
Go 语言的 switch 语句还支持求值结果为类型信息的表达式,也就是 type switch 语句。
func main() {
// x 必须是一个接口类型变量
// 通过x.(type),可以获得变量 x 的动态类型信息
var x interface{} = 13
switch x.(type) {
case nil:
println("x is nil")
case int:
println("the type of x is int")
case string:
println("the type of x is string")
case bool:
println("the type of x is string")
default:
println("don't support the type")
}
}
通过x.(type),我们除了可以获得变量 x 的动态类型信息之外,也能获得其动态类型对应的值信息:
func main() {
var x interface{} = 13
// v 存储的是变量 x 的动态类型对应的值信息
switch v := x.(type) {
case nil:
println("v is nil")
case int:
println("the type of v is int, v =", v)
case string:
println("the type of v is string, v =", v)
case bool:
println("the type of v is bool, v =", v)
default:
println("don't support the type")
}
}
// 输出结果如下
the type of v is int, v = 13