
(1)概述:
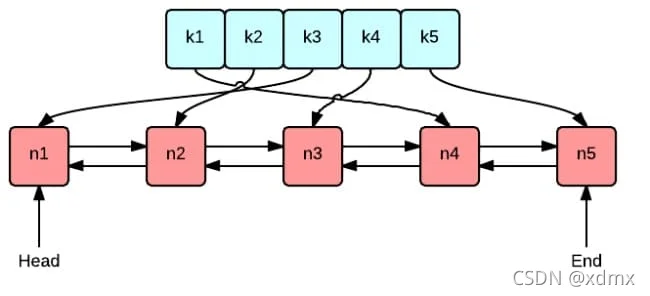
如图,groupcache的LRU就是一个哈希表映射一个双向链表。使得增删改都是o(1)。
LRU认为,如果数据最近被访问过,那么他将来被访问的概率也更大,于是把最近受访问的数据移动到队头。那么队尾自然就是最不常被访问的,所以只要内存满了,就淘汰队尾数据。
(2)源码
首先是主结构cache,包括了双向链表和map
// Cache is an LRU cache. It is not safe for concurrent access.
type Cache struct {
// MaxEntries is the maximum number of cache entries before
// an item is evicted. Zero means no limit.
//缓存的最大数量,0表示没有限制
MaxEntries int
// OnEvicted optionally specifies a callback function to be
// executed when an entry is purged from the cache.
// 回调函数,当元素被删除时调用
OnEvicted func(key Key, value interface{})
// 双向循环链表,上图的红色部分
ll *list.List
// 一个对照节点,使得查找也是o(1),也就是上图的绿色部分
cache map[interface{}]*list.Element
}
接着是链表节点的Value类型:
// A Key may be any value that is comparable. See http://golang.org/ref/spec#Comparison_operators
type Key interface{}
// entry 是双向链表节点的数据类型
//在链表中仍保存每个值对应的 key 的好处在于:淘汰队首节点时,可以用 key 从字典中删除对应的映射
type entry struct {
key Key
value interface{}
}
New创建实例化Cache结构
/ New creates a new Cache.
// If maxEntries is zero, the cache has no limit and it's assumed
// that eviction is done by the caller.
func New(maxEntries int) *Cache {
return &Cache{
MaxEntries: maxEntries,
ll: list.New(),
cache: make(map[interface{}]*list.Element),
}
}
Add添加一个k,v对,具体写法看我的注释
// Add adds a value to the cache.
func (c *Cache) Add(key Key, value interface{}) {
// c.cache是一个hash映射,如果是空,则make,顺便初始化c的链表
if c.cache == nil {
c.cache = make(map[interface{}]*list.Element)
c.ll = list.New()
}
// 如果key已经在cache中,就把该key对应的链表节点移动到链表头
// 这里是o(1)查找
if ee, ok := c.cache[key]; ok {
c.ll.MoveToFront(ee)
// 具体看下面这句 ele := c.ll.PushFront(&entry{key, value})
// 说明 ee.Value是*entry类型的,利用ee.Value.(*entry)转为 *entry,更新该节点 value的值
ee.Value.(*entry).value = value
return
}
// 如果key不在cache中,就创建节点,并移动到链表头部
ele := c.ll.PushFront(&entry{key, value})
// 将 key 对应的链表 ele 加入cache 哈希表中
c.cache[key] = ele
// 如果最大内存不是无限制,而且链表长度大于最大缓存了,就淘汰队尾
if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries {
c.RemoveOldest()
}
}
接着先看删除队尾的函数RemoveOldest()
// RemoveOldest removes the oldest item from the cache.
// RemoveOldest 删除掉cache中最不常被访问的项
func (c *Cache) RemoveOldest() {
// 如果cache是nil,那就没得删了,直接返回
if c.cache == nil {
return
}
// 使用c.ll.Back()直接定位到队尾节点
ele := c.ll.Back()
if ele != nil {
c.removeElement(ele)
}
}
再看封装好的删除链表节点及map元素方法:
// removeElement 封装了一个删除方法,因为不止一次用到
func (c *Cache) removeElement(e *list.Element) {
// 将链表对应的节点删掉
c.ll.Remove(e)
// 拿到 e.Value 对应的数据类型 *entry
kv := e.Value.(*entry)
// delete()函数删除 c.cache 这个map里相连在链表上该删除节点的那个元素
delete(c.cache, kv.key)
// 如果回调函数不为nil就调用
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
Get函数的实现比较简单,有就返回值且移动节点,没有就返回空
// Get looks up a key's value from the cache.
func (c *Cache) Get(key Key) (value interface{}, ok bool) {
if c.cache == nil {
return
}
// 如果缓存命中了,就将该key对应的节点ele移动到队头
if ele, hit := c.cache[key]; hit {
c.ll.MoveToFront(ele)
return ele.Value.(*entry).value, true
}
return
}
Remove也比较简单,判断如果key是存在的,就移除
// Remove removes the provided key from the cache.
func (c *Cache) Remove(key Key) {
if c.cache == nil {
return
}
// 如果缓存中确实有这个key对应的,就移除
if ele, hit := c.cache[key]; hit {
c.removeElement(ele)
}
}
Len方法返回缓存的数量
// Len returns the number of items in the cache.
func (c *Cache) Len() int {
// 优先判断这个是必要的,因为如果你缓存啥都没有,一来就调用下面的Len,是会
// 报空指针异常的
if c.cache == nil {
return 0
}
return c.ll.Len()
}
Clear 函数就是清空cache中的所有存储项
// Clear purges all stored items from the cache.
func (c *Cache) Clear() {
// 如果回调函数不为空,就要一个一个去执行
if c.OnEvicted != nil {
for _, e := range c.cache {
kv := e.Value.(*entry)
c.OnEvicted(kv.key, kv.value)
}
}
// 将 ll 和 cache 直接置为空
c.ll = nil
c.cache = nil
}
LRU的内容比较少,就这样。