
目录
25、append新元素前后的slice是否相同?
分两种情况:
- 第一种,slice剩余的容量够append新元素,那么新元素直接追加在原有数组后面,slice指向的地址不变。
- 第二种,slice剩余的容量不够append新元素,那么slice会申请一个更大的内存,将原有的数组copy过来,然后再将新元素追加在新数组后面。这种情况下,slice指向的数组地址会变。
26、函数的参数传递?
函数的参数传递本质上都是值的拷贝,不同的是,值类型拷贝的是值,引用类型拷贝的是地址。
27、map底层实现原理?
// A header for a Go map.
type hmap struct {
count int
// 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8
// 状态标志,下文常量中会解释四种状态位含义。
B uint8
// buckets(桶)的对数log_2
// 如果B=5,则buckets数组的长度 = 2^5=32,意味着有32个桶
noverflow uint16
// 溢出桶的大概数量
hash0 uint32
// 哈希种子
buckets unsafe.Pointer
// 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
oldbuckets unsafe.Pointer
// 如果发生扩容,oldbuckets是指向老的buckets数组的指针
// 老的buckets数组大小是新的buckets的1/2;非扩容状态下,它为nil。
nevacuate uintptr
// 表示扩容进度,小于此地址的buckets代表已搬迁完成。
extra *mapextra
// 这个字段是为了优化GC扫描而设计的。
// 当key和value均不包含指针,并且都可以inline时使用。
// extra是指向mapextra类型的指针。
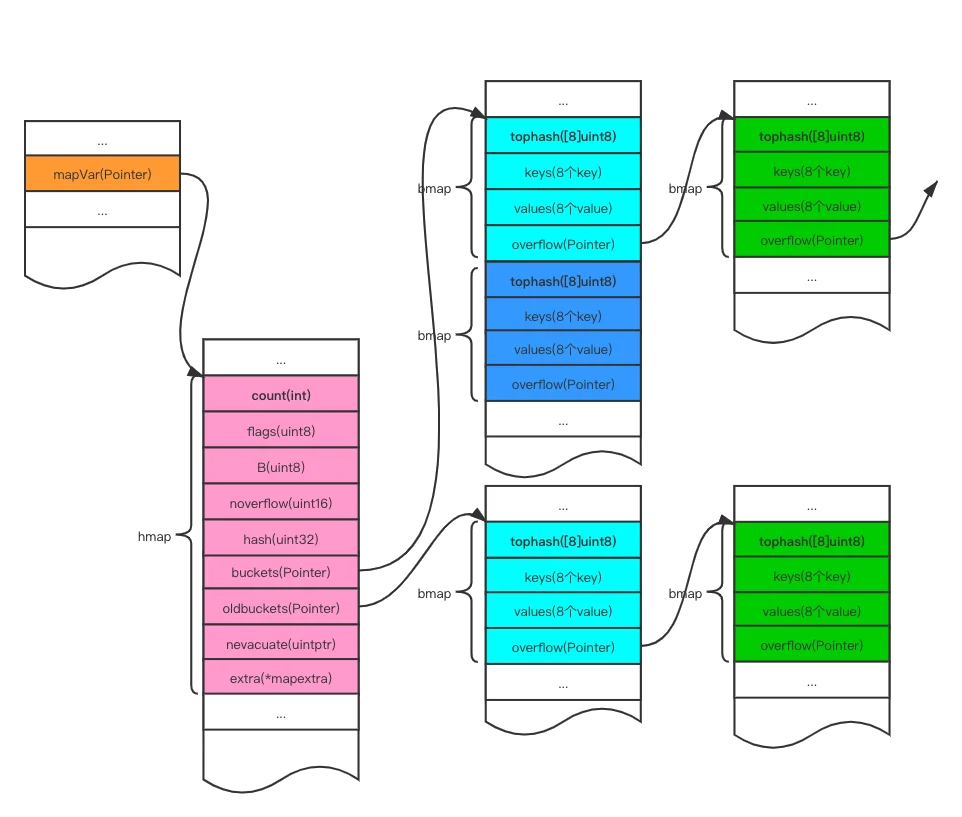
}- Golang的map本质上是一个指针,占用8个字节,指向了一个hmap结构体。
- hmap中有一个字段是buckets,buckets是一个数组指针,指向由若干个bmap(bucket)组成的数组,数组的大小为2^B(B是桶的对数)。
- bmap由四个字段组成:tophash、keys、values和overflow。每一个bmap最多可以存储8个元素(key、value对)。
- 数据的存储机制:key经过哈希运算得到哈希值,哈希值的低B位决定了这个key进入哪一个bmap,哈希值的高8位决定key落入bmap的哪一个位置。当一个bmap存满之后,会创建一个新的bmap并通过链表连接。
28、map如何扩容?
待补充。。。
29、map如何查找?
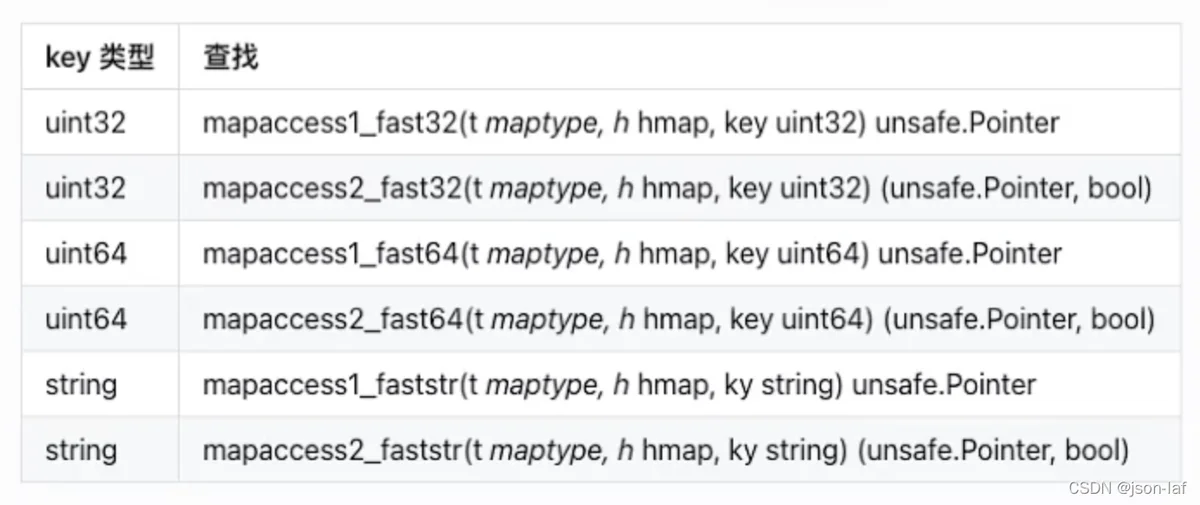
Golang中map查找有两种语法,带comma的和不带comma的,带comma的会比不带comma的多返回一个comma值(bool类型),这个值代表所查询的key在不在map中。

值得注意的是,根据key的不同类型和返回参数,map底层会调用不同的查找函数来提高效率。
详细的查找流程如下:
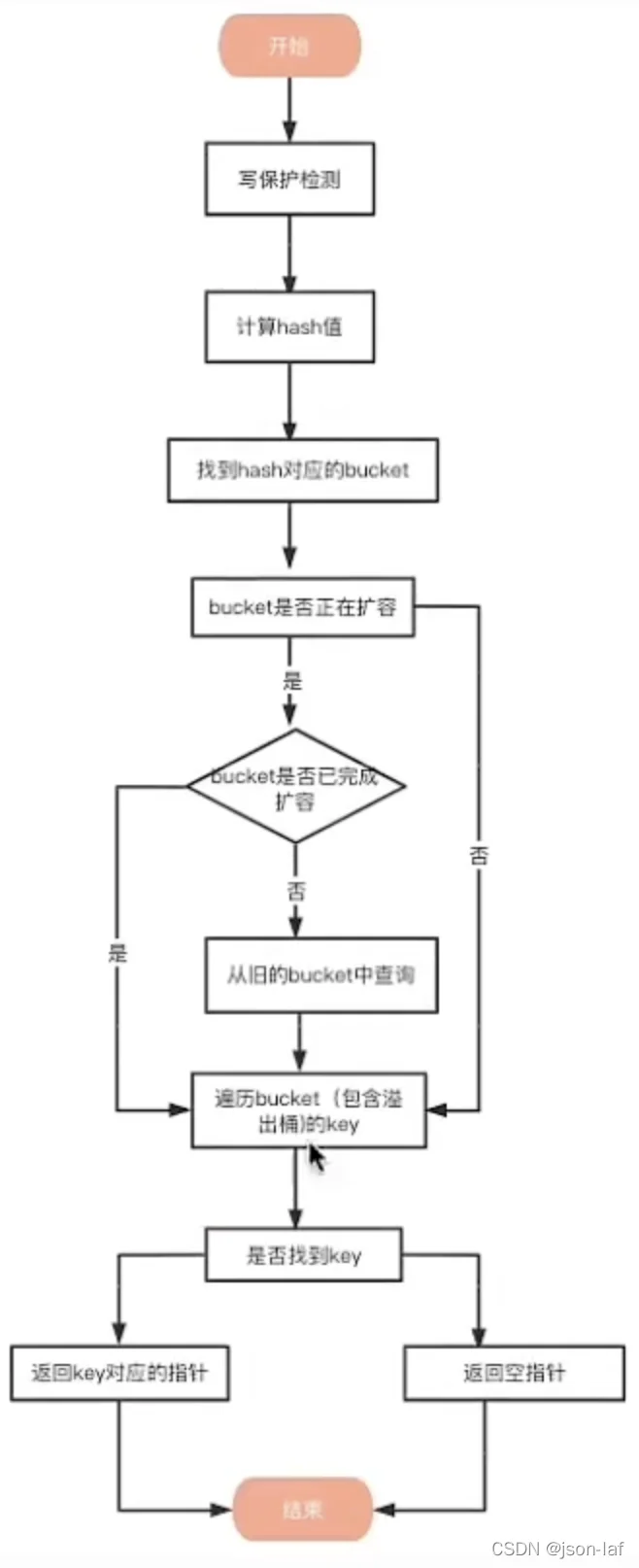
- 写保护监测。判断是否有其他线程对该map进行写操作(本质上是判断map的flags字段,1表示其他协程正在进行写操作),如果是则直接panic抛异常退出。原因是Golang在语言上不支持线程安全。
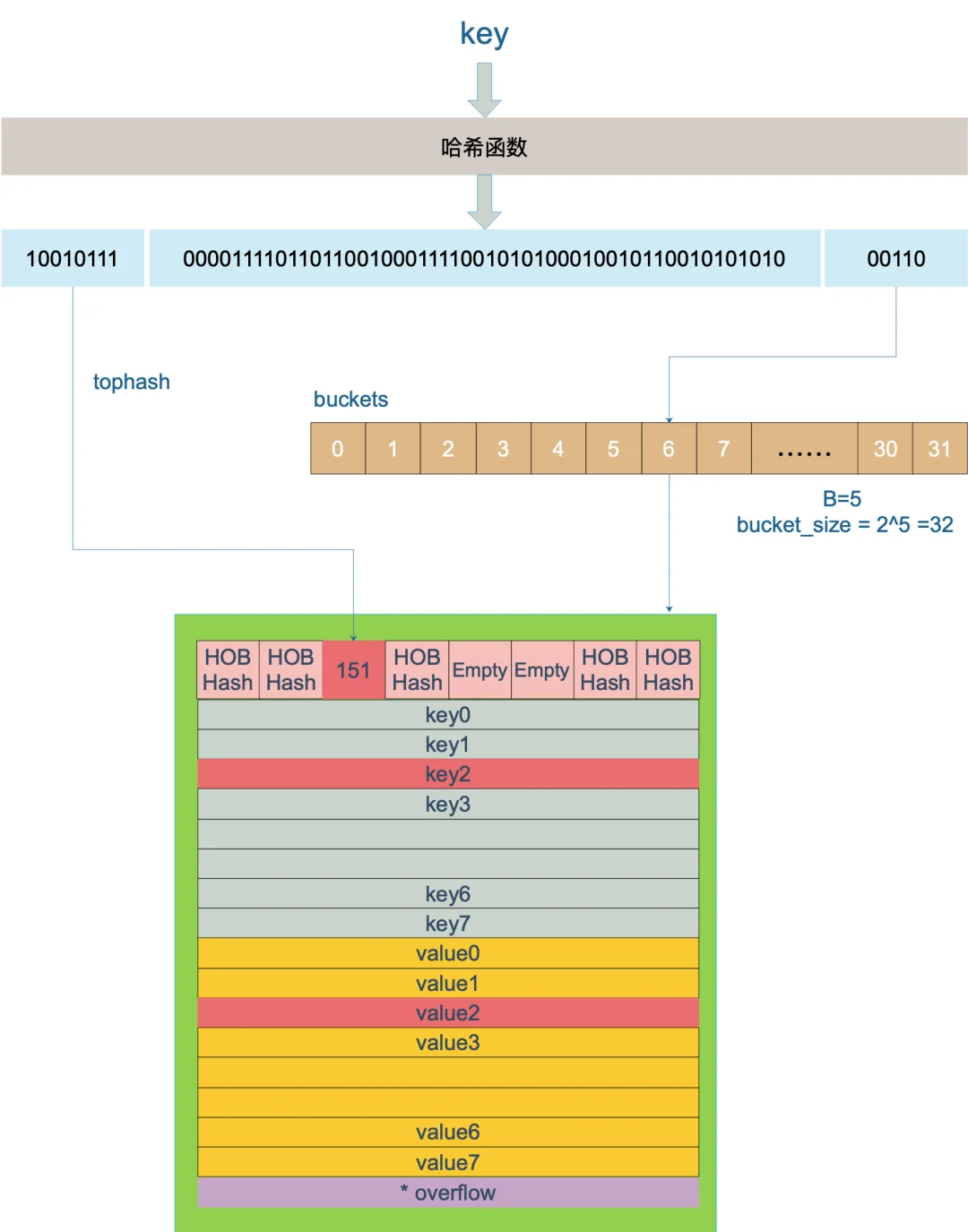
- 计算key的哈希值。根据key计算出的哈希值为64位,可以将这个哈希值分为高8位、中间部分和低B位三部分。
- 找到哈希对应的bucket(查找是通过哈希值的低B位来确定key对应的bucket)。判断bucket是否在扩容,还在扩容则使用旧buckets。
- 遍历bucket查找。在bucket以及bucket的overflow中查找tophash值为key哈希高8位的槽位(key所在位置)。如果找不到则返回空指针。
- 返回指针。key的地址=bucket的地址+tophash字段的大小+槽位下标i*key的大小,value的地址=bucket的地址+tophash字段的大小+key的数量(默认为8)*key的大小+槽位下标i*value的大小。
30、介绍一下channel及其特性?
Go 语言中,不要通过共享内存来通信,而要通过通信来实现内存共享。Go 的CSP(Communicating Sequential Process)并发模型,中文可以叫做通信顺序进程,是通过 goroutine 和 channel 来实现的。
channel 收发遵循先进先出 FIFO 的原则。分为有缓冲区和无缓冲区,channel 中包括 buffer、sendx 和 recvx 收发的位置(ring buffer 记录实现)、sendq、recv。当 channel 因为缓冲区不足而阻塞了队列,则使用双向链表存储。
特性:
- 给一个 nil channel 发送数据,造成永远阻塞
- 从一个 nil channel 接收数据,造成永远阻塞
- 给一个已经关闭的 channel 发送数据,引起 panic
- 从一个已经关闭的 channel 接收数据,如果缓冲区中为空,则返回一个零值
- 无缓冲的 channel 是同步的,而有缓冲的 channel 是非同步的
- 关闭一个 nil channel 将会发生 panic
31、channel的底层实现原理?
channel本质上是一个8个字节的指针,指向hchan结构体。
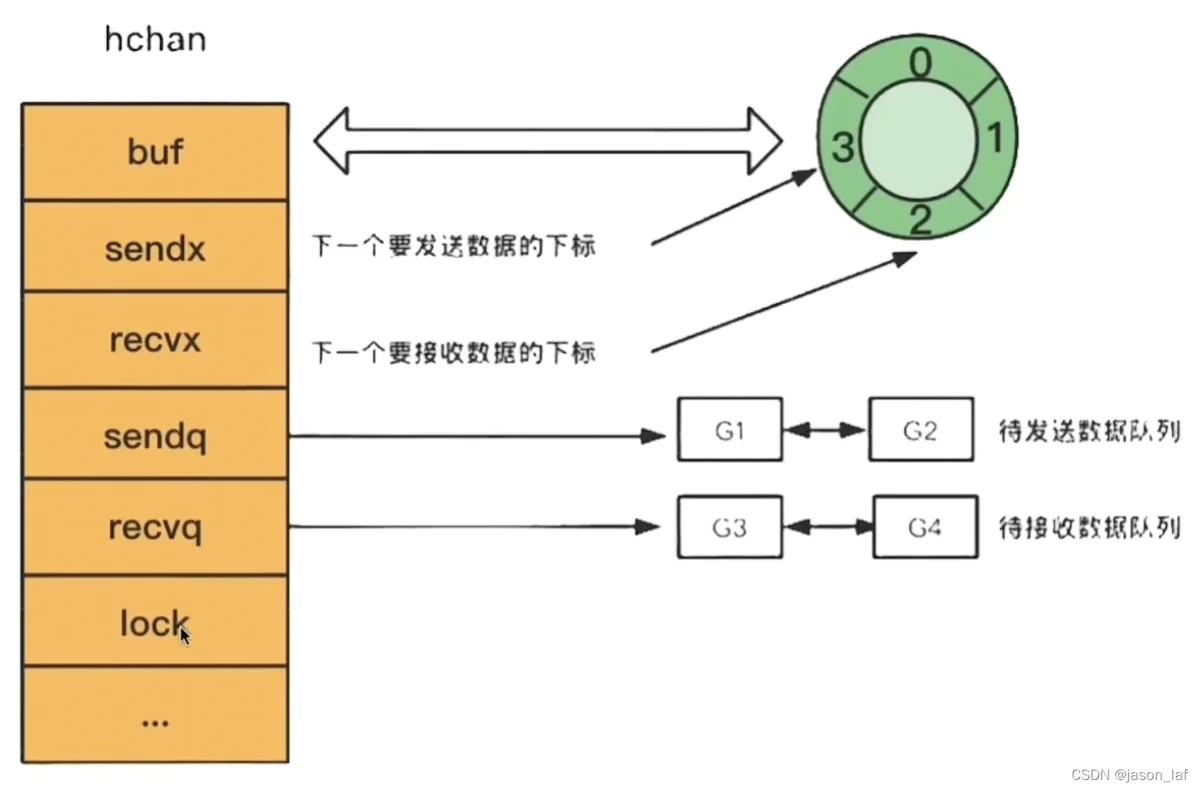
// A header for a Go channel.
type hchan struct {
qcount uint // 循环数组里的元素个数
dataqsiz uint // 循环数组的长度,如ch := make(chan int, 10)。此处的10即dataqsiz
elemsize uint16 // 要发送或接收的数据类型大小
buf unsafe.Pointer // 当channel设置了缓冲数量时,该buf指向一个存储缓冲数据的区域,该区域是一个循环队列的数据结构
closed uint32 // 关闭状态
sendx uint // 当channel设置了缓冲数量时,数据区域即循环队列此时已发送数据的索引位置
recvx uint // 当channel设置了缓冲数量时,数据区域即循环队列此时已接收数据的索引位置
recvq waitq // 想读取数据但又被阻塞住的goroutine队列
sendq waitq // 想发送数据但又被阻塞住的goroutine队列
lock mutex
...
}其中waitq是一个结构体
type waitq struct {
first *sudog
last *sudog
}channel读写数据可以分为有缓冲和无缓冲两种。以两个goroutine为例,具体流程如下。
1. 无缓冲channel读写
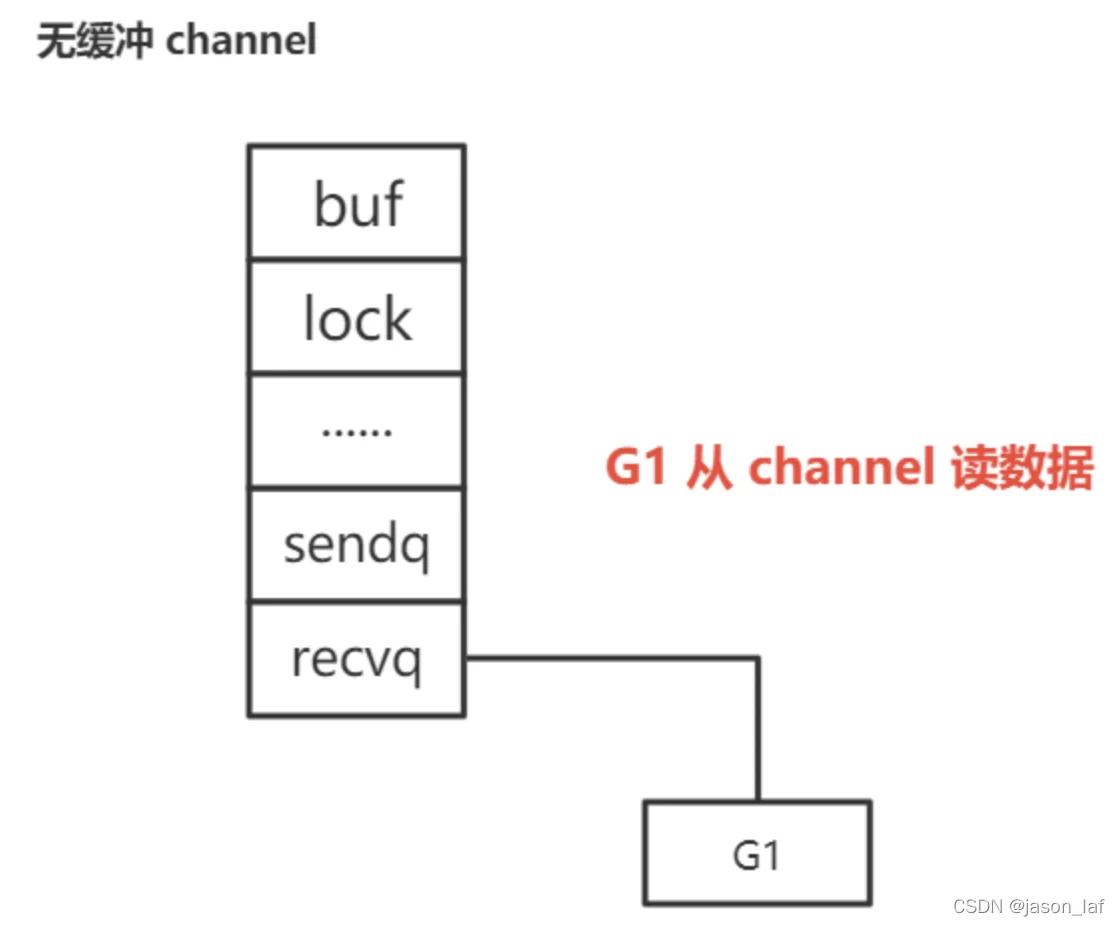
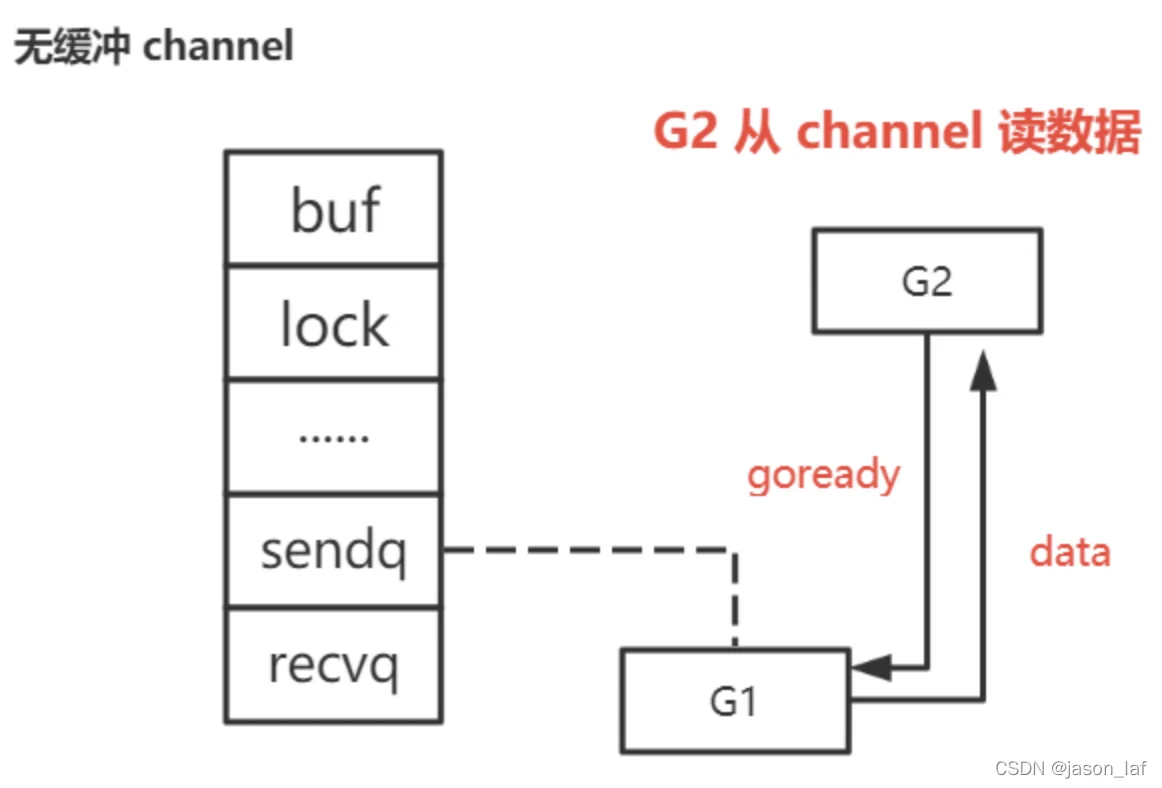
根据读写顺序可以分为先读后写和先写后读。
先读后写:由于channel是无缓冲的,G1(读goroutine)会被挂在recvq队列,然后休眠。当G2(写goroutine)写入数据时,发现recvq队列中的G1,就会将数据传给G1,并设置G1 goready函数,等待下次调度运行,同时会将G1从等待队列中移出。
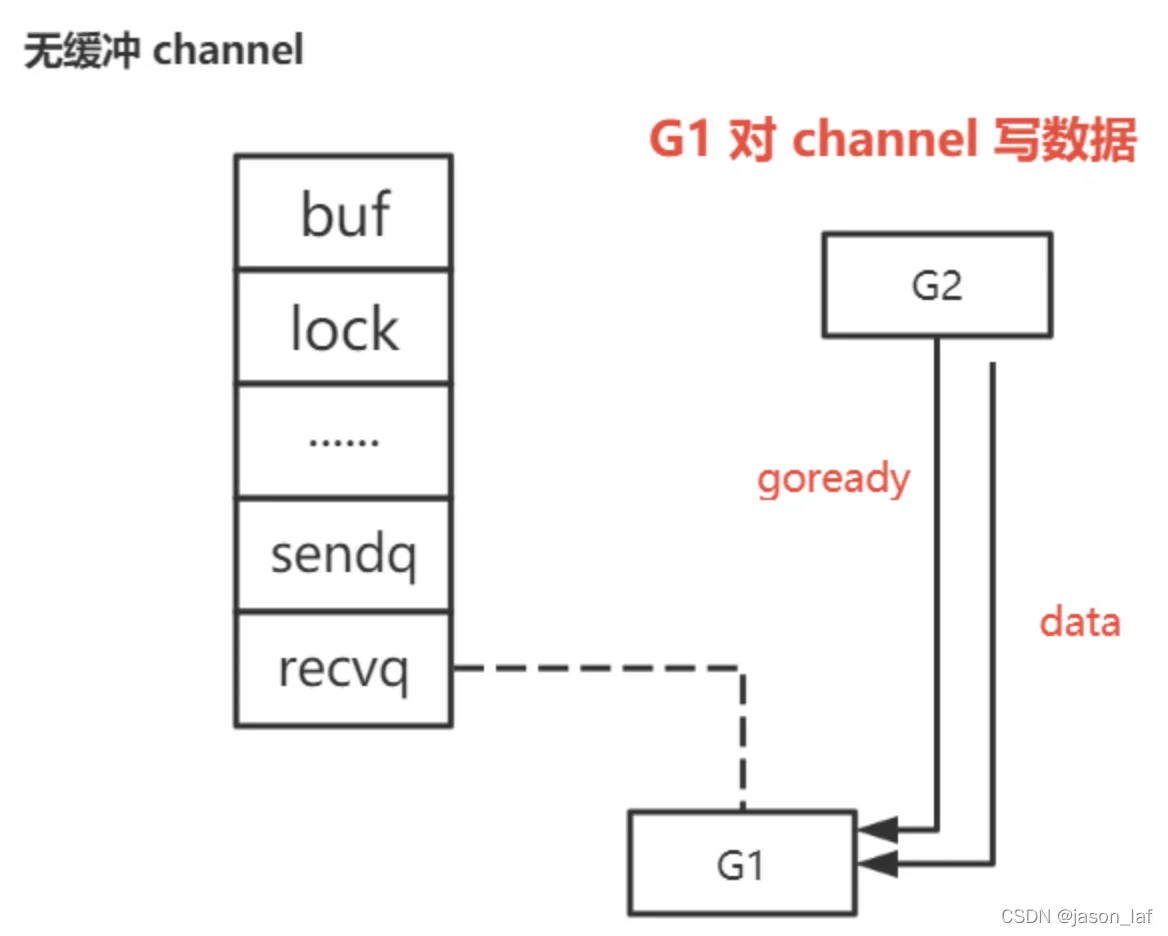
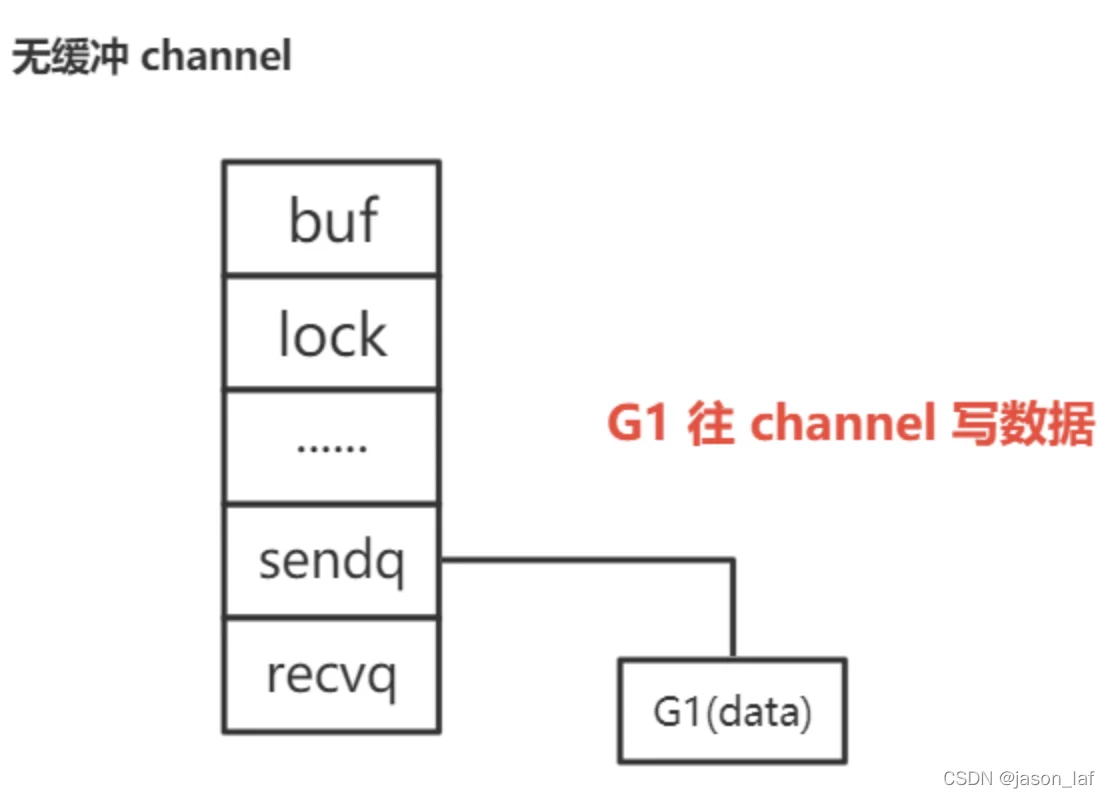
先写后读:由于channel是无缓冲的,因此G1(写goroutine)会被挂在sendq队列,然后休眠。当G2(读goroutine)来读数据时,发现sendq队列中的G1,将G1的数据取出来,并对G1设置goready函数,这样下次再发生调度时,G1就可以正常运行,并且会从等待队列中移除。
2. 有缓冲channel
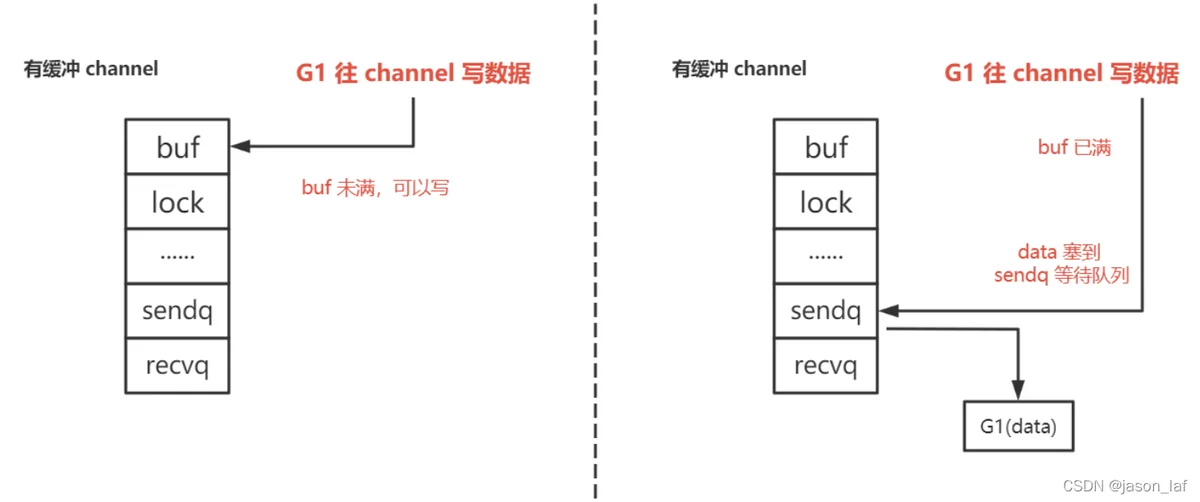
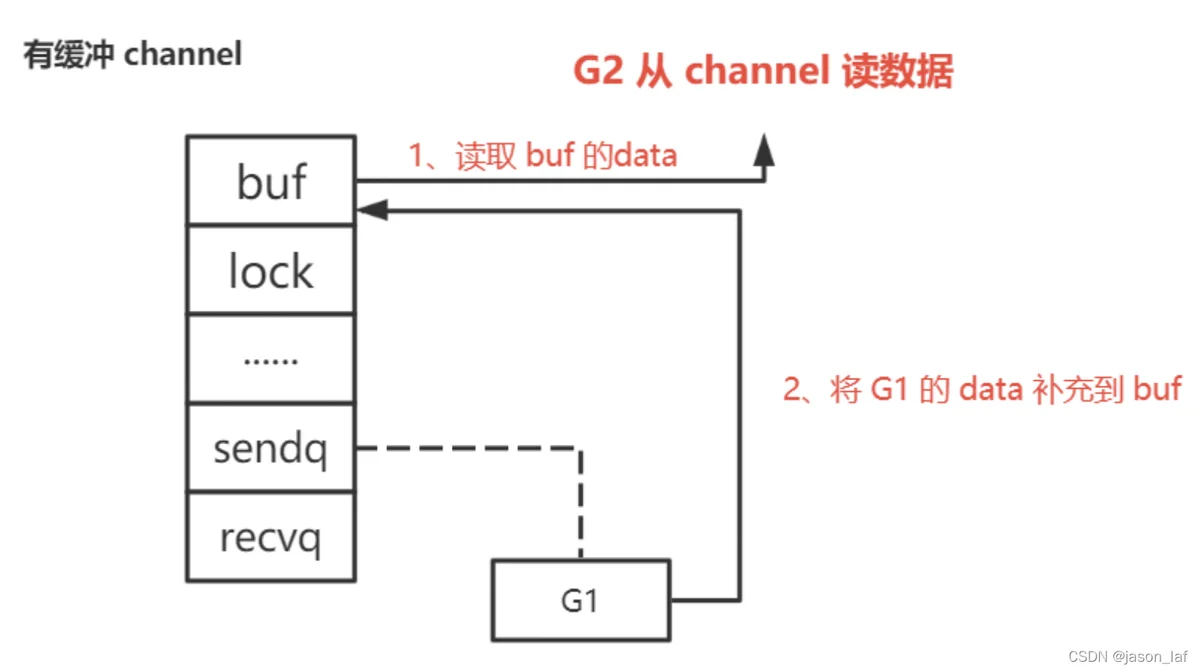
先读再写:先判断缓冲区是否有数据,如果有数据则从缓冲区取数据,取完数据之后如果sendq队列中有数据则会按序将sendq队列中的数据放入缓冲区尾部。如果没有数据则将G1(读goroutine)保存在recevq队列,并且休眠。当G2(写goroutine)写数据时,会判断缓冲区是否已满,如果已满则将G2挂在sendq队列,并休眠。如果未满则将G2(写goroutine)保存在缓冲区。
先写再读:先判断缓冲区是否已满,如果未满则将G1(写goroutine)保存在缓冲区,如果已满则将G1挂在sendq队列,并且休眠。当G2(读goroutine)读数据时,优先去缓冲区取数据,如果缓冲区没有数据则挂在recevq队列,并且休眠。当G2取完数据之后如果sendq队列中有数据则会按序将sendq队列中的数据放入缓冲区尾部。
ring buffer实现?
channel中使用了 ring buffer(环形缓冲区) 来缓存写入的数据。ring buffer 有很多好处,而且非常适合用来实现 FIFO 式的固定长度队列。
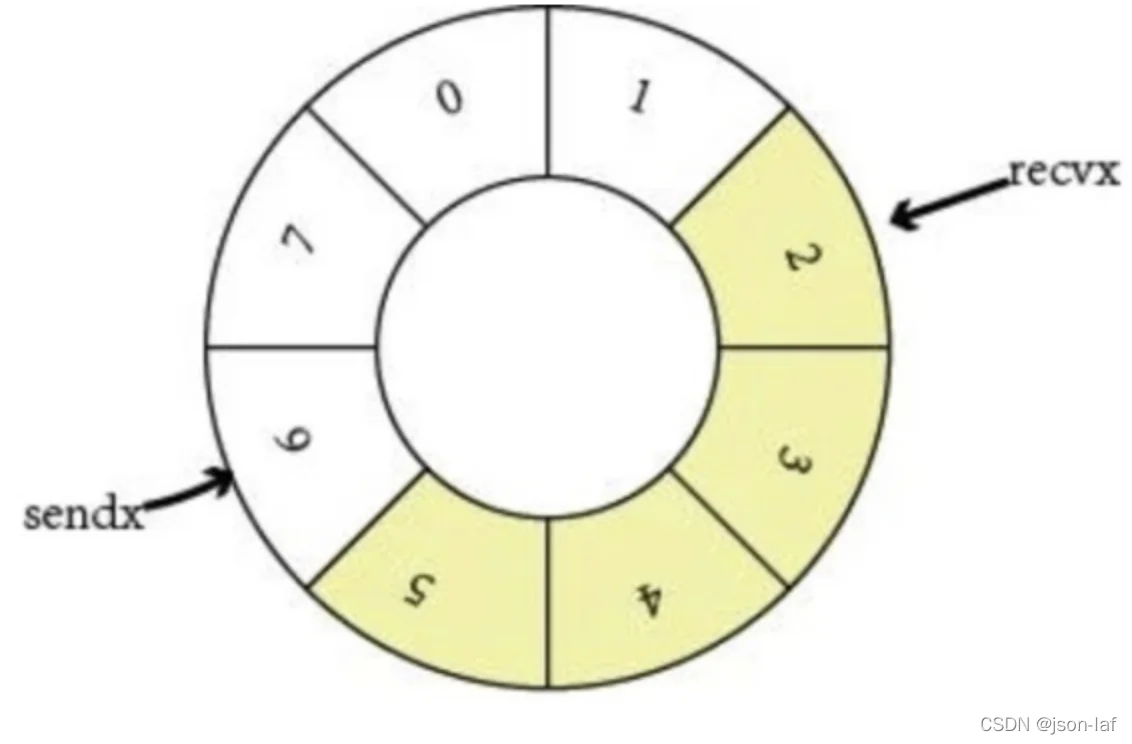
上图展示的是一个缓冲区为 8 的 channel buffer,recvx 指向最早被读取的数据,sendx 指向再次写入时插入的位置。
32、Golang中函数和方法的区别?
Golang中函数是指不属于任何结构体或自定义类型(不能是基本类型)的函数,也就是说函数没有接收者,而方法有接收者。
33、Golang方法值接收者和指针接收者的区别?
- 值类型接收者的方法,无论调用者是对象还行对象指针,都不会影响调用者本身。
- 指针类型接收者的方法,无论调用者是对象还是对象指针,都会影响调用者本身。
接收者是值类型的方法会隐含实现接收者是指针类型的方法,接收者是指针类型的方法会隐含实现值类型的方法。
通常我们会使用指针类型作为方法的接收者,原因是:
- 使用指针类型作为方法的接收者可以修改调用者的值。
- 使用指针类型作为方法的接收者可以避免在调用该方法时复制该值,在值的类型为大型结构体时,这样做会更加高效。
34、Golang中返回局部变量的指针是否安全?
一般来说,局部变量是分配在栈上,在函数返回后会自动销毁。
在Golang中,编译器会对每个局部变量做逃逸分析,如果变量的作用域超过了该函数,那么编译器会将该局部变量分配到堆上,所以即使函数释放,该局部变量也不会受到影响。
35、slice的底层原理?
slice是无固定长度的数组,大小为24个字节,底层是一个结构体。
type slice struct {
array unsafe.Pointer // 数组指针,8个字节
len int // 切片的长度,8个字节
cap int // 切片的容量,8个字节
}slice有三种状态:nil、空和零。
package main
import "fmt"
func main() {
var nilSlice []int // nil slice
emptySlice := make([]int, 0) // empty slice
zeroSlice := make([]int, 3) // zero slice
fmt.Println(nilSlice, emptySlice, zeroSlice)
}
36、slice深拷贝和浅拷贝的区别?
- 深拷贝:深拷贝拷贝的是数据本身,在内存中新开辟一个内存地址存放数据,修改新对象不会影响原来的对象。
- 浅拷贝:指的是拷贝数据的地址,本质上是指向同一个内存空间,修改内容会影响到原来的对象。
深拷贝方式:copy函数、通过遍历老切片append到新切片中。
package main
import (
"fmt"
)
func main() {
// 使用copy函数拷贝
oldSli := []int{1, 2, 3}
newSli := make([]int, 3)
res := copy(newSli, oldSli) // 返回拷贝元素的数量
fmt.Println(oldSli, newSli, res)
newSli1 := []int{}
res1 := copy(newSli1, oldSli) // 这里拷贝未成功,原因是新切片的容量为0
fmt.Println(oldSli, newSli1, res1)
// 使用遍历老切片,append函数拷贝
for _, val := range oldSli {
newSli1 = append(newSli1, val) // append函数内部会自动对slice扩容
}
fmt.Println(oldSli, newSli1)
}
// 输出
[1 2 3] [1 2 3] 3
[1 2 3] [] 0
[1 2 3] [1 2 3]浅拷贝方式:引用类型的变量默认的赋值操作就是浅拷贝
package main
import (
"fmt"
)
func main() {
oldSli := []int{1, 2, 3}
newSli := oldSli
fmt.Println(oldSli, newSli)
newSli[0] = 4
fmt.Println(oldSli, newSli)
}
// 输出
[1 2 3] [1 2 3]
[4 2 3] [4 2 3]37、slice和map是线程安全(并发安全)的么?为什么?
slice和map都不是线程安全的,多个线程对其操作可能会得到不正确的结果。
线程安全指的是多个线程访问同一个对象时,调用这个对象的行为都能获得正确的结果,那么这个对象就是线程安全的。
Golang官网认为map的应用场景更多是单线程,因此不应该为了小部分场景(并发)而对map加锁,因为加锁会产生性能消耗。
1. slice
slice底层并没有使用加锁等方式,对slice的行为不能得到正确的结果,所以不是线程安全的。
对slice并发操作并不会报错,只会造成数据丢失。
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
// var lock sync.Mutex
sli := []int{}
for i := 0; i < 10000; i++ {
wg.Add(1)
go func(i int) {
// lock.Lock()
// defer lock.Unlock()
sli = append(sli, i)
wg.Done()
}(i)
}
wg.Wait()
fmt.Println(len(sli))
}
// 这里每次都会输出不同的结果
// 产生的主要原因是同时读取到相同索引位,自然也就会产生覆盖的写入
// 解决方法是加锁,将注释的地方取消注释即可2. map
解决并发读写报错的方法:
第一种方式:使用读写锁
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
// var lock sync.RWMutex // 通过添加读写锁解决并发读写的问题
wg.Add(200)
m := make(map[int]int)
for i := 0; i < 100; i++ {
go func(i int) {
// lock.Lock()
m[i] = i
// lock.Unlock()
wg.Done()
}(i)
}
for i := 0; i < 100; i++ {
go func(i int) {
// lock.RLock()
fmt.Println(m[i])
// lock.RUnlock()
wg.Done()
}(i)
}
wg.Wait()
}
// 输出
fatal error: concurrent map writes
// 解决方法是加读写锁,取消注释部分即可第二种方式:使用Golang提供的sync.Map
package main
import (
"fmt"
"sync"
)
func main() {
var wg sync.WaitGroup
// var lock sync.RWMutex // 通过添加读写锁解决并发读写的问题
wg.Add(200)
// m := make(map[int]int)
var m sync.Map
for i := 0; i < 100; i++ {
go func(i int) {
// lock.Lock()
// m[i] = i
// lock.Unlock()
m.Store(i, i)
wg.Done()
}(i)
}
for i := 0; i < 100; i++ {
go func(i int) {
// lock.RLock()
// fmt.Println(m[i])
// lock.RUnlock()
v, ok := m.Load(i)
fmt.Println(v, ok)
wg.Done()
}(i)
}
wg.Wait()
}
// 截取部分输出
...
18 true
<nil> false
<nil> false
19 true
29 true
<nil> false
30 true
31 true
...
// 这里存在一个问题:map读的数据可能还没写入,所以会有nil
// sync.Map是用读写分离实现的,它包含了两个数据结构(read和dirty),其思想是空间换时间。
// 和map+RWMutex相比,sync.Map减少了加锁对性能的影响。
- 多个线程对map读不会报错
- 多个线程对map读写会报错
- 多个线程对map写会报错
Golang实现线程安全的方法:
互斥锁、读写锁、原子操作、channel
38、slice如何反转?
package main
import (
"fmt"
)
func main() {
a := []int{1, 2, 3, 4, 5, 6}
for left, right := 0, len(a)-1; left < right; left, right = left+1, right-1 {
a[left], a[right] = a[right], a[left]
}
fmt.Println(a, len(a), cap(a))
}39、slice的内存泄露是什么?
由于slice的底层是数组,很可能数组很大,但slice所取的元素数量却很小,这就导致数组占用的绝大多数空间是被浪费的。
如果我们只用到一个slice的一小部分,那么底层的整个数组也将继续保存在内存当中。当这个底层数组很大,或者这样的场景很多时,可能会造成内存急剧增加,造成崩溃。
解决方法:通过深拷贝将需要的分片复制到一个新的slice中去,减少内存的占用。
40、map遍历为什么是无序的?
map本身就是无序的,而且为了避免开发者认为map是有序的特意做了随机化。
- map遍历不是固定从0号bucket开始遍历的,每次遍历都是从一个随机的bucket中随机的cell开始遍历。
- map在扩容后会发生key的迁移,迁移后key可能从一个bucket迁移到另外一个bucket。
map有序遍历的方法:先对key排序,再按照key顺序遍历map。
package main
import (
"fmt"
"sort"
)
func main() {
sli := []int{}
m := map[int]string{
1: "Alice",
2: "Bob",
3: "Carol",
4: "Dave",
}
for v := range m {
sli = append(sli, v)
}
sort.Ints(sli)
fmt.Println("排序前...")
for i, v := range m {
fmt.Println(i, v)
}
fmt.Println("排序后...")
for _, v := range sli {
fmt.Println(v, m[v])
}
}
// 输出
排序前...
3 Carol
4 Dave
1 Alice
2 Bob
排序后...
1 Alice
2 Bob
3 Carol
4 Dave41、map哈希冲突的解决方法?
- 哈希表:根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为哈希表,这一映像过程称为哈希造表或者散列,所得的存储位置称哈希地址或散列地址。
- 哈希冲突:在计算hash地址的过程中会出现对于不同的关键字出现相同的哈希地址的情况,即key1 ≠ key2,但是f(key1) = f(key2),这种情况就是hash冲突。由于哈希函数是从关键字集合和地址集合的映像,通常关键字集合比较大,而地址集合的元素仅为哈希表中的地址值,韵词哈希冲突只能尽可能的减少,不能完全避免。
Golang解决哈希冲突的方法是拉链法(链地址法),其思想是当产生哈希冲突时,创建一个新的bucket,并将发生冲突的bucket的overflow区指向新bucket。
哈希冲突方法总结:开放地址法(线性探测、二次探测、随机探测)、链地址法、建立公共溢出区、再哈希法。
- 开放地址法:当发生冲突时,按照一定算法查找一个空位置存放。
- 链地址法:将所有关键字为同义字的记录存储在一个链表中 。
- 建立公共溢出区:在创建哈希表的同时,再额外创建一个公共溢出区,专门用来存放发生哈希冲突的元素。查找时,先从哈希表查,查不到再去公共溢出区查。
- 再哈希法:出现冲突后采用其他的哈希函数计算,直到不再冲突为止。
42、map的负载因子为什么是6.5?
负载因子是衡量哈希表空间占用率的核心指标,也就是平均每个bucket存储元素个数。其主要作用是平衡bucket占用存储空间大小和查找元素时的性能高低。Golang官方经过实验得出负载因子为6.5时哈希表的性能较好。负载因子为6.5意味着当map元素个数大于或等于bucket个数*6.5时,map会发生扩容。
负载因子=哈希表元素个数/桶的个数
负载因子与哈希表的扩容和迁移等重新哈希(rehash)行为有直接关系:
- 对map进行插入和删除操作时,会导致bucket不均,内存利用率低,需要迁移
- 当负载因子过大,哈希冲突的几率大,需要对map进行扩容
- 负载因子越大,bucket中的元素越多,空间利用率越高,但发生哈希冲突的几率变大
- 负载因子越小,bucket中的元素越少,发生哈希冲突的几率变小,但空间利用率低,且还会增加扩容操作的次数。
43、map的扩容机制?
往map中插入新元素是,会进行条件检测,符合以下两种情况会触发扩容:
- 超过负载:map的元素个数大于负载因子6.5*bucket的个数。
- 溢出bucket的数量过多:当bucket的个数小于2^15时,如果溢出bucket的个数大于等于bucket的个数,则认为溢出bucket的数量过多;当bucket个数小于2^15时,如果溢出bucket的个数大于等于2^15,则认为溢出bucket数量过多。
对于超过负载,map使用双倍扩容机制,即新建一个bucket数组,数组大小是原来的两倍。然后将旧的bucket数据搬迁到新的bucket中。
对于溢出bucket的数量过多,map使用等量扩容机制,即bucket数量保持不变,做一次类似双倍扩容的搬迁动作(重新排序原来分散的键值对),使数据排列的更紧密。
44、CSP模型?
“不要通过共享内存来通信,我们应该使用通信来共享内存”。这句话对应两种共享内存的模型。第一种是直接读取内存中的数据,第二种是通过发送消息的方式来进行同步。CSP(Communicating Sequential Process,通信顺序进程)就是基于第二种方式的并发编程模型。Golang中的channel和goroutine是CSP模型的体现,即不同的并发实体通过共享的channel实现通信。
- 优点:解耦生产者和消费者,降低并发中的耦合。
- 缺点:容易发生死锁
45、为什么channel是线程安全的?
- 从设计初衷来看,channel本身就是为了并发而生,为了保证数据的一致性,必须保证线程安全。
- 从实现原理来看,hmap结构体中有一个互斥锁保证数据的读写安全,对循环数组buf中的数据进行入队和出队的时候,必须先获取锁才能操作channel数组。
46、如何通过channel控制多个goroutine的执行顺序?
由于多个goroutine并发执行时,每个goroutine抢到的处理器的时间不一样,所以执行的顺序也就不一样。可以通过channel的阻塞机制来控制goroutine的执行顺序。
47、channel在什么情况下会发生死锁?
- 单个协程永久阻塞导致死锁
- 多个协程由于资源竞争或彼此通信而造成的一种阻塞现象。
48、互斥锁的实现原理?
Golang中有两种锁:互斥锁(sync.Mutex)和读写互斥锁(sync.RWMutex),都属于悲观锁。
Mutex的概念:当一个goroutine获得锁之后,其他goroutine不能获得锁,即只能存在一个读者或写者,不能同时读和写。
使用场景:多个线程同时访问临界区,为了保证数据的安全,锁住一些共享资源,以防止并发访问这些共享数据时可能导致的数据不一致的问题。
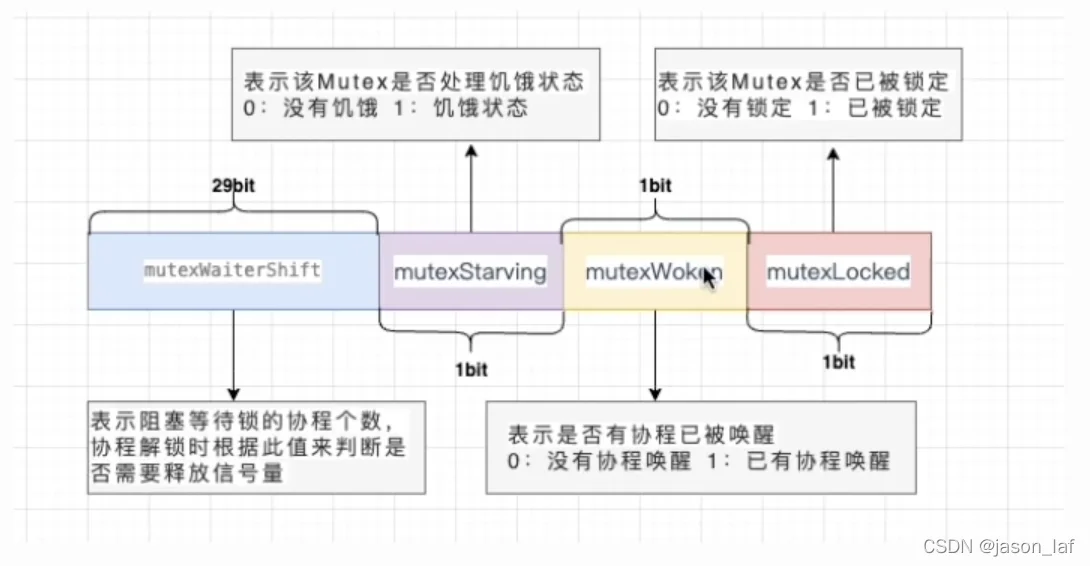
Mutex本质上是一个结构体,包含state和sama两个字段,占8个字节。
底层数据结构:
type Mutex struct {
state int32 // state使用二进制表示锁的状态,有锁定、被唤醒和饥饿模式等。
sama uint32 // 信号量,mutex阻塞队列的定位是通过这个变量来实现的,从而实现goroutine的阻塞和唤醒
}state表示内容示意图:
sama表示内容示意图:
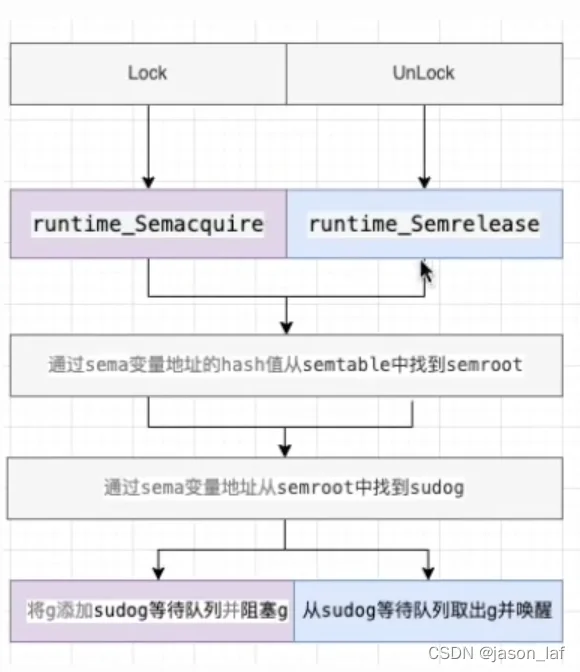
锁的操作:锁的实现一般会依赖于原子操作和信号量。通过原子操作实现锁的锁定,通过信号量实现线程的阻塞与唤醒。
加锁:通过原子操作CAS获取锁,如果成功则结束。如果不成功则进入自旋,满足自旋条件则循环获取锁。如果四次自旋后仍然未获得锁,则进入阻塞等待被唤醒。当拥有锁的goroutine解锁后,会唤醒等待的goroutine,被唤醒的goroutine会重新获取锁。如果该goroutine一直没有获取锁,则会进入饥饿模式,在饥饿模式下该goutine不用抢直接获取锁。

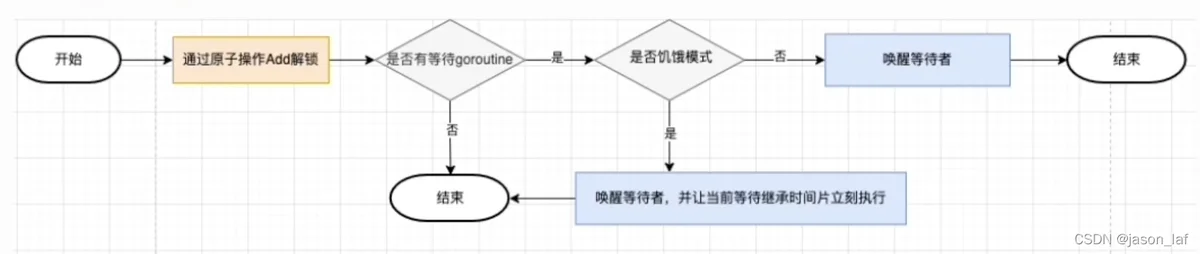
解锁:通过原子操作Add解锁,判断是否有等待的goroutine,如果没有则结束。如果有等待的goroutine则判断其是否处在饥饿模式,如果是饥饿模式,则直接唤醒并让当前等待继承时间片立刻执行。如果不是饥饿模式,则只唤醒等待者,让被阻塞的goroutine和新进来的goroutine进行竞争。
注意点:
- Lock()之前Unlock()会fatal error: sync: unlock of unlocked mutex
- Lock()之后再次Lock()会导致死锁
- 锁定状态与goroutine没有关联,一个goroutine加锁,另一个goroutine可以解锁。
49、互斥锁正常模式和饥饿模式的区别?
Golang中有两种抢锁的模式:正常模式和饥饿模式。
刚开始的时候处于正常模式,当G1拥有锁的时候,G2会不断自旋尝试获取锁,自旋4次后如果未获取锁就会进入等待队列里,并阻塞等待被唤醒。
- 在正常模式下,goroutine按照先进先出(FIFO)的顺序等待。唤醒的goroutine不会直接获取锁,而是与新的goroutine竞争锁。由于新的goroutine正在被CPU执行,所以被唤醒的goroutine在与新创建的goroutine竞争中很有可能会失败,导致长时间获取不到锁。为了减少这种情况的发生,如果被唤醒的Goroutine在1ms内没有获取锁,就会将互斥锁切换为饥饿模式。这时就会进入饥饿模式。
- 在饥饿模式下,锁会直接交给等待队列的第一位Goroutine。新创建的Goroutine不会参与抢锁和自旋,而是直接进入等待队列的尾部。当(1)等待队列清空;(2)Goroutine获取锁的时间小于1ms。
50、互斥锁允许自旋的条件?
Golang中的互斥锁实现了自旋和阻塞两种场景,当满足不了自旋的条件时,就会进入阻塞。
当线程获取不到锁的时候,会有2种处理方式:自旋和堵塞。
- 自旋是没有获取到锁的线程循环判断该资源是否释放。适用于低并发且程序执行时间短的场景,缺点是耗费CPU资源。
- 堵塞是将自己堵塞起来,将CPU释放给其他线程,内核会将线程置为堵塞状态,待锁释放后,内核会在合适的时间唤醒线程。适用于高并发场景,缺点是有线程切换上下文的开销。
允许自旋的条件。
- 锁被占用,且未处于饥饿模式。
- 累计自旋次数小于最大自旋次数4。
- CPU核数大于1。
- 有空闲的P
- 当前Goroutine所挂载的P下面,本地待运行队列为空。