
golang序列化和反序列化在encoding/json包,主要方法为encoding/json.Marshal和encoding/json.Unmarshal,序列化和反序列化主要是通过反射来实现的。
序列化
序列化是调用encoding/json.Marshal,一开始会定义一个encodeState结构体,在序列化过程中可以理解为一种树形的解析方式,树形的方式常规的一种方式就是用递归的方式去实现,我们知道递归很容易引起性能问题,所以json源码里也做了缓存的优化,encodeState里用到了bytes.Buffer,正是在递归过程中不断写入buffer,最后统一获取输出。
func Marshal(v interface{}) ([]byte, error) {
e := newEncodeState()
//执行序列化
err := e.marshal(v, encOpts{escapeHTML: true})
if err != nil {
return nil, err
}
//序列化完成之后通过读取buffer输出
buf := append([]byte(nil), e.Bytes()...)
encodeStatePool.Put(e)
return buf, nil
}
实现
序列化的思路很简单
一开始传入interface接口类型,然后通过反射获取到数据类型,根据不同的数据类型或者实现内置的接口得到不同的编码方法encoderFunc,最后完成序列化工作。
func (e *encodeState) reflectValue(v reflect.Value, opts encOpts) {
valueEncoder(v)(e, v, opts)
}
func valueEncoder(v reflect.Value) encoderFunc {
.....
return typeEncoder(v.Type())
}
获取接口类编码方法
在json包中提供了两个接口encoding/json.Marshaler和encoding.TextMarshaler,可以实现这两个接口来完成自定义的序列化的工作,如果实现了这两个接口,就会返回对应的编码方法。
那么怎样才算实现一个接口呢?我们以结构体为例:
- 如果是结构体指针变量,对于结构体实现接口或者结构体指针实现接口都是通过的。
- 如果是结构体变量,对于结构体实现接口是通过的,但是结构体指针实现接口是不通过的。
在json序列化源码中,对于结构体变量,接口的实现又是结构体指针的情况,因为结构体变量对应的指针是通过的,也就是实现这个接口的,所以处理方式是会先的到一个条件编码newCondAddrEncoder,然后在用反射中的CanAddr是否可以寻址去调用接口实现方法还是继续使用内置的编码方法。
func newTypeEncoder(t reflect.Type, allowAddr bool) encoderFunc {
if t.Kind() != reflect.Ptr && allowAddr && reflect.PtrTo(t).Implements(marshalerType){
return newCondAddrEncoder(addrMarshalerEncoder,newTypeEncoder(t,false))
}
if t.Implements(marshalerType){
return marshalerEncoder
}
if t.Kind() != reflect.Ptr && allowAddr && reflect.PtrTo(t).Implements(textMarshalerType){
return newCondAddrEncoder(addrTextMarshalerEncoder,newTypeEncoder(t,false))
}
if t.Implements(textMarshalerType){
return textMarshalerEncoder
}
}
.....
- 如果当前不是指针类型、可以寻址的并且它的指针实现了Marshaler,那么就可以得到一个条件编码,然后再根据这个类型是否可以寻址去得到addrMarshalerEncoder编码方法或使用内置的编码方法
- 当前的数据类型直接实现了Marshaler,返回marshalerEncoder编码方法
- 如果当前不是指针类型、可以寻址的并且它的指针实现了TextMarshaler,那么就可以得到一个条件编码,然后再根据这个类型是否可以寻址去得到addrTextMarshalerEncoder编码方法或使用内置的编码方法
- 当前数据类型直接实现了TextMarshaler,返回textMarshalerEncoder编码方法
获取不同类型对应的编码方法
上面提到的内置的编码方法,就是json里面根据不同的类型得到的编码方法,类型包含int、bool、float、string、struct、interface、map、slice、array和ptr等。
func newTypeEncoder(t reflect.Type, allowAddr bool) encoderFunc {
.....
switch t.Kind() {
case reflect.Bool:
return boolEncoder
case reflect.Int,reflect.Int8,reflect.Int16,reflect.Int32,reflect.Int64:
return intEncoder
case reflect.Uint,reflect.Uint8,reflect.Uint16,reflect.Uint32,reflect.Uint64,reflect.Uintptr:
return uintEncoder
case reflect.Float32:
return float32Encoder
case reflect.Float64:
return float64Encoder
case reflect.String:
return stringEncoder
case reflect.Interface:
return interfaceEncoder
case reflect.Struct:
return newStructEncoder(t)
case reflect.Map:
return newMapEncoder(t)
case reflect.Slice:
return newSliceEncoder(t)
case reflect.Array:
return newArrayEncoder(t)
case reflect.Ptr:
return newPtrEncoder(t)
default:
return unsupportedTypeEncoder
}
}
前面也提到用树形方式递归调用,正是通过这个方法,生成最后的数据,下面给一个简单的递归示例图:
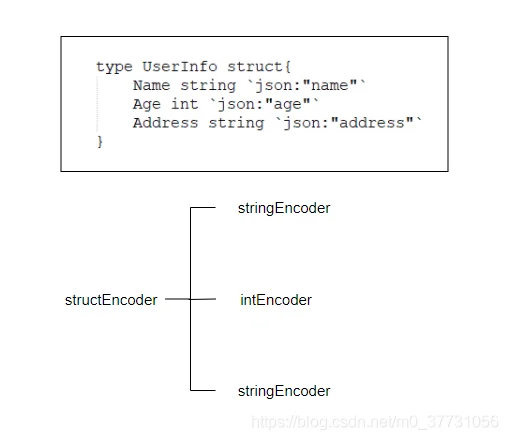
- 指针ptr或interface,通过反射获取Elem元素,然后针对元素类型进一步分析。
- map和struct,通过反射获得所有keys或fileds字段,然后针对key或filed字段类型进一步分析,注意这里结构体字段还有标签tags的映射关系。
- slice和array,通过反射获取Elem元素,然后针对元素类型编码每个值。
- bool、int和float直接对单值进行编码。
调用编码方法
下面以最常用的结构体为例,去分析它的编码过程:
func newStructEncoder(t reflect.Type) encoderFunc {
se := structEncoder{fields: cachedTypeFields(t)}
return se.encode
}
首先构造一个structEncoder对象,然后这个对象保存了结构体每个字段的信息,还记得上面提到的,先去得到每个字段信息,然后分析对应字段的数据类型,得到不同的编码方法吧?这里调用cachedTypeFields方法说明字段是会被缓存的,最后实际上调用的是encoding/json.typeFields方法。
func typeFields(t reflect.Type) structFields {
// Anonymous fields to explore at the current level and the next.
current := []field{}
next := []field{{typ: t}}
// Count of queued names for current level and the next.
var count, nextCount map[reflect.Type]int
// Types already visited at an earlier level.
visited := map[reflect.Type]bool{}
// Fields found.
var fields []field
// Buffer to run HTMLEscape on field names.
var nameEscBuf bytes.Buffer
//结构体之间可以嵌套,需要循环遍历
for len(next) > 0 {
current, next = next, current[:0]
count, nextCount = nextCount, map[reflect.Type]int{}
for _, f := range current {
if visited[f.typ] {
continue
}
visited[f.typ] = true
//遍历结构体的每个字段
for i := 0; i < f.typ.NumField(); i++ {
sf := f.typ.Field(i)
//表示私有的属性不可输出
isUnexported := sf.PkgPath != ""
//表示是否是嵌套类型
if sf.Anonymous {
t := sf.Type
if t.Kind() == reflect.Ptr {
t = t.Elem()
}
if isUnexported && t.Kind() != reflect.Struct {
// Ignore embedded fields of unexported non-struct types.
continue
}
// Do not ignore embedded fields of unexported struct types
// since they may have exported fields.
} else if isUnexported {
// Ignore unexported non-embedded fields.
continue
}
//获取标签信息
tag := sf.Tag.Get("json")
if tag == "-" {
continue
}
//解析标签信息
name, opts := parseTag(tag)
if !isValidTag(name) {
name = ""
}
index := make([]int, len(f.index)+1)
copy(index, f.index)
index[len(f.index)] = i
ft := sf.Type
//如果名字为空并且字段类型是指针
if ft.Name() == "" && ft.Kind() == reflect.Ptr {
// Follow pointer.
//进一步获取字段的元素,得到非指针的数据类型
ft = ft.Elem()
}
// Only strings, floats, integers, and booleans can be quoted.
quoted := false
//如果包含string标签,则将string,float,int,bool类型的字段做上标记,后续转化为string类型
if opts.Contains("string") {
switch ft.Kind() {
case reflect.Bool,
reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64,
reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr,
reflect.Float32, reflect.Float64,
reflect.String:
quoted = true
}
}
// Record found field and index sequence.
//如果名字不为空或者不是嵌套类型或者字段类型不是结构体,则生成字段信息
if name != "" || !sf.Anonymous || ft.Kind() != reflect.Struct {
tagged := name != ""
if name == "" {
name = sf.Name
}
//得到具体的字段信息
field := field{
name: name,
tag: tagged,
index: index,
typ: ft,
omitEmpty: opts.Contains("omitempty"),//空值过滤的标签omitempty
quoted: quoted,
}
field.nameBytes = []byte(field.name)
field.equalFold = foldFunc(field.nameBytes)
// Build nameEscHTML and nameNonEsc ahead of time.
//将字段信息写入buf,保存到字段信息中
nameEscBuf.Reset()
nameEscBuf.WriteString(`"`)
HTMLEscape(&nameEscBuf, field.nameBytes)
nameEscBuf.WriteString(`":`)
field.nameEscHTML = nameEscBuf.String()
field.nameNonEsc = `"` + field.name + `":`
fields = append(fields, field)
if count[f.typ] > 1 {
// If there were multiple instances, add a second,
// so that the annihilation code will see a duplicate.
// It only cares about the distinction between 1 or 2,
// so don't bother generating any more copies.
fields = append(fields, fields[len(fields)-1])
}
continue
}
// Record new anonymous struct to explore in next round.
//如果有嵌套字段,继续分析嵌套的结构体
nextCount[ft]++
if nextCount[ft] == 1 {
next = append(next, field{name: ft.Name(), index: index, typ: ft})
}
}
}
}
for i := range fields {
f := &fields[i]
f.encoder = typeEncoder(typeByIndex(t, f.index))//分析每个字段的数据类型,得到编码方法
}
nameIndex := make(map[string]int, len(fields))
for i, field := range fields {
nameIndex[field.name] = i
}
return structFields{fields, nameIndex}
}
分析完结构体的字段,也就是最后执行结构体的编码方法,其实也是执行结构体每个字段的编码方法。
func (se structEncoder) encode(e *encodeState, v reflect.Value, opts encOpts) {
next := byte('{')
FieldLoop:
for i := range se.fields.list {
f := &se.fields.list[i]
// Find the nested struct field by following f.index.
fv := v
//通过索引得到字段的值信息
for _, i := range f.index {
if fv.Kind() == reflect.Ptr {
if fv.IsNil() {
continue FieldLoop
}
fv = fv.Elem()
}
fv = fv.Field(i)
}
//如果标签是omitempty并且对应字段值是空值,则跳过
if f.omitEmpty && isEmptyValue(fv) {
continue
}
//将字段的编码信息写入encodeState的buf中,encodeState是作为最后编码结果输出的
e.WriteByte(next)
next = ','
if opts.escapeHTML {
e.WriteString(f.nameEscHTML)
} else {
e.WriteString(f.nameNonEsc)
}
opts.quoted = f.quoted
//执行对应字段的编码方法
f.encoder(e, fv, opts)
}
//编码结束符号标记
if next == '{' {
e.WriteString("{}")
} else {
e.WriteByte('}')
}
}
反序列化
反序列化是调用encoding/json.Unmarshal,同样是定义decodeState结构体,通过分析json数据,得到我们想要的结构体。
实现
一开始传入的也是interface接口类型,和序列化不同的是这里的接口类型必须是指针类型,因为json数据最后是要写入到这个传入的对象的,所以这个对象必须是可写入的。
反序列化实现方式也和序列化有些不同,不同在于从分析它的数据类型变为按顺序去解析,通过解析对应特殊符号来得到想要的对象。
func Unmarshal(data []byte, v interface{}) error {
// Check for well-formedness.
// Avoids filling out half a data structure
// before discovering a JSON syntax error.
var d decodeState
err := checkValid(data, &d.scan)//校验数据
if err != nil {
return err
}
d.init(data)//初始化数据
return d.unmarshal(v)//反序列化
}
json数据起始符和结束符
{["-tfn:,}]func stateBeginValue(s *scanner, c byte) int {
if isSpace(c) {
return scanSkipSpace
}
switch c {
case '{':
//下一步的步骤
s.step = stateBeginStringOrEmpty
//说明当前扫描得是对象,当前要要先解析对象的key值
return s.pushParseState(c, parseObjectKey, scanBeginObject)
case '[':
s.step = stateBeginValueOrEmpty
//说明当前扫描的是数组,当前要先解析对象的元素值
return s.pushParseState(c, parseArrayValue, scanBeginArray)
case '"'://string类型的字面量
s.step = stateInString
//解析的是字面量信息,key或value
return scanBeginLiteral
case '-'://负号开头字面量
s.step = stateNeg
return scanBeginLiteral
case '0': //0或0开头小数字面量 beginning of 0.123
s.step = state0
return scanBeginLiteral
case 't': //true字面量 beginning of true
s.step = stateT
return scanBeginLiteral
case 'f': //false字面量 beginning of false
s.step = stateF
return scanBeginLiteral
case 'n': //null字面量 beginning of null
s.step = stateN
return scanBeginLiteral
}
//数字或小数字面量
if '1' <= c && c <= '9' { // beginning of 1234.5
s.step = state1
return scanBeginLiteral
}
return s.error(c, "looking for beginning of value")
}
解析array、object、literal
在解析完起始符后,会进入到反序列化的执行的入口,进一步去得到我们想要的array数组、object对象、literal字面量。
func (d *decodeState) value(v reflect.Value) error {
switch d.opcode {
default:
panic(phasePanicMsg)
case scanBeginArray:
.....
case scanBeginObject:
if v.IsValid() {
if err := d.object(v); err != nil {
return err
}
} else {
d.skip()
}
d.scanNext()
case scanBeginLiteral:
....
}
return nil
}
我们先来看看反序列化是如何解析对象的,对象的解析是调用object方法,我们以结构体为例:
一开始会调用encoding/json.indirect方法得到三个不同类型的值,分别为Unmarshaler接口实例、TextUnmarshaler接口实例和得到当前传入对象的非指针类型。
如果实现encoding/json.Unmarshaler或encoding.TextUnmarshaler接口实例就会被调用。
func (d *decodeState) object(v reflect.Value) error {
// Check for unmarshaler.
u, ut, pv := indirect(v, false)
if u != nil {
start := d.readIndex()
d.skip()
return u.UnmarshalJSON(d.data[start:d.off])
}
.....
在未实现接口的情况,反序列化使用传入对象的非指针类型,先去得到所有的字段信息。
func (d *decodeState) object(v reflect.Value) error {
.....
v = pv
t := v.Type()
var fields structFields
switch v.Kind() {
case reflect.Struct:
fields = cachedTypeFields(t)//得到当前结构体对象的所有字段信息
}
for{
d.scanWhile(scanSkipSpace)
//根据偏移量得到想要的字段名称
start := d.readIndex()
d.rescanLiteral()
item := d.data[start:d.readIndex()]
key, ok := unquoteBytes(item)
var subv reflect.Value
//得到想要的字段信息
var f *field
if i, ok := fields.nameIndex[string(key)]; ok {
// Found an exact name match.
f = &fields.list[i]
}
if f != nil {
subv = v
subv = subv.Field(i)
}
d.scanWhile(scanSkipSpace)
//回到调用的入口去解析字段的字面量信息
if err := d.value(subv); err != nil {
return err
}
}
}
再通过入口方法value得到我们想要的字面量信息,并写入到对象中。
func (d *decodeState) value(v reflect.Value) error {
switch d.opcode {
default:
panic(phasePanicMsg)
case scanBeginArray:
.....
case scanBeginObject:
.....
case scanBeginLiteral://当前扫描字面量信息
// All bytes inside literal return scanContinue op code.
start := d.readIndex()
d.rescanLiteral()
if v.IsValid() {
//最后将解析出来的字面量信息写入到传入的对象中
if err := d.literalStore(d.data[start:d.readIndex()], v, false); err != nil {
return err
}
}
}
return nil
}
最后来看一看,字面量是如何调用rescanLiteral对字符串进行切片的。
func (d *decodeState) rescanLiteral() {
data, i := d.data, d.off
Switch:
switch data[i-1] {
case '"': // string字符串的解析
for ; i < len(data); i++ {
switch data[i] {
case '\\':
i++ // escaped char
case '"':
i++ // tokenize the closing quote too
break Switch
}
}
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '-': // number 数字的解析
for ; i < len(data); i++ {
switch data[i] {
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'.', 'e', 'E', '+', '-':
default:
break Switch
}
}
case 't': // true 布尔的解析
i += len("rue")
case 'f': // false
i += len("alse")
case 'n': // null
i += len("ull")
}
if i < len(data) {
d.opcode = stateEndValue(&d.scan, data[i])//解析完字面量之后,跳转到结束符号方法
} else {
d.opcode = scanEnd
}
d.off = i + 1
}
更多欢迎关注go成神之路