记得大学刚毕业那年看了侯俊杰的《深入浅出MFC》,就对深入浅出这四个字特别偏好,并且成为了自己对技术的要求标准——对于技术的理解要足够的深刻以至于可以用很浅显的道理给别人讲明白。以下内容为个人见解,如有雷同,纯属巧合,如有错误,烦请指正。
今天,我们聊一聊go语言中chan,在开始我们话题之前,我们先看看官方对于chan的介绍(其中斜体为原文拷贝,没有任何加工):
A channel provides a mechanism for concurrently executing functions to communicate by sending and receivingvalues of a specified element type. The value of an uninitialized channel is nil.
chan提供了一种并发通信机制,用于生产和消费某一指定类型数据,未初始化的chan的值是nil(这一点可以看出chan是interface类型,只是内建在编译器内)。
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
chan的类型可以是chan、chan<-、<-chan任意一种+数据类型(如int或者自定义类型),有没有发现chan和C++的模板很像?
The optional <- operator specifies the channel direction, send or receive. If no direction is given, the channel isbidirectional. A channel may be constrained only to send or only to receive by conversion or assignment.
<-运算符是用来指定chan的方向的,发送或者接收(生产或消费),如果没有给定方向,chan就是双向的。通道在赋值或者类型转换时可以限定仅接收或者仅发送。这一点可以类比C语言一个用法:函数1通过malloc申请了一片内存并填入了自己设定的值,然后调用函数2时,限定函数2只能读取,那么我们就在函数2的参数证明中加const关键字,函数2访问的是与函数1相同的内存,但却只能读取(其实函数内部在做一次强行类型转换也能写入,防君子不妨小人啊~)。例子可能不太恰当,希望能够帮助语言转型读者理解。有以下几点需要注意(类型采用int作为例子):
- make(chan<- int, 8)和make(<-chan int, 8),编译是可以通过的,但我实在想不出来这东西能有啥用,new出来的chan要么只接收要么只发送,何来通信呢?
- chan int无需任何转换语句就可以赋值给chan<- int和<-chan int两种类型的变量;
- chan<- int或者<-chan int不能够转换为其他类型
以上需要注意的几点经过go1.9.2编译器验证
chan T // can be used to send and receive values of type T
chan<- float64 // can only be used to send
float64s <-chan int // can only be used to receive ints
上面这几句话就不翻译了,都能看明白
The <- operator associates with the leftmost chan possible:
chan<- chan int // same as chan<- (chan int)
chan<- <-chan int // same as chan<- (<-chan int)
<-chan <-chan int // same as <-chan (<-chan int) chan (<-chan int)
<-运算符总是优先和左边的chan组合成类型,如上面的语句所示,虽然说所有语句都是无效的,但是能帮助读者理解,那么问题来了,<-chan <-chan int为什么等同于<-chan (<-chan int)呢?我是这样理解的:第二个<-优先与左边的chan组合,但是左边的chan因为已经和第一个<-组合了,相当于第二个<-左边没有chan了,所以只能与右边的chan组合。
A new, initialized channel value can be made using the built-in function make, which takes the channel type and an optional capacity as arguments:
make(chan int, 100)
使用编译器内建函数make创建新的chan,同时可以指定容量。
The capacity, in number of elements, sets the size of the buffer in the channel. If the capacity is zero or absent, the channel is unbuffered and communication succeeds only when both a sender and receiver are ready. Otherwise, the channel is buffered and communication succeeds without blocking if the buffer is not full (sends) or not empty (receives). A nil channel is never ready for communication.
容量指的是chan为指定类型对象创建的缓冲数量,如果容量设定为0或者没有指定(make(chan int)),chan内部不会创建缓冲,只有接收者和发送者都就绪后才能通信。否则,chan当缓冲未满或者非空时是不会阻塞发送者或者接收者的。空chan(未初始化)是不可以用于通信的。这里面就有大量信息了:
- chan在接收和发送会阻塞,阻塞条件是接收是缓冲空或者发送时缓冲满;
- 如果没有缓冲,接收者和发送者需要同时就绪才会通信,否则调用者就会阻塞,何所谓同时就绪,就是接收者调用接收(<-chan)同时发送者调用发送(chan<-)那一刻。我们常常写测试程序的时候在main函数中创建了一个无缓冲的chan,然后立刻发送一个数据,后面再创建协程接收数据,main函数就会阻塞造成死锁。这是为什么呢?因为无缓冲chan在双方都就绪后才能通信,否则就会阻塞调用者,所以要先创建协程接收数据,然后再main函数中发送一个数据。
- 没有被初始化的chan在调用发送或者接收的时候会被阻塞,没想到吧?C/C++程序猿第一感觉肯定崩溃,因为是空指针(nil)。
A channel may be closed with the built-in function close. The multi-valued assignment form of the receive operator reports whether a received value was sent before the channel was closed.
chan通过内建函数close删除,或者说析构,接收者可以通过多值赋值的方式来感知chan是否已经关闭了。什么意思呢?就是说<-chan是一个两个返回值的函数,第一个返回值是指定类型的对象,第二个返回值就是是否接收到了数据,如果第二个返回值是false,说明chan已经关闭了。这里面有一个比较有意思的事情,当chan缓冲中还有一些数据时,关闭chan(调用内建函数close)后,接收者不会立刻收到chan关闭信号(就是第二个返回值为false),而是等缓冲中所有的数据全部被读取后接收者才会收到chan关闭信号。这一点对于C/C++的程序猿是无法想象的,因为chan已经关闭了,意味着内存都已经回收了,而go是有垃圾回收机制,也就不用担心这一点了。
A single channel may be used in send statements, receive operations, and calls to the built-in functions cap andlen by any number of goroutines without further synchronization. Channels act as first-in-first-out queues. For example, if one goroutine sends values on a channel and a second goroutine receives them, the values are received in the order sent.
一个chan可以在任意协程发送、接收或者调用内建函数(cap和len),无需在用其他的同步机制(意思就是线程安全,当然在go语言中没有线程只有协程)。chan可以看做是FIFO队列,数据是先入先出。
好啦,有关chan的官方解释分析完了,我们可以总结一下几点:
- chan是一个用于开发并行程序比较好用的同步机制;
- chan可以类比成一个queue加上mutex的组合,queue用于数据缓冲,mutex用于互斥访问,当队列满或者空,发送或者接收就会阻塞;
- chan只有一种运算符<-,放在chan前面就是从chan接收数据,放在chan后面就是向chan发送数据,没有->运算符;
- 语言内建函数make,close用于创建和删除chan,内建函数len和cap用于获取chan的缓冲数据数量和缓冲总容量;
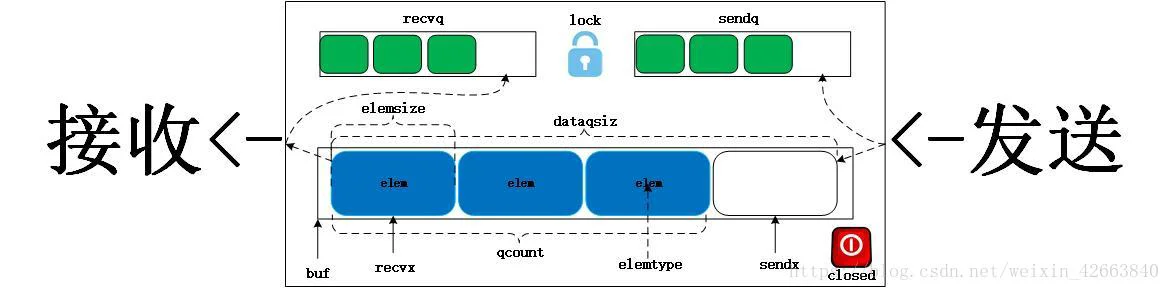
既然我们已经分析了chan,那就看看chan是如何实现的,代码位于go/src/runtime/chan.go文件中。看到代码有些人可能会懵逼,根本没有chan这个类型啊,只有hchan,定义如下:
// 代码源于go/src/runtime/chan.go
type hchan struct {
qcount uint // 队列中的元素总量
dataqsiz uint // 缓冲大小,=make(chan T, x)中的x
buf unsafe.Pointer // 缓冲区地址
elemsize uint16 // 元素大小,单位为字节
closed uint32 // chan关闭标记
elemtype *_type // 元素类型
sendx uint // 待发送元素在缓冲器中的索引
recvx uint // 待接收元素在缓冲器中的索引
recvq waitq // 接收等待队列,用于阻塞接收协程
sendq waitq // 发送等待队列,用于阻塞发送协程
lock mutex // 互斥锁
}chan是golang的内建类型,我们能够通过go文件看到的类型类似于自定义类型,好比C/C++中的int和struct,我想应该是编译器将chan和hchan关联起来了。因为我找不到go编译器代码,也没法肯定这个说法,姑且假定这个说法是对的吧。
// 代码源于go/src/runtime/chan.go
func makechan(t *chantype, size int64) *hchan {
// 这里要重点说明一下了,为了实现chan T这种模板的效果,需要用一个数据结构描述T
// go用的就是chantype这个类型,该类型由编译器实例化对象,并在创建chan时传入
// 必要是我会把chantype中的成员变量解释一下,当前我们了解一下chantype.elem成员
// chantype.elem的类型是_type,里面记录着改类型的全部属性,后面会根据引用说明
// 后面用元素代表T的对象
elem := t.elem
// 此处用到了数据类型的size,就是sizeof(T),从下面的代码可以看出如果数据类型超过
// 65536个字节会抛异常,那么在定义类型的时候尽量避免使用数组,限制类型大小
// 说来也是,如果需要传递过大的对象,也就没必要用对象了,直接用指针多好
// 这个判断编译器会判断,此处多判断一次更安全,读者可以试一下,编译器会报错哦
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 这里需要看两个定义:maxAlign = 8
//hchanSize = unsafe.Sizeof(hchan{}) + uintptr(-int(unsafe.Sizeof(hchan{}))&(maxAlign-1))
// 从上面的定义来看,hchanSize是一个宏,计算了chan对象8字节对齐后的大小
// 同时这里面也要求chan所管理的数据的对齐要求不能超过8字节,这个也要注意
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 这里做了2个判断,申请的缓冲数量不能为负数,申请缓冲内存不能超过系统最大内存
// 有个事情不明:size < 0和 int64(uintptr(size)) != size应该都是用来判断size是否负数的
// 还是说 int64(uintptr(size)) != size还有其他目的?
if size < 0 || int64(uintptr(size)) != size || (elem.size > 0 && uintptr(size) > (_MaxMem-hchanSize)/elem.size) {
panic(plainError("makechan: size out of range"))
}
var c *hchan
// 如果缓冲数据类型中没有指针或者不需要缓冲,chan对象和缓冲在内存是连着的
// 那么问题来了,为什么元素类型中没有指针就可以申请连续内存呢?
if elem.kind&kindNoPointers != 0 || size == 0 {
c = (*hchan)(mallocgc(hchanSize+uintptr(size)*elem.size, nil, true))
if size > 0 && elem.size != 0 {
c.buf = add(unsafe.Pointer(c), hchanSize) // 跳过chan对象的大小就是缓冲首地址
} else {
c.buf = unsafe.Pointer(c) // 没有缓冲那么缓冲地址就指向自己
}
// chan对象和缓冲是两个内存
} else {
c = new(hchan)
c.buf = newarray(elem, int(size))
}
// 记录元素的大小,类型以及缓冲区大小
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}上面的代码就是我们make(chan struct{}, 10)的实现,创建完chan后,我们就要看看发送数据chan是如何实现的:
// 代码源自go/src/runtime/chan.go
// 该函数官方注释是:entry point for c <- x from compiled code
// 意思是编译器会将c <- x语句转换为chansend1的调用,其中getcallerpc中的PC就是
// 学习《微机原理》里面的PC(program counter)存储器,这个过于底层且和我们理解chan
// 原理关系不大,所以不做过多说明
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc(unsafe.Pointer(&c)))
}
// 参数block是用来指定是否阻塞的,说明chan的实现是具备是否阻塞这个选项的
// 只是go语言本身没有开放这个选项而已,我甚至怀疑r := c <- x这种方式的调用编译器
// 会调用chansend函数,但是测试编译语法错误,说明go就没有开发这个选项
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 判断通道是否为空指针
if c == nil {
// 如果是非阻塞模式直接返回
if !block {
return false
}
// gopark就是阻塞当前协程的,有兴趣读者可以自行了解
// 看到了吧,如果是空指针直接阻塞,我们上面提到的这里证明了
gopark(nil, nil, "chan send (nil chan)", traceEvGoStop, 2)
throw("unreachable")
}
// 无效代码
if debugChan {
print("chansend: chan=", c, "\n")
}
// 无效代码
if raceenabled {
racereadpc(unsafe.Pointer(c), callerpc, funcPC(chansend))
}
// 第一个条件就是非阻塞模式,因为我们用的都是阻塞模式,其实继续研究没意义,但我还要分析
// 条件大概是(chan没有关闭)并且((无缓冲且没有接收者)或(有缓冲但缓冲区满了))
// 这个判断完全符合我们上面的总结
if !block && c.closed == 0 && ((c.dataqsiz == 0 && c.recvq.first == nil) || (c.dataqsiz > 0 && c.qcount == c.dataqsiz)) {
return false
}
// 无效代码
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
// 加锁了,说明下面操作的内容涉及到多协程操作
lock(&c.lock)
// 这个厉害了,向已关闭的chan发送数据会直接进程崩溃,所以一般关闭chan的是发送者
// 或者要先通知发送协程退出后在关闭chan,这一点一定要注意
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 从等待队列中取出一个接收者,此处我们部队waitq这个类型做过多介绍
// 只要知道它是个队列,用来阻塞协程就可以了,就好像我们使用std::map不关心实现一样
if sg := c.recvq.dequeue(); sg != nil {
// 如果有接收者等待数据就直接发送数据给这个接收者
// 由于我会有一篇文章专门讲相关的内容,读者如果想了解可以自行分析相关代码
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
// 走到这里说明没有接收者等待数据,那就要判断缓冲器是否有空间了
if c.qcount < c.dataqsiz {
// func chanbuf(c *hchan, i uint) unsafe.Pointer {
// return add(c.buf, uintptr(i)*uintptr(c.elemsize)
// } 这段代码应该不用过多解释了,就是从缓冲地址加上元素的偏移
qp := chanbuf(c, c.sendx)
// 无用代码
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
// 这个可以理解为内存拷贝,将需要发送的数据拷贝到队列中
// 其实这里能够解答我上面的问题,当元素中有指针,拷贝方式完全不一样
// 这里我们不讨论拷贝,我后续会专门分析这块
typedmemmove(c.elemtype, qp, ep)
// 更新索引,这个索引就是一个循环索引
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// 累加计数,这个没什么难度哈
c.qcount++
unlock(&c.lock)
return true
}
// 走到这里说明队列已经满啦,不阻塞模式则直接返回
if !block {
unlock(&c.lock)
return false
}
// 后面的代码是将发送者放入等待队列阻塞的过程,实现比较复杂,读者愿意了解
// 可以自行分析,我会有专门的文章分析这部分内容,本文的目的是让读者了解chan
// 的实现原理,使用chan更加游刃有余,我认为代码分析到这个程度是达到目的了
......
return true
}我们分析完发送数据,接着我们分析接收数据的代码:
// 代码源自go/src/runtime/chan.go
// 由于分析发送部分,接收我们就简要说明,不做详细讲解了
// 发现没有?接收函数有三个,发送只有两个,这里面chanrecv1和chanrecv2是给编译器用的
// 可以看出来多返回值的语法对于底层来说还是多个函数,语言简单无非是别人帮你做了很多事情
func chanrecv1(c *hchan, elem unsafe.Pointer) {
chanrecv(c, elem, true)
}
func chanrecv2(c *hchan, elem unsafe.Pointer) (received bool) {
_, received = chanrecv(c, elem, true)、
return
}
// 这里是接收数据的主要实现
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
// 无用代码
if debugChan {
print("chanrecv: chan=", c, "\n")
}
// 如果是空指针就阻塞
if c == nil {
if !block {
return
}
gopark(nil, nil, "chan receive (nil chan)", traceEvGoStop, 2)
throw("unreachable")
}
// 这里的判断和发送原理一样,不过多解释,那么问题来了
// 为什么这里判断c.qcount和c.closed需要用源自操作而发送不需要呢?
if !block && (c.dataqsiz == 0 && c.sendq.first == nil || c.dataqsiz > 0 && atomic.Loaduint(&c.qcount) == 0) && atomic.Load(&c.closed) == 0 {
return
}
// 无用代码
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
// 这里需要注意一下,当chan关闭同时换种没有数据才会返回false
// 也就是我们前面的总结,缓冲还有数据时即便已经关闭依然可以读取数据
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(unsafe.Pointer(c))
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
// 看看有没有阻塞的发送者
if sg := c.sendq.dequeue(); sg != nil {
// 直接从发送者那里接收数据
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
// 缓冲冲有数据
if c.qcount > 0 {
// 取出缓冲中的数据
qp := chanbuf(c, c.recvx)
// 无用代码
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
// 拷贝数据到接收者提供的内存中
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 清理缓冲中的元素,按照很多人的习惯都不做清理的,因为后续的数据自然就覆盖了
// 但是大家不要忘记了元素中如果有指针,不清理这个指针指的内存将无法释放
typedmemclr(c.elemtype, qp)
// 更新接收索引,同样也是环形的
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 计数减一
c.qcount--
unlock(&c.lock)
return true, true
}
// 非阻塞模式缓冲满就直接返回
if !block {
unlock(&c.lock)
return false, false
}
// 和发送数据一样,后面就是阻塞协程并唤醒的过程
......
return true, !closed
}最后我们在看看chan被关闭是如何实现的:
func closechan(c *hchan) {
// close空指针的chan会崩溃,请注意
if c == nil {
panic(plainError("close of nil channel"))
}
// close已经close的chan也会崩溃哦
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
// 无用代码
if raceenabled {
callerpc := getcallerpc(unsafe.Pointer(&c))
racewritepc(unsafe.Pointer(c), callerpc, funcPC(closechan))
racerelease(unsafe.Pointer(c))
}
// 设置关闭符号
c.closed = 1
var glist *g
// 唤醒所有阻塞的读取协程
for {
sg := c.recvq.dequeue()
......
}
// 唤醒所有阻塞的发送协程
for {
sg := c.sendq.dequeue()
......
}
......
}有没有人想过为什么chan的实现要传入block这个参数,全程没有看到传入这个参数的过程啊?我也一度怀疑这个问题,如果我的程序不想阻塞难道只能自己实现类似的队列,各位看看下面的代码就什么都明白了:
drained := false
for !drained {
select {
case x := <-chan:
......
default:
drained = true
}
}select语句出现default时,所有的 case都不满足条件就会执行default,此处的调用编译器就会传入block=false。还有,当我要持续的从chan读取数据的时候,代码貌似需要写成这样:
for {
item, ok := <- chan
if (!ok) {
return;
}
......
}其实go还提供了一种方式遍历chan,看下面的代码,是不是简洁了很多?只要chan被关闭了,就会推出for循环。
for item := range chan {
......
}至此,我们已经从代码层面分析了chan实现方法,妈妈以后再也不用担心我用不好chan啦~最后我们用一幅图结束话题: