
提到爬虫,总会联想到Python。似乎Python是爬虫的唯一选择。爬虫只是完成一个访问页面然后收集数据的任务,用任何语言来写都能实现。相比较Python快速实现但是庞大的体型,Golang来写爬虫似乎是更好的又一选择。
HTTP请求
Golang语言的HTTP请求库不需要使用第三方的库,标准库就内置了足够好的支持:
使用官方的HTTP包可以快速的请求页面并得到返回数据。
就像Python有Scrapy库,爬虫框架可以很大程度上简化HTTP请求、数据抽取、收集的流程,同时还能提供更多的工具来帮助我们实现更复杂的功能。
Golang爬虫框架——Goribot
zhshch2002/gospider是一个用Golang写成的爬虫轻量框架,有不错的扩展性和分布式支持能力,文档在https://wiki.xzhsh.ch/gospider/。
获取Goribot:
使用Goribot实现上文的代码的功能要看起来简洁不少。
如此之实现了一个单一的功能,即访问“https://github.com”并打印出结果。如此的应用还不足以使用框架。那我们来入手一个更复杂点的爬虫应用。
用Goribot爬取B站信息
我们来建立一个复杂点的爬虫应用,预期实现两个功能:
- 沿着链接自动发现新的视频链接
- 提取标题、封面图、作者和视频数据(播放量、投币、收藏等)
研究B站页面
Network
XHRPreview那么,交给你一个任务,依次查看XHR下的所有请求,找到最像是服务器返回的点赞、收藏、播放量数据的哪一个。
很好,那来看看你找到是这个吗?
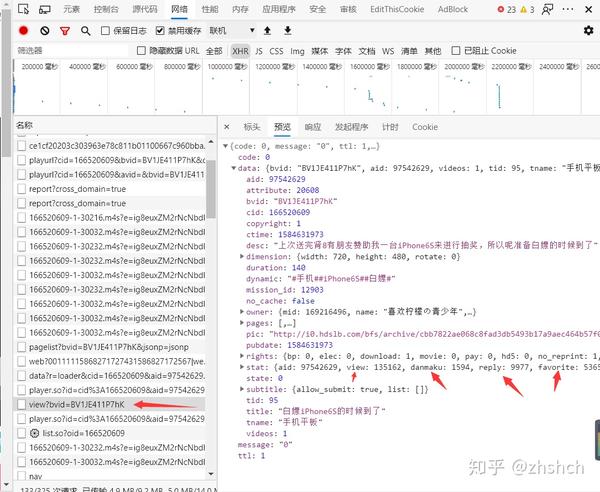
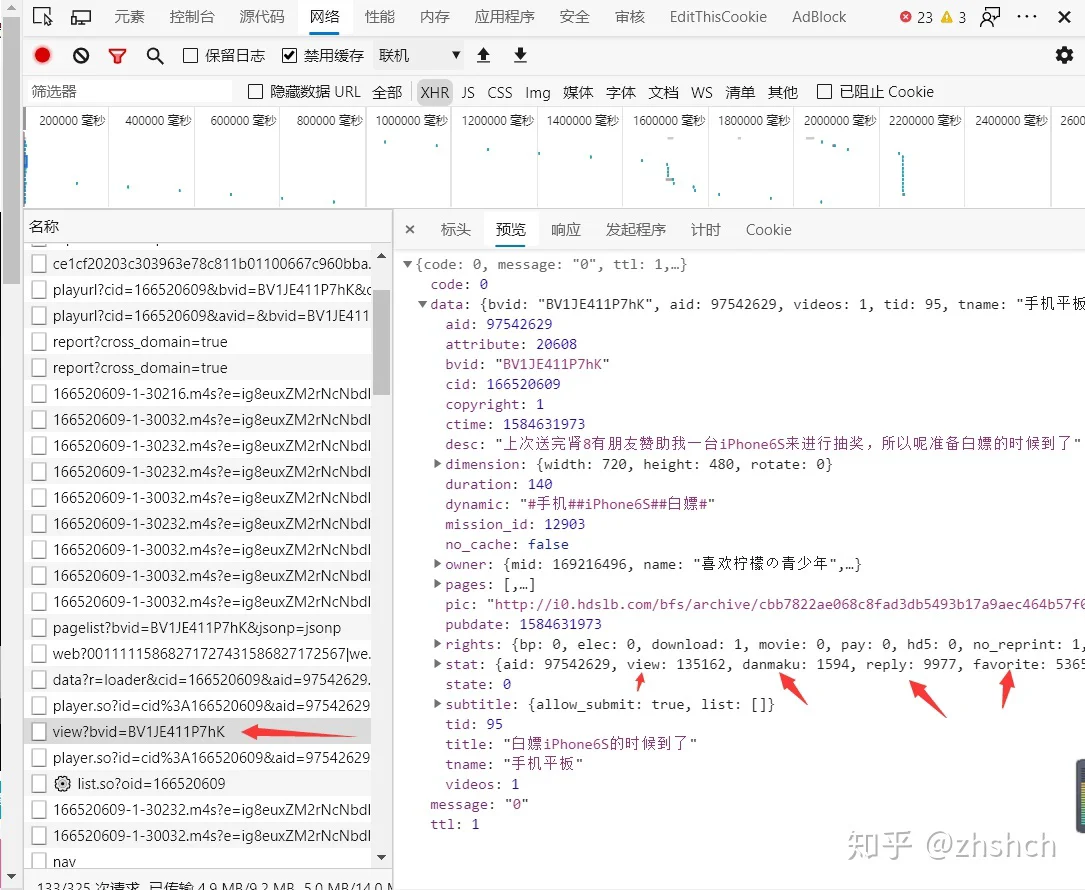
你已经成功达成了一个爬虫工程师的成就——从Ajax请求里寻找目标数据。
Header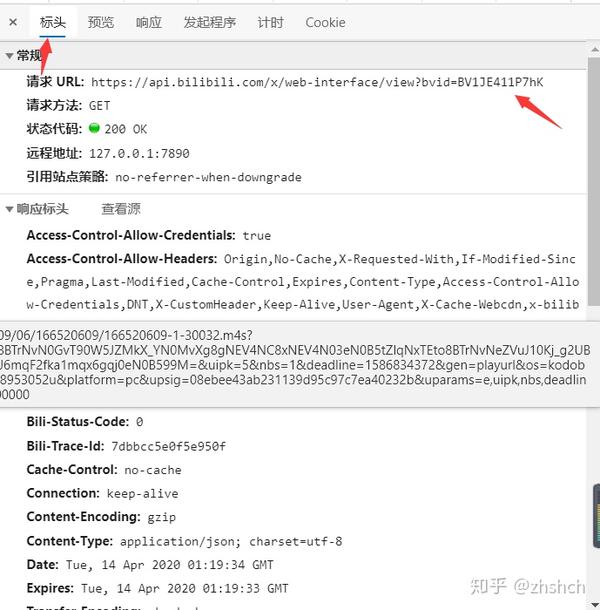
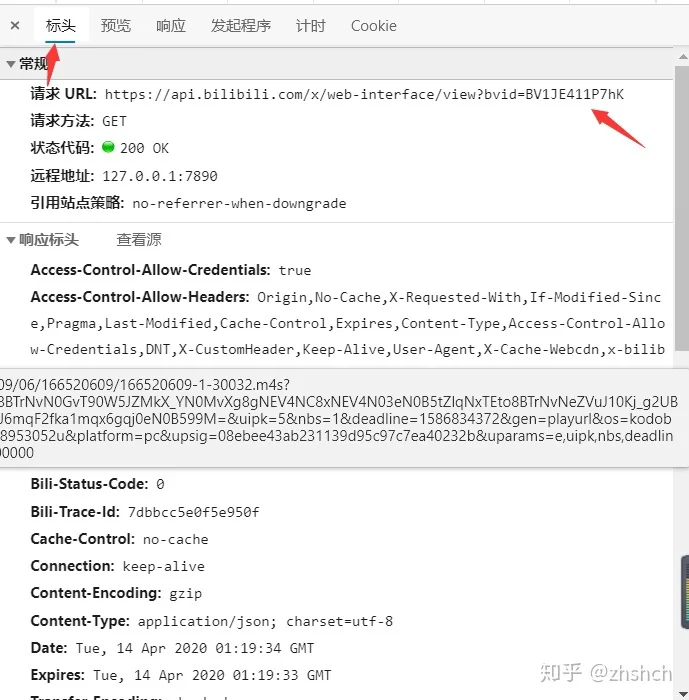
发现了视频Id——BV号。
搭建爬虫
完整代码在后文。
创建爬虫
获取视频数据
这是一个函数,自动解析响应里的Json数据,也就是刚才看的Ajax结果。解析完数据后保存到蜘蛛的Item处理队列。
发现新视频
收集Item
我们在获取视频数据里获取了Ajax数据,并保存到Item队列。我们在这里处理这些Item以避免读写文件和数据库对爬取主线程的阻塞。
OnItem最后 Run 吧
完整代码如下
最后
爬虫框架只是工具,重要的是人怎么使用它。了解工具可以看Gospider | Zhshch's Wiki。