
走了不少弯路,把问题搞复杂了。开始以为文件流就是分片下载,其实不是。
旧版的pdf.js好像不需要设置,自动就是支持分片加载的。
1 服务端golang beego
http.serverfile本身自动支持分片下载的,不用操心。
2 前端
viewer.html页面不需要修改。如果需要,则修改viewer.js和pdf.js等引用文件位置
修改一下web\viewer.js
修改引用位置,如果没问题,则不需要修改
修改引用位置,如果没问题,则不需要修改
修改build\pdf.js 中分片大小
修改引用位置,如果没有问题,则不需修改
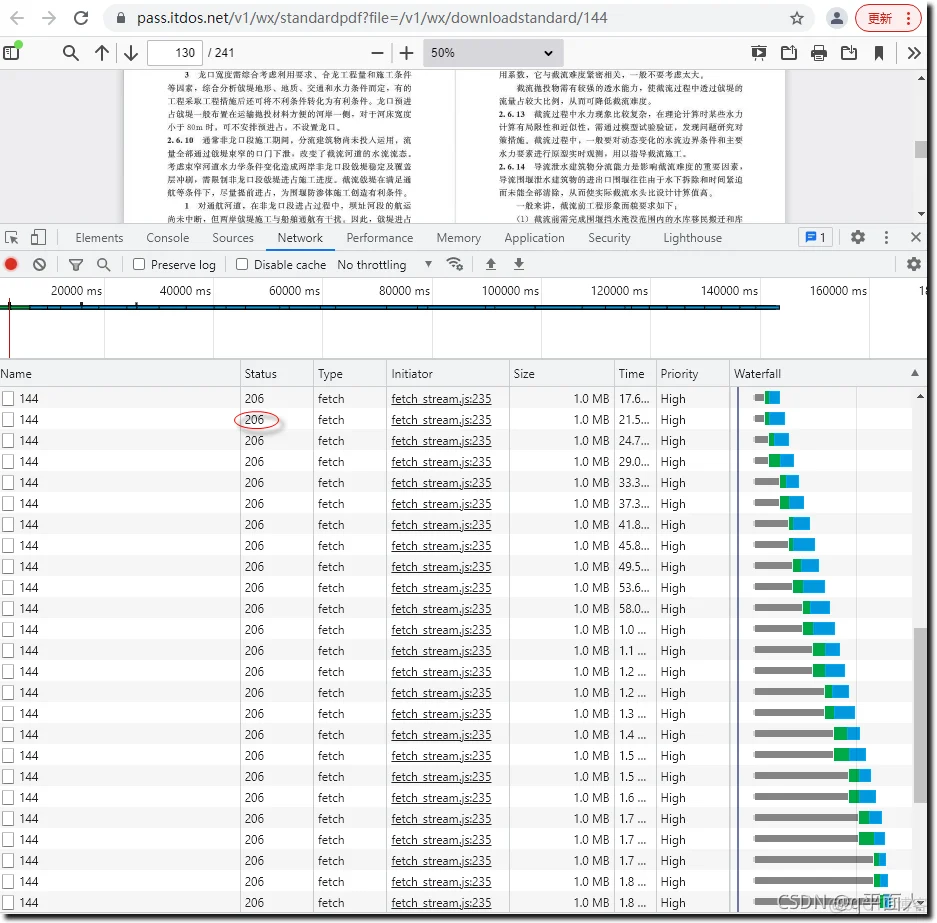
用一个40M的文件测试一下,效果如下:
相关知识:
实现过pdf.js默认一次性加载所有page,加载整个pdf - 53BK报刊网
pdf.js的一些参数:
initialData TypedArray 带有第一部分或全部pdf数据的类型化数组。由扩展使用,因为在切换到范围请求之前已经加载了一些数据。
disableRange 布尔 (可选)禁用PDF文件的范围请求加载。启用后,如果服务器支持部分内容请求,则将以块的形式提取PDF。默认值为“false”。
disableStream 布尔 (可选)禁用PDF文件数据的流式传输。默认情况下,PDF.js会尝试以块的形式加载PDF。默认值为“false”。
disableAutoFetch 布尔 (可选)禁用PDF文件数据的预取。启用范围请求后,即使不需要显示当前页面,PDF.js也会自动继续获取更多数据。默认值为“false”。注意:还必须禁用流式传输,请参阅上文,以便禁用预取功能以使其正常工作。
实现过pdf.js默认一次性加载所有page,加载整个pdf
disableRange设为 true 即可
这样可以pdf.js可以实现pdf文件页码的自动选择(不重复加载pdf文件)
pdfjs优化,实现按需加载,节省流量和内存 - 小黑电脑
3.3 pdfjs关闭自动获取
在pdfjs发行包的web/viewer.js文件中,找到配置项disableAutoFetch,可以看到它的默认值是false,意味着会自动获取所有分片。
将它改为true,意味着关闭自动获取,它仅仅会下载所需要的分片,实现了按需加载。