
- 第一章:
Gin 是如何储存和映射URL 路径到相应的处理函数的 - 第二章:
Gin 中间件的设计思想及其实现 - 第三章:
Gin 是如何解析客户端发送请求中的参数的 - 第四章:
Gin 是如何将各类格式(JSON/XML/YAML 等)数据解析
Gin Github官方地址
Gin是如何组织和映射URL到处理函数的
在谈这个之前我们先以官方给的示例代码来作为我们的切入口,然后一步一步的看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | func main() { router := gin.Default() // 这个处理函数将会匹配 /user/john 但不会匹配 /user/ 或者 /user router.GET("/user/:name", func(c *gin.Context) { name := c.Param("name") c.String(http.StatusOK, "Hello %s", name) }) // 这个路径将会匹配 /user/john/ 或者 /user/john/send // 如果没有匹配到 /user/john, 那么将会被重定向到 /user/john/ router.GET("/user/:name/*action", func(c *gin.Context) { name := c.Param("name") action := c.Param("action") message := name + " is " + action c.String(http.StatusOK, message) }) router.POST("/user/:name/*action", func(c *gin.Context) { log.Println(c.FullPath() == "/user/:name/*action") // true }) router.Run(":8080") } |
首先,我们要通过
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | type Engine struct { //中间件信息就存储在这个里面 RouterGroup //是否启动自动重定向。例如:配置Handler时是/foo, //但实际发送的请求是/foo/。在启用本选项后,将会重定向到/foo RedirectTrailingSlash bool // 是否启动请求路由修复功能。 // 启用过后,当/../foo找不到匹配路由时,会自动删除..部分路由,然后重新匹配知道找到匹配路由,如上路由就会被匹配到/foo RedirectFixedPath bool //启用后,如果找不到当前路由匹配的方法,则返回405响应码。 // 如果启用路由修复仍然找不到匹配的路由再返回404 HandleMethodNotAllowed bool //是否获取真正的客户端IP,而不是代理服务器IP(nginx等), // 开启后将会从"X-Real-IP和X-Forwarded-For"中解析得到客户端IP ForwardedByClientIP bool //启用后将在头部加入"X-AppEngine"标识,以便与PaaS集成 AppEngine bool //启用后,将使用原有的URL.rawPath(没有对转义字符进行处理的, // 如%/+等)地址来进行解析,而不是使用URL.path来解析,默认为false UseRawPath bool //如果启用,则路径中的转义字符将不会被转义 UnescapePathValues bool //设置用来缓存客户端发送的文件的缓冲区大小,默认:32MB MaxMultipartMemory int64 //启用后将会删除多余的分隔符"/" RemoveExtraSlash bool //用于保存tmpl文件中用于引用变量的定界符,默认是"{{}}", // 调用r.Delims("{[{", "}]}")可以修改 delims render.Delims //设置防止JSON劫持,在json字符串前加的逻辑代码, //默认是:"while(1);" secureJsonPrefix string //html文件解析器 HTMLRender render.HTMLRender //tmpl文件的内建函数列表,可以在tmpl文件中调用函数,使用 //router.SetFuncMap(template.FuncMap{ // "formatAsDate": formatAsDate, //})可设置 FuncMap template.FuncMap // HandlersChain就是func(*Context)数组 // 以下四个调用链中保存的就是在不同情况下回调的处理函数 // 找不到匹配路由(404) allNoRoute HandlersChain //返回405状态时会回调 allNoMethod HandlersChain //没有配置路由时回调,主要是代码测试时候使用的 noRoute HandlersChain //没有配置映射方法时回调,主要是代码测试时候使用的 noMethod HandlersChain //连接池用于保存与客户端的连接上下文(Context) pool sync.Pool //路径搜索树,代码中配置的路由信息都以树节点的形式组织起来 // 下面会详细介绍 trees methodTrees } |
在大致了解完
RouterGroup
1 2 3 4 5 6 7 | type RouterGroup struct { Handlers HandlersChain basePath string //注意这里存在交叉依赖 engine *Engine root bool } |
光看这个
1 2 3 4 | func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes { group.Handlers = append(group.Handlers, middleware...) return group.returnObj() } |
从这里函数一看,咦?这不就是绑定中间件方法吗?从这里我们就可以看出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | type IRoutes interface { Use(...HandlerFunc) IRoutes Handle(string, string, ...HandlerFunc) IRoutes Any(string, ...HandlerFunc) IRoutes GET(string, ...HandlerFunc) IRoutes POST(string, ...HandlerFunc) IRoutes DELETE(string, ...HandlerFunc) IRoutes PATCH(string, ...HandlerFunc) IRoutes PUT(string, ...HandlerFunc) IRoutes OPTIONS(string, ...HandlerFunc) IRoutes HEAD(string, ...HandlerFunc) IRoutes StaticFile(string, string) IRoutes Static(string, string) IRoutes StaticFS(string, http.FileSystem) IRoutes } |
看到这里是不是很眼熟,对了,这就是官方示例中绑定路由信息的函数。例如:
1 2 3 4 | router.GET("/user/:name", func(c *gin.Context) { name := c.Param("name") c.String(http.StatusOK, "Hello %s", name) }) |
那么我们接下来就选择
首先我们来看一下
1 2 3 4 5 6 7 | func (group *RouterGroup) POST(relativePath string, handlers ...HandlerFunc) IRoutes { return group.handle(http.MethodPost, relativePath, handlers) } func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes { return group.handle(http.MethodGet, relativePath, handlers) } |
这里简单对比一下
1 2 3 4 5 6 7 8 9 10 11 | func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes { //计算最简洁的相对路径,去除多余符号 absolutePath := group.calculateAbsolutePath(relativePath) //合并处理函数,就是讲我们自己编写的处理函数与中间件函数连接成一个处理链, //这样在路由匹配时不仅会调用我们编写的函数,也会调用中间件函数 handlers = group.combineHandlers(handlers) //像向engine对象添加路由信息 group.engine.addRoute(httpMethod, absolutePath, handlers) return group.returnObj() } |
从上面我们可以看出,路由信息经过一系列的处理,最终还是通过
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | func (engine *Engine) addRoute(method, path string, handlers HandlersChain) { //此处省略参数校验 //打印配置的路由信息 debugPrintRoute(method, path, handlers) //获取对应方法的根树,engine为每个HTTP方法(GET/POST/DELET...)都生成了一个根树 root := engine.trees.get(method) //如果根树为空,则说明还未给该HTTP方法生成过搜索树 if root == nil { root = new(node) root.fullPath = "/" engine.trees = append(engine.trees, methodTree{method: method, root: root}) } //获取到根树之后再调用真正的储存函数 root.addRoute(path, handlers) } |
在了解真正的储存函数之前,我们需要先看一下
路由根树
首先我们就从获取根树的函数开始。
1 | root := engine.trees.get(method) |
从这里我们可以看到根树,是从
1 2 3 4 5 6 7 8 | type methodTrees []methodTree type methodTree struct { // HTTP方法名 method string //真正的根节点指针 root *node } |
而树节点的数据结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | type node struct { //当前节点所达路径 path string //用于记录子节点的与当前节点的最长公共前缀的后一个字符 //例如:当前节点为/(根节点),有两个子节点,全路径分别为: // /user、/form_table //那么当前节点的indices就是"uf",用于快速索引到子节点的 // 如果当前节点 indices string //子节点指针数组 children []*node //当前节点的处理链 handlers HandlersChain //匹配优先级,一般按照最长路径匹配原则设置 priority uint32 //节点类型 nType nodeType //当前节点与子节点中所有参数的个数 // 参数指的是REST参数,而不是GET/POST中提交的参数 maxParams uint8 //子节点是否为通配符节点 wildChild bool //达到当前节点的完整路径 fullPath string } type nodeType uint8 const ( //静态路由信息节点,默认值 static nodeType = iota //根节点 root //参数节点 param //表示当前节点已经包含所有的REST参数了 catchAll ) |
真正的存储函数解读如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 | func (n *node) addRoute(path string, handlers HandlersChain) { //记录完整的路径 fullPath := path //随着匹配路径的增长优先级逐渐增大 n.priority++ //计算当前传入路径中有多少参数 numParams := countParams(path) //如果当前节点为空,则生成一个新的根节点,并以此更新当前空节点 // Empty tree if len(n.path) == 0 && len(n.children) == 0 { n.insertChild(numParams, path, fullPath, handlers) n.nType = root return } //初始化父节点的路径长度 // 主要是看传入的路径和当前节点是否有公共前缀 parentFullPathIndex := 0 walk: for { //如果当前路径中的参数个数大于父节点中记录的参数数目则更新为大值 // 因为父节点记录的是自己和子节点中所有参数的最大个数 if numParams > n.maxParams { n.maxParams = numParams } //寻找公共前缀的下标索引 i := longestCommonPrefix(path, n.path) //如果当前节点的路径长度大于公共前缀的下标索引 // 则说明当前节点路径和新加入的路径不存在包含关系 // (/user、/user/:name这样就有包含关系) // 需要分裂成两个子节点,例如: // /user /form_table // 最初当前节点路径为/user,传入的新路径为/form_table // 则可计算得公共前缀的下标索引为1 // 则当前节点的路径更新为"/" // 并分裂成两个子节点,路径分别为"user"、"form_table" // 这第一步就是将当前节点分裂成一个子节点 if i < len(n.path) { child := node{ path: n.path[i:], wildChild: n.wildChild, indices: n.indices, children: n.children, handlers: n.handlers, //由于分裂并不会增长匹配路径所以优先级不会增加 //这里减一主要是在这个函数的开始部分默认就会+1 //所以需要减掉 priority: n.priority - 1, fullPath: n.fullPath, } //更新当前节点的最大参数值 for _, v := range child.children { if v.maxParams > child.maxParams { child.maxParams = v.maxParams } } n.children = []*node{&child} //这里就更新成了公共前缀的后一个字符了 n.indices = string([]byte{n.path[i]}) n.path = path[:i] n.handlers = nil n.wildChild = false n.fullPath = fullPath[:parentFullPathIndex+i] } //这一步就是分裂成两个子节点中的第二步 //将新加入的路径生成相应子节点,加入刚才被分裂的父节点当中去 if i < len(path) { path = path[i:] //判断当前节点是否是通配符节点,如:*name、:name if n.wildChild { parentFullPathIndex += len(n.path) n = n.children[0] n.priority++ // Update maxParams of the child node if numParams > n.maxParams { n.maxParams = numParams } numParams-- // 检查当前路径是否还未遍历完 if len(path) >= len(n.path) && n.path == path[:len(n.path)] { //如果发现还有子路可以遍历则递归 if len(n.path) >= len(path) || path[len(n.path)] == '/' { continue walk } } pathSeg := path if n.nType != catchAll { pathSeg = strings.SplitN(path, "/", 2)[0] } prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path panic("'" + pathSeg + "' in new path '" + fullPath + "' conflicts with existing wildcard '" + n.path + "' in existing prefix '" + prefix + "'") } c := path[0] //如果当前节点是参数节点,且有一个子节点则递归遍历 if n.nType == param && c == '/' && len(n.children) == 1 { parentFullPathIndex += len(n.path) n = n.children[0] n.priority++ continue walk } //这个是查看有没有现存的子节点与传入路径相匹配, // 有则进入该子节点进行递归 for i, max := 0, len(n.indices); i < max; i++ { if c == n.indices[i] { parentFullPathIndex += len(n.path) i = n.incrementChildPrio(i) n = n.children[i] continue walk } } //如果传入路径非":"、"*"开头则说明是普通静态节点 // 直接构造后插入,并添加子节点索引 if c != ':' && c != '*' { n.indices += string([]byte{c}) child := &node{ maxParams: numParams, fullPath: fullPath, } n.children = append(n.children, child) n.incrementChildPrio(len(n.indices) - 1) n = child } n.insertChild(numParams, path, fullPath, handlers) return } //如果当前节点已经有处理函数,则说明之前已经有注册过这个路由了,发出警告,并更新处理函数 if n.handlers != nil { panic("handlers are already registered for path '" + fullPath + "'") } n.handlers = handlers return } } |
在了解完树节点的数据结构和构造过程之后,我们以下面这段代码为例看看在根树生成后的大致结构是什么样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | func main() { router := gin.Default() router.GET("/user/:name", func(c *gin.Context) { name := c.Param("name") c.String(http.StatusOK, "Hello %s", name) }) router.GET("/user/:name/*action", func(c *gin.Context) { name := c.Param("name") action := c.Param("action") message := name + " is " + action+"," c.String(http.StatusOK, message) }) if err := router.Run();err != nil { log.Println("something error"); } } |
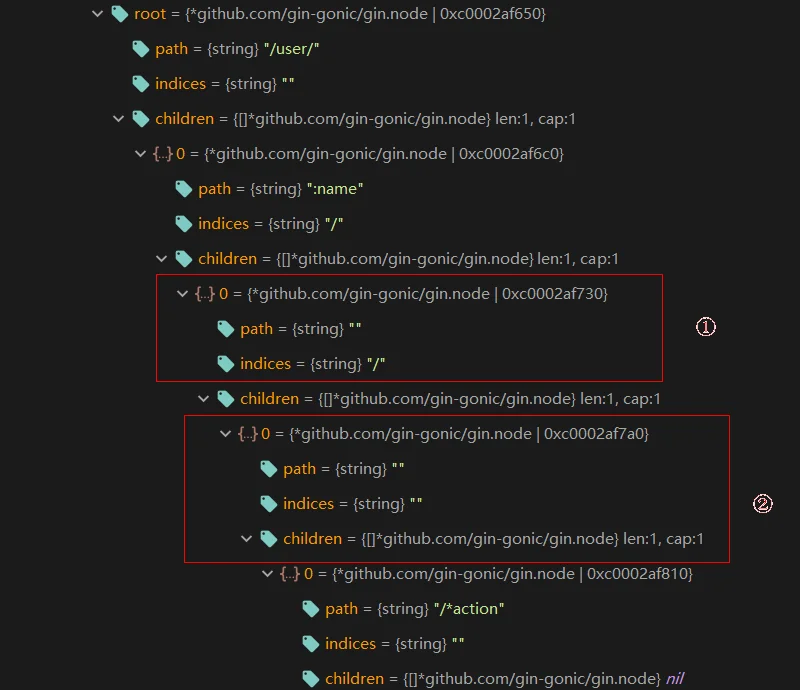
这里需要说明的是
: 通配符表示当前参数必须存在,而* 表示该参数可有可无。当indices 为空时,则表示当前节点只有一个子节点,且wildchild 为true,此时是用不上indices 的,直接取索引0.
我们先看红框①这个节点匹配的是
1 2 3 4 | router.GET("/user/:name", func(c *gin.Context) { name := c.Param("name") c.String(http.StatusOK, "Hello %s", name) }) |
而红框②这个节点匹配的是
发现的问题
在研读Gin的接受代码时,我发现如下一种现象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | func main() { router := gin.Default() router.GET("/user/:name/*action", func(c *gin.Context) { log.Println("/user/:name/*action"); }) router.GET("/user/:name/*action/other", func(c *gin.Context) { log.Println("/user/:name/*action/other"); }) if err := router.Run();err != nil { log.Println("something error"); } } |
在运行上述代码之后,你会发现无论你是发送
1 2 3 | router.GET("/user/:name/*action/other", func(c *gin.Context) { log.Println("/user/:name/*action/other"); }) |
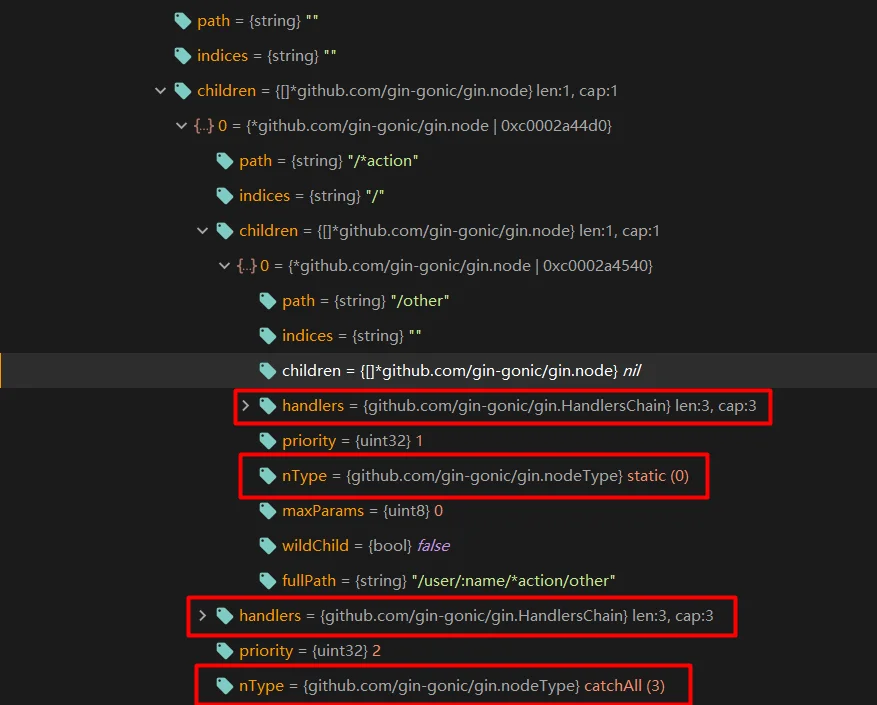
通过
虽然