
博客原文
导言
io.Copy()/io.CopyN()/io.CopyBuffer()/io.ReaderFromsendfilesplicesplicespliceiosplice因本人才疏学浅,故行文之间恐有纰漏,望诸君海涵,不吝赐教,若能予以斧正,则感激不尽。
splice
mmapsendfileMSG_ZEROCOPYsplicesplice()fd_in 和 fd_out 也是分别代表了输入端和输出端的文件描述符,这两个文件描述符必须有一个是指向管道设备的,这算是一个不太友好的限制。
off_in 和 off_out 则分别是 fd_in 和 fd_out 的偏移量指针,指示内核从哪里读取和写入数据,len 则指示了此次调用希望传输的字节数,最后的 flags 是系统调用的标记选项位掩码,用来设置系统调用的行为属性的,由以下 0 个或者多个值通过『或』操作组合而成:
splice()splice()splice()splice()splice()splice()splice()splice()数据传输过程图:
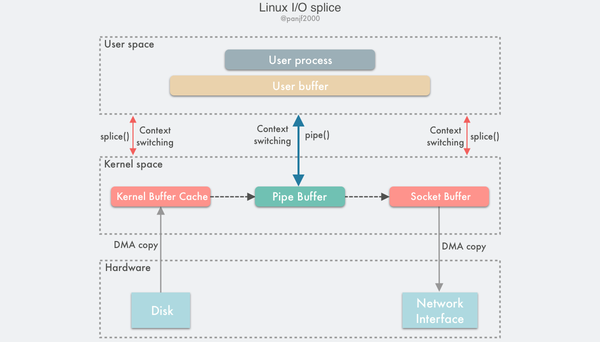
splice()pipe()pipe()splice()splice()splice()splice()splicepipe pool for splice
pipe pool in HAProxy
splicepipepipesplicesplicesplicepipesplicepipesplicepipesplicepipe对于这问题的解决方案,自然而然就会想到 -- 『复用』,比如大名鼎鼎的 HAProxy。
HAProxy 是一个使用 C 语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于 TCP 和 HTTP 的应用程序代理。它非常适用于那些有着极高网络流量的 Web 站点。GitHub、Bitbucket、Stack Overflow、Reddit、Tumblr、Twitter 和 Tuenti 在内的知名网站,及亚马逊网络服务系统都在使用 HAProxy。
splicesplice首先我们来自己思考一下,一个最简单的 pipe pool 应该如何实现,最直接且简单的实现无疑就是:一个单链表+一个互斥锁。链表和数组是用来实现 pool 的最简单的数据结构,数组因为数据在内存分配上的连续性,能够更好地利用 CPU 高速缓存加速访问,但是首先,对于运行在某个 CPU 上的线程来说,一次只需要取一个 pipe buffer 使用,所以高速缓存在这里的作用并不十分明显;其次,数组不仅是连续而且是固定大小的内存区,需要预先分配好固定大小的内存,而且还要动态伸缩这个内存区,期间需要对数据进行搬迁等操作,增加额外的管理成本。链表则是更加适合的选择,因为作为 pool 来说其中所有的资源都是等价的,并不需要随机访问去获取其中某个特定的资源,而且链表天然是动态伸缩的,随取随弃。
mmapshmat即便是基于 futex 的互斥锁,如果是一个全局的锁,这种最简单的 pool + mutex 实现在竞争激烈的场景下会有可预见的性能瓶颈,因此需要进一步的优化,优化手段无非两个:降低锁的粒度或者减少抢(全局)锁的频次。因为 pipe pool 中的资源本来就是全局共享的,也就是无法对锁的粒度进行降级,因此只能是尽量减少多线程抢锁的频次,而这种优化常用方案就是在全局资源池之外引入本地资源池,对多线程访问资源的操作进行错开。
至于锁本身的优化,由于 mutex 是一种休眠等待锁,即便是基于 futex 优化之后在锁竞争时依然需要涉及内核态开销,此时可以考虑使用自旋锁(Spin Lock),也即是用户态的锁,共享资源对象存在用户进程的内存中,避免在锁竞争的时候陷入到内核态等待,自旋锁比较适合临界区极小的场景,而 pipe pool 的临界区里只是对链表的增删操作,非常匹配。
HAProxy 实现的 pipe pool 就是依据上述的思路进行设计的,将单一的全局资源池拆分成全局资源池+本地资源池。
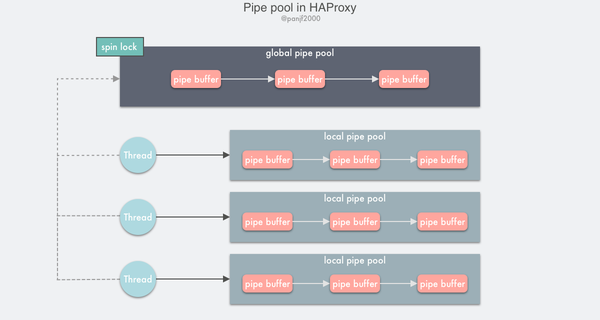
TLSTLSobjexe.text.data.bssTLSTLS.tdata.tboss.data.bssTLSTLSTLSTLSTLSHAProxy 的 pipe pool 实现原理:
thread_localTLSTLSTLSTLSHAProxy 的 pipe pool 实现虽然只有短短的 100 多行代码,但是其中蕴含的设计思想却包含了许多非常经典的多线程优化思路,值得细读。
pipe pool in Go
iospliceTLSTLSsync.Poolruntime.SetFinalizersync.PoolTLSsync.Poolsync.Poolsync.Poolsync.Poolsync.Poolsync.Poolsync.Poolsync.Pool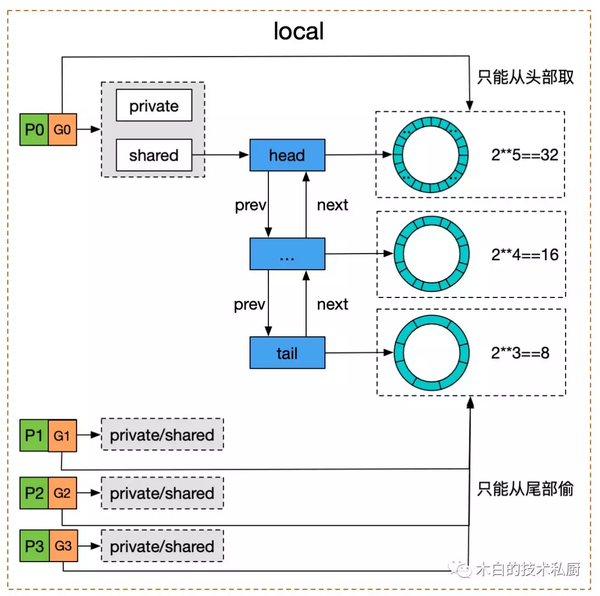
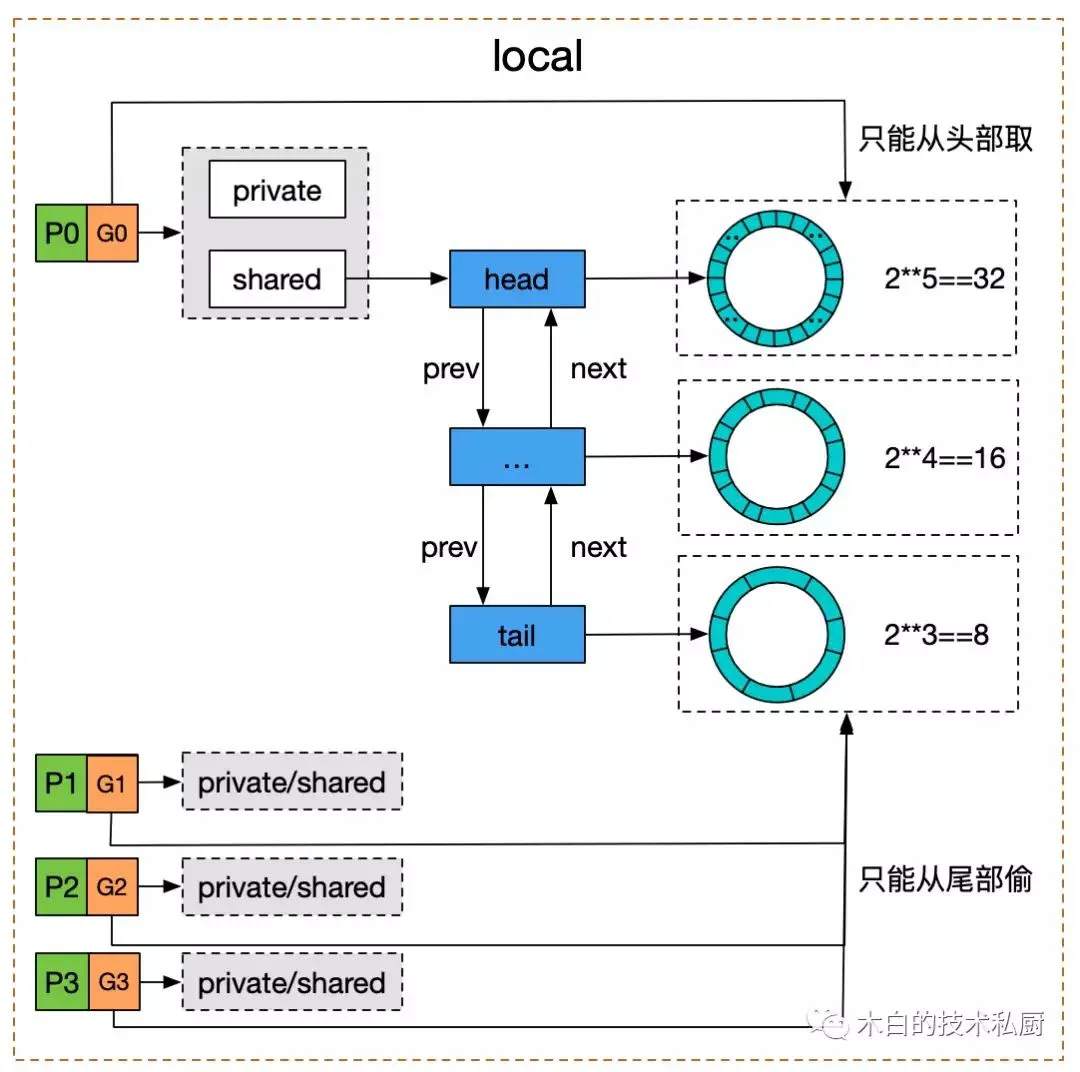
sync.PoolprivatesharedsharedsharedNewprivatesharedsharedsync.Mutexsync.Poolsync.PoolTLSTLSsync.Poolsync.Poolsync.Poolruntime.SetFinalizersync.Poolsync.Poolruntime.SetFinalizersplice基于 pipe pool 复用和直接创建&销毁 pipe buffers 相比,耗时下降在 99% 以上,内存使用则是下降了 100%。
iosplice这个特性最快应该会在今年下半年的 Go 1.17 版本发布,到时就可以享受到 pipe pool 带来的性能提升了。
小结
通过给 Go 语言实现一个 pipe pool,期间涉及了多种并发、同步的优化思路,我们再来归纳总结一下。
- 资源复用,提升并发编程性能最有效的手段一定是资源复用,也是最立竿见影的优化手段。
- 数据结构的选取,数组支持 O(1) 随机访问并且能更好地利用 CPU cache,但是这些优势在 pool 的场景下并不明显,因为 pool 中的资源具有等价性和单个存取(非批量)操作,数组需要预先分配固定内存并且伸缩的时候会有额外的内存管理负担,链表随取随弃,天然支持动态伸缩。
- 全局锁的优化,两种思路,一种是根据资源的特性尝试对锁的粒度进行降级,一种是通过引入本地缓存,尝试错开多线程对资源的访问,减少竞争全局锁的频次;还有就是根据实际场景适当地选择用户态锁。
- 利用语言的 runtime,像 Go、Java 这类自带一个庞大的 GC 的编程语言,在性能上一般不是 C/C++/Rust 这种无 GC 语言的对手,但是凡事有利有弊,自带 runtime 的语言也具备独特的优势,比如 HAProxy 的 pipe pool 是 C 实现的,在进程的生命周期中创建的 pipe buffers 会一直存在占用资源(除非主动关闭,但是很难准确把控时机),而 Go 实现的 pipe pool 则可以利用自身的 runtime 进行定期的清理工作,进一步减少资源占用。
参考&延伸
我是潘少,人生这么长,做个有趣的人,写点有趣的文字。
欢迎关注我的个人公众号 - 远赴星辰,分享深度的计算机技术和非常好玩的故事。