
代码分享论坛https://lim.app
前言
三月份的时候,接触了一下可转债打新,中了三次。感觉操作简便,收益率可观,于是便想着搞一个自动化打新工具。但是苦于没有合适的API接口,自己还需要上课,想着手动申购一下也不麻烦。五月份可转债数量很少,自己漏掉几个,很难受,于是决定逆向一下同花顺app,搞一个自动化申购的接口出来,于是便有了这篇文章。目前只有自动化申购的接口,卖出,撤单等各类股票交易接口暂时未完成,别问,问就是敏捷开发。测试了几天,都没有什么问题。这个话题不知道能不能聊,先发出来试试。/狗头
用到的工具
JEB、GDA、xposed、frida、fiddler、wireshark、DDMS、pycharm、雷电模拟器、同花顺appV10.02.12
寻找核心dex
通过直接解包逆向app,发现其dex并不是核心dex,而是类似于一个加载器,利用so接口获取odex并完成加载。 通过启动时发送的MonitorInfoReceive数据包,可以发现软件odex以及dex在本地目录有保存。
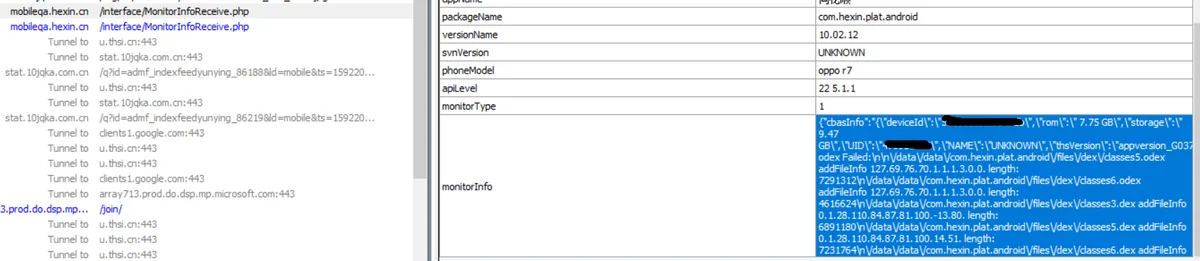 在相应目录下果然找到了相关文件:
在相应目录下果然找到了相关文件:
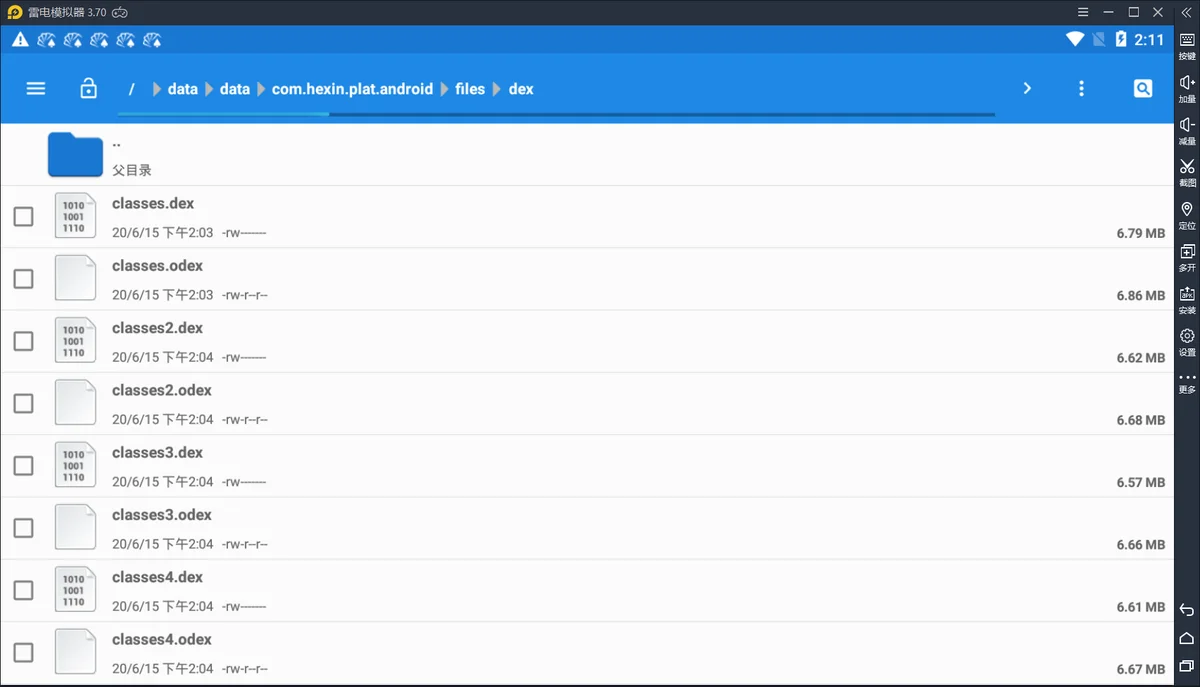 将文件复制到电脑后,发现dex文件异常,而odex正常,直接将odex中dex.035(dex文件的开头标识符)字符前面的字段删除,得到dex文件,正常打开。此处我没有深入研究app加载的流程以及dex文件显示异常的原因,对比太麻烦了==实际工作中,大部分情况下这样拿到dex文件已经够用了,但是部分函数反编译的时候会有问题,对比采用frida hook拿到的dex文件不存在问题。因此最后采用的是通过frida拿到的dex文件。
该app一共有7个dex,分开研究肯定很麻烦,这么多dex在混淆的情况下需要合并分析才行。这儿安利JEB,对multidex支持很好,希望GDA也能够增加这个功能。但是JEB对各种跳转显示的不好,各种goto,翻译一部分代码的时候,N多goto差点儿让我猝死。
至此,已经拿到了核心dex,并且通过JEB能够合并分析。
将文件复制到电脑后,发现dex文件异常,而odex正常,直接将odex中dex.035(dex文件的开头标识符)字符前面的字段删除,得到dex文件,正常打开。此处我没有深入研究app加载的流程以及dex文件显示异常的原因,对比太麻烦了==实际工作中,大部分情况下这样拿到dex文件已经够用了,但是部分函数反编译的时候会有问题,对比采用frida hook拿到的dex文件不存在问题。因此最后采用的是通过frida拿到的dex文件。
该app一共有7个dex,分开研究肯定很麻烦,这么多dex在混淆的情况下需要合并分析才行。这儿安利JEB,对multidex支持很好,希望GDA也能够增加这个功能。但是JEB对各种跳转显示的不好,各种goto,翻译一部分代码的时候,N多goto差点儿让我猝死。
至此,已经拿到了核心dex,并且通过JEB能够合并分析。
寻找日志函数
我逆向分析的时候喜欢先搞定日志函数,然后通过hook日志函数来寻找突破点。在这个案例中,直接看JEB字符串部分,找到疑似日志的部分,跳转过去,定位就行。这部分没什么可谈的,日志部分是最简单的。最后定位于frr类以及frq类,采用frida进行hook。
var frr = Java.use('frr');
frr.a.overload('java.lang.String', 'java.lang.String').implementation = function (arg1, arg2) {
send(arg1 + " : " + arg2);
};
frr.b.implementation = function (arg1, arg2) {
send(arg1 + " bbb: " + arg2);
};
frr.c.implementation = function (arg1, arg2) {
send(arg1 + " : " + arg2);
};
frr.d.implementation = function (arg1, arg2) {
send(arg1 + " : " + arg2);
};
frr.e.implementation = function (arg1, arg2) {
send(arg1 + " : " + arg2);
};
var frq = Java.use('frq');
frq.a.overload('java.lang.String', 'java.lang.String').implementation = function (arg1, arg2) {
this.a(arg1, arg2);
send(arg1 + " : " + arg2);
};
frq.a.overload('java.lang.String', 'java.lang.String', 'boolean').implementation = function (arg1, arg2, arg3) {
this.a(arg1, arg2, arg3);
send(arg1 + " : " + arg2);
};
frq.b.overload('java.lang.String', 'java.lang.String').implementation = function (arg1, arg2) {
this.b(arg1, arg2);
send(arg1 + " : " + arg2);
};
frq.c.overload('java.lang.String', 'java.lang.String').implementation = function (arg1, arg2) {
this.c(arg1, arg2);
send(arg1 + " : " + arg2);
};
frq.d.overload('java.lang.String', 'java.lang.String').implementation = function (arg1, arg2) {
this.d(arg1, arg2);
send(arg1 + " : " + arg2);
};
frq.e.overload('java.lang.String', 'java.lang.String').implementation = function (arg1, arg2) {
this.e(arg1, arg2);
send(arg1 + " : " + arg2);
};
通过日志没有看到多少有用的东西,但是可以了解到同花顺app采用TCP通信,并且可以拿到IP地址和服务器端口,方便下一步的抓包。
连接认证
通常我分析app会fiddler和wireshark全部开启,方便抓包分析。
同花顺app整体协议采用TCP通信协议,很多不重要的数据包并没有加密,直接采用的明文方式。这个给出了可乘之机。
首次启动app会发送一条注册设备的数据包,服务器返回passport.dat数据包作为日后连接登录的凭证。以后的连接数据包全部采用passport.dat。
 值得一提的是,此处发送的时候,采用的宽字符。python实现部分:
值得一提的是,此处发送的时候,采用的宽字符。python实现部分:
str_info = 'ScreenWidth=720'
str_info += '\r\nScreenHeight=1280'
str_info += '\r\nsmallestWidth=0dp'
str_info += '\r\ndensity=1.0'
str_info += '\r\nrealdata=true'
str_info += '\r\ntime2012=1'
str_info += '\r\nAppletVersion=' + constants.APPLET_VERSION
str_info += '\r\nsvnver=' + constants.SVN_VER
str_info += '\r\nTestVersion=' + constants.TEST_VERSION
str_info += '\r\nBranchName=' + constants.BRANCH_NAME
str_info += '\r\nFunClientSupport=0111111111100011111111'
str_info += '\r\napp=android'
str_info += '\r\nfor=ths_am_gphone_login'
str_info += '\r\nprogid=500'
str_info += '\r\nnet=1'
str_info += '\r\nqsid=800'
str_info += '\r\nsourceid=' + constants.SOURCE_ID
str_info += '\r\nspcode=' + constants.SP_CODE
str_info += '\r\nchannelid=' + constants.SOURCE_ID
str_info += '\r\ntype=' + constants.TYPE
str_info += '\r\nudid=' + constants.UDID
str_info += '\r\nimei=' + constants.IMEI
str_info += '\r\nsim=' + constants.UDID
str_info += '\r\nimsi=' + constants.IMSI
str_info += '\r\nmacA=' + constants.MAC
str_info += '\r\nsdk=22'
str_info += '\r\nsdkn=5.1.1'
str_info += '\r\nCA=4'
str_info += '\r\ndev=' + constants.DEV
str_info += '\r\n'
data = b''
for i in range(len(str_info)):
data += int.to_bytes(ord(str_info[i]), 2, byteorder='little', signed=False)
data = int.to_bytes(len(str_info), 2, byteorder='little', signed=False) + data
# data长度不够8的倍数则用00补齐
data += b"\x00\x00\x00\x00\x00\x00\x00"
data = data[0:int(len(data) / 8) * 8]
数据包组包完毕,直接在前面加上头部分就行,后续统一讲头部分。
手机号绑定(验证码发送及验证)
其实这部分没有什么好讲的,都是明文,只有一个RSA加密,直接搜索字符串,找到RSA的公钥就ok,单纯的体力活。直接给出这两部分的python实现部分:
# 获取验证码
reqpage = str(random.randint(10000, 99999))
enc_account = base64.b64encode(rsa_utils.rsa_encrypt(account.encode('utf-8')))
enc_account = parse.quote(enc_account)
url = 'verify?reqtype=wlh_thsreg_modify&mobile_login=1&qsid=800®flag&udid=' + constants.UDID + '&encoding=GBK&mobile=' + enc_account + '&rsa_version=default_4&foreign=1&foreign_country=86'
str_info = '[frame]'
str_info += '\r\nid=4222'
str_info += '\r\npageList=' + reqpage
str_info += '\r\nreqPage=' + reqpage
str_info += '\r\nreqPageCount=1'
str_info += '\r\n[' + reqpage + ']'
str_info += '\r\nid=1101'
str_info += '\r\nhost=auth'
str_info += '\r\nurl=' + url
str_info += '\r\n'
# 验证验证码,采用密码登录也是一样的,不过几个参数变化
reqpage = str(random.randint(10000, 99999))
enc_account = base64.b64encode(rsa_utils.rsa_encrypt(account.encode('utf-8')))
enc_account = str(enc_account, 'utf-8')
enc_password = base64.b64encode(rsa_utils.rsa_encrypt(password.encode('utf-8')))
enc_password = str(enc_password, 'utf-8')
str_info = '[frame]'
str_info += '\r\nid=2054'
str_info += '\r\npageList=' + reqpage
str_info += '\r\nreqPage=' + reqpage
str_info += '\r\nreqPageCount=1'
str_info += '\r\n[' + reqpage + ']'
str_info += '\r\nid=1001'
str_info += '\r\ncrypt=2'
str_info += '\r\nctrlcount=2'
str_info += '\r\nctrlid_0=34338'
str_info += '\r\nctrlvalue_0=' + enc_account
str_info += '\r\nctrlid_1=34339'
str_info += '\r\nctrlvalue_1=' + enc_password
str_info += '\r\nreqctrl=4304'
str_info += '\r\nloginmode=1'
if not isSMS:
str_info += '\r\nloginType=3\r\n'
else:
str_info += '\r\nforeign=1'
str_info += '\r\nforeign_country=86'
str_info += '\r\nloginType=7\r\n'
券商登录
和券商相关的协议部分全部采用DES加密,DES密钥由客户端生成,512位RSA密钥加密过后在券商登录阶段发送至服务器。这部分不再是简单的上述的文本,而是类似于TLV的结构体。其中T为一个字节,L为双字节,V根据L的值来确定。 这部分定位比较困难,因此需要采用DDMS来找到关键位置。寻找过程比较枯燥无味,这部分正如之前网友讲的,没什么营养。个人也没怎么记录,因此直接讲解一下该部分组包方法。
qssj = wtid + "#" + qsid + "#" + dtkltype + "#1#"
reqpage = str(random.randint(10000, 99999))
data = b'\x13\x02' + b'\x00\x01\x00\x30\x01\x01\x00\x30'
data += int.to_bytes(2, 1, byteorder='little', signed=False)
data += int.to_bytes(len(account), 2, byteorder='little', signed=False)
data += str.encode(account)
data += int.to_bytes(3, 1, byteorder='little', signed=False)
data += int.to_bytes(len(password), 2, byteorder='little', signed=False)
data += str.encode(password)
data += int.to_bytes(4, 1, byteorder='little', signed=False)
data += int.to_bytes(len(txmm), 2, byteorder='little', signed=False)
data += str.encode(txmm)
data += int.to_bytes(5, 1, byteorder='little', signed=False)
data += int.to_bytes(0, 2, byteorder='little', signed=False)
data += int.to_bytes(6, 1, byteorder='little', signed=False)
data += int.to_bytes(len(qssj), 2, byteorder='little', signed=False)
data += str.encode(qssj)
data += int.to_bytes(7, 1, byteorder='little', signed=False)
data += int.to_bytes(len(reqpage), 2, byteorder='little', signed=False)
data += str.encode(reqpage)
data += int.to_bytes(8, 1, byteorder='little', signed=False)
data += int.to_bytes(1, 2, byteorder='little', signed=False)
data += int.to_bytes(49, 1, byteorder='little', signed=False)
data += int.to_bytes(9, 1, byteorder='little', signed=False)
HD_INFO = 'HDInfo=' + constants.HD_INFO
data += int.to_bytes(len(HD_INFO), 2, byteorder='little', signed=False)
data += str.encode(HD_INFO)
# 这部分数据直接固定
data += b'\x0a\x00\x00\x0b\x00\x00\x0c\x00\x00\x0d\x01\x00\x30\x0e\x00\x00\x0f\x00\x00\x10\x00\x00\x11\x00\x00' \
b'\x12\x00\x00'
需要发送的数据构造完毕后,在其前面添加包序号以及两字节的包头等内容后补齐至8的倍数。补齐后,数据采用随机生成的16字节密钥完成DES加密,密钥通过RSA(该处RSA加密与上述不同)加密后放在之前加密好的密文之前。
enc_data = Des.des(data, globals()['server_key'], True)
enc_key = constants.RSA_KEY_HEADER
enc_key += globals()['qs_login_header']
enc_key += globals()['server_key']
enc_key = rsa_utils.rsa_encrypt_key(enc_key)
enc_key_length = len(enc_key)
data = enc_key
data += enc_data
申购可转债
登录完成后,来到了申购可转债环节。这部分可转债数据构造完成后,就可以采用上述生成的16字节密钥进行加密了。
reqpage = random.randint(10000, 99999).__str__()
str_info = '[frame]'
str_info += '\r\nid=2682'
str_info += '\r\npageList=' + reqpage
str_info += '\r\nreqPage=' + reqpage
str_info += '\r\nreqPageCount=1'
str_info += '\r\nqsid=' + globals()['qsid']
str_info += '\r\nwtaccount=' + globals()['wtaccount']
str_info += '\r\nwttype=' + globals()['dtkltype']
str_info += '\r\n[' + reqpage + ']'
str_info += '\r\nid=1820'
str_info += '\r\nreqctrl=2001'
str_info += '\nctrlid_0=36641'
str_info += '\nctrlvalue_0=1'
str_info += '\nctrlid_1=36615'
str_info += '\nctrlvalue_1=' + quantity
str_info += '\nctrlid_2=2102'
str_info += '\nctrlvalue_2=' + code
str_info += '\nctrlid_3=2127'
str_info += '\nctrlvalue_3=' + price
str_info += '\nctrlcount=4'
str_info += '\r\nHDInfo=' + constants.HD_INFO
包头部分
包头部分主要包含了当前数据包的长度以及类型之类的信息。
full_data = b''
full_data += int.to_bytes(data_header.headLength, 2, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.id, 4, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.type, 4, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.pageId, 2, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.dataLength, 4, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.frameId, 4, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.textLength, 4, byteorder='little', signed=False)
full_data += int.to_bytes(data_header.sessionType, 4, byteorder='little', signed=False)
full_data += data
后记
讲到现在,对app通讯部分就了解差不多了。其实该APP逆向过程中,主要就是体力活==只是单纯的分享源码,不写点儿啥的话对不起自己这么多天。所以随便写点儿东西,该源码我也没有完善,所以希望通过我的一点儿笔记给有心思研究该app的同志一点儿小小的启发。 该app在逆向的过程中,最麻烦的莫过于服务器返回数据的解析了,其他还好说,关键是主要StuffCurveStruct以及StuffTableStruct两种格式数据的处理。StuffCurveStruct应该包含的是股票的详细信息, 这部分暂未完成解析, 感觉用处不大。StuffTableStruct包含了除股票信息之类, 比如个人持仓之类的信息,这部分花费了比较大的精力去搞定。 目前大家如果还想开发新的接口的话,直接通过frida hook发送的数据康康就行,返回数据我应该已经解析的差不多了。