
本文章收录于:
目录
1. make与new的区别
Make 用于map、slice 和channel几种类型的内存分配。并且返回一个有初始值的对象,注意不是指针。
注:channel在make之后打印出来的也是内存地址,是个特殊类型。
New 用于使用type声明的类型的内存分配。new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即一个T类型的值。用Go的术语说,它返回了一个指针,指向新分配的类型T的零值。有一点非常重要:new返回指针。
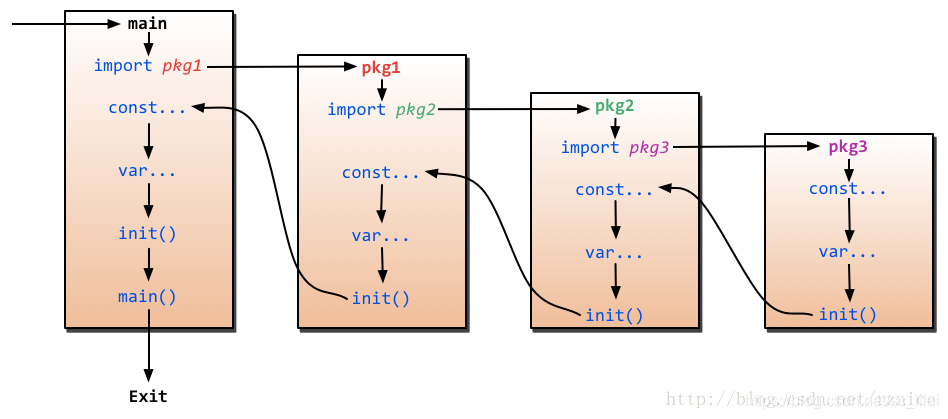
2. 简要描述go中的main和init函数的区别
首先,这两个函数应用位置不同,init函数可以应用于所有的package,main只能应用于 package main,需要注意的是虽然一个package中可以写任意多个init,但是无论是从可读性还是可维护性来说,都是不推荐的; 其次,这两个函数定义时都不能有任何的参数和返回值, 最后,个人理解,init函数为初始化操作,main函数为程序入口。
一图胜千言
3. 下面的代码输出什么,若会报错报什么错?
func main(){
/*
先defer的后执行
recover后输出panic中的信息
*/
defer func(){
If err:=recover();err!=nil{
fmt.Print(err)
} else {
fmt.Print("no")
}
}()
defer func(){
panic("1111111111111")
}()
panic("22222222222")
}
答案:不会报错,而是被recover捕捉,打印出1111111111111
4. 这段代码会输出什么?
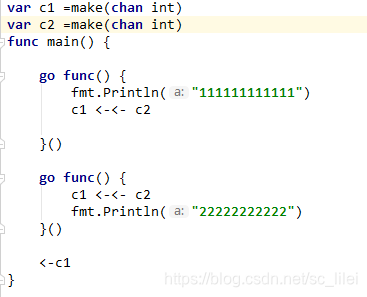
答案:先打印出111111111,然后报错(死锁)
说明:两个协程都是读取c2中的元素,然后塞入c1, 然而c2又是无缓冲且没有任何协程在往c2中写数据,所以第一个协程读c2的时候就导致死锁,因为c2永远读不出数据。 如何改能让程序不报错?在第一个协程前加一个协程:
gofunc(){
c2<-1
}()5、简述channel和mutex锁机制的原理异同与使用场景
channel原理: 当channel能存放的元素数量为0时表示为阻塞型channel。当管道无数据时,需要从管道取数据的协程会被阻塞,不会向下执行。 所以可以通过多个协程应用同一个channel,从而实现协程间的同步。
channel使用场景: 1. 需要协程通信时 2. 需要管道传输数据时。
Mutex原理: 互斥锁用来防止资源竞争,多个协程使用同一把排它锁时,原来是并发运行的话将变为线性运行。
排它锁针对任意操作都是排它的,没有读写区分。 若一个goroutine获得锁,则其他goroutine会一直阻塞到他释放锁后才能获得锁。
mutex使用场景: 解决协程并发时对同一资源的竞争问题。
6、sync.WaitGroup的使用场景?
程序中需要并发,需要创建多个goroutine,并且一定要等这些并发全部完成后才继续接下来的程序执行.WaitGroup的特点是Wait()可以用来阻塞直到队列中的所有任务都完成时才解除阻塞,而不需要sleep一个固定的时间来等待.但是其缺点是无法指定固定的goroutine数目(也就是协程池功能).
7、写一段闭包代码,阐述其作用
package main
import "fmt"
type logClosure func(format string, v...interface{})
func LoggerWrapper(logType string)logClosure{
return func(format string, v...interface{}) {
fmt.Printf(fmt.Sprintf("[%s] %s", logType, format), v...,)
fmt.Println() // 换行
}
}
func main(){
info_logger := LoggerWrapper("INFO")
warning_logger := LoggerWrapper("WARNING")
info_logger("this is a %s log", "info")
warning_logger("this is a %s log", "warning")
}
作用:给访问外部函数定义的内部变量创造了条件,将关于的函数的一切封闭到了函数内部,减少了全局变量。
使用场景:
每次调用函数A时都要改变全局变量B,且B只与A相关,以往没有闭包时只能将B定义为全局变量;而现在可以将B定义为A的内部变量,将真正的执行函数作为闭包放在A内部去执行。
8、执行这段代码会发生什么?
type ConfigOne struct {
Daemon string
}
func (c *ConfigOne) String() string {
return fmt.Sprintf("print: %v", c)
}
c := &ConfigOne{}
_ = c.String()答案:如果类型实现 String(),%v 和%+v 格式将使用 String() 的值, 这里会造成死递归
9、单例实现
var once sync.Once
type manager struct {name string}
var single *manager
func Singleton() *manager{
once.Do(func() {
single = &manager{"a"}
})
return single
}
注意一个once实例只能用一次。
10、这段代码输出什么?
fmt.Println(len("你好bj!"))
答案:是9, len方法返回字符串的字节长度。
11、这段代码可以编译过吗,如果会错是在哪一行?
type Test struct {
Name string
}
var list map[string]Test
func main() {
list = make(map[string]Test)
name := Test{"xiaoming"}
list["name"] = name
fmt.Println(list["name"].Name)
list["name"].Name = "Hello"
fmt.Println(list["name"])
}不能!倒数第三行报错: cannot assign to struct field list["name"].Name in map
因为map的value不是指针。首先,map本来存储的就是value的“初始指针值”,可以打印list["name"].Name, 但不能通过取值的方式来修改。 因为当map扩容时,内部元素会在内存中移动, 移动之后list["name"].Name获取到的值依然有效,但获取到的指针是无效的,如果允许这样赋值,那之后再打印list["name"].Name 是获取不到修改后的值的。 而当value是指针时,也就是说list["name"]是指针,list["name"].Name就是指针内部的指针,值改变后,list["name"]仍然获取到的是原始数据指针,也就仍然可以获取到list["name"].Name。
12、ABCD哪一行会报错?
type S struct {
}
func f(x interface{}) {
}
func g(x *interface{}) {
}
func main() {
s := S{}
p := &s
f(s) //A
g(s) //B
f(p) //C
g(p) //D
}B和D行。interface可以接受任意类型参数,包括指针。但是*interface{} 就只能接受*interface{}
13、下面的代码会怎样输出?每次输出结果一样吗?
const N = 10
var wg = &sync.WaitGroup{}
func main() {
for i := 0; i < N; i++ {
go func(i int) {
wg.Add(1)
println(i)
defer wg.Done()
}(i)
}
wg.Wait()
}
大部分时候可以输出0~9,但是顺序都不一样,有时只能输出部分数字。 因为wg.Add被包含在协程中,到达wg.Wait时,已经执行到wg.Add(1)的协程数量是无法确定的,这中间没有耗时也没有等待的操作。 虽然不会报错,但waitgroup不应该被这样使用!Wg.Add语句应该在协程之外。
文中的题目部分来自网络,由个人整理而成,如有错误请指出。