

有一个业务需求,需要将用户 ID(数值型 >=10000000)映射为一个唯一且不重复的长 6 个字符的邀请码,用于邀请新用户注册。可以不用通过邀请码反推对应的用户 ID 是什么。
2.我的思路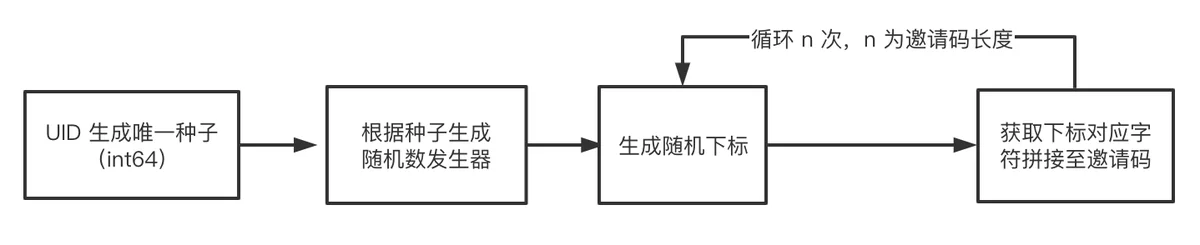
首先确定生成邀请码的字符空间,使用数字和英文大小写字母共计 62 个字符。如果长度时 6 的邀请码,那么空间大小 62^6 = 56,800,235,584,这是一个非常大的空间,足够用户量为亿级别的业务使用。
// AlphanumericSet 字母数字集
var AlphanumericSet = []rune{
'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z',
}
当然,为什么提升用户体验,可以把 O、o、0、I、1 这五个形似易混淆的字符去掉。
然后将 UID 通过 MD5 散列后,取散列值的前 8 个字节与后 8 个字节做异或运算,获取随机数种子。
// GetSeedByUID 通过用户ID获取其对应的 seed
func GetSeedByUID(uid string) int64 {
sum := md5.Sum([]byte(uid))
pre := binary.BigEndian.Uint64(sum[:8])
suf := binary.BigEndian.Uint64(sum[8:])
return int64(pre^suf)
}
最后使用获取到的 seed 创建一个随机数发生器,随机范围是字母数字集,随机次数是邀请码长度 6 次。
// GetInvCodeByUID 根据用户ID获取指定长度的邀请码
func GetInvCodeByUID(uid string, l int) string {
seed := GetSeedByUID(uid)
r := rand.New(rand.NewSource(seed))
var code []rune
for i := 0; i < l; i++ {
idx := r.Intn(len(AlphanumericSet))
code = append(code, AlphanumericSet[idx])
}
return string(code)
}
func main() {
fmt.Println(GetInvCodeByUID("100000000", 6)) // i0jLVz
fmt.Println(GetInvCodeByUID("100000001", 6)) // fhTeiE
fmt.Println(GetInvCodeByUID("100000002", 6)) // K5R5OP
}
一切看似美好,但果真如此吗?
如果说不同种子的随机数序列是随机的,那么上面邀请码发生碰撞的概率是 (1/62)^6,这是一个概率极低的事件,可以认为不可能发生,那么便满足我们的要求。
下面写一个单元测试来验证一下。
func TestGetInvCodeByUID(t *testing.T) {
sUID, eUID := 10000000, 11000000
var seedConCnt int // 种子冲突次数
var codeConCnt int // 邀请码冲突次数
mSeed := make(map[int64]struct{})
mCode := make(map[string]struct{})
// 统计 100W 个用户ID生成邀请码发生碰撞的次数
t.Run("getConflictNumTestCase", func(t *testing.T) {
for uid := sUID; uid < eUID; uid++ {
seed := GetSeedByUID(strconv.Itoa(uid))
if _, ok := mSeed[seed]; ok {
seedConCnt++
codeConCnt++
continue
}
mSeed[seed] = struct{}{}
code := GetInvCodeByUID(strconv.Itoa(uid), 6)
if _, ok := mCode[code]; ok {
codeConCnt++
continue
}
mCode[code] = struct{}{}
}
if seedConCnt != 0 || codeConCnt != 0 {
t.Errorf("seedConCnt=%v, codeConCnt=%v conRate=%v", seedConCnt, codeConCnt, float64(codeConCnt)/float64(eUID-sUID))
}
})
}
go test 运行输出:
--- FAIL: TestGetInvCodeByUID (10.53s)
--- FAIL: TestGetInvCodeByUID/getConflictNumTestCase (10.53s)
main_test.go:33: seedConCnt=0, codeConCnt=246 conRate=0.000246
FAIL
exit status 1
FAIL test 11.294s
可以看到,测试用例失败了,在 100W 个用户 ID 中存在 246 个邀请码个冲突,冲突率在万分之一的级别,而不是预想的 (1/62)^6,这是完全不能接受的。为什么会出现这种情况呢,随机数的种子是不同的啊!
((1/62)^6 * 100W)≈1/5.6W(1/62)^6回到最初的需求,我只需要将 UID 唯一映射到对应长度的邀请码即可。实际上我可以不用随机值,直接取 MD5 值的前 6 字节最为下标即可。这么来看话,我上面的做法真的是画蛇添足。
// GetInvCodeByUID 获取指定长度的邀请码
func GetInvCodeByUID(uid string, l int) string {
// 因为 md5 值为 16 字节
if l > 16 {
return ""
}
sum := md5.Sum([]byte(uid))
var code []rune
for i := 0; i < l; i++ {
idx := sum[i] % byte(len(AlphanumericSet))
code = append(code, AlphanumericSet[idx])
}
return string(code)
}
修改一下单测统计 md5 值的前 6 字节相同与碰撞的概率。
func TestGetInvCodeByUID(t *testing.T) {
sUID, eUID := 10000000, 11000000
var md5ConCnt int // md5 前 6 字节冲突次数
var codeConCnt int // 邀请码冲突次数
mSeed := make(map[uint64]struct{})
mCode := make(map[string]struct{})
// 统计 100W 个用户ID生成邀请码发生碰撞的次数
t.Run("getConflictNumTestCase", func(t *testing.T) {
for uid := sUID; uid < eUID; uid++ {
sum := md5.Sum([]byte(strconv.Itoa(uid)))
md5Value := uint64(sum[5]) | uint64(sum[4])<<8 | uint64(sum[3])<<16 | uint64(sum[2])<<24 |
uint64(sum[1])<<32 | uint64(sum[0])<<40
if _, ok := mSeed[md5Value]; ok {
md5ConCnt++
codeConCnt++
continue
}
mSeed[md5Value] = struct{}{}
code := GetInvCodeByUID(strconv.Itoa(uid), 6)
if _, ok := mCode[code]; ok {
codeConCnt++
continue
}
mCode[code] = struct{}{}
}
if md5ConCnt != 0 || codeConCnt != 0 {
t.Errorf("md5ConCnt=%v codeConCnt=%v conRate=%v", md5ConCnt, codeConCnt, float64(codeConCnt)/float64(eUID-sUID))
}
})
}
单测执行结果:
--- FAIL: TestGetInvCodeByUID (1.26s)
--- FAIL: TestGetInvCodeByUID/getConflictNumTestCase (1.26s)
main_test.go:35: md5ConCnt=0, codeConCnt=5 conRate=5e-06
FAIL
exit status 1
FAIL test 1.424s
可见,冲突率降到了百万分之一的级别。因为邀请码目标空间是 62^6 = 56,800,235,584,随着生成的邀请码数量上升,碰撞的概率也会上升,这个百万分之一的碰撞率是正常的。
这种方式产生碰撞的原因是:虽然每个字节是不同值,但是对字符集大小取模后可能会相同,所以就有可能出现碰撞。为了解决碰撞的问题,我们可以借助 DB(如 Redis)来判断是否发生碰撞,如果发生了碰撞可以再散列,再取模生成对应的邀请码,或者使用散列值的其他字节生成对应的邀请码。
5.其他解决办法有没有碰撞率为 0 的生成办法呢?毕竟用户ID是唯一的,生成一个唯一的邀请码也是理所当然的。
因为我们的用户ID是一个数值,可以将其看作是一个 62 进制的数,每一位的值范围是 0~61,类似于 10 进制数的每一位的范围是 0~9,取 62 进制数位的每一位作为字符集的下标,这样我们便可以采用 进制法(除法取整与取模) 来实现。
// GetInvCodeByUIDUnique 获取指定长度的邀请码
func GetInvCodeByUIDUnique(uid uint64, l int) string {
var code []rune
for i := 0; i < l; i++ {
idx := uid % uint64(len(AlphanumericSet))
code = append(code, AlphanumericSet[idx])
uid = uid / uint64(len(AlphanumericSet)) // 相当于右移一位(62进制)
}
return string(code)
}
// 示例
fmt.Println(GetInvCodeByUIDUnique(100000000, 6)) // ezAL60
fmt.Println(GetInvCodeByUIDUnique(100000001, 6)) // fzAL60
fmt.Println(GetInvCodeByUIDUnique(100000002, 6)) // gzAL60
理论上是不会冲突的,我们测试一下。
func TestGetInvCodeByUIDUnique(t *testing.T) {
sUID, eUID := 10000000, 20000000
var codeConCnt int // 邀请码冲突次数
mCode := make(map[string]struct{})
// 统计 1KW 个用户ID生成邀请码发生碰撞的次数
t.Run("getConflictNumTestCaseUnique", func(t *testing.T) {
for uid := sUID; uid < eUID; uid++ {
code := GetInvCodeByUIDUnique(uint64(uid), 6)
if _, ok := mCode[code]; ok {
codeConCnt++
continue
}
mCode[code] = struct{}{}
}
if codeConCnt != 0 {
t.Errorf("codeConCnt=%v conRate=%v", codeConCnt, float64(codeConCnt)/float64(eUID-sUID))
}
})
}
go test -run "TestGetInvCodeByUIDUnique"=== RUN TestGetInvCodeByUIDUnique
=== RUN TestGetInvCodeByUIDUnique/getConflictNumTestCaseUnique
--- PASS: TestGetInvCodeByUIDUnique (7.20s)
--- PASS: TestGetInvCodeByUIDUnique/getConflictNumTestCaseUnique (7.20s)
PASS
ok test 7.389s
如果说业务场景不允许通过通过邀请码反推用户ID,那么可以考虑对用户ID做扩散和混淆的处理,提高反推用户ID的成本,具体可参见用户ID生成唯一邀请码的几种方法。
参考文献
CSDN.一文完全掌握 Go math/rand
CSDN.用户ID生成唯一邀请码的几种方法
维基百科.生日问题