
本文是 「Golang 并发编程」系列的第一篇,笔者水平有限,欢迎各位大佬指点~ 文章首发于公众号 「翔叔架构笔记」,欢迎关注~
1. 前言
go2. 进程、线程、协程
任何并发程序,无论在应用层是何形式,最终都要被操作系统所管理。由此涉及到以下几个概念:
goroutinegoroutine3. 早期的调度模型:GM 模型
1.1GMGMgo func()GGM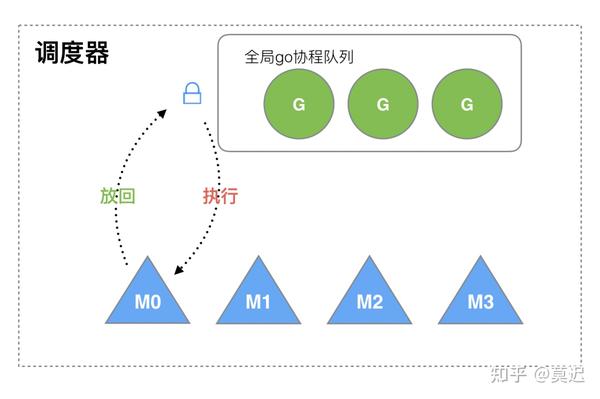
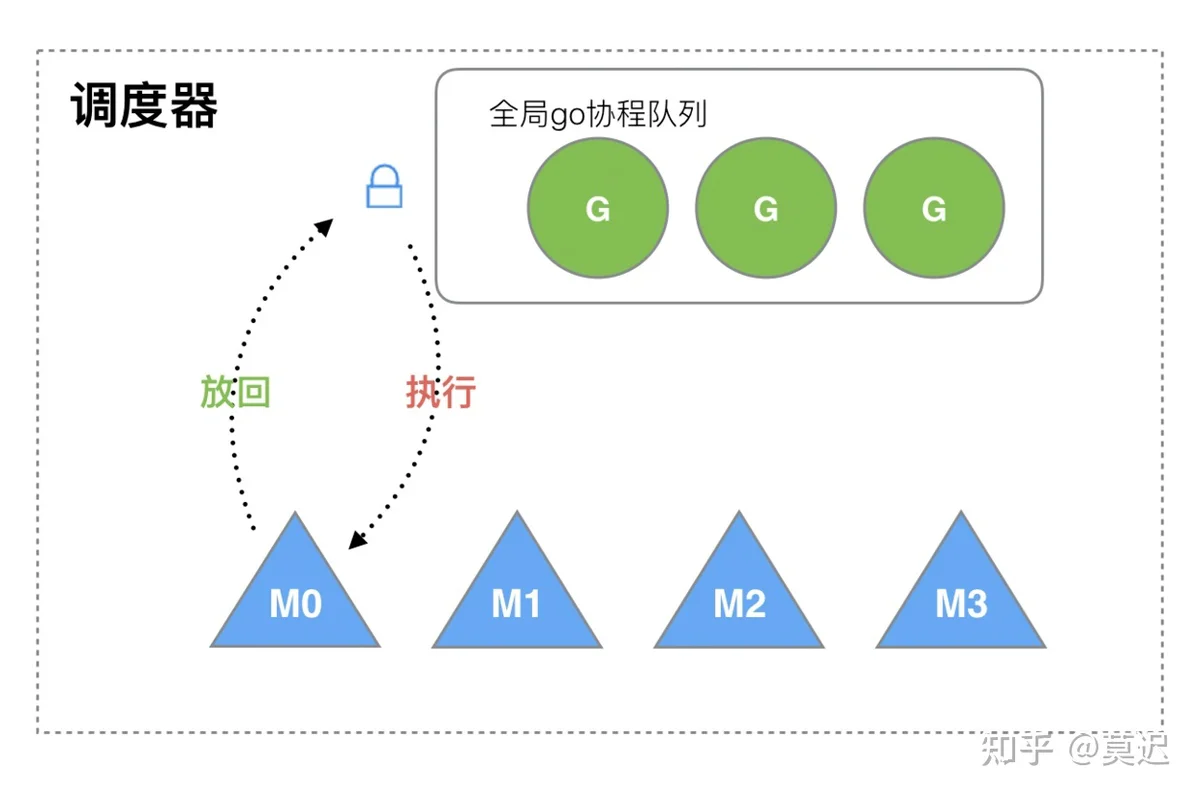
这样的设计在高并发下会带来以下问题:
What’s wrong with current implementation:
1. Single global mutex (Sched.Lock) and centralized state. The mutex protects all goroutine-related operations (creation, completion, rescheduling, etc).
2. Goroutine (G) hand-off (G.nextg). Worker threads (M’s) frequently hand-off runnable goroutines between each other, this may lead to increased latencies and additional overheads. Every M must be able to execute any runnable G, in particular the M that just created the G.
3. Per-M memory cache (M.mcache). Memory cache and other caches (stack alloc) are associated with all M’s, while they need to be associated only with M’s running Go code (an M blocked inside of syscall does not need mcache). A ratio between M’s running Go code and all M’s can be as high as 1:100. This leads to excessive resource consumption (each MCache can suck up up to 2M) and poor data locality.
4. Aggressive thread blocking/unblocking. In presence of syscalls worker threads are frequently blocked and unblocked. This adds a lot of overhead.
(原文见 )
翻译总结一下,即存在以下优化点:
- 全局锁、中心化状态带来的锁竞争导致的性能下降
- M 会频繁交接 G,导致额外开销、性能下降。每个 M 都得能执行任意的 runnable 状态的 G
- 对每个 M 的不合理的内存缓存分配,进行系统调用被阻塞住的 M 其实不需要分配内存缓存
- 强线程阻塞/解阻塞。频繁的系统调用导致的线程阻塞/解阻塞带来了大量的系统开销。
GMP4. 高效的 GMP 调度模型
GMP(Processor)P(Processor)goroutineMgoroutineG除此之外,GMP 还引入了几个新概念:
LRQ (Local Runnable Queue)GRQ (Global Runnable Queue)如下图所示:
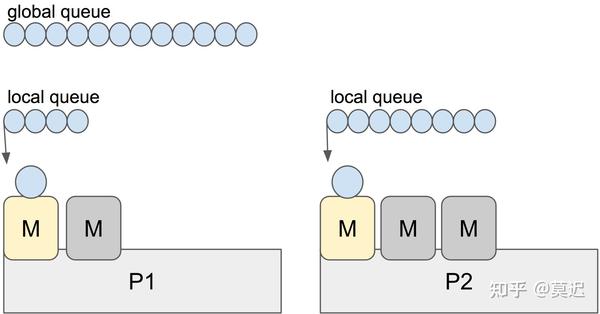
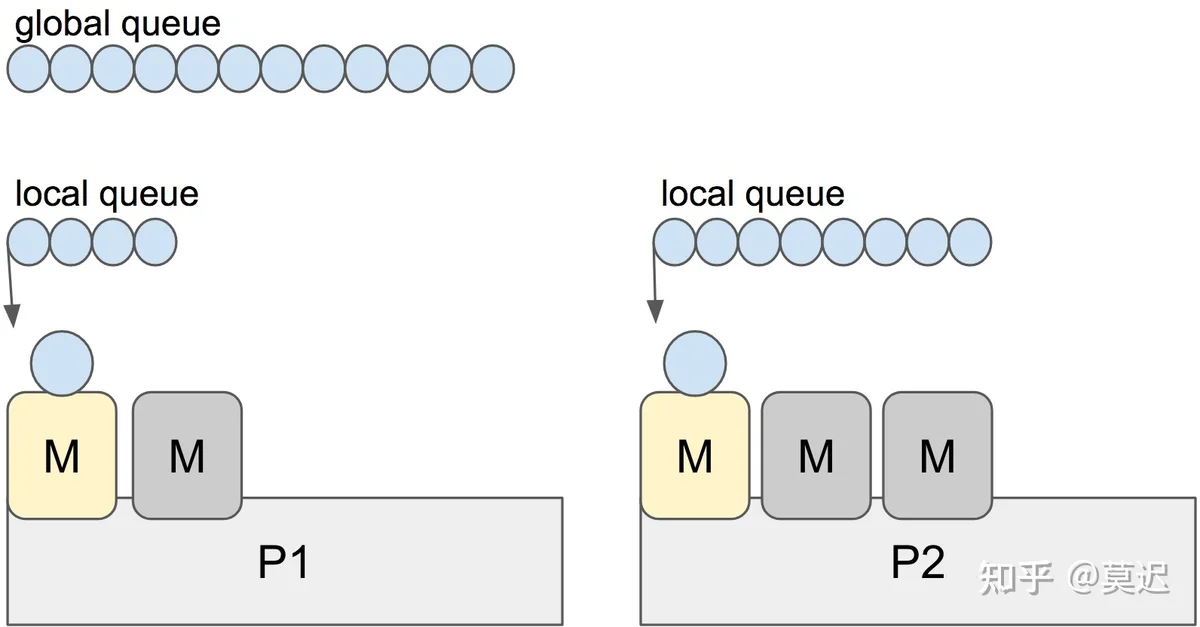
从 runtime 源码可知,整体的调度流程如下:
翻译一下,即
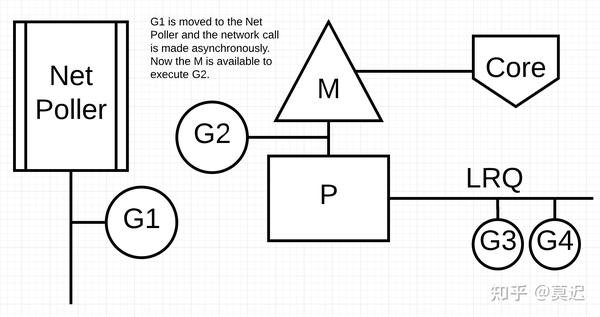
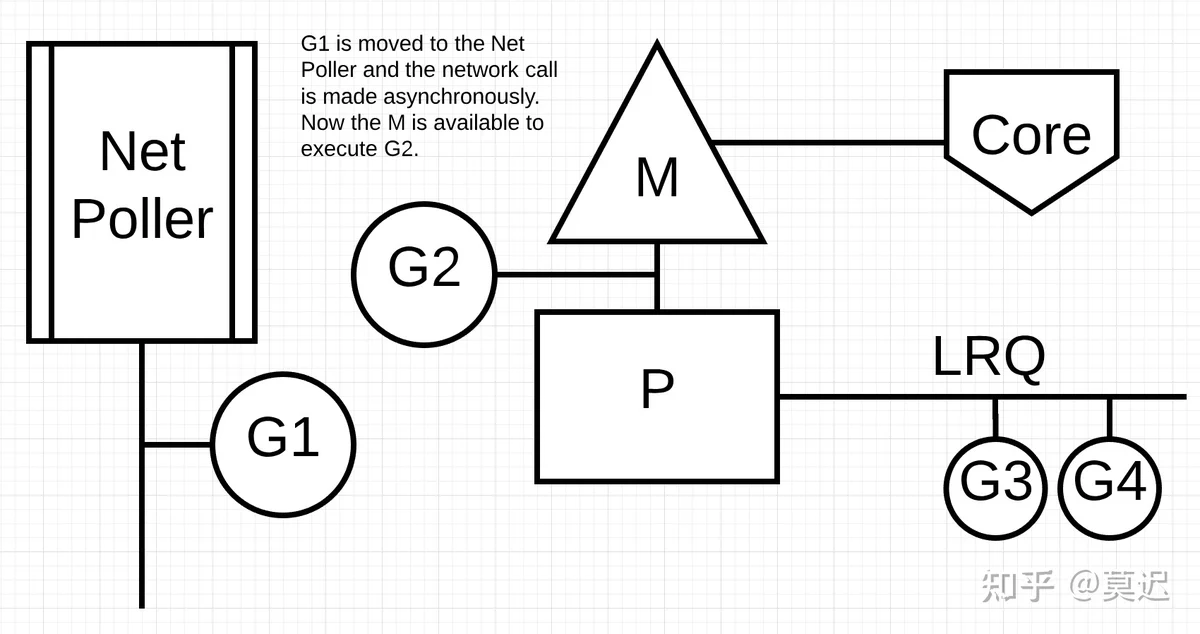
Network PollerNetwork PollerNetwork PollerNetwork Poller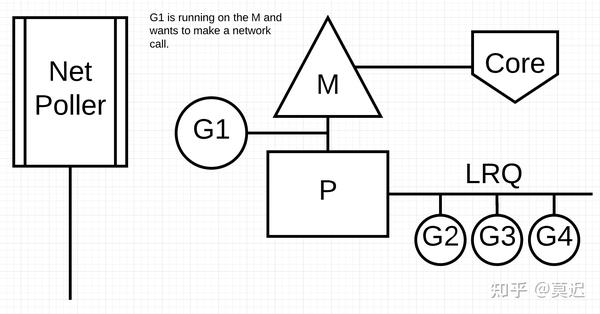

Work-stealing 机制
GMPwork-stealing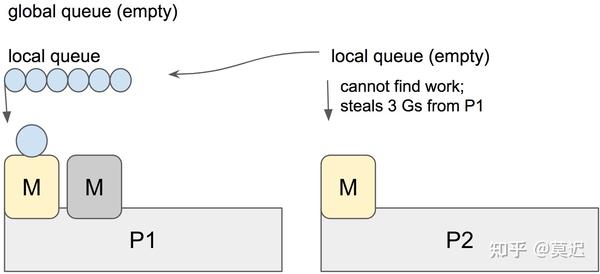
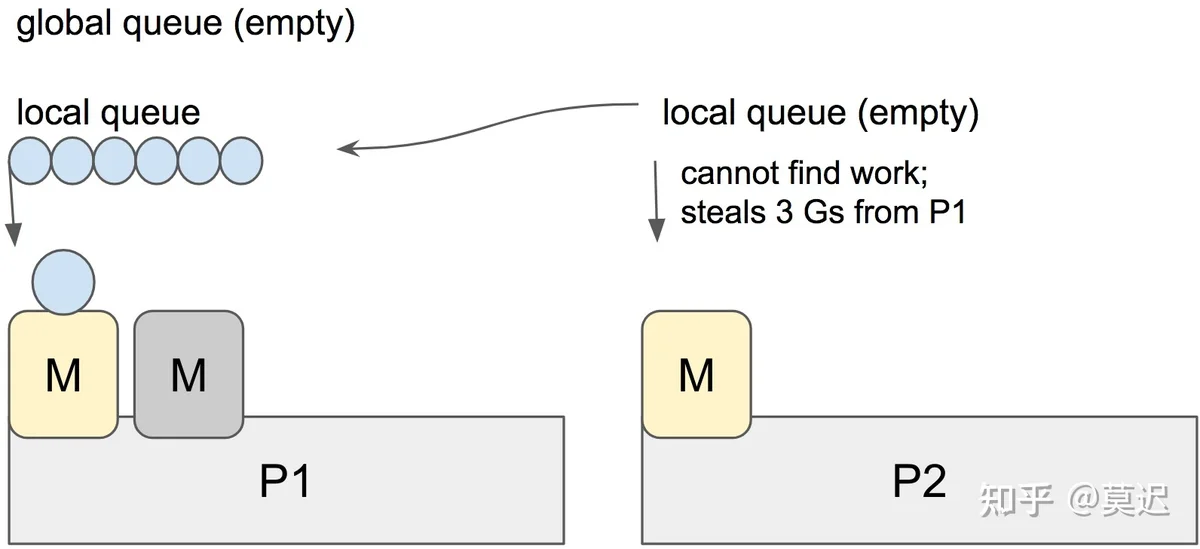
当一个新的 G 被创建时,它会被追加到它当前 P 的 LRQ 队尾。当一个 G 被执行完时,它当前的 P 会先尝试从自己的 LRQ 中 pop 一个 G 出来执行,如果此时队列为空,则会随机选取一个 P 并偷走它一半的 G ,对应图中,也就是 3 个 G
这就好比公司里的卷王,自己的需求做完了,还要悄悄把摸鱼大王的需求清单里一半的需求都挂到自己名下,囧
最后一个疑问:GRQ 什么时候被写入呢?
runq5. 小结
本文讲解了 go 语言调度器的发展及基于 GMP 的 work-stealing 策略,这个「偷」可以说是非常精妙啦~ 这是 「#Golang 并发编程」 系列的第一篇文章,如果对你有帮助,可以点个关注/在看来激励我写文章~
To be continued...