
调度模型的由来
早期操作系统是单进程的,那么执行进程只能是顺序执行的
- 顺序执行,效率比较低
- 当前进程的阻塞会带来CPU浪费,因为CPU没办法处理后面待处理的进程
后来出现了多进程操作系统,多进程处理下,会涉及到基于CPU调度器对进程分配时间片,宏观上三个进程在并发,实际还是顺序执行,这么看来,解决了进程阻塞带来对CPU浪费
但是这种方式会带来进程切换成本(进程切换涉及到拷贝复制)的浪费。
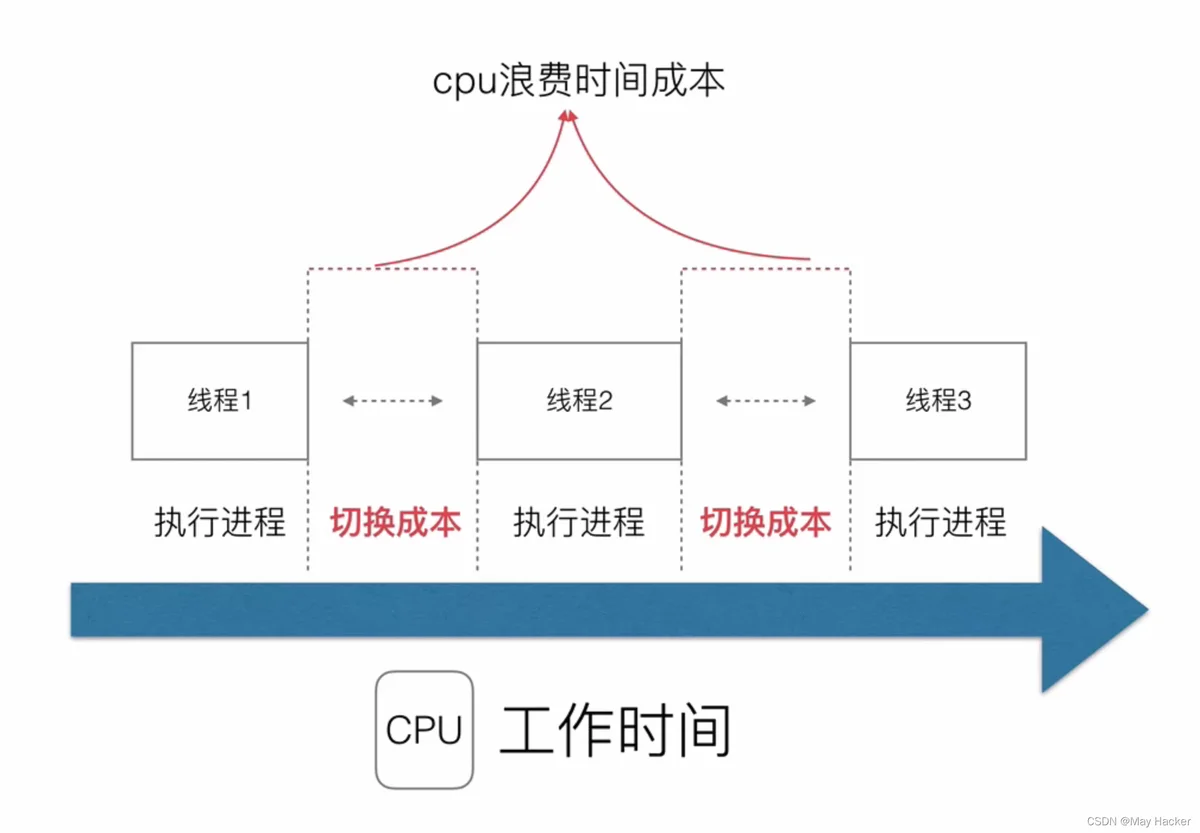
当进程数量越多,切换成本也就越浪费,CPU的一部分浪费在了切换上。
除此之外,进程和线程占用内存是很大的,进程虚拟内存占用可能是GB级别的,线程是MB级别的。
总的来说,高消耗CPU和高内存占用都是需要解决的问题。
怎么解决呢?
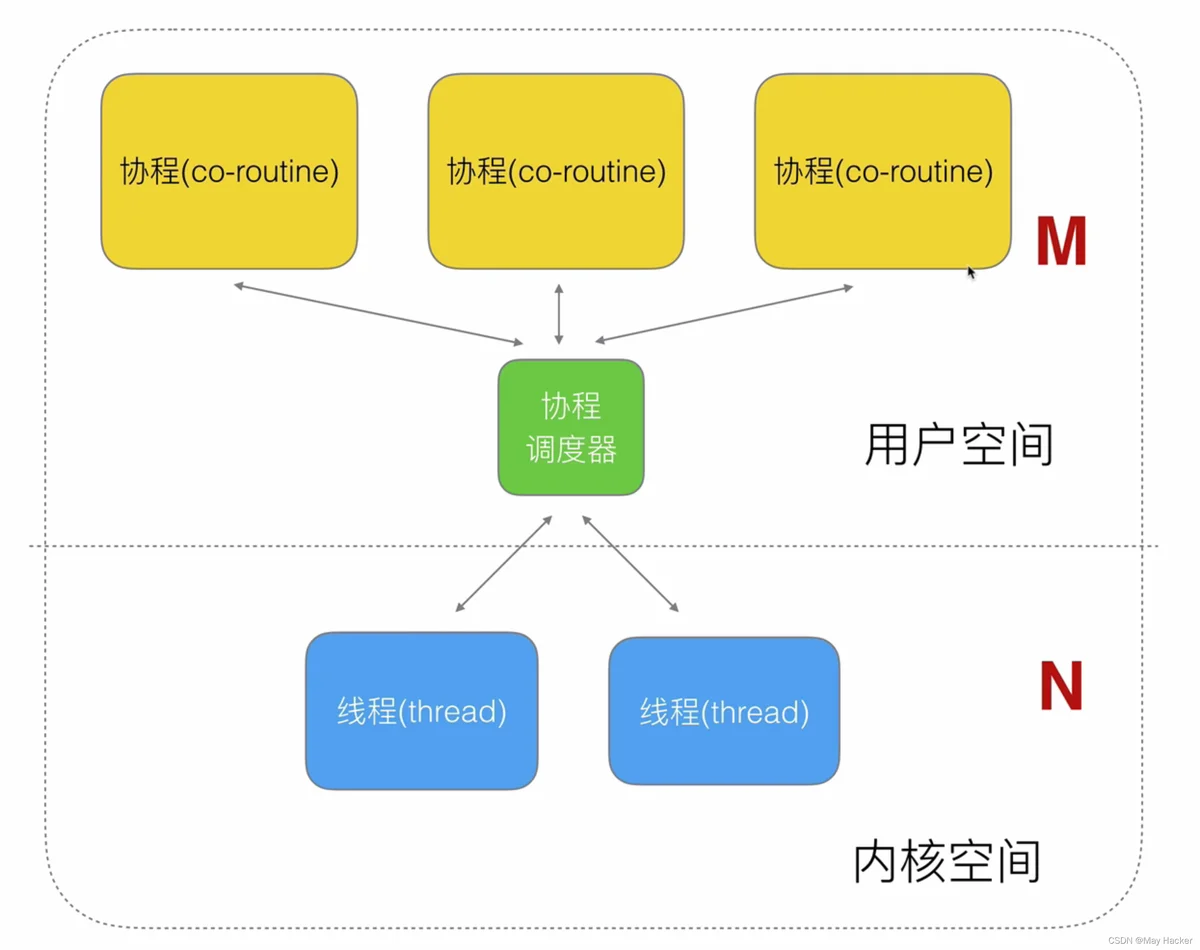
线程分为用户空间和内核空间
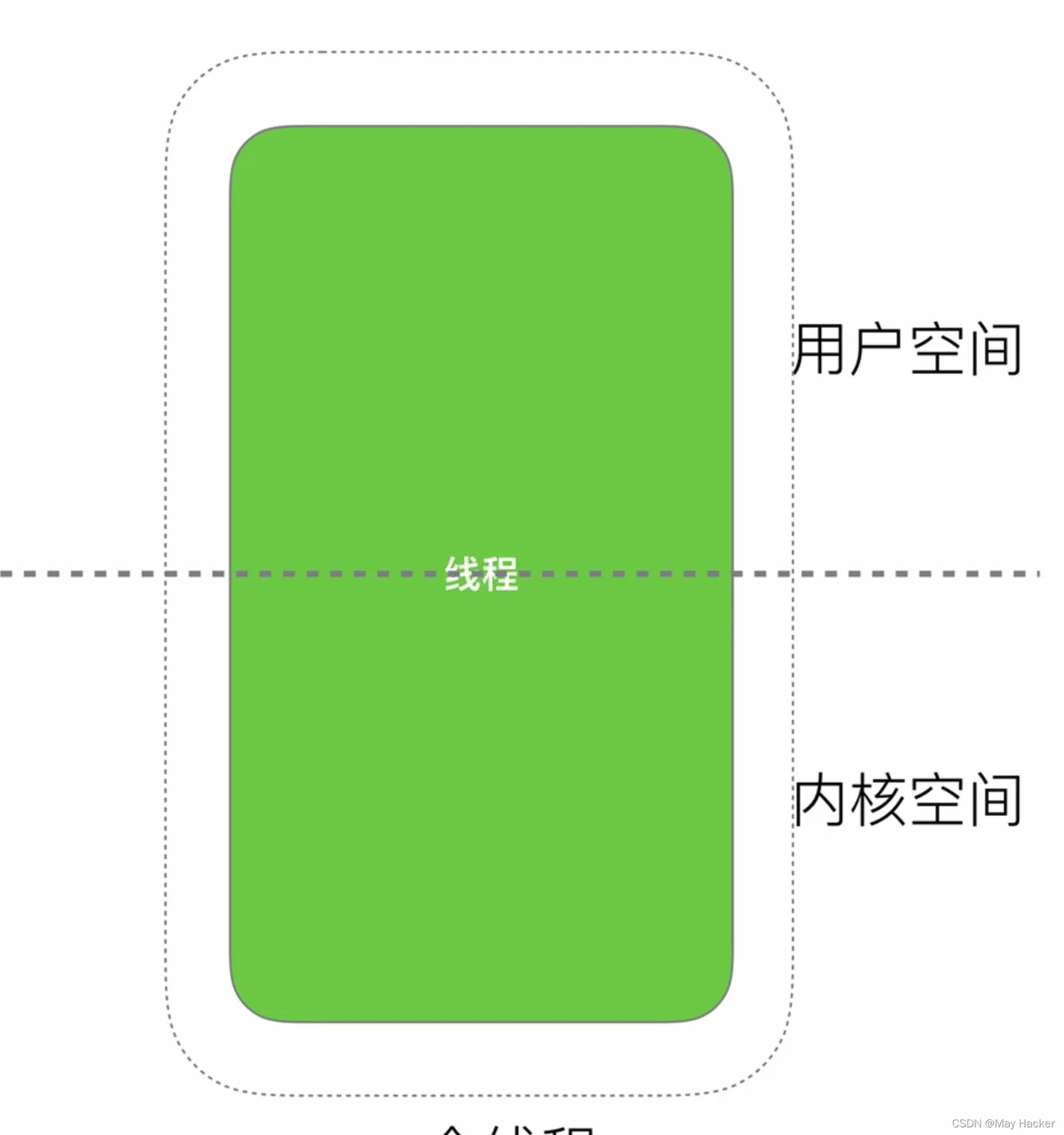
线程也会涉及用户态和内核态之间的切换,如果把线程一分为二,即用户线程和内核线程,用户线程负责业务上的处理,内核线程负责操作系统层面的处理。
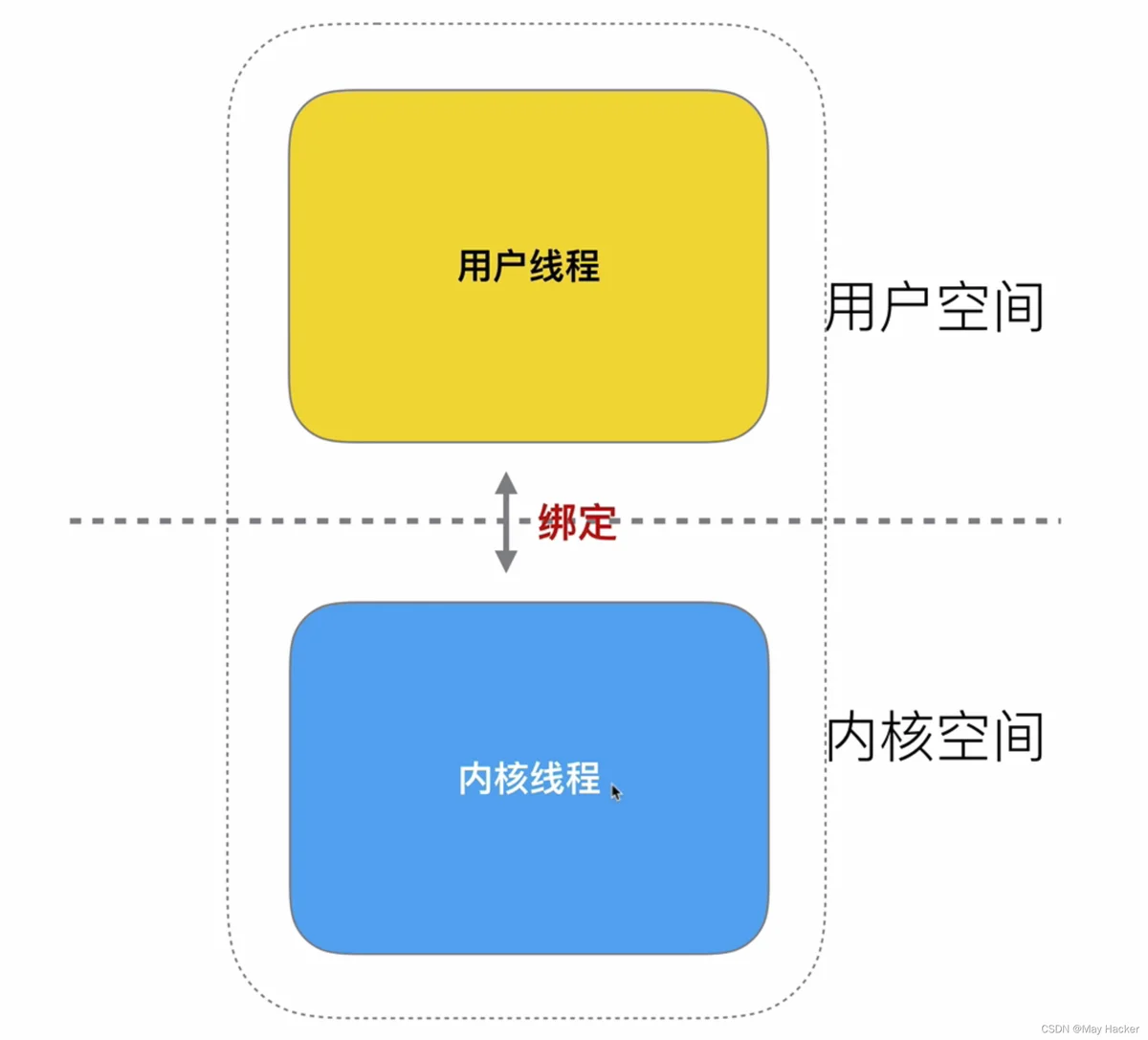
我们把用户线程称为协程,内核线程还称为线程。为了进一步提高效率,我们通过协程调度器来为内核线程绑定多个协程。
协程调度器通过轮询的方式与协程配合
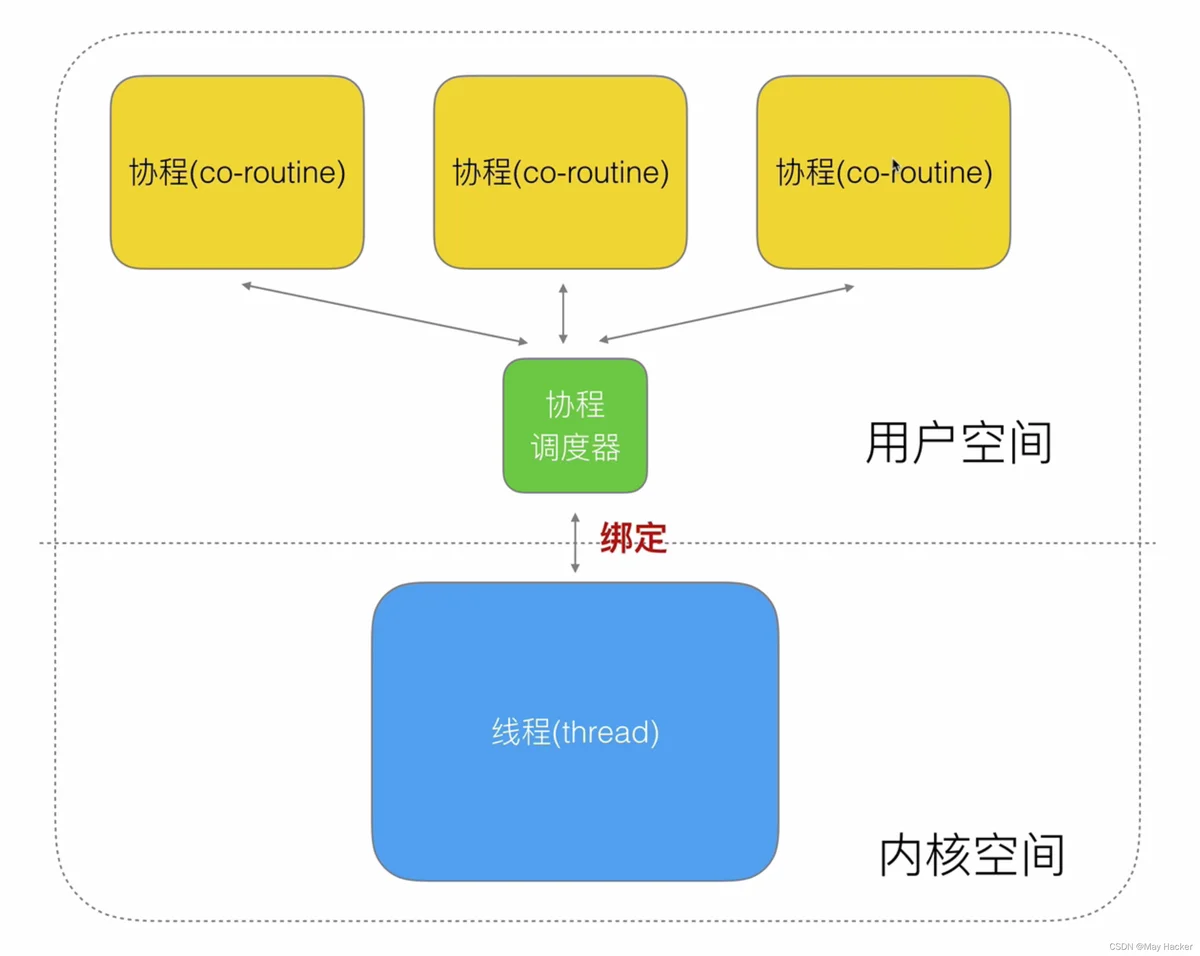
1:N所以进一步演化为一种M:N的关系
什么是GMP?
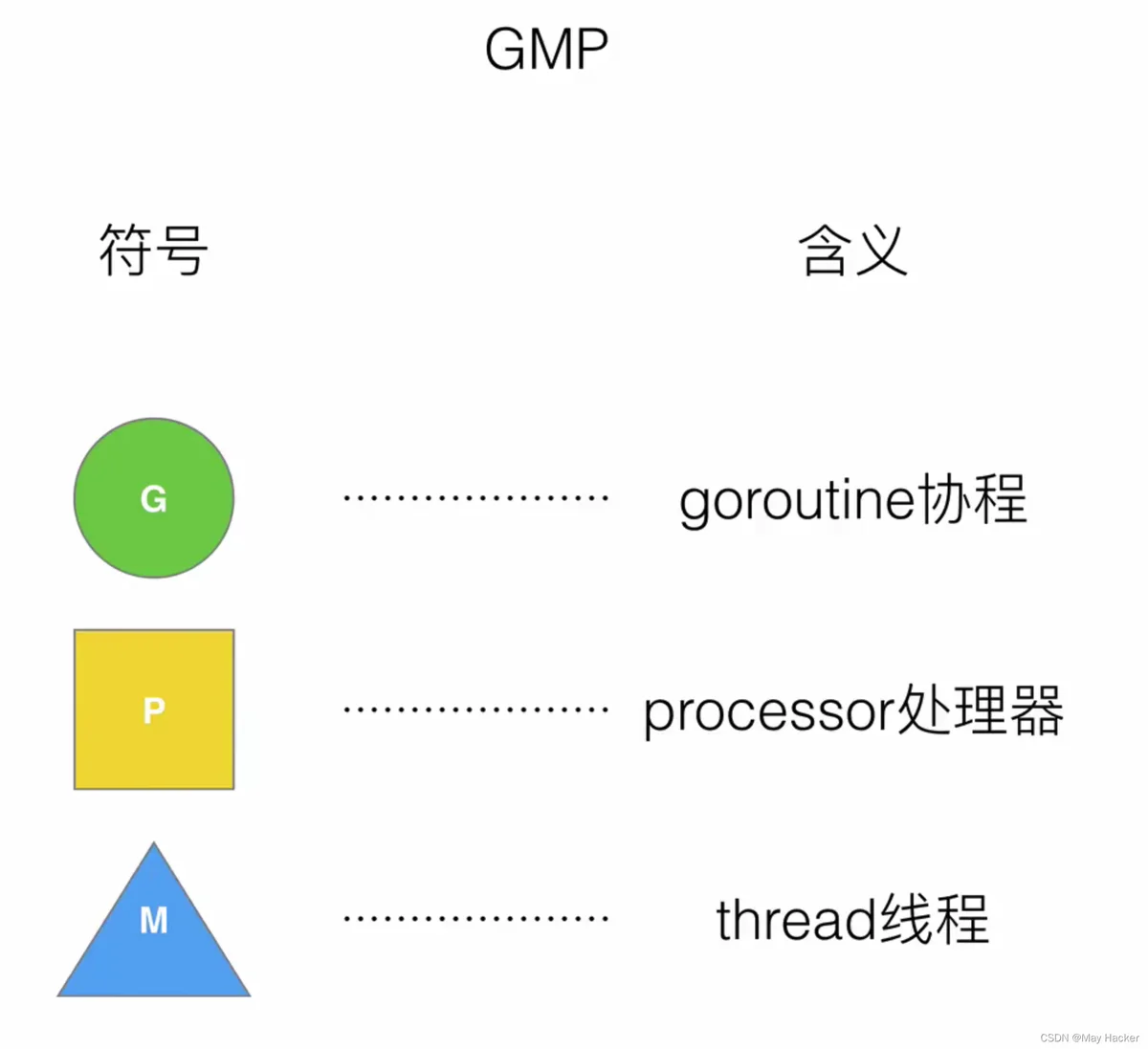
进程控制块(process control block)线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上。
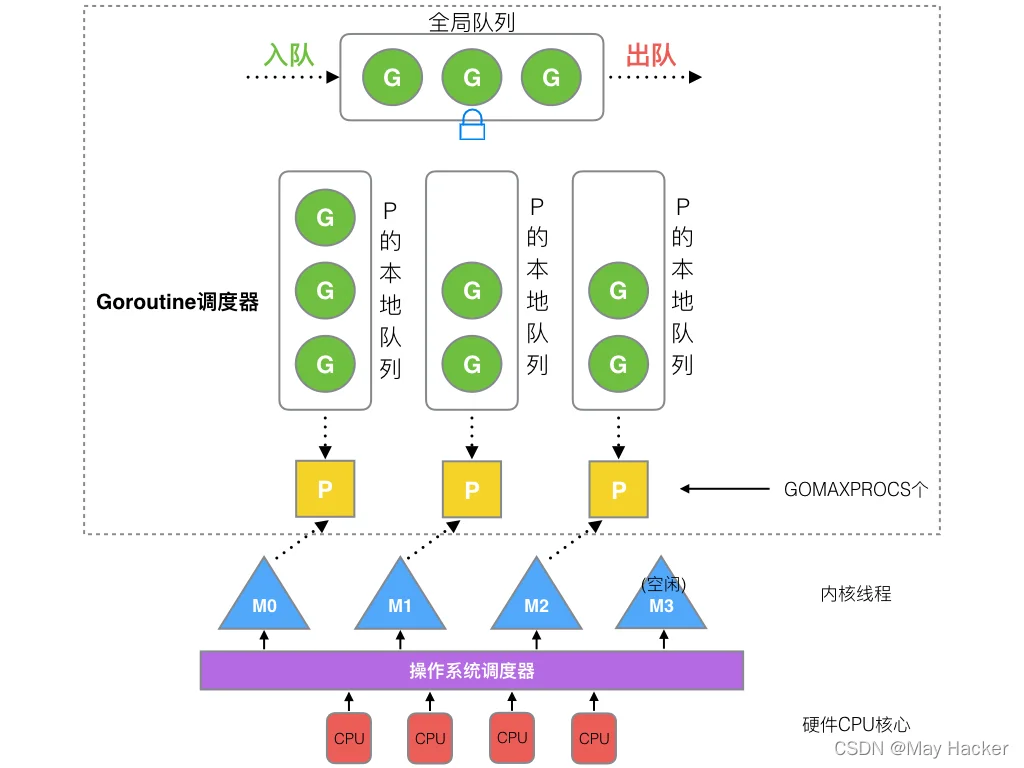
全局队列(Global Queue)P的本地队列P列表MM运行G,G执行之后,M会从P获取下一个G,不断重复下去。
Goroutine调度器,即Processor,它是和OS调度器是通过M结合起来的,每个M都代表了1个内核线程,OS调度器负责把内核线程分配到CPU的核上执行。
细说一下GMP对GoRoutine的调度策略:
- 协程调度器优先从本地队列中获取GoRoutine执行
- 之后从全局队列中获取GoRoutine执行
- 再之后从其他协程调度器中去steal协程执行
- 值得注意的是,不会完全按照以上的顺序来,因为runtime.schedule会在执行完61个本地goroutine之后,去全局队列尝试拿goroutine执行,避免全局队列中的goroutine饿死现象。
- 还有就是,协程调度器有runq和runnext,runnext代表的是下个要执行的协程,在协程数量小于257的时候,会先运行runnext中的goroutine
参考资料
https://www.kancloud.cn/aceld/golang