
从头开始开发一个简单的Kubernetes Operator。
当一个任务在Kubernetes集群中重复执行时,这可能是我们没有充分利用Kubernetes提供的所有特性,因为它的功能就是自动化任务的执行。通常,这些任务是由人工操作执行的,他们对系统应该如何运行、如何部署应用程序以及如何排除问题有深入的了解。
在创建一个operator之前,我们需要考虑标准方法,为我们的应用程序选择正确的Kubernetes资源。假设,我们的应用是有状态的,StatefulSet或许比Deployment更合适, 因为它提供了额外的特性,您可以从中受益,比如惟一的网络标识符、持久化存储、有序部署等等。
如果这种方法不合适,标准资源不能覆盖我们应用程序的特定领域逻辑,我们将需要扩展Kubernetes功能来实现自动化并实现Kubernetes operator。在本文中,我们将使用client-go库构建hello world operator,对其进行调整以实现高可用性,并使用Helm将其部署到Kubernetes集群中。
什么是Kubernetes Operator
Operators是Kubernetes的扩展,用于处理自定义资源(CRD),对应用程序的特定用例进行处理。为此,它们遵循operator 模式,特别是控制循环,这是一个无限循环,确保集群的状态满足用户在CRD中声明定义的要求。
一些operators例子:
- 创建一个应用程序的Deployment并根据流量情况或其他性能指标对其pod副本进行自动伸缩,
- 获取和恢复StatefulSet的备份,例如数据库。
- 扩展标准资源以添加新特性并提供更大的灵活性。例如,Traefik定义了IngressRoute CRD来扩展标准的Ingress。
在我们的例子当中,由于开发一个operator可能比较复杂,我们将构建一个非常简单的示例,用于监视一些自定义资源的变化并创建一个Job任务。
Operator架构
operator的主要功能就是监视kubernetes API的变化,并作出响应确保集群的状态满足CRD中声明的需求。由于集群中的事件数量可能是巨大的,对operator的合理设计将确保其高性能和可伸缩性:
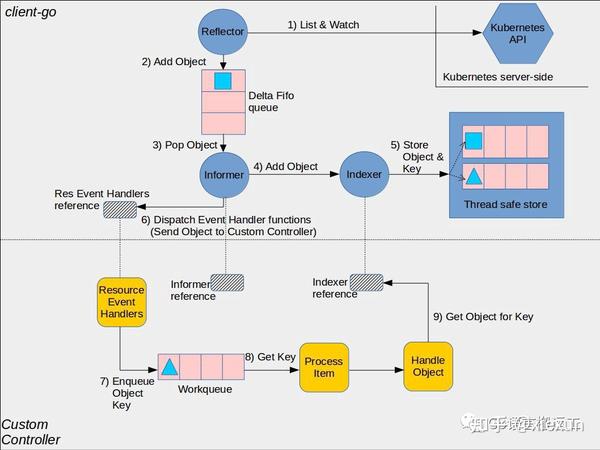
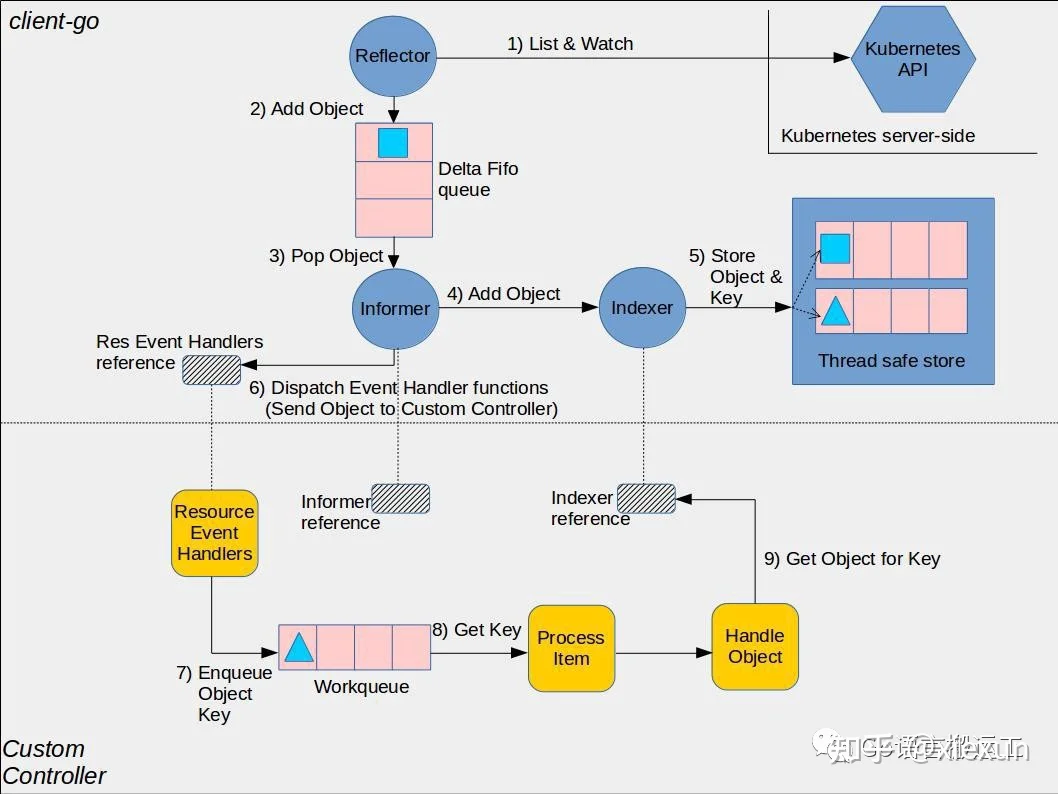
在本文中,我们将聚焦在client-go中的组件:
- clientset:与不同的API Groups交互的客户端。
- informer:跟踪API中的变化。
- indexer:在内存中索引API对象以避免API调用。
- workerqueue:以并发安全的方式处理与API对象相关的事件的内存队列。通过这种方式,我们确保不会在两个不同的worker中同时处理同一个事件。
- leaderelection:使用Kubernetes租赁对象的多个副本机制选择领导者。
自定义资源的定义
在开发operator代码之前,我们需要定义将要处理的CRD。与其他API一样,Kubernetes允许您使用OpenAPI模式定义它的自定义API对象。代码如下:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: echos.mmontes.io
spec:
group: mmontes.io
names:
kind: Echo
listKind: EchoList
plural: echos
singular: echo
shortNames:
- ec
scope: Namespaced
versions:
- name: v1alpha1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
message:
type: string
required:
- message这个CustomResourceDefinition资源将由Helm在安装我们的图表时创建;我们只需要把它放在CRDS文件夹。我们将进一步了解Helm chart的细节。现在,我们可以在下面的代码中定义operator使用的Go类型:
package v1alpha1
import metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
// +genclient
// +genclient:noStatus
// +k8s:deepcopy-gen=true
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type Echo struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata"`
Spec EchoSpec `json:"spec"`
}
type EchoSpec struct {
Message string `json:"message"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
type EchoList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Echo `json:"items"`
}
对结构进行注释,以生成与我们的CRDs及其深拷贝方法相关的clientsets和informer。为了实现这一点,我们将使用以下基于http://k8s.io/code-generator的脚本:
#!/usr/bin/env bash
set -o errexit
set -o nounset
set -o pipefail
SCRIPT_ROOT=$(dirname "${BASH_SOURCE[0]}")/..
CODEGEN_PKG=${CODEGEN_PKG:-$(
cd "${SCRIPT_ROOT}"
ls -d -1 ./vendor/k8s.io/code-generator 2>/dev/null || echo ../code-generator
)}
GO_PKG="github.com/mmontes11/echoperator/pkg"
bash "${CODEGEN_PKG}"/generate-groups.sh "all" \
${GO_PKG}/echo/v1alpha1/apis \
${GO_PKG} \
echo:v1alpha1 \
--go-header-file "${SCRIPT_ROOT}"/codegen/boilerplate.go.txt
控制器(controller)
我们需要配置的第一件事是与Kubernetes API服务的连接。这里有两个选择:
- ** KUBECONFIG**:指向kubeconfig文件的环境变量。适合本地开发。
- ** InClusterConfig**:使用pod的service account令牌访问API,因此还需要正确配置RBAC。稍后我们将对此进行详细解释。
一旦我们创建了连接,我们就可以实例化一个核心Kubernetes clientset,并使用我们的CRD clientset将它们作为依赖传递给operator(也就是控制器):
var restConfig *rest.Config
var errKubeConfig error
if config.KubeConfig != "" {
restConfig, errKubeConfig = clientcmd.BuildConfigFromFlags("", config.KubeConfig)
} else {
restConfig, errKubeConfig = rest.InClusterConfig()
}
if errKubeConfig != nil {
logger.Fatal("error getting kubernetes config ", err)
}
kubeClientSet, err := kubernetes.NewForConfig(restConfig)
if err != nil {
logger.Fatal("error getting kubernetes client ", err)
}
echov1alpha1ClientSet, err := echov1alpha1clientset.NewForConfig(restConfig)
if err != nil {
logger.Fatal("error creating echo client ", err)
}
ctrl := controller.New(
kubeClientSet,
echov1alpha1ClientSet,
config.Namespace,
logger.WithField("type", "controller"),
)
之后,我们可以配置控制器的informers,以便开始接收有关我们感兴趣的资源的事件。我们将使用cache.SharedIndexInformer来实现并将informer和indexer的职责集中在一个对象上。换句话说,此对象会维护自己更新的索引,并允许您配置事件处理程序,以便在资源更改时得到通知。唯一的要求是它需要在启动时同步。
事件将被放入workerqueue.RateLimiterInterface队列中。用于对将要处理的工作排队,而不是在事件发生时立即执行。通过这种方式,我们可以确保一次只处理固定数量的对象,而且我们永远不会在不同的worker中同时处理同一事件。以下是控制器代码:
type Controller struct {
kubeClientSet kubernetes.Interface
echoInformer cache.SharedIndexInformer
jobInformer cache.SharedIndexInformer
scheduledEchoInformer cache.SharedIndexInformer
cronjobInformer cache.SharedIndexInformer
queue workqueue.RateLimitingInterface
namespace string
logger log.Logger
}
func (c *Controller) Run(ctx context.Context, numWorkers int) error {
defer utilruntime.HandleCrash()
defer c.queue.ShutDown()
c.logger.Info("starting controller")
c.logger.Info("starting informers")
for _, i := range []cache.SharedIndexInformer{
c.echoInformer,
c.scheduledEchoInformer,
c.jobInformer,
c.cronjobInformer,
} {
go i.Run(ctx.Done())
}
c.logger.Info("waiting for informer caches to sync")
if !cache.WaitForCacheSync(ctx.Done(), []cache.InformerSynced{
c.echoInformer.HasSynced,
c.scheduledEchoInformer.HasSynced,
c.jobInformer.HasSynced,
c.cronjobInformer.HasSynced,
}...) {
err := errors.New("failed to wait for informers caches to sync")
utilruntime.HandleError(err)
return err
}
c.logger.Infof("starting %d workers", numWorkers)
for i := 0; i < numWorkers; i++ {
go wait.Until(func() {
c.runWorker(ctx)
}, time.Second, ctx.Done())
}
c.logger.Info("controller ready")
<-ctx.Done()
c.logger.Info("stopping controller")
return nil
}
func (c *Controller) addEcho(obj interface{}) {
c.logger.Debug("adding echo")
echo, ok := obj.(*echov1alpha1.Echo)
if !ok {
c.logger.Errorf("unexpected object %v", obj)
return
}
c.queue.Add(event{
eventType: addEcho,
newObj: echo.DeepCopy(),
})
}
func New(
kubeClientSet kubernetes.Interface,
echoClientSet echov1alpha1clientset.Interface,
namespace string,
logger log.Logger,
) *Controller {
echoInformerFactory := echoinformers.NewSharedInformerFactory(
echoClientSet,
10*time.Second,
)
echoInformer := echoInformerFactory.Mmontes().V1alpha1().Echos().Informer()
scheduledechoInformer := echoInformerFactory.Mmontes().V1alpha1().ScheduledEchos().Informer()
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClientSet, 10*time.Second)
jobInformer := kubeInformerFactory.Batch().V1().Jobs().Informer()
cronjobInformer := kubeInformerFactory.Batch().V1().CronJobs().Informer()
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
ctrl := &Controller{
kubeClientSet: kubeClientSet,
echoInformer: echoInformer,
jobInformer: jobInformer,
scheduledEchoInformer: scheduledechoInformer,
cronjobInformer: cronjobInformer,
queue: queue,
namespace: namespace,
logger: logger,
}
echoInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: ctrl.addEcho,
})
scheduledechoInformer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: ctrl.addScheduledEcho,
UpdateFunc: ctrl.updateScheduledEcho,
})
return ctrl
}
worker
worker的职责是通过执行任务来处理来自队列的事件确保集群处于所声明状态。为此,worker实现了一个无限控制循环,根据用户的要求调节状态。在我们的例子中,调节状态意味着创建一个Job来响应一个添加自定义Echo资源的事件。
我们将使用http://k8s.io/api,通过编程创建Kubernetes资源:
import (
echo "github.com/mmontes11/echoperator/pkg/echo"
echov1alpha1 "github.com/mmontes11/echoperator/pkg/echo/v1alpha1"
batchv1 "k8s.io/api/batch/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
func createJob(newEcho *echov1alpha1.Echo, namespace string) *batchv1.Job {
return &batchv1.Job{
ObjectMeta: metav1.ObjectMeta{
Name: newEcho.ObjectMeta.Name,
Namespace: namespace,
Labels: make(map[string]string),
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(
newEcho,
echov1alpha1.SchemeGroupVersion.WithKind(echo.EchoKind),
),
},
},
Spec: createJobSpec(newEcho.Name, namespace, newEcho.Spec.Message),
}
}
func createJobSpec(name, namespace, msg string) batchv1.JobSpec {
return batchv1.JobSpec{
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
GenerateName: name + "-",
Namespace: namespace,
Labels: make(map[string]string),
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: name,
Image: "busybox:1.33.1",
Command: []string{"echo", msg},
ImagePullPolicy: "IfNotPresent",
},
},
RestartPolicy: corev1.RestartPolicyNever,
},
},
}
}
上面代码实现以编程方式创建Kubernetes对象。
事件类型决定调用哪个方法以及在哪里创建或更新相应的对象。值得注意的是,当控制器启动时,出于一致性的原因,我们将收到添加事件,因此我们需要检查是否已经创建了对象,以避免创建两次。实现这一点的策略是从对象元数据中获取一个键,并检查它是否已经存在于索引中。代码如下:
func (c *Controller) runWorker(ctx context.Context) {
for c.processNextItem(ctx) {
}
}
func (c *Controller) processNextItem(ctx context.Context) bool {
obj, shutdown := c.queue.Get()
if shutdown {
return false
}
defer c.queue.Done(obj)
err := c.processEvent(ctx, obj)
if err == nil {
c.logger.Debug("processed item")
c.queue.Forget(obj)
} else if c.queue.NumRequeues(obj) < maxRetries {
c.logger.Errorf("error processing event: %v, retrying", err)
c.queue.AddRateLimited(obj)
} else {
c.logger.Errorf("error processing event: %v, max retries reached", err)
c.queue.Forget(obj)
utilruntime.HandleError(err)
}
return true
}
func (c *Controller) processEvent(ctx context.Context, obj interface{}) error {
event, ok := obj.(event)
if !ok {
c.logger.Error("unexpected event ", obj)
return nil
}
switch event.eventType {
case addEcho:
return c.processAddEcho(ctx, event.newObj.(*echov1alpha1.Echo))
case addScheduledEcho:
return c.processAddScheduledEcho(ctx, event.newObj.(*echov1alpha1.ScheduledEcho))
case updateScheduledEcho:
return c.processUpdateScheduledEcho(
ctx,
event.oldObj.(*echov1alpha1.ScheduledEcho),
event.newObj.(*echov1alpha1.ScheduledEcho),
)
}
return nil
}
func (c *Controller) processAddEcho(ctx context.Context, echo *echov1alpha1.Echo) error {
job := createJob(echo, c.namespace)
exists, err := resourceExists(job, c.jobInformer.GetIndexer())
if err != nil {
return fmt.Errorf("error checking job existence %v", err)
}
if exists {
c.logger.Debug("job already exists, skipping")
return nil
}
_, err = c.kubeClientSet.BatchV1().
Jobs(c.namespace).
Create(ctx, job, metav1.CreateOptions{})
return err
}
func resourceExists(obj interface{}, indexer cache.Indexer) (bool, error) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err != nil {
return false, fmt.Errorf("error getting key %v", err)
}
_, exists, err := indexer.GetByKey(key)
return exists, err
}
运行高可用的控制器
部署控制器之前最后一件事是根据配置确定使用哪种架构:单机架构还是高可用性架构。这正是runner的责任,但在本文中,我们将重点关注高可用性。高可用性意味着需运行控制器的多个副本,以确保如果leader宕机,另一个副本将获得leader并开始运行控制循环来处理CRDs。
Kubernetes是为解决类似这样的分布式系统问题而设计的,并提供开箱即用的解决方案。在这种情况下,一个租赁(lease)对象会负责这件事;该对象可以被看作是一个分布式互斥锁,它只能有一个副本,根据该副本来确定leader。
这看起来很好,但是…Kubernetes如何高效地做到这一点呢?
Kubernetes使用etcd分布式键-值存储,与其他键-值存储不同,它提供了一种watching keys机制。能及时发现对象的变更,而不需要进行长时间的轮询或消耗额外的网络资源。此外,client-go提供了leaderelection
包,它在底层使用租约对象提供了一个抽象。下面是代码:
type Runner struct {
ctrl *controller.Controller
clientset *kubernetes.Clientset
config config.Config
logger log.Logger
}
func (r *Runner) Start(ctx context.Context) {
if r.config.HA.Enabled {
r.logger.Info("starting HA controller")
r.runHA(ctx)
} else {
r.logger.Info("starting standalone controller")
r.runSingleNode(ctx)
}
}
func (r *Runner) runSingleNode(ctx context.Context) {
if err := r.ctrl.Run(ctx, r.config.NumWorkers); err != nil {
r.logger.Fatal("error running controller ", err)
}
}
func (r *Runner) runHA(ctx context.Context) {
if r.config.HA == (config.HA{}) || !r.config.HA.Enabled {
r.logger.Fatal("HA config not set or not enabled")
}
lock := &resourcelock.LeaseLock{
LeaseMeta: metav1.ObjectMeta{
Name: r.config.HA.LeaseLockName,
Namespace: r.config.Namespace,
},
Client: r.clientset.CoordinationV1(),
LockConfig: resourcelock.ResourceLockConfig{
Identity: r.config.HA.NodeId,
},
}
leaderelection.RunOrDie(ctx, leaderelection.LeaderElectionConfig{
Lock: lock,
ReleaseOnCancel: true,
LeaseDuration: r.config.HA.LeaseDuration,
RenewDeadline: r.config.HA.RenewDeadline,
RetryPeriod: r.config.HA.RetryPeriod,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: func(ctx context.Context) {
r.logger.Info("start leading")
r.runSingleNode(ctx)
},
OnStoppedLeading: func() {
r.logger.Info("stopped leading")
},
OnNewLeader: func(identity string) {
if identity == r.config.HA.NodeId {
r.logger.Info("obtained leadership")
return
}
r.logger.Infof("leader elected: '%s'", identity)
},
},
})
}
部署到Kubernetes集群
我们的operator代码已经准备好部署了。下一步将创建一个Helm chart。首先将values.yml用于配置Kubernetes资源。代码:
nameOverride: ""
fullnameOverride: ""
image:
repository: mmontes11/echoperator
pullPolicy: IfNotPresent
tag: v0.0.1
env: production
logLevel: info
numWorkers: 4
ha:
enabled: true
leaderElection:
leaseDurationSeconds: 15
renewDeadlineSeconds: 10
retryPeriodSeconds: 2
replicaCount: 3
monitoring:
enabled: true
path: /metrics
port: 2112
namespace: monitoring
interval: 10s
labels:
release: monitoring
resources: {}
nodeSelector: {}
如您所见,有一个用于配置高可用性的对象ha。完成这些之后,现在我们可以在configmap中创建与高可用性相关的键了,如下所示:
{{ $fullName := include "echoperator.fullname" . }}
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ $fullName }}
labels:
{{ include "echoperator.labels" . | nindent 4 }}
data:
NAMESPACE: {{ .Release.Namespace }}
NUM_WORKERS: {{ .Values.numWorkers | quote }}
HA_ENABLED: {{ .Values.ha.enabled | quote }}
{{ if .Values.ha.enabled }}
HA_LEASE_LOCK_NAME: {{ $fullName }}
HA_LEASE_DURATION_SECONDS: {{ .Values.ha.leaderElection.leaseDurationSeconds | quote }}
HA_RENEW_DEADLINE_SECONDS: {{ .Values.ha.leaderElection.renewDeadlineSeconds | quote }}
HA_RETRY_PERIOD_SECONDS: {{ .Values.ha.leaderElection.retryPeriodSeconds | quote }}
{{ end }}
METRICS_ENABLED: {{ .Values.monitoring.enabled | quote }}
{{ if .Values.monitoring.enabled }}
METRICS_PATH: {{ .Values.monitoring.path }}
METRICS_PORT: {{ .Values.monitoring.port | quote }}
{{ end }}
ENV: {{ .Values.env }}
LOG_LEVEL: {{ .Values.logLevel }}
如果要高可用,deployment将设置replicas键,并引用这个configmap,将其键作为环境变量导出到pod中。代码如下:
{{ $fullName := include "echoperator.fullname" . }}
{{ $selectorLabels := include "echoperator.selectorLabels" . }}
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ $fullName }}
labels:
{{ include "echoperator.labels" . | nindent 4 }}
spec:
{{ if .Values.ha.enabled}}
replicas: {{ .Values.ha.replicaCount }}
{{ end }}
selector:
matchLabels:
{{ $selectorLabels | nindent 6 }}
template:
metadata:
labels:
{{ $selectorLabels | nindent 8 }}
spec:
serviceAccountName: {{ $fullName }}
containers:
- name: {{ $fullName }}
image: "{{ .Values.image.repository }}:{{ .Values.image.tag | default .Chart.AppVersion }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
{{ with .Values.resources }}
resources:
{{ toYaml . | nindent 12 }}
{{ end }}
envFrom:
- configMapRef:
name: {{ $fullName }}
{{ with .Values.nodeSelector }}
nodeSelector:
{{ toYaml . | nindent 8 }}
{{ end }}
注意,我们在deployment中指定了一个自定义的serviceAccountName,原因是我们需要为该帐户定义安全策略,以便可以从pod访问CRDs。否则,我们将使用默认service account访问它们,但不具有访问CRDs的权限。
当在deployment中使用service account时,一个带有令牌的卷(/var/run/secrets/ Kubernetes .io/serviceaccount/token)将被挂载到pod上,以便它们可以在Kubernetes API中进行身份验证。
为了定义该令牌的安全策略,我们将使用Kubernetes RBAC:
- serviceAccount:将在集群中授予权限的资源。
- ClusterRole:集群范围角色,可以对某些资源执行某些操作。
- ClusterRoleBinding:为serviceaccount分配角色。
apiVersion: v1
kind: ServiceAccount
metadata:
name: {{ include "echoperator.fullname" . }}
labels:
{{- include "echoperator.labels" . | nindent 4 }}
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: {{ include "echoperator.fullname" . }}
labels:
{{ include "echoperator.labels" . | nindent 4 }}
rules:
- apiGroups:
- mmontes.io
resources:
- echos
- scheduledechos
verbs:
- get
- list
- watch
- apiGroups:
- batch
resources:
- jobs
verbs:
- get
- list
- watch
- create
- apiGroups:
- batch
resources:
- cronjobs
verbs:
- get
- list
- watch
- create
- update
{{ if .Values.ha.enabled }}
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- get
- watch
- create
- update
{{ end }}
---
{{ $fullName := include "echoperator.fullname" . }}
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: {{ $fullName }}
labels:
{{ include "echoperator.labels" . | nindent 4 }}
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: {{ $fullName }}
subjects:
- kind: ServiceAccount
name: {{ $fullName }}
namespace: {{ .Release.Namespace }}
最后,我们可以执行如下命令来部署operator:
$ helm repo add mmontes [https://charts.mmontes-dev.duckdns.org](https://charts.mmontes-dev.duckdns.org/)
$ helm install echoperator mmontes/echoperator创建CRD
下面,让我们看看operator如何创建hello world Echo CRD,如下所示:
apiVersion: mmontes.io/v1alpha1
kind: Echo
metadata:
name: hello-world
namespace: default
spec:
message: "Hola, 世界!"总结
构建Kubernetes operator是一种量身定制的解决方案,只有在标准Kubernetes资源不能满足应用程序特定领域的需求时才应该考虑这个解决方案。原因是,解决一个非常具体的问题需要大量的时间和对Kubernetes的了解。
然而,如果你认为你的用例已经足够先进,并且你已经决定承担成本,那么Kubernetes社区中有一些很棒的工具可以用: