
引子:在之前的文章里 golang netpoll的实现与分析 讲了一些,对于golang netpoll的实现,但是,数据是怎么通过硬件到达golang的这块不是太明确,今天就主要分析下这一块。
linux的网络的基本实现
在 TCP/IP ⽹络分层模型⾥,整个协议栈被分成了物理层、链路层、⽹络层,传输层和应⽤层。物理层对应的是⽹卡和⽹线,应⽤层对应的是我们常⻅的 Nginx,FTP 等等各种应⽤。Linux 实现的是链路层、⽹络层和传输层这三层。
在 Linux 内核实现中,链路层协议靠⽹卡驱动来实现,内核协议栈来实现⽹络层和传输层。内核对更上层的应⽤层提供 socket 接⼝来供⽤户进程访问。我们⽤ Linux 的视⻆来看到的 TCP/IP ⽹络分层模型应该是下⾯这个样⼦的。
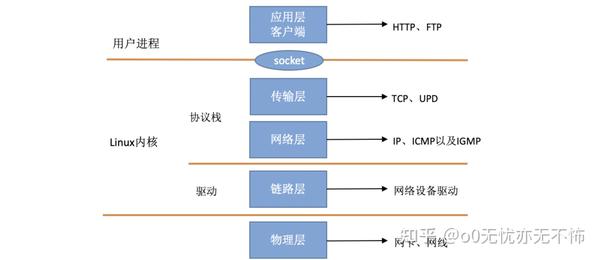
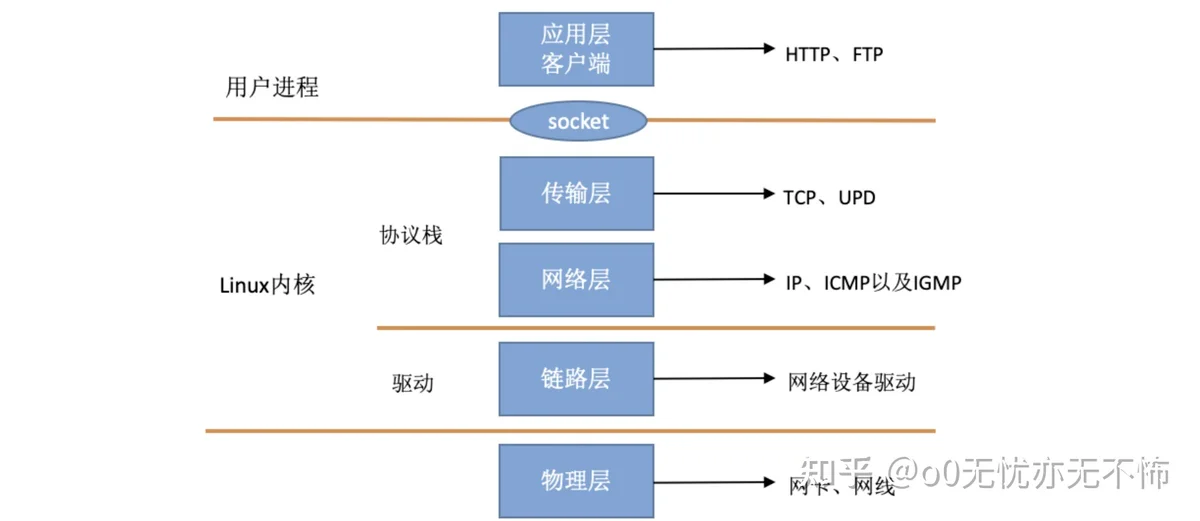
如何网络事件
当设备上有数据到达的时候,会给 CPU 的相关引脚上触发⼀个电压变化,以通知 CPU 来处理数据。
也可以把这个叫 硬中断
但是我们知道,cpu运行速度很快,但是网络读取数据会很慢,这时候就会长期占用cpu,导致cpu无法处理其他事件,比如,鼠标移动。
那么在linux中是怎么解决掉这个问题的呢?
linux内核将中断处理拆分开,拆分为了2个部分,一个是上面提到的 硬中断,另外就是 软中断。
第一部分接收到cpu电压变化,产生硬中断,然后只做最简单的处理,然后异步的交给硬件去接收信息到缓冲区。这个时候,cpu就已经可以接收其他中断信息过来了。
第二部分就是软中断部分,软中断是怎么做的呢?其实就是对内存的二进制位进行变更,类似于我们平常写业务常用的到的status字段一样,比如网络Io中,当缓冲区接收数据完毕,会将当前状态改为完成。举个例子,epoll读取某个io时间读取完数据时,并不会直接进入就绪态,而是等下次循环遍历判断状态,才会将这个fd塞入就绪列表(当然,这个时间很短,不过相对于cpu来说,这个时间就很长了)。
2.4 以后的内核版本采⽤的下半部实现⽅式是软中断,由 ksoftirqd 内核线程全权处理。和硬中断不同的是,硬中断是通过给 CPU 物理引脚施加电压变化,⽽软中断是通过给内存中的⼀个变量的⼆进制值以通知软中断处理程序。
这也就是为什么知道2.6才有epoll(正式引入)使用的原因,2.4以前内核都不支持这种方式。
总体的数据流转图如下:
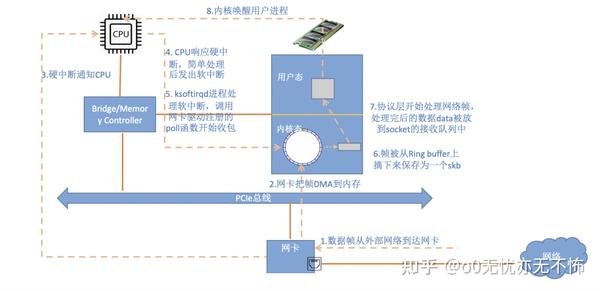
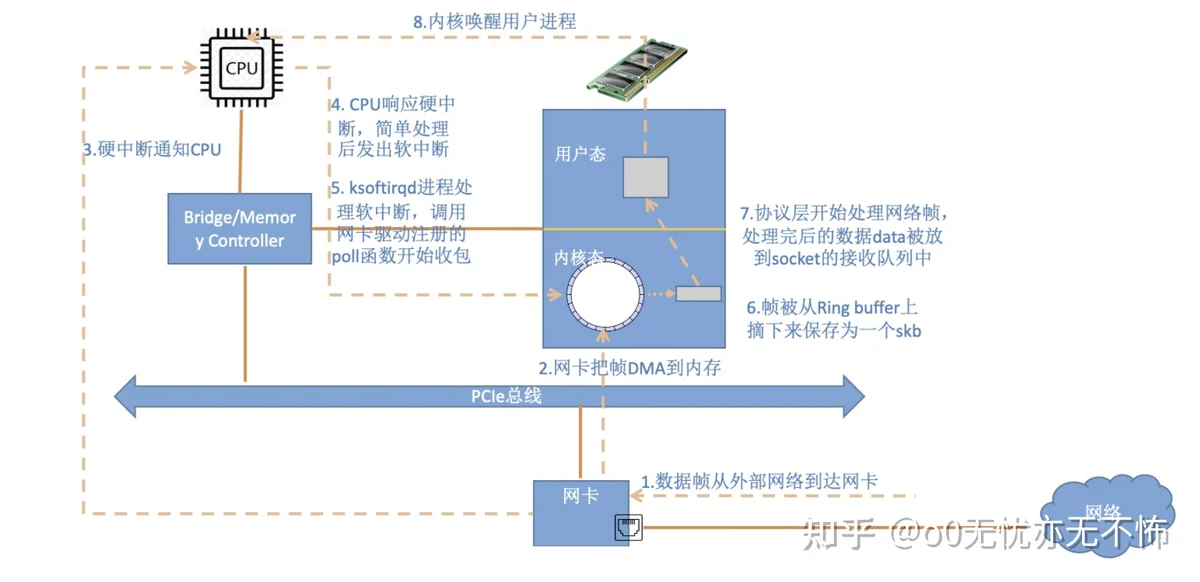
一个数据从到达网卡,要经历以下步骤才会完成一次数据接收:
- 数据包从外面的网络进入物理网卡。如果目的地址不是该网卡,且该网卡没有开启混杂模式,该包会被网卡丢弃。
- 网卡将数据包通过DMA的方式写入到指定的内存地址,该地址由网卡驱动分配并初始化。注: 老的网卡可能不支持DMA,不过新的网卡一般都支持。
- 网卡通过硬件中断(IRQ)通知CPU,告诉它有数据来了
- CPU根据中断表,调用已经注册的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数
- 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知CPU了,这样可以提高效率,避免CPU不停的被中断。
- 启动软中断。这步结束后,硬件中断处理函数就结束返回了。由于硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致CPU没法响应其它硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理。
- 内核中的ksoftirqd进程专门负责软中断的处理,当它收到软中断后,就会调用相应软中断所对应的处理函数,对于上面第6步中是网卡驱动模块抛出的软中断,ksoftirqd会调用网络模块的net_rx_action函数
- net_rx_action调用网卡驱动里的poll函数来一个一个的处理数据包
- 在pool函数中,驱动会一个接一个的读取网卡写到内存中的数据包,内存中数据包的格式只有驱动知道
- 驱动程序将内存中的数据包转换成内核网络模块能识别的skb格式,然后调用napi_gro_receive函数
- napi_gro_receive会处理GRO相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈。然后判断是否开启了RPS,如果开启了,将会调用enqueue_to_backlog
- 在enqueue_to_backlog函数中,会将数据包放入CPU的softnet_data结构体的input_pkt_queue中,然后返回,如果input_pkt_queue满了的话,该数据包将会被丢弃,queue的大小可以通过net.core.netdev_max_backlog来配置
- CPU会接着在自己的软中断上下文中处理自己input_pkt_queue里的网络数据(调用__netif_receive_skb_core)
- 如果没开启RPS,napi_gro_receive会直接调用__netif_receive_skb_core
- 看是不是有AF_PACKET类型的socket(也就是我们常说的原始套接字),如果有的话,拷贝一份数据给它。tcpdump抓包就是抓的这里的包。
- 调用协议栈相应的函数,将数据包交给协议栈处理。
- 待内存中的所有数据包被处理完成后(即poll函数执行完成),启用网卡的硬中断,这样下次网卡再收到数据的时候就会通知CPU
epoll
poll函数
这里的poll函数是说注册的回调函数,在软中断中进行处理的。比如epoll程序,会注册一个“ep_poll_callback”
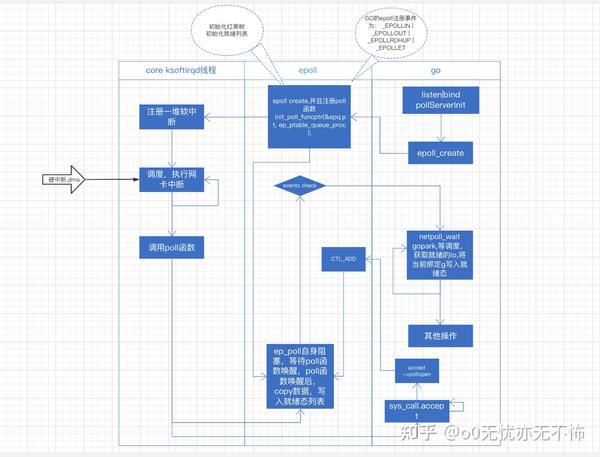
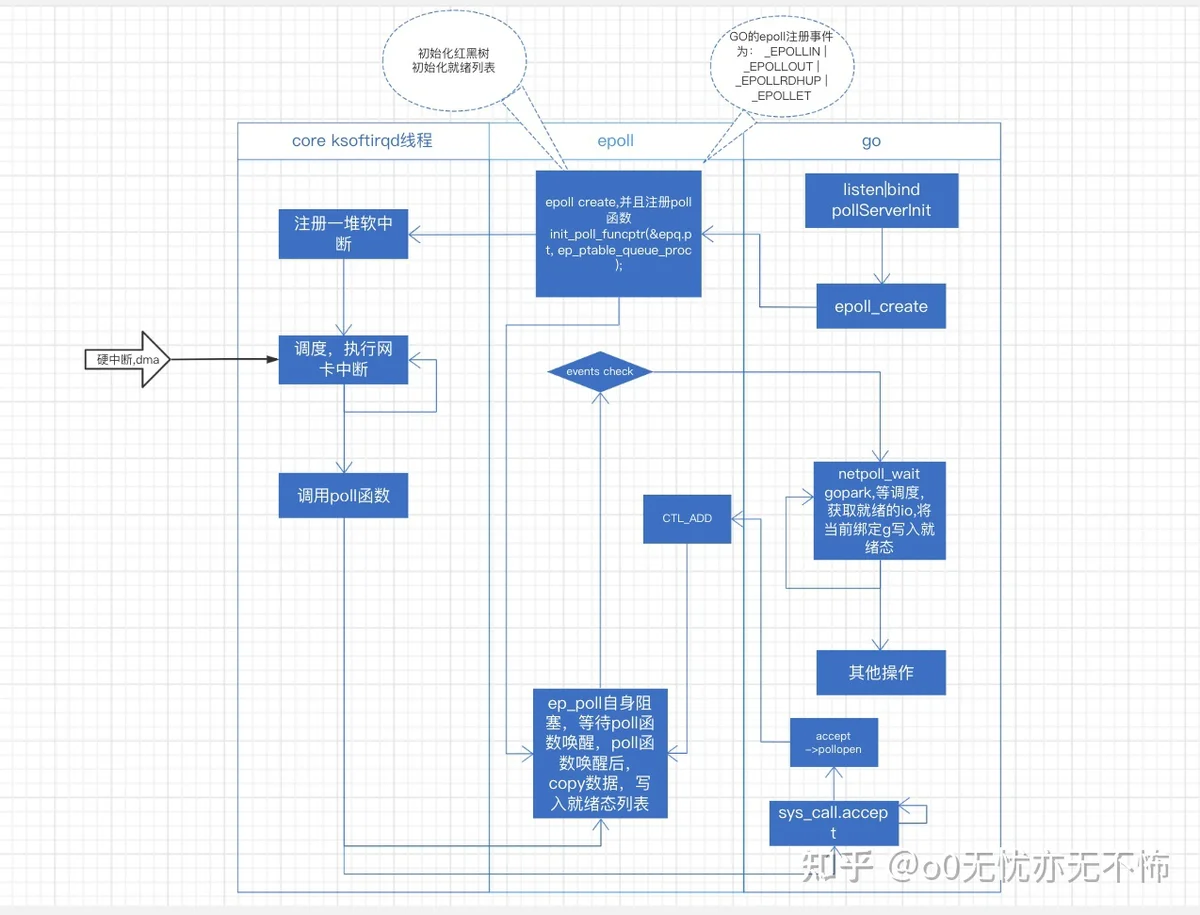
以go epoll为例:
go: accept –> pollDesc.Init -> poll_runtime_pollOpen –> runtime.netpollopen(epoll_create) -> epollctl(EPOLL_CTL_ADD)
go: netpollblock(gopark),让出cpu->调度回来,netpoll(0)将协程写入就绪态->其他操作......
epoll thread: epoll_create(ep_ptable_queue_proc,注册软中断到ksoftirqd,将方法ep_poll_callback注册到)->epoll_add->epoll_wait(ep_poll让出cpu)
core: 网卡接收到数据->dma+硬中断->软中断->系统调度到ksoftirqd,处理ep_poll_callback(这里要注意,新的连接进入到程序,不是通过callback,而是走accept)->获取到之前注册的fd句柄->copy网卡数据到句柄->根据事件类型,对fd进行操作(就绪列表)
部分代码
go: accept
epoll源码
基础数据结构
epoll用kmem_cache_create(slab分配器)分配内存用来存放struct epitem和struct eppoll_entry。 当向系统中添加一个fd时,就创建一个epitem结构体,这是内核管理epoll的基本数据结构:
而每个epoll fd(epfd)对应的主要数据结构为:
struct eventpoll在epoll_create时创建。
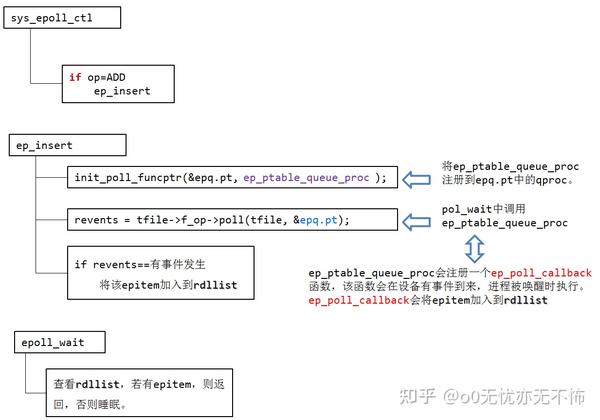
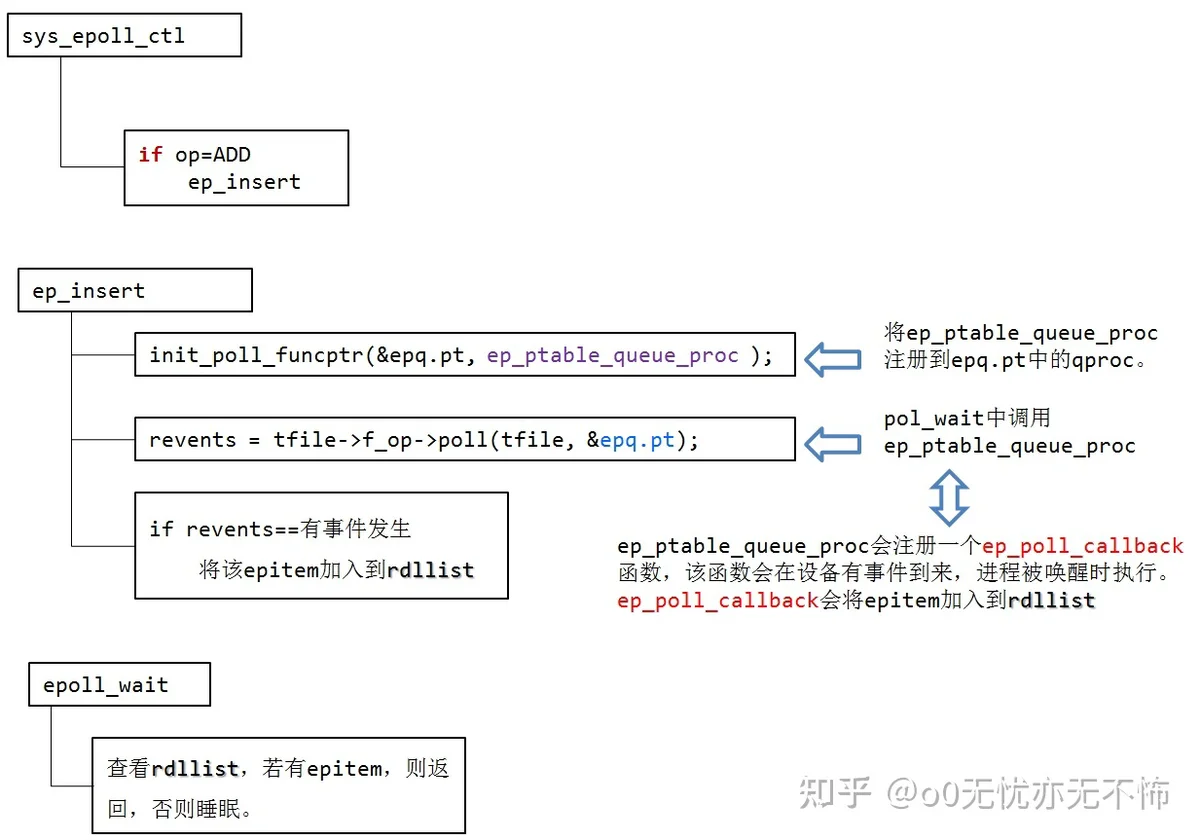
static const struct file_operations eventpoll_fops = { .release= ep_eventpoll_release, .poll = ep_eventpoll_poll, };ep_insert的实现如下:
这两个函数将ep_ptable_queue_proc注册到epq.pt中的qproc。 typedef struct poll_table_struct { poll_queue_proc qproc; unsigned long key; }poll_table; 执行f_op->poll(tfile, &epq.pt)时,XXX_poll(tfile, &epq.pt)函数会执行poll_wait(),poll_wait()会调用epq.pt.qproc函数,即ep_ptable_queue_proc。 ep_ptable_queue_proc函数如下:
ep_ptable_queue_proc
其中struct eppoll_entry定义如下:
在ep_ptable_queue_proc函数中,引入了另外一个非常重要的数据结构eppoll_entry。eppoll_entry主要完成epitem和epitem事件发生时的callback(ep_poll_callback)函数之间的关联。首先将eppoll_entry的whead指向fd的设备等待队列(同select中的wait_address),然后初始化eppoll_entry的base变量指向epitem,最后通过add_wait_queue将epoll_entry挂载到fd的设备等待队列上。完成这个动作后,epoll_entry已经被挂载到fd的设备等待队列。
由于ep_ptable_queue_proc函数设置了等待队列的ep_poll_callback回调函数。所以在设备硬件数据到来时,硬件中断处理函数中会唤醒该等待队列上等待的进程时,会调用唤醒函数ep_poll_callback(参见博文http://www.cnblogs.com/apprentice89/archive/2013/05/09/3068274.html)。
所以ep_poll_callback函数主要的功能是将被监视文件的等待事件就绪时,将文件对应的epitem实例添加到就绪队列中,当用户调用epoll_wait()时,内核会将就绪队列中的事件报告给用户。
epoll_wait实现如下:
epoll_wait调用ep_poll,ep_poll实现如下:
小知识
混杂模式
混杂模式(英语:promiscuous mode)是电脑网络中的术语。是指一台机器的网卡能够接收所有经过它的数据流,而不论其目的地址是否是它。
混杂模式常用于网络分析
DMA
DMA,全称Direct Memory Access,即直接存储器访问。
DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的。DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高。
DMA的主要特征: - 每个通道都直接连接专用的硬件DMA请求,每个通道都同样支持软件触发,这些功能通过软件来配置。 - 在同一个DMA模块上,多个请求间的优先权可以通过软件编程设置(共有四级:很高、高、中等和低),优先权设置相等时由硬件决定(请求0优先于请求1,依此类推)。 - 独立数据源和目标数据区的传输宽度(字节、半字、全字),模拟打包和拆包的过程。源和目标地址必须按数据传输宽度对齐。 - 支持循环的缓冲器管理。 - 每个通道都有3个事件标志(DMA半传输、DMA传输完成和DMA传输出错),这3个事件标志逻辑或成为一个单独的中断请求。 - 存储器和存储器间的传输、外设和存储器、存储器和外设之间的传输。 - 闪存、SRAM、外设的SRAM、APB1、APB2和AHB外设均可作为访问的源和目标。 - 可编程的数据传输数目:最大为65535(0xFFFF)。
非阻塞socket编程处理EAGAIN错误
在linux进行非阻塞的socket接收数据时经常出现Resource temporarily unavailable,errno代码为11(EAGAIN),这是什么意思? 这表明你在非阻塞模式下调用了阻塞操作,在该操作没有完成就返回这个错误,这个错误不会破坏socket的同步,不用管它,下次循环接着recv就可以。对非阻塞socket而言,EAGAIN不是一种错误。在VxWorks和Windows上,EAGAIN的名字叫做EWOULDBLOCK。