
Minio是GlusterFS创始人之一Anand Babu Periasamy发布新的开源项目。基于Apache License v2.0开源协议的对象存储项目,采用Golang实现,客户端支Java,Python,Javacript, Golang语言。
其设计的主要目标是作为私有云对象存储的标准方案。主要用于存储海量的图片,视频,文档等。非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。
对象存储的元数据
在对象存储里,元数据包括 account(用户), bucket, bucket index等信息。Minio没有独立的元数据服务器,这个和GlusterFs的架构设计很类似,在minio里都保存在底层的本地文件系统里。
在本地文件系统里,一个bucket对应本地文件系统中的一个目录。一个对象对应bucket目录下的一个目录(在EC的情况下对应多个part文件)。目录下保存者对象相关的数据和元数据。
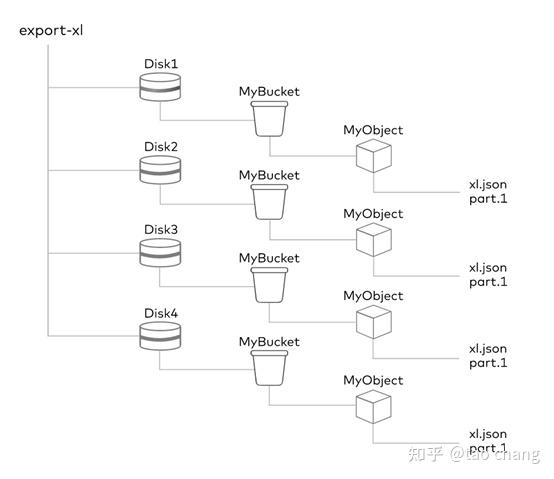
如上图所示:在Erasure Set中有4个磁盘:Disk1,Disk2,Disk3,Disk4,四个磁盘组成一个Erasure Set。每个bucket对应一个相应桶名称的目录,每个对象对应bucket的一个目录:目录里保存着对应的数据和元数据文件。
创建bucket的元数据操作:对于Erasure Set(2+2)为例:创建一个bucket,对应底层文件系统的4次目录创建。创建一个文件,需要对应底层4次目录创建,8次文件创建操作。对于小文件,数据和元数据都保存在meta文件中,也需要4次文件创建操作。由此可知,minio对应大量小文件的性能非常差。
数据存储EC
Minio目前数据仅支持EC的数据读写模式,不支持副本模式,也不支持一个集群内的扩容。在Minio的设计里,一个独立的集群中的节点数量和磁盘的数量是都是固定的,后续不能增加。只能以Federation的方式整个集群为单位扩容。
Minio把4~16个磁盘组成一个Erasure Set,每个Erasure Set包含4~16个磁盘,最少4个磁盘,最大16个磁盘,最小需要4个节点。磁盘均匀分布在所有的节点上。
例如:4个节点,每个节点8个磁盘。 每个Erasure Set 最大16个磁盘,总共32个磁盘的集群创建2个Erasure Set。每个节点取4块磁盘构成一个独立的Erasure Set中。
例如:5个节点,每个节点10个磁盘:组成了5个Erasure Set,每个节点2个磁盘组成一个Erasure Set。
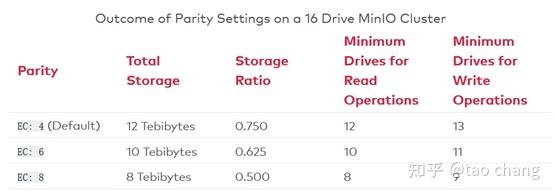
对象在Erasure Set 中通过Hash均匀分布在所有的Erasure Set中。在Minio中用格式(EC:N),其中N表示EC(M+N),M为数据块的数量,N为校验块parity的数量。Minio的读操作,需要的磁盘数量为:Erasure Set中M个磁盘,写操作需要M+1个磁盘。
EC Set的配置:
对于小文件,数据和元数据都同时保存在对应的xl.meta的文件中。对应大文件的写入,会创建相应的目录,该目录下是对应的part的数据文件和元数据。
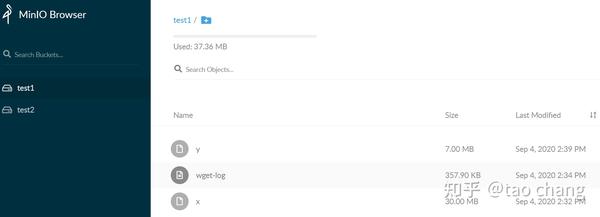
由图3可知:当前集群中有2个bucket:test1和test2。 test1中有3个对象:分别是x,y,wget-log三个对象。x是30M的大文件,通过multipart上传到集群中,有2个part,分别为part.1和part.2文件。wget-log文件是一个小文件,大小为357.9KB.
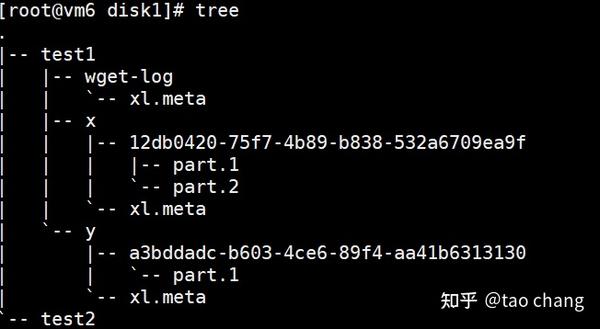
通过图4:可以清晰的看到,每个bucket对应一个同名本地目录,每个对象也对应一个同名的目录,下面存数据和元数据。对应小文件,数据和元数据都保存在 xl.meta的元数据文件中。
故障恢复
Minio的EC的实现逻辑是在客户端实现的。故障分为临时故障和永久故障:
- 临时故障:客户端会在队列中不断的重试。如果客户端crash,那么就只能依赖读修复或者后台扫描修复了。
- 永久性故障:如果磁盘故障和节点故障,这时候需要管理员去主动恢复节点(节点重启)或者添加新的磁盘,替换旧的磁盘。替换完成后,Minio的EC Set会主动监测EC set 的所有磁盘的状态,并主动的修复数据。
- 读恢复:读操作首先读数据,如果数据不完整,会通过parity块来主动修复损坏的EC data block。
- 后台扫描:Minio后台会不断的扫描数据和校验块是否完整,如果不完整,会在后台启动修复。
- 手动触发修复:Minio提供命令管理员也可以主动触发修复。
minio扩容
Mino不支持单个集群的扩容。Minio通过Federation模式来实现整个集群扩容。
传统的扩展方式是:通过增加节点来扩展单集群,一般需要处理数据寻址和数据均衡。minio 不支持对单个集群进行扩展。这种设计使得系统的很多模块更加简单(比如一个对象转换到它所在的纠删组,运用简单的哈希即可),降低了整个系统出错的概率,使得MinIO对象存储系统更加可靠、稳定。但是这就需要部署前规划好集群的大小和部署方式,相对不够灵活。
Federation 依赖2个组件:
- etcd (用于存储桶DNS服务记录)
- CoreDNS (用于基于填充的桶式DNS服务记录的DNS管理,可选)
Minio的Federation模式的扩容:只能用于新的bucket模式。Etcd 用于记录bucket 和 集群的映射关系。CoreDNS 用于域名解析。
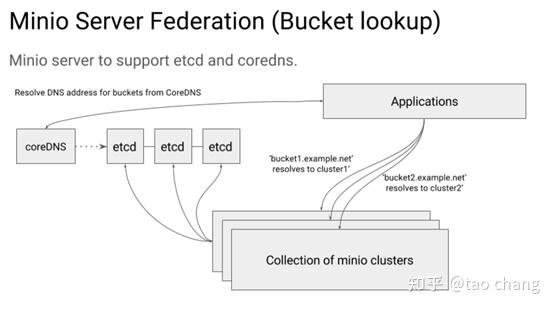
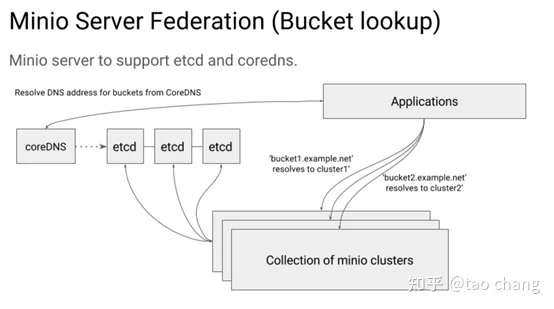
如图5所示:每个minio cluster把自己的信息注册到etcd里。一个bucket 只能存储在一个集群中。Application通过coreDNS来调度bucket对应的集群,coreDNS通过各种负载均衡的算法来分配bucket访问的集群。读取时,通过etcd来获取bucket对应的集群信息。
对象存储的其它功能
Bucket and Object tag
支持给bucket和对象打标签。目前Buceket 和 Object 的 tag 保存在对应的元数据文件中。
minio gateway
minio gateway功能可用不使用自带的Erasure Code Set存储系统,可以直接对接第三方的对象存储(AWS,GCS,Azure等其他公有云),NAS,HDFS等存储系统,从而通过s3直接访问上述系统。这个功能为已有的NAS,HDFS等系统提供S3接口提供了极大的方便。
多租户
每个租户可以有一套独立的minio server集群,部署在相关的节点和磁盘上。不同租户Server的端口不同,对应的磁盘的数据目录不同。
支持Bucket Quota
minio 支持bucket级别的配额管理。
Bucket replication
Minio支持bucket之间同步或异步的复制。支持两种模式:server side 和 client side, 也支持 active-passive 和 active-active模式。
- Server-sidde Bucket Replication 支持后端相同的MinIO Cluster之间的同一个集群或者远程集群之间的数据复
- Client-side Bucket Replication通过mc mirror进程实现桶的数据在 S3接口兼容的集群之间完成数据复制。client-side的复制模式有两种:同步和异步两种复制模式。同步的模式就是当数据完全复制到2个集群中,才给客户端完成上传成功的应答。Minio模式为异步复制模式。
Storage Class
Minio目前支持两种模式的存储级别:STANDARD 和 REDUCED_REDUNDANCY, 其区别仅仅是 EC 模式下 parity block 数量的不同。REDUCED_REDUNDANCY的parity小于等于STANDARD的parity的数量。STANDARD默认EC:4,REDUCED_REDUNDANCY默认 EC:2模式。
Disk Cache
Minio 可用用本地磁盘做Cache:实现的是 Write-Through 和 Write-Back两种模式。
DiskCache主要的应用场景是:Edge Server做为Gateway Cache,通过在application 和 public cloud 设置一个writethrough缓存。所有的upload操作都是 write through模式,同时写cache 和 public cloud存储。download操作可用就近访问本地的Cache。对于WriteBack,本地缓存可能有数据丢失的风险,如果应用场景可以接受,也可以使用这种缓存模式。
MINIO_CACHE_QUOTA 设置缓存容量大小。通过LRU算法来实现缓存淘汰。MINIO_CACHE_WATERMARK_LOW和 MINIO_CACHE_WATERMARK_HIGH 用来控制缓存空间的低位和高位。MINIO_CACHE_AFTER设置一个对象缓存需要的最小访问次数。MINIO_CACHE_RANGE可以设置对象的rang 访问是否要缓存。MINIO_CACHE_COMMIT设置缓存的模式:writeback 或者writethrough模式。MINIO_CACHE_EXCLUDE可用设置某些模式的文件名不缓存。
Bucket notifications机制:当mino中有bucket或者对象相关的创建,删除等事件,可以同步到外部到系统。目前支持如下列表的外部系统:


生命周期
- Minio支持对象生命周期的管理。
WORM
- 支持WORM数据保护的功能
多版本
- Minio支持对象的多版本。
压缩加密
- 支持压缩和加密
桶策略
- 支持bucket policy功能
s3 select
- 支持部分S3 Select功能
总结
- Minio的类似于glusterfs是一个无中心元数据服务器的设计。其index还是依赖底层本地文件系统,导致当bucket 保存大量对象时, bucket list操作很慢。
- Minio目前只支持EC的模式。
- 针对大文件的场景比较合适,由于设计简单,能发挥出磁盘等硬件的性能。目前看到的minio的应用场景也主要是替代HDFS的大数据的场景。
- EC默认推荐的配置是EC(M+N),其中M=N的模式,也就是数据盘和冗余盘相等的模式。例如 EC(4+4),EC(8+8)等模式,这种配置磁盘空间的利用率只有50%左右。对于大文件,大容量的情况,似乎空间浪费还是比较严重。社区后续也支持自己设置EC的模式,考虑到可靠性,目前官方不推荐使用。
- 针对海量小文件场景,EC显然不合适,无论是元数据还是数据存储模式都不合适,性能比较差,空间利用率比较差。
- Minio的扩容也只支持集群扩容。并且新的集群只能存储新创建的bucket的数据。这对应用来说很不友好。
- 故障恢复:在单个集群里,节点或者磁盘都是固定的,不能动态的增加。所以磁盘或者节点失效后需要管理员人工介入,及时更换新的磁盘或者修改未能成功启动的磁盘,然后管理员通过命令才能在后台恢复数据。
- 其它对象存储的功能支持的比较全: 存储分级,生命周期,WORM,压缩加密,多版本,桶策略,桶复制等功能。
综上所述:Minio对象存储系统适用于大文件场景,海量小文件的场景下并不适合。通过Federation扩容的方式适用于新创建的bucket的场景。 对于Minio的架构设和设计,笔者并不特别看好,其和glusterfs类似,适合特定的场景,对于Minio的未来,笔者也不看好。
参考: