Trie 树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。
现在,我们先来看下,Trie 树到底长什么样子。
我举个简单的例子来说明一下。我们有 6 个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这 6 个字符串依次进行字符串匹配,那效率就比较低,有没有更高效的方法呢?
这个时候,我们就可以先对这 6 个字符串做一下预处理,组织成 Trie 树的结构,之后每次查找,都是在 Trie 树中进行匹配查找。Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。最后构造出来的就是下面这个图中的样子。
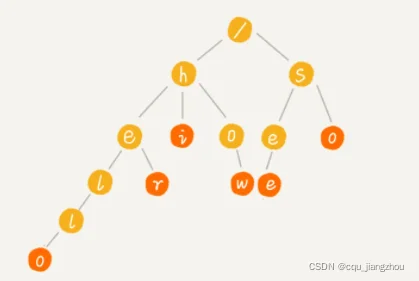
其中,根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(注意:红色节点并不都是叶子节点)。
为了让你更容易理解 Trie 树是怎么构造出来的,我画了一个 Trie 树构造的分解过程。构造过程的每一步,都相当于往 Trie 树中插入一个字符串。当所有字符串都插入完成之后,Trie 树就构造好了。
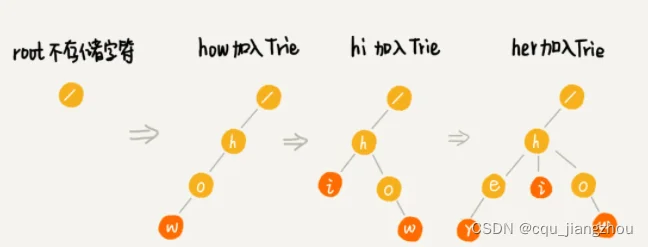
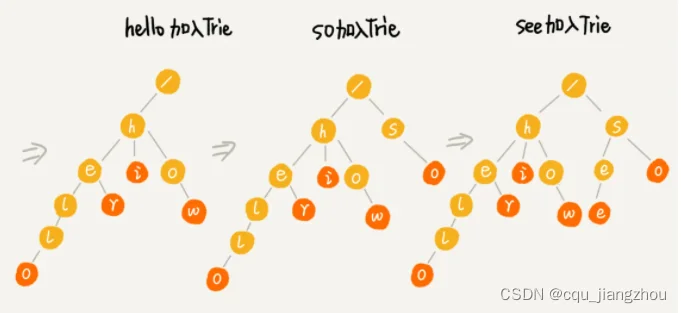
当我们在 Trie 树中查找一个字符串的时候,比如查找字符串“her”,那我们将要查找的字符串分割成单个的字符 h,e,r,然后从 Trie 树的根节点开始匹配。如图所示,绿色的路径就是在 Trie 树中匹配的路径。
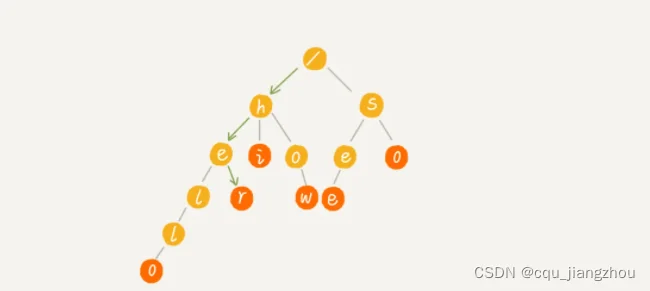
如果我们要查找的是字符串“he”呢?我们还用上面同样的方法,从根节点开始,沿着某条路径来匹配,如图所示,绿色的路径,是字符串“he”匹配的路径。但是,路径的最后一个节点“e”并不是红色的。也就是说,“he”是某个字符串的前缀子串,但并不能完全匹配任何字符串。
1、基于数组的代码实现
以下代码用于判断a-z小写的单词是否存在
package main
import "fmt"
const Size = 26 //数组大小为26
type TireNode struct {
Data uint8
IsWord bool
Next []*TireNode
}
type TireHead struct {
Len int
Next []*TireNode
}
func NewTire() *TireHead {
//next := make([]*TireNode, Size, Size)
head := &TireHead{
Len: 0,
Next: nil,
}
return head
}
func (t *TireHead) Insert(str string) {
//index := str[0] - 'a'
if t.Next == nil {
t.Next = make([]*TireNode, Size, Size)
}
cur := t.Next
index := uint8(0)
for i := 0; i < len(str); i++ {
index = str[i] - 'a' //只能比较 a-z的Size个字符(26个)
if cur[index] == nil { //TODO 注意:如果节点为空,需要创建
newNode := &TireNode{
Data: str[i],
IsWord: false,
Next: make([]*TireNode, Size, Size),
}
cur[index] = newNode
} else {
cur[index].Data = str[i] //todo 如果节点已经有了,就直接使用可以了
}
if i == len(str)-1 {
cur[index].IsWord = true //todo 最后一个字符对应的 标志位需要设置为true,代表是一个完整的字符
}
cur = cur[index].Next
}
}
func (t *TireHead) isExist(str string) bool {
if t.Next == nil {
return false
}
cur := t.Next
index := uint8(0)
for i := 0; i < len(str); i++ {
index = str[i] - 'a'
if cur[index] == nil {
//todo 特别要注意条件的判断:如果找到对应的内容为nil了,就直接返回。
// 不然从nil对应的变量中取数据,包报错
return false
}
if cur[index].Data != str[i] {
return false
}
if i == len(str)-1 && cur[index].IsWord == true {
return true
}
cur = cur[index].Next
if cur == nil {
return false
}
}
return false
}
func main() {
tire := NewTire()
//tire.Insert("ab")
//tire.Insert("ok")
tire.Insert("he")
tire.Insert("ok")
tire.Insert("hello")
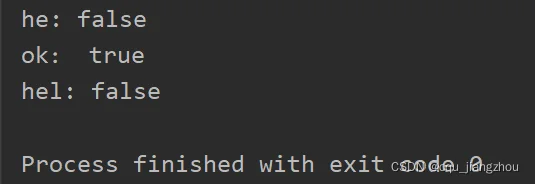
fmt.Println("he:",tire.isExist("a"))
fmt.Println("ok:",tire.isExist("ok"))
fmt.Println("hel:",tire.isExist("hel"))
}
2、基于hashmap的代码实现
package main
import (
"fmt"
)
//数据节点;存储数据:数据值、是否结束标志位、下一个节点指针
type TNode struct {
Data byte
IsWord bool
Next map[byte]*TNode
}
//根节点,存储数据为:1、字符串个数;2、数据节点map序列
type TNRoot struct {
Len int
Node map[byte]*TNode
}
func CreateTire() TNRoot {
tn := make(map[byte]*TNode)
//创建节点的时候,需要将node赋值
tRoot := TNRoot{
Len: 0,
Node: tn, //todo 技巧:需要赋值,不然后续没有办法操作
}
return tRoot
}
func (tn *TNRoot) insert(str string) {
cur := tn.Node
for i := 0; i < len(str); i++ {
if cur[str[i]] == nil {
newNode := &TNode{
Data: str[i],
IsWord: false,
Next: make(map[byte]*TNode), //TODO 技巧:下一个节点需要实例化,不然是空,后续无法操作。
}
cur[str[i]] = newNode
}
if i == len(str)-1 {
cur[str[i]].IsWord = true
}
cur = cur[str[i]].Next
}
tn.Len++
}
func (tn *TNRoot) isExist(str string) bool {
if tn.Node == nil {
return false
}
cur := tn.Node
for i := 0; i < len(str); i++ {
if cur[str[i]] == nil { //如果比较的数据不存在,直接返回
return false
}
if cur[str[i]].Data != str[i] {
return false
}
if i == len(str)-1 { //判断最后一个比较的字符是否是结束标志位
if cur[str[i]].IsWord == true {
return true
}
}
cur = cur[str[i]].Next
}
return false
}
func main() {
tire := CreateTire()
tire.insert("hello")
tire.insert("ok")
tire.insert("he")
fmt.Println(tire.isExist("ok"))
fmt.Println(tire.isExist("he"))
fmt.Println(tire.isExist("hel"))
fmt.Println("tire树的字符串数量:", tire.Len)
}