
一、基础语法

1、格式化字符串
fmt.Sprintfpackage main
import "fmt"
func main(){
// %d 表示整型数字,%s 表示字符串
var stockcode = 123
var enddate = "2022.3.28"
var url = "Code=%d&endDate=%s"
var target_url=fmt.Sprintf(url, stockcode, enddate)
fmt.Println(target_url)
}
- 运行结果
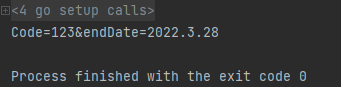
二、变量
1、一般形式
varvar identifier type
var a string = "阿巴阿巴"
//可以一次声明多个变量
var identifier1, identifier2 type
var b, c int = 1, 2
2、变量声明
方式一:指定变量类型,如果没有初始化,则变量默认为零值
- 格式
var v_name v_type
v_name = value
- 实例
package main
import "fmt"
func main(){
//声明一个变量并初始化
var a string = "阿巴阿巴"
fmt.Println(a)
//没有初始化就为零值
var b int
fmt. Println(b) // 0
//bool 类型 零值为 false
var c bool
fmt.Println(c) // false
}
- 不同类型的零值
- 数值类型为 0
- 布尔类型为 false
- 字符串为 “”(空字符串)
- 以下几种为 nil:
var a *int
var a []int
var a map[string] int
var a chan int
var a func(string) int
var a error // error 是接口
方式二:根据值自行判定变量类型
- 格式
var v_name = value
- 实例
package main
import "fmt"
func main() {
var d = true
fmt.Println(d) // true
}
:=- 格式
v_name := value
- 实例
var intVal int
intVal := 1 // 这时候编译错误,重复声明了
// 正确的
intVal := 1
intVal := 1var intVal int
intVal = 1
var a string = "阿巴阿巴"f := "阿巴阿巴"3、多变量声明
- 格式
//类型相同多个变量, 非全局变量
var vname1, vname2, vname3 type
vname1, vname2, vname3 = v1, v2, v3
var vname1, vname2, vname3 = v1, v2, v3 // 和 python 很像,不需要显示声明类型,自动推断
vname1, vname2, vname3 := v1, v2, v3 // 出现在 := 左侧的变量不应该是已经被声明过的,否则会导致编译错误
// 这种因式分解关键字的写法一般用于声明全局变量
var (
vname1 v_type1
vname2 v_type2
)
- 实例
package main
var x, y int
var ( // 这种因式分解关键字的写法一般用于声明全局变量
a int
b bool
)
var c, d int = 1, 2
var e, f = 123, "hello"
//这种不带声明格式的只能在函数体中出现
//g, h := 123, "hello"
func main(){
g, h := 123, "hello"
println(x, y, a, b, c, d, e, f, g, h)
}
4、短变量声明,使用 := 赋值操作符
- 省略 var 关键字,简写为 a := 50 或 b := false。此时 a 和 b 的类型(int 和 bool)将由编译器自动推断。
- 这是使用变量的首选形式,但是它只能被用在函数体内,而不可以用于全局变量的声明与赋值。
注意事项
- 给一个变量赋值后,一定要使用,不然会报错
- 但是全局变量是允许声明但不使用的
- 多变量可以在同一行进行赋值
// 方式一
var a, b int
var c string
a, b, c = 5, 7, "abc"
// 方式二(短变量声明)
a, b, c := 5, 7, "abc"
a, b = b, aval, err = Func1(var1)__, b = 5, 7package main
import "fmt"
func main() {
_,numb,strs := numbers() //只获取函数返回值的后两个
fmt.Println(numb,strs) // 结果为:2 str
}
//一个可以返回多个值的函数
func numbers()(int,int,string){
a , b , c := 1 , 2 , "str"
return a,b,c
}
三、常量
- 格式
const identifier [type] = value
// 可以省略类型说明符 [type],因为编译器会自行推断变量的类型
// 显示类型定义
const b string = "abc"
// 隐式类型定义
const b = "abc"
//多变量声明
const c_name1, c_name2 = value1, value2
- 枚举值:值的数量有限的数据,如性别、周几、月份、颜色等
- 常量可以用作枚举:
// 数字 0、1 和 2 分别代表未知性别、女性和男性。
const (
Unknown = 0
Female = 1
Male = 2
)
- 若要在常量表达式中使用函数进行计算,函数必须是内置函数
package main
import "unsafe"
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(a)
)
func main(){
println(a, b, c) // 结果为:abc 3 16
}
unsafe.sizeof()type StringHeader struct {
Data uintptr
Len int
}
- 在64位系统上 uintptr 和 int 都是8字节,加起来就16了。
iota
- iota 是一个特殊常量,可认为是一个能被编译器修改的常量
- iota 在 const 关键字出现时将被重置为 0,const 中每新增一行变量,iota 便会计数一次(iota 可理解为 const 语句块中的行索引)
- iota 可以被用作枚举值:
const (
a = iota
b = iota
c = iota
)
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const (
a = iota
b
c
)
- 实例
package main
import "fmt"
func main(){
const (
a = iota // 0
b // 1
c // 2
d = "阿巴阿巴" // 独立值,iota += 1
e // "阿巴阿巴",iota += 1
f = 100 // iota += 1
g // 100,iota += 1
h = iota // 7,恢复计数
i // 8
)
fmt.Println(a, b, c, d, e, f, g, h, i)
// 运行结果为:0 1 2 阿巴阿巴 阿巴阿巴 100 100 7 8
}
- 注意:在定义常量组时,如果不提供初始值,则表示使用上行的表达式。如:在这里的 e 和 g 没有被初始化,故使用上一行的值
- 实例2
package main
import "fmt"
const (
i=1<<iota // 表示1左移0位
j=3<<iota // 表示3左移1位
k
l
)
func main() {
fmt.Println("i=",i) // i=1:左移 0 位,不变仍为 1。
fmt.Println("j=",j) // j=3:左移 1 位,变为二进制 110,即 6。
fmt.Println("k=",k) // k=3:左移 2 位,变为二进制 1100,即 12。
fmt.Println("l=",l) // l=3:左移 3 位,变为二进制 11000,即 24。
}
- iota 表示从 0 开始自动加 1,所以 i=1<<0, j=3<<1(<< 表示左移的意思),即:i=1, j=6。注意 k 和 l 应该是 k=3<<2,l=3<<3。
四、运算符
位运算符
^A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
指针运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 返回变量存储地址 | &a :将给出变量的实际地址 |
| * | 指针变量 | *a :是一个指针变量 |
- 实例
package main
import "fmt"
func main() {
var n6 = 16
var ptr *int = &n6
fmt.Println("int 变量地址", &n6) // 0xc00000a0b8
fmt.Println("int 变量地址", ptr) // 0xc00000a0b8
fmt.Println("修改前的", *ptr) // 16
*ptr = 18
fmt.Println("修改后的", *ptr) // 18
}
- 注意:Go 的自增、自减只能作为表达式使用,而不能用于赋值语句
a++ // 这是允许的,类似 a = a + 1,结果与 a++ 相同
a-- //与 a++ 相似
b = a++ // 这是不允许的,会出现编译错误 syntax error: unexpected ++ at end of statement
五、条件语句
?:1、if 语句
获取输入
- Go 的 if 不需使用括号将条件包含起来
- Go 的 if 还有一个强大的地方就是条件判断语句里面允许声明一个变量,这个变量的作用域只能在该条件逻辑块内,其他地方就不起作用了,如下所示:
- 语法:
if statement; condition {
}
- 实例
package main
import "fmt"
func main() {
var s int;
fmt.Println("输入一个数字:")
fmt.Scan(&s)
if num := 9; num < s{
fmt.Println("9 < s")
} else {
fmt.Println("s ≥ 9")
}
}
- 应用:找到100以内的所有素数
package main
import "fmt"
func main(){
count := 1
var flag bool
//while(count < 100){...} // go 里没有 while
for count < 100{
count++
flag = true;
// 注意 temp 变量 :=
for temp:=2; temp < count; temp++ {
if count % temp == 0{
flag = false
}
}
if flag == true {
fmt.Println(count, "是素数")
}else {
continue
}
}
}
2、switch 语句
- 语法:
switch var1 {
case val1:
...
case val2:
...
default:
...
}
- 可以同时测试多个可能符合条件的值,使用逗号分割它们,例如:case val1, val2, val3。
Type Switch
- switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型。
- 语法:
switch x.(type){
case type:
statement(s);
case type:
statement(s);
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s);
}
- 实例
package main
import "fmt"
func main() {
var x interface{}
switch i := x.(type) {
case nil:
fmt.Printf(" x 的类型 :%T",i) // x 的类型 :<nil>
case int:
fmt.Printf("x 是 int 型")
case float64:
fmt.Printf("x 是 float64 型")
case func(int) float64:
fmt.Printf("x 是 func(int) 型")
case bool, string:
fmt.Printf("x 是 bool 或 string 型" )
default:
fmt.Printf("未知型")
}
}
fallthrough
- 使用 fallthrough 会强制执行后面的 case 语句,fallthrough 不会判断下一条 case 的表达式结果是否为 true。
- 实例:
package main
import "fmt"
func main() {
num := 2
switch {
case num == 1:
fmt.Println("这里是1号")
fallthrough
case num == 2:
fmt.Println("这里是2号")
fallthrough
case num == 3:
fmt.Println("这里是3号")
fallthrough
case num == 4:
fmt.Println("这里是4号")
case num == 5:
fmt.Println("这里是5号")
fallthrough
default:
fmt.Println("这里是6号")
}
}
- 运行结果:
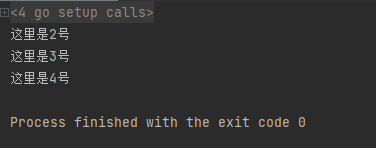
- 如果想要执行多个 case,需要使用 fallthrough 关键字,也可用 break 终止。
switch{
case 1:
...
if(...){
break
}
fallthrough // 此时switch(1)会执行case1和case2,但是如果满足if条件,则只执行case1
case 2:
...
case 3:
}
3、select 语句
- select 是 Go 中的一个控制结构,类似于用于通信的 switch 语句。每个 case 必须是一个通信操作,要么是发送要么是接收。
- select 随机执行一个可运行的 case。如果没有 case 可运行,它将阻塞,直到有 case 可运行。一个默认的子句应该总是可运行的。
语法
- 每个 case 都必须是一个通信
- 所有 channel 表达式都会被求值
- 所有被发送的表达式都会被求值
- 如果任意某个通信可以进行,它就执行,其他被忽略。
- 如果有多个 case 都可以运行,Select 会随机公平地选出一个执行。其他不会执行。否则:
- 如果有 default 子句,则执行该语句。
- 如果没有 default 子句,select 将阻塞,直到某个通信可以运行;Go 不会重新对 channel 或值进行求值。
- 实例:select 是随机执行的不是循环检测,是为了避免饥饿问题
package main
import (
"fmt"
"time"
)
func Chann(ch chan int, stopCh chan bool){
for j := 0; j < 10; j++ {
ch <- j
time.Sleep(time.Second)
}
stopCh <- true
}
func main(){
ch := make(chan int)
c := 0
stopCh := make(chan bool)
go Chann(ch, stopCh)
for {
select {
case c = <-ch:
fmt.Println("Receive C", c)
case s := <-ch:
fmt.Println("Receive S", s)
case _ = <-stopCh:
goto end
}
}
end:
}
- 运行结果:

六、循环语句
1、for 循环
- 语法
//1.和 C 语言的 for 一样:
/*
init: 一般为赋值表达式,给控制变量赋初值;
condition: 关系表达式或逻辑表达式,循环控制条件;
post: 一般为赋值表达式,给控制变量增量或减量。
*/
for init; condition; post { }
//2.和 C 的 while 一样:
for condition { }
//3.和 C 的 for(;;) 一样:
for { }
- 实例
//在 sum 小于 10 的时候计算 sum 自相加后的值:
package main
import "fmt"
func main() {
sum := 1
for ; sum <= 10; {
sum += sum
}
fmt.Println(sum)
// 这样写也可以,更像 While 语句形式
for sum <= 10{
sum += sum
}
fmt.Println(sum)
}
- 无限循环(按 ctrl + c 停止)
package main
import "fmt"
func main() {
sum := 0
for {
sum++ // 无限循环下去
}
fmt.Println(sum) // 无法输出
}
For-each range 循环
- 这种格式的循环用于对字符串、数组、切片等进行迭代输出元素
- 实例
package main
import "fmt"
func main() {
strings := []string{"google", "runoob"}
for i, s := range strings{
fmt.Println(i, s)
}
numbers := [6]int{1, 2, 3, 5}
for i, x := range numbers{
fmt.Printf("第 %d 位 x 的值 = %d\n", i ,x)
}
}
- 运行结果:

2、循环控制语句
2.1、break
- 作用:
- 用于循环语句中跳出循环,并开始执行循环之后的语句。
- break 在 switch(开关语句)中在执行一条 case 后跳出语句的作用。
- 在多重循环中,可以用标号 label 标出想 break 的循环。
- 使用标记和不使用标记的区别:
package main
import "fmt"
func main() {
// 不使用标记
fmt.Println("---- break ----")
for i := 1; i <= 3; i++ {
fmt.Printf("i: %d\n", i)
for i2 := 11; i2 <= 13; i2++ {
fmt.Printf("i2: %d\n", i2)
break
}
}
// 使用标记
fmt.Println("---- break label ----")
re:
for i := 1; i <= 3; i++ {
fmt.Printf("i: %d\n", i)
for i2 := 11; i2 <= 13; i2++ {
fmt.Printf("i2: %d\n", i2)
break re
}
}
}
- 运行结果为:
---- break ----
i: 1
i2: 11
i: 2
i2: 11
i: 3
i2: 11
---- break label ----
i: 1
i2: 11
2.2、continue
- 作用:
- 跳过当前循环执行下一次循环语句。
- for 循环中,执行 continue 语句会触发 for 增量语句的执行。
- 在多重循环中,可以用标号 label 标出想 continue 的循环。
- 使用标记和不使用标记的区别:
package main
import "fmt"
func main() {
// 不使用标记
fmt.Println("---- continue ---- ")
for i := 1; i <= 3; i++ {
fmt.Printf("i: %d\n", i)
for i2 := 11; i2 <= 13; i2++ {
fmt.Printf("i2: %d\n", i2)
continue
}
}
// 使用标记
fmt.Println("---- continue label ----")
re:
for i := 1; i <= 3; i++ {
fmt.Printf("i: %d\n", i)
for i2 := 11; i2 <= 13; i2++ {
fmt.Printf("i2: %d\n", i2)
continue re
}
}
}
- 运行结果:
---- continue ----
i: 1
i2: 11
i2: 12
i2: 13
i: 2
i2: 11
i2: 12
i2: 13
i: 3
i2: 11
i2: 12
i2: 13
---- continue label ----
i: 1
i2: 11
i: 2
i2: 11
i: 3
i2: 11
2.3、goto 语句
- 作用:
- 可以无条件地转移到过程中指定的行
- goto 语句通常与条件语句配合使用。可用来实现条件转移, 构成循环,跳出循环体等功能
- 在结构化程序设计中一般不主张使用 goto 语句, 以免造成程序流程的混乱,使理解和调试程序都产生困难。
- 实例:
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 10
/* 循环 */
LOOP: for a < 20 {
if a == 15 {
/* 跳过迭代 */
a = a + 1
goto LOOP
}
fmt.Printf("a的值为 : %d\n", a)
a++
}
}
- 运行结果:
a的值为 : 10
a的值为 : 11
a的值为 : 12
a的值为 : 13
a的值为 : 14
a的值为 : 16
a的值为 : 17
a的值为 : 18
a的值为 : 19
七、函数
1、定义
- 格式
func function_name( [parameter list] ) [return_types] {
函数体
}
- 解析:
- func:函数由 func 开始声明
- function_name:函数名称,参数列表和返回值类型构成了函数签名。
- parameter list:参数列表。可以没有
- return_types:返回类型。可以没有
- 实例:
//先变量名,再数据类型
/* 函数返回两个数的最大值 */
func max(num1, num2 int) int {
/* 声明局部变量 */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
2、值传递
- 传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
- 默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
- 实例:
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int = 200
fmt.Printf("交换前 a 的值为 : %d\n", a )
fmt.Printf("交换前 b 的值为 : %d\n", b )
/* 通过调用函数来交换值 */
swap(a, b)
fmt.Printf("交换后 a 的值 : %d\n", a )
fmt.Printf("交换后 b 的值 : %d\n", b )
}
/* 定义相互交换值的函数 */
func swap(x, y int) int {
var temp int
temp = x /* 保存 x 的值 */
x = y /* 将 y 值赋给 x */
y = temp /* 将 temp 值赋给 y*/
return temp;
}
- 运行结果:a 和 b 的值并没有互换
交换前 a 的值为 : 100
交换前 b 的值为 : 200
交换后 a 的值 : 100
交换后 b 的值 : 200
3、引用传递
- 引用传递是指在调用函数时,将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数
/* 定义交换值函数*/
func swap(x *int, y *int) {
var temp int
temp = *x /* 保持 x 地址上的值 */
*x = *y /* 将 y 值赋给 x */
*y = temp /* 将 temp 值赋给 y */
}
4、函数闭包
- 定义:Go 语言支持匿名函数,可作为闭包。匿名函数是一个"内联"语句或表达式。
- 匿名函数的优越性在于可以直接使用函数内的变量,不必申明。
- 以下实例中,我们创建了函数 getSequence() ,返回另外一个函数。该函数的目的是在闭包中递增 i 变量
package main
import "fmt"
func getSequence() func() int {
i:=0
return func() int {
i+=1
return i
}
}
func main(){
/* nextNumber 为一个函数,函数 i 为 0 */
nextNumber := getSequence()
/* 调用 nextNumber 函数,i 变量自增 1 并返回 */
fmt.Println(nextNumber())
fmt.Println(nextNumber())
fmt.Println(nextNumber())
/* 创建新的函数 nextNumber1,并查看结果 */
nextNumber1 := getSequence()
fmt.Println(nextNumber1())
fmt.Println(nextNumber1())
}
- 运行结果
1
2
3
1
2
- 实例2:
package main
import "fmt"
// 闭包使用方法,函数声明中的返回值(闭包函数)不用写具体的形参名称
func add(x1, x2 int) func(int, int) (int, int, int){
i := 0
return func(x3 int, x4 int) (int, int, int) {
i += 1
return i, x1 + x2, x3 + x4
}
}
func main() {
add_func := add(1, 2)
fmt.Println(add_func(4, 5))
fmt.Println(add_func(1, 3))
fmt.Println(add_func(2, 2))
}
- 运行结果
1 3 9
2 3 4
3 3 4
5、函数与结构体
- 实例:
package main
import "fmt"
// 定义结构体
type Circle struct {
radius float64
}
// 该 method 属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
func main() {
var c1 Circle
c1.radius = 10.00
fmt.Println("圆的面积 = ", c1.getArea()) // 314
}
八、变量作用域
1、全局变量
- 全局变量可以在整个包甚至外部包(被导出后)使用
2、局部变量
- 注意 for 循环中的局部变量
- 实例:
package main
import "fmt"
func main(){
var a int = 0
fmt.Println("for start")
for a:=0; a < 10; a++ {
fmt.Print(a)
}
fmt.Println("for end")
fmt.Println(a)
}
- 运行结果
for start
0 1 2 3 4 5 6 7 8 9
for end
0
- 在 for 循环的 initialize(a:=0) 中,此时 initialize 中的 a 与外层的 a 不是同一个变量,initialize 中的 a 为 for 循环中的局部变量,因此在执行完 for 循环后,输出 a 的值仍然为 0。
- 如果把 for 循环中的 a := 0 改为 a = 0,则最后返回的值会是 10 而不是 0
可以通过花括号来控制变量的作用域,花括号中的变量是段都的作用域,同名变量会覆盖外层
- 实例1
a := 5
{
a := 3
fmt.Println("in a = ", a)
}
fmt.Println("out a = ", a)
/*
输出:
in a = 3
out a = 5
*/
- 实例2
a := 5
{
fmt.Println("in a = ", a)
}
fmt.Println("out a = ", a)
/*
输出:
in a = 5
out a = 5
*/
- 实例3
a := 5
{
a := 3
fmt.Println("a = ", a)
}
/*
输出报错:
a declared and not used
*/
九、数组
1、一维数组
声明
- 格式:
var variable_name [SIZE] variable_type
//实例
var balance [10] float32
初始化
- 声明方式
var n [10]int // n 是一个长度为 10 的数组
var balance = [5]float32{1.0, 2.0, 3.0, 4.0, 5.0}
//等价于
balance := [5]float32{1.0, 2.0, 3.0, 4.0, 5.0}
- 如果数组长度不确定,可以使用 … 代替数组的长度,编译器会根据元素个数自行推断数组的长度:
var balance = [...]float32{1.0, 2.0, 3.0, 4.0, 5.0}
//等价于
balance := [...]float32{1.0, 2.0, 3.0, 4.0, 5.0}
- 如果设置了数组的长度,可以通过指定下标来初始化元素
// 将索引为 1 和 3 的元素初始化
balance := [5]float32{1:1.0, 3:3.0}
// 没有初始化的元素默认值为 0.0
2、二维数组
格式
var variable_name [SIZE1][SIZE2]...[SIZEN] variable_type
//实例
var threedim [5][10][4]int
- 实例
package main
import "fmt"
func main() {
// 1.创建数组
values := [][]int{}
// 2.使用 append() 函数向空的二维数组添加两行一维数组
row1 := []int{1, 2, 3}
row2 := []int{4, 5, 6}
values = append(values, row1)
values = append(values, row2)
// 3.显示两行数据
fmt.Println("Row 1")
fmt.Println(values[0])
fmt.Println("Row 2")
fmt.Println(values[1])
// 4.访问第一个元素
fmt.Println("第一个元素为:")
fmt.Println(values[0][0])
}
- 运行结果:
Row 1
[1 2 3]
Row 2
[4 5 6]
第一个元素为:
1
初始化
a := [3][4]int{
{0, 1, 2, 3} , /* 第一行索引为 0 */
{4, 5, 6, 7} , /* 第二行索引为 1 */
{8, 9, 10, 11}, /* 第三行索引为 2 */
}
- 注意:以上代码中倒数第二行的 } 必须要有逗号,因为最后一行的 } 不能单独一行,也可以写成这样:
a := [3][4]int{
{0, 1, 2, 3} , /* 第一行索引为 0 */
{4, 5, 6, 7} , /* 第二行索引为 1 */
{8, 9, 10, 11}} /* 第三行索引为 2 */
- 注意:多维数组初始化或赋值时需要注意 Go 语法规范,该写在一行就写在一行,一行一条语句。如上面的最好不用分行写
- range 方式循环二维数组
package main
import "fmt"
func main() {
arr := [...][]int{
{1, 2, 3, 4},
{10, 20, 30, 40},
}
for i := range arr{
for j := range arr[i] {
fmt.Println(arr[i][j])
}
}
}
十、指针
1、定义
格式
var var_name *var-type
//实例
var ip *int /* 指向整型*/
var fp *float32 /* 指向浮点型 */
使用
- 在指针类型前面加上 * 号(前缀)来获取指针所指向的内容。
package main
import "fmt"
func main() {
var a int= 20 /* 声明实际变量 */
var ip *int /* 声明指针变量 */
ip = &a /* 指针变量的存储地址 */
fmt.Printf("a 变量的地址是: %x\n", &a )
/* 指针变量的存储地址 */
fmt.Printf("ip 变量储存的指针地址: %x\n", ip )
/* 使用指针访问值 */
fmt.Printf("*ip 变量的值: %d\n", *ip )
}
- 运行结果
a 变量的地址是: c00000a0b8
ip 变量储存的指针地址: c00000a0b8
*ip 变量的值: 20
2、空指针
- 当一个指针被定义后没有分配到任何变量时,它的值为 nil。
- nil 指针也称为空指针。
- nil 指代零值或空值
- 实例:
package main
import "fmt"
func main() {
var ptr *int
fmt.Printf("ptr 的值为 : %x\n", ptr ) // 0
}
- 空指针判断
if(ptr != nil) /* ptr 不是空指针 */
if(ptr == nil) /* ptr 是空指针 */
3、指针数组
- 实例
package main
import "fmt"
const MAX int = 3
func main() {
a := []int{10, 100, 200}
var i int
var ptr [MAX]*int
for i = 0; i < MAX; i++ {
ptr[i] = &a[i] // 整数地址赋值给指针数组
}
for i = 0; i < MAX; i++ {
fmt.Printf("a[%d] = %d\n", i, *ptr[i])
}
}
- 运行结果
a[0] = 10
a[1] = 100
a[2] = 200
指针数组与 range 的结合
实例1
package main
import "fmt"
const max = 3
func main() {
number := [max]int{5, 6, 7}
var ptrs [max]*int //指针数组
//将number数组的值的地址赋给ptrs
for i, x := range &number {
ptrs[i] = &x
}
for i, x := range ptrs{
fmt.Printf("指针数组:索引:%d ,值:%d 值的内存地址为:%d\n", i, *x, x)
}
}
- 运行结果
指针数组:索引:0 ,值:7 值的内存地址为:824634417240
指针数组:索引:1 ,值:7 值的内存地址为:824634417240
指针数组:索引:2 ,值:7 值的内存地址为:824634417240
- 原因:
- 在这里x是作为一个临时变量,仅被声明一次,此后都是将迭代 &number 出的值赋值给 x,而 x 变量的内存地址始终未变,故再将 x 的地址发送给 ptrs 数组,自然结果也是相同的
实例2
- 正确方法应如下:也可以直接用一个数组指针
package main
import "fmt"
const max = 3
func main() {
number := [max]int{5, 6, 7}
var ptrs [max]*int //指针数组
var p *[3]int = &number //数组指针
for i, _ := range &number {
ptrs[i] = &number[i]
}
// 输出地址比对
for i := 0; i < 3; i++ {
fmt.Println(&number[i], ptrs[i], &(*p)[i])
}
}
- 运行结果:
0xc0000ae078 0xc0000ae078 0xc0000ae078
0xc0000ae080 0xc0000ae080 0xc0000ae080
0xc0000ae088 0xc0000ae088 0xc0000ae088
4、指向指针的指针
- 当定义一个指向指针的指针变量时,第一个指针存放第二个指针的地址,第二个指针存放变量的地址:

- 格式:
var ptr **int;
- 实例
package main
import "fmt"
func main() {
var a int
var ptr *int
var pptr **int
a = 3000
// 指针 ptr 地址
ptr = &a
// 指向指针 ptr 地址
pptr = &ptr
// 获取 pptr 的值
fmt.Printf("变量 a = %d\n", a)
fmt.Printf("指针变量 *ptr = %d\n", *ptr)
fmt.Printf("指向指针的指针变量 **pptr = %d\n", **pptr)
}
- 运行结果
变量 a = 3000
指针变量 *ptr = 3000
指向指针的指针变量 **pptr = 3000
十一、结构体
定义
- 格式
type name struct {
member definition
member definition
...
member definition
}
- 实例
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
// 创建一个新的结构体
fmt.Println(Books{"Go 语言", "www.runoob.com", "Go 语言教程", 6495407})
// 也可以使用 key => value 格式
fmt.Println(Books{title: "Go 语言", author: "www.runoob.com", subject: "Go 语言教程", book_id: 6495407})
// 忽略的字段为 0 或 空
fmt.Println(Books{title: "Go 语言", author: "www.runoob.com"})
}
- 运行结果
{Go 语言 www.runoob.com Go 语言教程 6495407}
{Go 语言 www.runoob.com Go 语言教程 6495407}
{Go 语言 www.runoob.com 0}
访问结构体成员
结构体.成员名package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books // 声明 Book1 为 Books 类型
// book1 描述
Book1.title = "Go 语言"
Book1.author = "www.runoob.com"
Book1.subject = "Go 语言教程"
Book1.book_id = 6495407
// 打印 Book1 信息
fmt.Printf( "Book title : %s\n", Book1.title)
fmt.Printf( "Book author : %s\n", Book1.author)
fmt.Printf( "Book subject : %s\n", Book1.subject)
fmt.Printf( "Book book_id : %d\n", Book1.book_id)
}
结构体作为函数参数
package main
import "fmt"
type Books struct {
title string
author string
subject string
book_id int
}
func main() {
var Book1 Books // 声明 Book1 为 Books 类型
// book1 描述
Book1.title = "Go 语言"
Book1.author = "www.runoob.com"
Book1.subject = "Go 语言教程"
Book1.book_id = 6495407
// 打印 Book1 信息
printBook(Book1)
}
func printBook( book Books ) {
fmt.Printf( "Book title : %s\n", book.title)
fmt.Printf( "Book author : %s\n", book.author)
fmt.Printf( "Book subject : %s\n", book.subject)
fmt.Printf( "Book book_id : %d\n", book.book_id)
}
结构体指针
- 格式:
//定义指向结构体的指针
var struct_pointer *Books
//查看结构体变量地址
struct_pointer = &Book1
//使用结构体指针访问结构体成员
struct_pointer.title
- 实例1
- 尽管 b 所表示的是 Book1 对象的内存地址,但是,在从 b 对应的内存地址取属性值的时候,就不是 *b.title 了。而是直接使用b.title,这点很特殊,它的效果就相当于 Book1.title:
type Books struct {
title string
author string
subject string
book_id int
}
var book1 = Books {"Go 入门到放弃","yuantiankai","go系列教程",6495407}
var b *Books
b = &Book1
fmt.Println(b) //&{Go 语言 www.runoob.com Go 语言教程 6495407}
fmt.Println(*b) //{Go 语言 www.runoob.com Go 语言教程 6495407}
fmt.Println(&b) //0xc000082018
fmt.Println(Book1) //{Go 语言 www.runoob.com Go 语言教程 6495407}
- 实例2
package main
import "fmt"
type Rect struct { //定义矩形类
x, y float64 //类型只包含属性,并没有方法
width, height float64
}
func (r *Rect) GetArea() float64 { //为Rect类型绑定Area的方法,*Rect为指针引用可以修改传入参数的值
return r.width * r.height //方法归属于类型,不归属于具体的对象,声明该类型的对象即可调用该类型的方法
}
func main() {
var rect Rect
rect.width = 10
rect.height = 20
fmt.Println(rect.GetArea())
}
注意事项
- 当结构体作为参数的值传递时,若想修改结构体本身的值,需要传入指针
func changeBook(book Books) {
book.title = "book1_change"
}
func main() {
var book1 Books
book1.title = "book1"
changeBook(book1)
fmt.Println(book1)
}
// 结果仍为 {book1 ...}
- 修改为如下
func changeBook(book *Books) {
book.title = "book1_change"
}
//结果便为{book1_change ...}
- 结构体中属性的首字母大小写问题
- 首字母大写相当于 public
- 首字母小写相当于 private
- 定义的结构体如果只在当前包内使用,结构体的属性不用区分大小写。如果想要被其他的包引用,那么结构体的属性的首字母需要大写。
- 当要将结构体对象转换为 JSON 时,对象中的属性首字母必须是大写,才能正常转换为 JSON。
// 示例一:
// 输出:{"Name":"小明"} //只有Name,没有age
type Person struct {
Name string //Name字段首字母大写
age int //age字段首字母小写
}
func main() {
person:=Person{"小明",18}
if result,err:=json.Marshal(&person);err==nil{ //json.Marshal 将对象转换为json字符串
fmt.Println(string(result))
}
}
// 示例二:
// 输出:{"Name":"小明","Age":18} // 两个字段都有
type Person struct{
Name string //都是大写
Age int
}
// 示例三:使用 tag 标记要返沪的字段名,就可以小写
// 输出:{"name":"小明","age":18}
type Person struct{
Name string `json:"name"` //标记json名字为name
Age int `json:"age"`
Time int64 `json:"-"` // 标记忽略该字段
}
func main(){
person:=Person{"小明",18, time.Now().Unix()}
if result,err:=json.Marshal(&person);err==nil{
fmt.Println(string(result))
}
}
十二、切片(Slice)
1、定义
- Go 语言切片是对数组的抽象,Go 数组的长度不可改变。
- 切片可以理解为 “动态数组”,与数组相比,切片的长度是不固定的,可以追加元素
格式
var identifier []type
// 实例
//这里的 len 是数组的长度并且也是切片的初始长度
var slice1 []type = make([]type, len)
//等价于
slice1 := make([]type, len)
//也可以指定容量,其中 capacity 为可选参数
make([]type, length, capacity)
2、初始化
// 1.直接初始化:[] 表示切片类型,其 cap=len=3
s :=[]int {1,2,3 }
// 2.将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片。
s := arr[startIndex:endIndex]
// 默认 endIndex 时将表示一直到arr的最后一个元素。
s := arr[startIndex:]
// 默认 startIndex 时将表示从 arr 的第一个元素开始。
s := arr[:endIndex]
// 3.通过切片 s 初始化切片 s1。
s1 := s[startIndex:endIndex]
// 4.通过内置函数 make() 初始化切片s,[]int 标识为其元素类型为 int 的切片。
s :=make([]int,len,cap)
3、len() 和 cap() 函数
- len() 方法获取长度
- cap() 方法可以测量切片最长可以达到多少
- 实例
package main
import "fmt"
func printSlice(x []int){
fmt.Printf("len = %d ,cap = %d ,slice = %v\n", len(x), cap(x), x)
}
func main() {
var numbers = make([]int, 3, 5)
printSlice(numbers)
}
- 运行结果
len=3 cap=5 slice=[0 0 0]
4、空(nil)切片
- 一个切片在未初始化之前默认为 nil,长度为 0
- 实例
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
if(numbers == nil){
fmt.Printf("切片是空的")
}
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
- 运行结果
len=0 cap=0 slice=[]
切片是空的
5、切片截取
- 可以通过设置下限及上限来设置截取切片 [lower-bound:upper-bound]
- 前开后闭,如 numbers[1:4] 表示 numbers[1]、[2]、[3]
- 默认下限为 0
- 默认上限为 len(s)
6、append() 和 copy() 函数
- 如果想增加切片的容量,我们必须创建一个新的更大的切片并把原分片的内容都拷贝过来
- copy 方法:拷贝切片
- append 方法:向切片追加新元素
- 实例
package main
import "fmt"
func printSlice(x []int){
fmt.Printf("len = %d ,cap = %d ,slice = %v\n", len(x), cap(x), x)
}
func main() {
var numbers []int
printSlice(numbers)
// 允许追加空切片
numbers = append(numbers, 0)
printSlice(numbers)
// 向切片添加一个元素
numbers = append(numbers, 1)
printSlice(numbers)
// 同时添加多个元素
numbers = append(numbers, 2, 3, 4)
printSlice(numbers)
// 创建切片 numbers1,是之前切片的两倍容量
numbers1 := make([]int, len(numbers), (cap(numbers)*2))
// 拷贝 numbers 的内容到 numbers1
copy(numbers1, numbers)
printSlice(numbers1)
}
- 运行结果:
len = 0 ,cap = 0 ,slice = []
len = 1 ,cap = 1 ,slice = [0]
len = 2 ,cap = 2 ,slice = [0 1]
len = 5 ,cap = 6 ,slice = [0 1 2 3 4]
len = 5 ,cap = 12 ,slice = [0 1 2 3 4]
- len切片<=cap切片<=len数组
- 切片由三部分组成:指向底层数组的指针、len、cap。
基于原数组或者切片创建一个新的切片后,新的切片的大小和容量
- 公式:对于底层数组容量是 k 的切片 slice[i:j] 来说:
长度: j-i
容量: k-i
- 实例
package main
import "fmt"
func printSlice1(x []int){
fmt.Printf("len = %d ,cap = %d ,slice = %v\n", len(x), cap(x), x)
}
func main() {
numbers := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
number1 := make([]int, 0, 5)
number2 := numbers[:3]
number3 := numbers[2:5]
number4 := numbers[3:8]
printSlice1(number1)
printSlice1(number2)
printSlice1(number3)
printSlice1(number4)
}
- 运行结果:
len = 0 ,cap = 5 ,slice = []
len = 3 ,cap = 11 ,slice = [0 1 2]
len = 3 ,cap = 9 ,slice = [2 3 4]
len = 5 ,cap = 8 ,slice = [3 4 5 6 7]
7、函数调用
- 在做函数调用时,slice 按引用传递,array 按值传递:
- 实例
package main
import "fmt"
func main(){
changeSliceTest()
}
func changeSliceTest() {
arr1 := []int{1, 2, 3}
arr2 := [3]int{1, 2, 3}
arr3 := [3]int{1, 2, 3}
fmt.Println("before change arr1, ", arr1)
changeSlice(arr1) // slice 按引用传递
fmt.Println("after change arr1, ", arr1)
fmt.Println("before change arr2, ", arr2)
changeArray(arr2) // array 按值传递
fmt.Println("after change arr2, ", arr2)
fmt.Println("before change arr3, ", arr3)
changeArrayByPointer(&arr3) // 可以显式取array的 指针
fmt.Println("after change arr3, ", arr3)
}
func changeSlice(arr []int) {
arr[0] = 9999
}
func changeArray(arr [3]int) {
arr[0] = 6666
}
func changeArrayByPointer(arr *[3]int) {
arr[0] = 6666
}
- 输出结果:
before change arr1, [1 2 3]
after change arr1, [9999 2 3]
before change arr2, [1 2 3]
after change arr2, [1 2 3]
before change arr3, [1 2 3]
after change arr3, [6666 2 3]
8、append() 获取的新切片的容量
- 当append(list, [params]),先判断 list 的 cap 长度是否大于等于 len(list) + len([params]),如果大于那么 cap 不变,否则 cap = 2 * max{cap(list), cap[params]}
- 即如果添加一次,添加多个值且添加后的长度大于扩容一次的大小,容量和长度相等,等到下次添加内容时如果不超过扩容大小,在现在的基础上进行翻倍
- 示例
package main
import "fmt"
func printSlice2(x []int){
fmt.Printf("len = %d ,cap = %d ,slice = %v\n", len(x), cap(x), x)
}
func main() {
s := make([]int, 0)
printSlice2(s)
s = append(s, 1)
printSlice2(s)
s = append(s, 2)
printSlice2(s)
s = append(s, 3)
printSlice2(s)
s = append(s, 4, 5)
printSlice2(s)
s = append(s, 6, 7, 8)
printSlice2(s)
s = append(s, 9)
printSlice2(s)
}
9、copy 函数注意事项
- 对于 copy(slice1, slice),要初始化 slice1 的 size,否则无法复制。
- 错误案例:
slice1 := make([]int, 0)
slice := []int{1, 2, 3}
copy(slice1, slice)
printSlice(slice)
printSlice(slice1)
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
- 运行结果:
len=3 cap=3 slice=[1 2 3]
len=0 cap=0 slice=[]
- 正确示例:
slice1 := make([]int, 3)
10、切片内部结构
struct Slice
{
byte* array; // actual data
uintgo len; // number of elements
uintgo cap; // allocated number of elements
};
unsafe.Sizeof24十三、范围(Range)
定义
- Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。
- 在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
实例
package main
import "fmt"
func main() {
//使用 range 去求一个 slice 的和,使用数组跟这个类似
nums := []int{2, 3, 4}
sum := 0
for _, num := range nums{
sum += num
}
fmt.Println(sum)
//在数组上使用 range 将传入 index 和值两个变量。上面的例子中不需要使用序号,
//所以用空白符"_"代替了。需要的话就如下:
for i, num := range nums{
if num == 3 {
fmt.Println("index: ", i)
}
}
//range 也可以用于 map 的键值对上
kvs := map[string]string{"a":"apple", "b":"banana"}
for k, v := range kvs {
fmt.Printf("%s -> %s\n", k, v)
}
//range 也可以用于枚举 Unicode 字符串。第一个参数是字符的索引,
//第二个是字符(Unicode的值)本身
for i, c := range "go" {
fmt.Println(i, c)
}
}
- 运行结果

十四、Map(集合)
定义
- Map 是一种无序的键值对的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
- Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,因为 Map 是使用 hash 表来实现的,所以 Map 是无序的,我们也无法决定它的返回顺序
声明
// 声明变量,默认 map 是 nil
var map_variable map[key_data_type]value_data_type
// 使用 make 函数
map_variable := make(map[key_data_type]value_data_type)
- 如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对
实例
package main
import "fmt"
func main() {
// 创建集合
//var countryCapitalMap map[string]string
//countryCapitalMap = make(map[string]string)
// 等价于
countryCapitalMap := make(map[string]string)
// map 插入 key-value 对,各个国家对应的首都
countryCapitalMap["France"] = "巴黎"
countryCapitalMap["Italy"] = "罗马"
countryCapitalMap["Japan"] = "东京"
countryCapitalMap["India"] = "新德里"
// 使用键遍历输出地图值
for country := range countryCapitalMap{
fmt.Println(country, "首都是:", countryCapitalMap[country])
}
// 查看元素在集合中是否存在
// 存在则ok值为true,否则为false
capital, ok := countryCapitalMap["American"]
fmt.Println(capital)
fmt.Println(ok)
if ok {
fmt.Println("American 的首都是:", capital)
} else {
fmt.Println("American 的首都不存在")
}
}
- 运行结果

delete() 函数
- 删除的实例
package main
import "fmt"
func main() {
// 创建 map
countryCapitalMap := map[string]string{
"France": "Paris",
"Italy": "Rome",
"Japan": "Tokyo",
"India": "New delhi",
}
fmt.Println("原始地图")
// 打印 map
for country := range countryCapitalMap {
fmt.Println(country, "的首都是:", countryCapitalMap[country])
}
// 删除元素
delete(countryCapitalMap, "France")
fmt.Println("法国条目被删除后的地图")
// 打印 map
for country := range countryCapitalMap {
fmt.Println(country, "的首都是:", countryCapitalMap[country])
}
}
- 运行结果

十五、递归函数
定义
- 使用递归时,需要设置退出条件,否则递归将陷入无限循环
- 格式
func recursion() {
recursion() /* 函数调用自身 */
}
func main() {
recursion()
}
阶乘
package main
import "fmt"
func Factorial(n uint64) (result uint64) {
if n > 0 {
result = n * Factorial(n-1)
return result
}
return 1
}
func main() {
i := 10
fmt.Printf("%d 的阶乘是 %d\n", i, Factorial(uint64(i)))
}
斐波那契数列
package main
import "fmt"
func fibonacci(n int) int {
if n < 2 {
return n
}
return fibonacci(n-1) + fibonacci(n-2)
}
func main() {
for i := 0; i < 10; i++ {
fmt.Printf("%d\t", fibonacci(i))
}
}
十六、类型转换
格式
//type_name 为类型,expression 为表达式
type_name(expression)
- 实例
package main
import "fmt"
func main() {
sum := 17
count := 5
var mean float32
mean = float32(sum) / float32(count)
fmt.Printf("mean 的值为:%f\n", mean)
}
- 运行结果
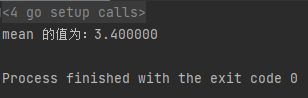
Go 不支持隐式转换类型
//错误案例
var a int64 = 3
var b int32
b = a
//正确示范
b = int32(a)
补充
package main
import (
"fmt"
"strconv"
)
func main(){
//String和其他基本数据类型转换
//(1)Sprintf
sprintf := fmt.Sprintf("%6.2f", 10.0)
fmt.Println(sprintf)
//(2)函数strconv
//base 相当于几进制
formatInt := strconv.FormatInt(100, 3)
fmt.Println(formatInt)
var f float64 = 10.2
//第二个表示转换成 float 类型,第三个表示保留几位,第四个表示 float64
float := strconv.FormatFloat(f, 'f', 5, 64)
fmt.Println(float)
//string 转基本数据类型 int,若错误,则直接变成0(默认值)
var str string = "hello"
parseInt, err := strconv.ParseInt(str, 10, 64)
fmt.Println(parseInt)
if err == nil {
fmt.Println(parseInt)
}
}
十七、接口
- Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。
格式
/* 定义接口 */
type interface_name interface {
method_name1 [return_type]
method_name2 [return_type]
method_name3 [return_type]
...
method_namen [return_type]
}
/* 定义结构体 */
type struct_name struct {
/* variables */
}
/* 实现接口方法 */
func (struct_name_variable struct_name) method_name1() [return_type] {
/* 方法实现 */
}
...
func (struct_name_variable struct_name) method_namen() [return_type] {
/* 方法实现*/
}
案例
package main
import "fmt"
type Phone interface {
call()
}
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {
fmt.Println("I am Nokia, I can call you")
}
type IPhone struct {
}
func (iPhone IPhone) call() {
fmt.Println("I am iPhone, I can call you too!")
}
func main() {
var phone Phone
phone = new(NokiaPhone)
phone.call()
phone = new(IPhone)
phone.call()
}
- 上面例子中,定义了一个接口 Phone,接口里有一个方法 call(),NokiaPhone 和 IPhone 分别实现了这个方法。
- 然后我们在 main 函数里定义了一个 Phone 类型变量,并分别为之赋值为 NokiaPhone 和 IPhone,然后各自调用 call() 方法
- 运行结果
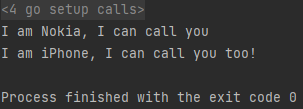
带参数的实现
package main
import "fmt"
type Animal interface {
eat()
}
type Cat struct {
name string
}
func (cat Cat) eat() {
fmt.Println(cat.name, "猫吃东西")
}
type Dog struct {
}
func (dog Dog) eat() {
fmt.Println("狗吃东西")
}
func main() {
var animal1 Animal = Cat{"加菲"}
var animal2 Animal = Dog{}
animal1.eat() // 加菲猫吃东西
animal2.eat() // 狗吃东西
}
十八、错误处理
- Go 语言通过内置的错误接口提供了非常简单的错误处理机制
- error 类型是一个接口类型,定义格式如下:
type error interface {
Error() string
}
- 可以在编码中通过实现 error 接口类型来生成错误信息
- 函数通常在最后的返回值中,使用 errors.New 来返回错误信息。
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
- 在下面的例子中,我们在调用 Sqrt 的时候传递了一个负数,然后就得到了 non-nil 的 error 对象,将此对象与 nil 比较,结果为 true,所以 fmt.Println ( fmt 包在处理 error 时会调用 Error 方法) 被调用,以输出错误
实例
package main
import "fmt"
// 定义一个 DivideError 结构
type DivideError struct {
dividee int
divider int
}
// 实现 error 接口
func (de *DivideError) Error() string {
strFormat := `
Cannot proceed, the divider is zero.
dividee: %d
divider: 0
`
return fmt.Sprintf(strFormat, de.dividee)
}
// 定义 int 类型除法运算的函数
func Divide(varDividee int, varDivider int) (result int, errorMsg string) {
if varDivider == 0 {
dData := DivideError{dividee: varDividee, divider: varDivider}
errorMsg = dData.Error()
return
} else {
return varDividee / varDivider, ""
}
}
func main() {
//正常情况
if result, errorMsg := Divide(100, 10); errorMsg == "" {
fmt.Println("100 / 10 = ", result)
}
//当除数为零的时候会返回错误信息
if _, errorMsg := Divide(100, 0); errorMsg != "" {
fmt.Println("errorMsg is:", errorMsg)
}
}
- 运行结果

fmt.Println 打印结构体的时候,会把其中的 error 的返回的信息打印出来。
package main
import "fmt"
type User struct {
username string
password string
}
func (p *User) Error() string {
return "Error: username or password shouldn't be empty!"
}
func (p *User) init(username string, password string) (*User, string) {
if username=="" || password=="" {
return p, p.Error()
}
p.username = username
p.password = password
return p, ""
}
func main() {
var user User
usertest1, _ := user.init("", "")
usertest2, _ := user.init("张三", "zhangsan")
fmt.Println(usertest1)
fmt.Println(usertest2)
}
- 运行结果

十九、并发
1、Go 并发
- Go 语言支持并发,通过 go 关键字来开启一个新的运行期线程,即 goroutine,以一个不同的、新创建的 goroutine 来执行一个函数
- 同一个程序中的所有 goroutine 共享同一个地址空间
- goroutine 是轻量级线程,goroutine 的调度是由 Golang 运行时进行管理的。
格式
go 函数名(参数列表)
// 实例
go f(x, y, z)
实例
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("hello")
say("world")
}
- 运行结果:输出的 hello 和 world 是没有固定先后顺序,因为它们是两个 goroutine 在执行。

2、通道(channel)
2.1、基础知识
<-ch <- v // 把 v 发送到通道 ch
v := <-ch // 从 ch 接收数据,并把值赋给 v
chanch := make(chan int)
- 注意:通道默认是不带缓冲区的。故发送端发送数据,同时必须有接收端相应的接收数据
- 实例:注意 x 是等于 5,先进后出
package main
import "fmt"
func sum(s []int, c chan int){
sum := 0
for _, v := range s {
sum += v
}
c <- sum // 把 sum 发送到通道 c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // 从通道 c 中接收
fmt.Println(x, y, x+y) // 结果为:-5 17 12
}
2.2、通道缓冲区
- 通道可以设置缓冲区,通过 make 的第二个参数指定缓冲区大小:
ch := make(chan int, 100)
- 带缓冲区的通道允许 发送端的数据发送 和 接收端的数据获取 处于异步状态,就是说发送端发送的数据可以放在缓冲区里面,等待接收端去获取数据,而不是立刻需要接收端去获取数据。
- 由于缓冲区大小有限,若是缓冲区满了,数据发送端就无法再发送数据
- 注意:
- 如果通道无缓存,发送方会阻塞直到接收方从通道中接收了值。
- 如果通道带缓存,发送方会阻塞直到发送的值被拷贝到缓冲区。
- 如果缓冲区已满,发送方会阻塞直到某个接收方获取到一个值,而接收方在有值可以接收之前会一直阻塞。
package main
import "fmt"
func main() {
// 这里我们定义了一个可以存储整数类型的带缓存通道
// 缓冲区大小为2
ch := make(chan int, 2)
// 因为 ch 是带缓冲的通道,我们可以同时发送两个数据
// 而不需要立刻去同步读取数据
ch <- 1
ch <- 2
// 获取这两个数据
fmt.Println(<-ch) // 1
fmt.Println(<-ch) // 2
}
2.3、Go 遍历通道与关闭通道
- Go 通过 range 关键字来实现遍历通道读取到的数据,类似于数组或切片
v, ok := <- ch
close()package main
import "fmt"
func Fibonacci(n int, c chan int) {
x, y := 0, 1
for i := 0; i < n; i++ {
c <- x
x, y = y, x+y
}
close(c)
}
func main() {
c := make(chan int, 10)
go Fibonacci(cap(c), c)
/*
range 函数遍历每个从通道接收到的数据,因为 c 在发送完10个数据之后就关闭了通道,
所以这里的 range 函数在接收到 10 个数据之后就会结束了。如果上面的 c 通道不关,
那么 range 函数就不会结束,从而在接收第 11 个数据的时候就阻塞了
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
*/
for i := range c {
fmt.Println(i)
}
}
- 运行结果:0 1 1 2 3 5 8 13 21 34
2.4、补充
- 关闭通道并不会丢失里面的数据,只是让读取通道数据的时候,不会读完之后一直阻塞等待新数据写入
- Channel 可以控制读写的权限
go func(c chan int) { //读写均可的channel c } (a)
go func(c <- chan int) { //只读的Channel } (a)
go func(c chan <- int) { //只写的Channel } (a)