
背景:
golang的interface是一种satisfied式的。A类只要实现了IA interface定义的方法,A就satisfied了接口IA。更抽象一层,如果某些设计上需要一些更抽象的共性,比如print各类型,这时需要使用reflect机制,reflect实质上就是将interface的实现暴露了一部分给应用代码。要理解reflect,需要深入了解interface。go的interface是一种隐式的interface,但golang的类型是编译阶段定的,是static的,如:
type MyInt int var i int var j MyInt
虽然MyInt底层就是int,但在编译器角度看,i的类型是int,j的类型是MyInt,是静态、不一致的。两者要赋值必须要进行类型转换。即使是interface,就语言角度来看也是静态的。如:
var r io.Reader
不管r后面用什么来初始化,它的类型总是io.Reader。更进一步,对于空的interface,也是如此。记住go语言类型是静态这一点,对于理解interface/reflect很重要。看一例:
var r io.Reader
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
return nil, err
}
r = tty
到这里,r的类型是什么?r的类型仍然是interface io.Reader,只是r = tty这一句,隐含了一个类型转换,将tty转成了io.Reader。
interface的实现:
作为一门编程语言,对方法的处理一般分为两种类型:一是将所有方法组织在一个表格里,静态地调用(C++, java);二是调用时动态查找方法(python, smalltalk, js)。而go语言是两者的结合:虽然有table,但是是需要在运行时计算的table。如下例:Binary类实现了两个方法,String()和Get()
type Binary uint64
func (i Binary) String() string {
return strconv.Uitob64(i.Get(), 2)
}
func (i Binary) Get() uint64 {
return uint64(i)
}
因为它实现了String(),按照golang的隐式方法实现来看,Binary satisfied了Stringer接口。因此它可以赋值: s:=Stringer(b)。以此为例来说明下interface的实现:interface的内存组织如图:
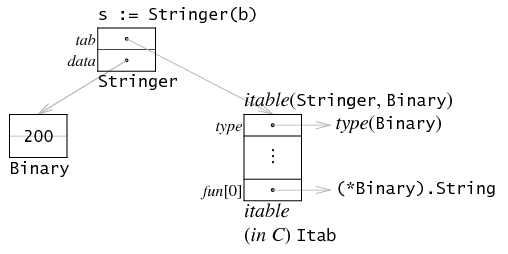
一个interface值由两个指针组成,第一个指向一个interface table,叫 itable。itable开头是一些描述类型的元字段,后面是一串方法。注意这个方法是interface本身的方法,并非其dynamic value(Binary)的方法。即这里只有String()方法,而没有Get方法。但这个方法的实现肯定是具体类的方法,这里就是Binary的方法。
当这个interface无方法时,itable可以省略,直接指向一个type即可。
另一个指针data指向dynamic value的一个拷贝,这里则是b的一份拷贝。也就是,给interface赋值时,会在堆上分配内存,用于存放拷贝的值。
同样,当值本身只有一个字长时,这个指针也可以省略。
一个interface的初始值是两个nil。比如,
var w io.Writer
这时,tab和data都是nil。interface是否为nil取决于itable字段。所以不一定data为nil就是nil,判断时要额外注意。
这样,像这样的代码:
switch v := any.(type) {
case int:
return strconv.Itoa(v)
case float:
return strconv.Ftoa(v, 'g', -1)
}
实际上是any这个interface取了 any. tab->type。
而interface的函数调用实际上就变成了:
s.tab->fun[0](s.data)itable的生成:
itable的生成是理解interface的关键。
如刚开始处提的,为了支持go语言这种接口间仅通过方法来联系的特性,是没有办法像C++一样,在编译时预先生成一个method table的,只能在运行时生成。因此,自然的,所有的实体类型都必须有一个包含此类型所有方法的“类型描述符”(type description structure);而interface类型也同样有一个类似的描述符,包含了所有的方法。
这样,interface赋值时,计算interface对象的itable时,需要对两种类型的方法列表进行遍历对比。如后面代码所示,这种计算只需要进行一次,而且优化成了O(m+n)。
可见,interface与itable之间的关系不是独立的,而是与interface具体的value类型有关。即(interface类型, 具体类型)->itable。
var any interface{} // initialized elsewhere
s := any.(Stringer) // dynamic conversion
for i := 0; i < 100; i++ {
fmt.Println(s.String())
}
itable的计算不需要到函数调用时进行,只需要在interface赋值时进行即可,如上第2行,不需要在第4行进行。
最后,看一些实现代码:
以下是上面图中的两个字段。
type iface struct {
tab *itab // 指南itable
data unsafe.Pointer // 指向真实数据
}
再看itab的实现:
type itab struct {
inter *interfacetype
_type *_type
link *itab
bad int32
unused int32
fun [1]uintptr // variable sized
}
可见,它使用一个疑似链表的东西,可以猜这是用作hash表的拉链。前两个字段应该是用来表达具体的interface类型和实际拥有的值的类型的,即一个itable的key。(上文提到的(interface类型, 具体类型) )
type imethod struct {
name nameOff
ityp typeOff
}
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
interfacetype如有若干imethod,可以猜想这是表达interface定义的方法数据结构。
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
对于_type,可见里面有gc的东西,应该就是具体的类型了。这里有个hash字段,itable实现就是挂在一个全局的hash table中。hash时用到了这个字段:
func itabhash(inter *interfacetype, typ *_type) uint32 {
// compiler has provided some good hash codes for us.
h := inter.typ.hash
h += 17 * typ.hash
// TODO(rsc): h += 23 * x.mhash ?
return h % hashSize
}
可见,这里有个把interface类型与具体类型之间的信息结合起来做一个hash的过程,这个hash就是上述的itab的存储地点,itab中的link就是hash中的拉链。
回到itab,看取一个itab的逻辑:
如果发生了typeassert或是interface的赋值(强转),需要临时计算一个itab。这时会先在hash表中找,找不到才会真实计算。
h := itabhash(inter, typ)
// look twice - once without lock, once with.
// common case will be no lock contention.
var m *itab
var locked int
for locked = 0; locked < 2; locked++ {
if locked != 0 {
lock(&ifaceLock)
}
for m = (*itab)(atomic.Loadp(unsafe.Pointer(&hash[h]))); m != nil; m = m.link {
if m.inter == inter && m._type == typ {
return m // 找到了前面计算过的itab
}
}
}
// 没有找到,生成一个,并加入到itab的hash中。
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize, 0, &memstats.other_sys))
m.inter = inter
m._type = typ
additab(m, true, canfail)
这个hash是个全局变量:
const (
hashSize = 1009
)
var (
ifaceLock mutex // lock for accessing hash
hash [hashSize]*itab
)
最后,看一下如何生成itab:
// both inter and typ have method sorted by name,
// and interface names are unique,
// so can iterate over both in lock step;
// the loop is O(ni+nt) not O(ni*nt). // 按name排序过的,因此这里的匹配只需要O(ni+nt)
j := 0
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
if m != nil {
ifn := typ.textOff(t.ifn)
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn // 找到匹配,将实际类型的方法填入itab的fun
}
goto nextimethod
}
}
}
nextimethod:
}
h := itabhash(inter, typ) //插入上面的全局hash
m.link = hash[h]
atomicstorep(unsafe.Pointer(&hash[h]), unsafe.Pointer(m))
}
到这里,interface的数据结构的框架。
reflection实质上是将interface背后的实现暴露了一部分给应用代码,使应用程序可以使用interface实现的一些内容。只要理解了interface的实现,reflect就好理解了。如reflect.typeof(i)返回interface i的type,Valueof返回value。
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对脚本之家的支持。