
前言
消息队列的作用
消息队列的结构
结构以及常见方案
连接
管道
生产者
交换机
队列
消费者
调用模式
简单队列
工作队列
发布订阅
路由模式
主题模式
远程调用
部署方式
单机模式
普通集群
镜像集群
Docker命令
一、前言
RabbitMQ是一套开源(MPL)的消息队列服务软件,是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开源实现,由以高性能、健壮以及可伸缩性出名的 Erlang 写成。
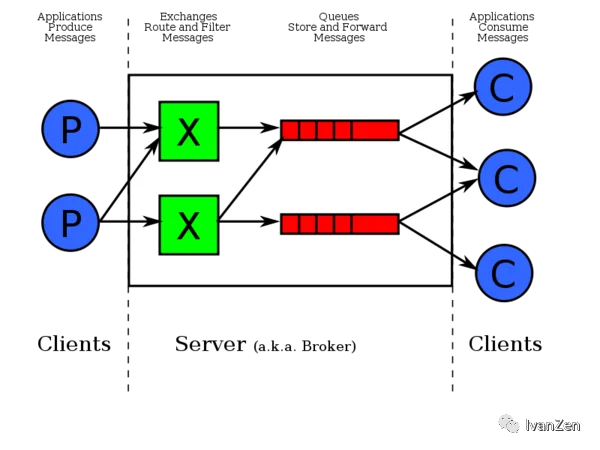
RabbitMQ是一个消息代理。它的工作就是接收和转发消息。你可以把它想像成一个邮局:你把信件放入邮箱,邮递员就会把信件投递到你的收件人处。在这个比喻中,RabbitMQ就扮演着邮箱、邮局以及邮递员的角色。
1. 消息队列的作用
解耦、异步、削峰
异步处理:相比于传统的串行、并行方式,提高了系统吞吐量。
应用解耦:系统间通过消息通信,不用关心其他系统的处理。
流量削锋:可以通过消息队列长度控制请求量;可以缓解短时间内的高并发请求。
日志处理:解决大量日志传输。
消息通讯:消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
2. 消息队列的结构
生产者
交换机
队列
消费者
二、结构以及常见方案
golang包:"github.com/streadway/amqp"
1. 连接(Connection)
// 连接到RabbitMQ服务器conn, err := amqp.Dial("amqp://{user}:{password}@{ip}:{port(5672)}/")failOnError(err, "Failed to connect to RabbitMQ")defer conn.Close()2. 管道(Channel)
// 配置连接套接字,它主要定义连接的协议和身份验证等ch, err := conn.Channel()failOnError(err, "Failed to open a channel")defer ch.Close()3. 生产者(Producer)
1) 生产消息
ch.Publish({exchange},{routingKey},{mandatory},{immediate},{publishing})exchange 交换机名
routingKey 路由键
mandatory 强制性 建议false当mandatory标志位设置为true时,如果exchange根据自身类型和消息routingKey无法找到一个合适的queue存储消息,那么broker会调用basic.return方法将消息返还给生产者;当mandatory设置为false时,出现上述情况broker会直接将消息丢弃;通俗的讲,mandatory标志告诉broker代理服务器至少将消息route到一个队列中,否则就将消息return给发送者;
immediate 消息 建议false当immediate标志位设置为true时,如果exchange在将消息路由到queue(s)时发现对于的queue上么有消费者,那么这条消息不会放入队列中。当与消息routeKey关联的所有queue(一个或者多个)都没有消费者时,该消息会通过basic.return方法返还给生产者。
publishing 消息
DeliveryMode: amqp.Persistent 设置消息持久化
2)样例代码
q, err := ch.QueueDeclare( "hello", // name 定义队列名 true, // durable 定义是否持久化 false, // delete when usused false, // exclusive false, // no-wait nil, // arguments)......body := "持久化的 Hello World!"err = ch.Publish( "", // exchange q.Name, // routing key false, // mandatory false, amqp.Publishing { DeliveryMode: amqp.Persistent, ContentType: "text/plain", Body: []byte(body),})3)生产者丢失消息解决方案 推荐使用confirm模式
从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息。
transaction机制发送消息前,开启事务(channel.txSelect()),然后发送消息,如果发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务(channel.txCommit())。缺点:吞吐量下降。
confirm模式一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;rabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
2. 交换机(Exchanges)
1)声明交换机
err=ch.ExchangeDeclare({name},{kind},{durable},{autoDelete},{internal},{noWait},{args})name 交换机名
kind 类型
fanout(广播)
direct(直接交换)比fanout多加了一层密码限制(routingKey)
topic(主题)
headers(首部)
durable 是否持久化 建议true是否持久化,RabbitMQ关闭后,没有持久化的Exchange将被清除
autoDelete 是否自动删除 建议false是否自动删除,如果没有与之绑定的Queue,直接删除
internal 是否自动删除 建议false是否内置的,如果为true,只能通过Exchange到Exchange
noWait 是否非阻塞 建议false
true表示是。
阻塞:表示创建交换器的请求发送后,阻塞等待RMQ Server返回信息。
非阻塞:不会阻塞等待RMQ Server的返回信息,而RMQ Server也不会返回信息。(不推荐使用)
args 其他参数
2)样例代码
err=ch.ExchangeDeclare( "busi_exchange", // name 名称 "topic", // kind true, // durable false, // autoDelete false, // internal false, // no wait nil //args)3)匿名交换机
使用了命名为空字符串("")的匿名交换机
err = ch.Publish("",q.Name,false,false,amqp.Publishing{})4)备份交换机(AE)
简称AE,当我们发送到一个不能被路由(或者没有被绑定queue的)消息,这就可能导致消息被代理者丢失(强制为false),或者返回给发布者(通过添加返回监听并设置强制为true),那么就会导致要么发布者重新发布,要么消息不要了。但是现在有一种方案就是先收集不可用的然后统一处理(这个就是备用交换机)
应用场景
当一个消息不能被route的时候,如果exchange设定了AE,则消息会被投递到AE。如果存在AE链,则会按此继续投递,直到消息被route或AE链结束或遇到已经尝试route过消息的AE
样例代码
......// 备份交换机=>建议此处使用 fanout 类型的交换器err=ch.ExchangeDeclare("def_exchange","fanout",true,false,false,false,nil)// 备份队列defq,err:=ch.QueueDeclare("def_queue",true,false,false,false,nil)// 备份绑定err=ch.QueueBind(defq.Name,"","def_exchange",false,nil)// 备份交换机策略参数,通常指定为死信交换机defargs:=make(map[string]interface{})defargs["alternate-exchange"]="def_exchange"......// 业务交换机 传入策略参数err=ch.ExchangeDeclare("busi_exchange","topic",true,false,false,false,defargs)3. 队列(Queue)
1)声明队列
q,err:=ch.QueueDeclare({name},{durable},{autoDelete},{exclusive},{nowait},{args})name 队列名称
durable 是否持久化 建议true队列的声明默认是存放到内存中的,如果rabbitmq重启会丢失,如果想重启之后还存在就要使队列持久化,保存到Erlang自带的Mnesia数据库中,当rabbitmq重启之后会读取该数据库。
autoDelete 是否自动删除 建议false当最后一个消费者断开连接之后队列是否自动被删除,可以通过RabbitMQ Management,查看某个队列的消费者数量,当consumers = 0时队列就会自动删除。
exclusive 是否排外的 建议false
当连接关闭时connection.close()该队列是否会自动删除。
该队列是否是私有的private,如果不是排外的,可以使用两个消费者都访问同一个队列,没有任何问题,如果是排外的,会对当前队列加锁,其他通道channel是不能访问的,如果强制访问会报异常:com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method(reply-code=405, reply-text=RESOURCE_LOCKED - cannot obtain exclusive access to locked queue 'queue_name' in vhost '/', class-id=50, method-id=20)。
应用于一个队列只能有一个消费者来消费的场景。
noWait 是否非阻塞 建议false
true表示是。
阻塞:表示创建交换器的请求发送后,阻塞等待RMQ Server返回信息。
非阻塞:不会阻塞等待RMQ Server的返回信息,而RMQ Server也不会返回信息。(不推荐使用)
args 其他参数
2) 消息队列丢数据解决方案 开启持久化磁盘的配置进行消息持久化
这个持久化配置可以和confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
durabletrueamqp.PublishingDeliveryModeamqp.Persistent3)临时队列
exclusivetrueq, err := ch.QueueDeclare(
"", // name
false, // durable
false, // delete when usused
true, // exclusive
false, // no-wait
nil, // arguments
)4)死信队列
消息因为超时或超过限制在队列里消失,这样我们就丢失了一些消息,也许里面就有一些是我们做需要获知的。而rabbitmq的死信功能则为我们带来了解决方案。设置了dead letter exchange与dead letter routingkey(要么都设定,要么都不设定)那些因为超时或超出限制而被删除的消息会被推动到我们设置的exchange中,再根据routingkey推到queue中。
样例代码
......
// 死信交换机
err=ch.ExchangeDeclare("dlx_exchange","topic",true,false,false,false,nil)
// 死信队列
delq,err:=ch.QueueDeclare("dlx_queue",true,false,false,false,nil)
// 死信绑定
err=ch.QueueBind(delq.Name,"dlx.*","dlx_exchange",false,nil)
// 死信队列策略参数
args:=make(map[string]interface{})
args["x-message-ttl"]=5000 // 定义超时时间 单位:毫秒
args["x-dead-letter-exchange"]="dlx_exchange" // 死信交换机名
args["x-dead-letter-routing-key"]="dlx.test" // 死信路由键
// 业务交换机
err=ch.ExchangeDeclare("busi_exchange","topic",true,false,false,false,nil)
// 业务队列
bq,err:=ch.QueueDeclare("busi_queue",true,false,false,false,args)
// 业务绑定
err=ch.QueueBind(bq.Name,"blc","busi_exchange",false,nil)4. 消费者(Consumer)
1)消费消息
msg,err:=ch.Consume({queue},{consumer},{autoAck},{exclusive},{noLocal},{noWait},{args})queue 队列
consumer 消费者
autoAck 是否自动响应 建议true消息确认机制,就是说,确认消息正常执行了。当消息正常执行后,会返回一个ACK。没有正常执行则不会返回ACK。
exclusive 是否排外的 建议false
noLocal 是否本地 建议false
如果服务器不应向此消费者发送此通道连接上发布的消息,则设置为true
noWait 是否非阻塞 建议false
args 其他参数
2) 消费者丢失消息 解决方案 => 手动确认消息
auto-ackd.Ack(false)msgs, err := ch.Consume(
q.Name, // queue 队列名称
"", // consumer 消费路由
false, // auto-ack 关闭自动回复,通常都关闭
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
......
go func() {
for d := range msgs {
log.Printf("Received a message: %s", d.Body)
d.Ack(false) //multiple:为了减少网络流量,手动确认可以被批处理,当该参数为 true 时,则可以一次性确认 delivery_tag 小于等于传入值的所有消息
}
}()忘记ack,是一个常见的错误,但后果是严重的。当客户端退出时,消息将被重新传递(这可能看起来像随机重新传递),但是RabbitMQ将会占用越来越多的内存,因为它无法释放任何未经消息的消息。
rabbitmqctlmessages_unacknowledged[root@xxx]#sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged3) 多线程消费消息
with only one thread being able to run a command on the Channel at a timeChannel的Consumer或者DeliverCallback在处理消息的时候,确实是单线程执行的
处理方案:Consumer或者DeliverCallback不处理消息,而是将消息转发给业务线程池处理。
4) 消费者限流与预取模式
消费者丢数据一般是因为采用了自动确认消息模式,改为手动确认消息即可。处理消息成功后,手动回复确认消息。
消费确认模式必须是非自动ACK机制(这个是使用baseQos的前提条件,否则会Qos不生效),然后设置basicQos的值;另外,还可以基于consume和channel的粒度进行设置(global)
ch.Qos(
15, // prefetchCount:会告诉RabbitMQ不要同时给一个消费者推送多于N个消息,即一旦有N个消息还没有ack,则该consumer将block掉,直到有消息ack
0, // prefetchSize:最多传输的内容的大小的限制,0为不限制,但据说prefetchSize参数,rabbitmq没有实现
false // global:true\false 是否将上面设置应用于channel,简单点说,就是上面限制是channel级别的还是consumer级别
)5) 消息幂等性
通常,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除。但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响;保证消息等幂性;在写入消息队列的数据做唯一标示,消费消息时,根据唯一标识判断是否消费过。
6) 消息顺序性
单线程消费保证消息的顺序性;对消息进行编号,消费者处理消息是根据编号处理消息
三、调用模式
1. 简单队列

2. 工作队列

1)循环调度
RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。但是毕竟每个消费者的消费能力不一致,会造成部分消费者”吃的很撑“,部分消费者“还很饥饿”,所以通常该模式并不是很提倡。
2)公平调度

设置预取计数值为1。告诉RabbitMQ一次只向一个worker发送一条消息。公平分发,某消费者在工作饱和情况下不发送消息给该消费者。
err = ch.Qos(
1, // prefetch count
0, // prefetch size
false, // global
)
failOnError(err, "Failed to set QoS")3. 发布订阅
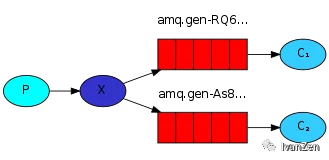
err = ch.QueueBind(
q.Name, // queue name
"", // routing key
"busi_exchange", // exchange
false,
nil,
)4. 路由模式
routing key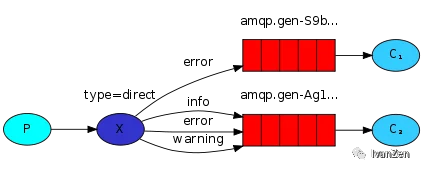
err = ch.QueueBind(
q.Name, // queue name
"info", // routing key
"busi_exchange", // exchange
false,
nil,
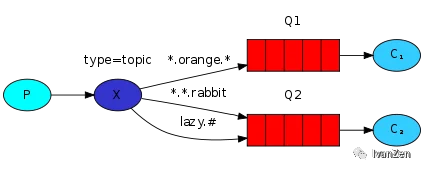
)5. 主题模式
*#
6. 远程调用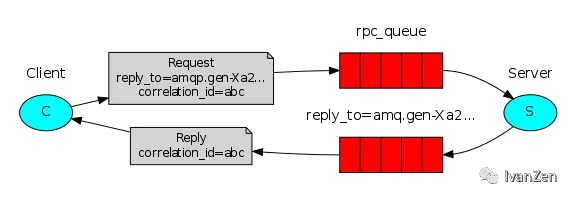
当客户端启动的时候,它创建一个匿名独享的回调队列。
在RPC中,客户端发送带有两个属性的消息:一个是设置回调队列的 reply_to 属性,另一个是设置唯一值的 correlation_id 属性。
将请求发送到一个 rpc_queue 队列中。
RPC工作者(又名:服务器)等待请求发送到这个队列中来。当请求出现的时候,它执行他的工作并且将带有执行结果的消息发送给reply_to字段指定的队列。
客户端等待回调队列里的数据。当有消息出现的时候,它会检查correlation_id属性。如果此属性的值与请求匹配,将它返回给应用。
四、部署模式
1. 单机模式
即单机情况不做集群,就单独运行一个 RabbitMQ 而已。
2. 普通集群模式
默认模式,以两个节点(node-1、node-2)为例来进行说明。对于 Queue 来说,消息实体只存在于其中一个节点 node-1(或者 node-2),node-1 和 node-2 两个节点仅有相同的元数据,即队列的结构。当消息进入 node-1 节点的 Queue 后,consumer 从 node-2 节点消费时,RabbitMQ 会临时在 node-1、node-2 间进行消息传输,把 A 中的消息实体取出并经过 B 发送给 consumer。所以 consumer 应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理 Queue。否则无论 consumer 连 node-1 或 node-2,出口总在 node-1,会产生瓶颈。当 node-1 节点故障后,node-2 节点无法取到 node-1 节点中还未消费的消息实体。如果做了消息持久化,那么得等 node-1 节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
3. 镜像集群模式
一般配合HAProxy配置为高可用集群,把需要的队列做成镜像队列,存在与多个节点属于 RabbitMQ 的 HA 方案。非常经典的 mirror 镜像模式,保证 100% 数据不丢失。在实际工作中也是用得最多的,并且实现非常的简单,一般互联网大厂都会构建这种镜像集群模式。mirror 镜像队列,目的是为了保证 rabbitMQ 数据的高可靠性解决方案,主要就是实现数据的同步,一般来讲是 2 - 3 个节点实现数据同步。对于 100% 数据可靠性解决方案,一般是采用 3 个节点。
4. Doker部署
[root@xxx]# docker pull rabbitmq:management
[root@xxx]# docker run -d --name myrabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin -p 15672:15672 -p 5672:5672 rabbitmq:management