
消费端log日志获取并可视化分析
0、加载配置文件
//加载配置文件
var cfg =new(model.Config)
err:=ini.MapTo(cfg,"./config/logtranfer.ini")
if err!=nil{
logrus.Errorf("ini load failed err:%s ",err)
return
}
fmt.Println("load ini config success")//别忘了tag 否则映射不出来
type Config struct {
KafkaConfig `ini:"kafka"`
ESConfig `ini:"es"`
}
type KafkaConfig struct{
Address string`ini:"address"`
Topic string `ini:"topic"`
}
type ESConfig struct {
Address string `ini:"address"`
Index string `ini:"index"`
MaxSize int `ini:"max_chan_size"`
GoroutineNumber int `ini:"consumer_goroutine_num"`
}//config.ini
[kafka]
address=127.0.0.1:9092
topic=web_log
[es]
address=192.168.1.113:9200
index=web
max_chan_size=10000
consumer_goroutine_num=16注意:这里的结构体一定要设置映射的tag,因为我们进行ini.MapTo加载配置文件时,配置文件config.ini中的标签是tag对应的
1、从kafka消息队列读取日志信息
// 连接kafka
err=kafka.Init([]string{cfg.KafkaConfig.Address},cfg.KafkaConfig.Topic)
if err!=nil{
logrus.Errorf("link kafka failed err:%s",err)
return
}
fmt.Println("link kafka success!")从消息队列中获取日志信息,将日志信息放入管道中,(设置管道的原因是为了将串行调用改为并行发生,不再发生函数调用,而是不停的往管道中放数据,)
//初始化kafka
//从中取数据放在通道中
func Init(addr []string,topic string)(err error){
consumer,err:=sarama.NewConsumer(addr,nil)
if err!=nil{
fmt.Println("creater consumer failed err:",err)
return
}
//拿到topic下面的分区
partitionList ,err :=consumer.Partitions(topic)
if err!=nil{
fmt.Println("partitionList get failed err:",err)
return
}
for partition :=range partitionList{
pc,err:=consumer.ConsumePartition(topic,int32(partition),sarama.OffsetNewest)
if err!=nil{
fmt.Printf("failed to start consumer for partition %d ,err: %v:",partition,err)
return err
}
//这里如果有defer 携程会在这个函数结束以后被强制关闭
//defer pc.AsyncClose()
//异步读分区数据
go func(sarama.PartitionConsumer){
for msg:=range pc.Messages(){
//为了将同步流程异步化 将取出的日志放在通道中
//fmt.Println(msg.Topic,msg.Value)
var m1 map[string]interface{}
err=json.Unmarshal(msg.Value,&m1)
if err!=nil{
logrus.Error("kafka info msg unmarshal failed err:",err)
continue
}
es.PutLogData(m1)
}
}(pc)
}
return
}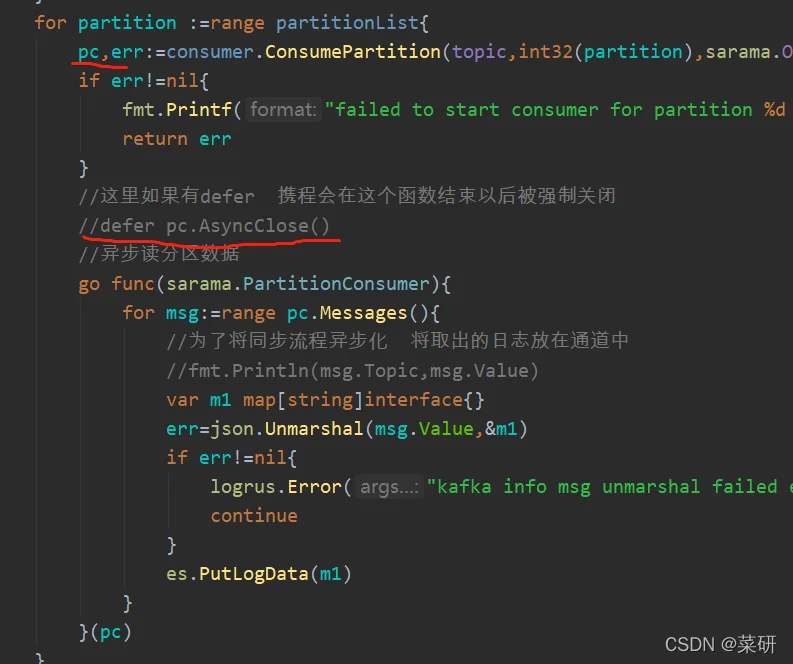
这里的pc一定不能关闭,因为我们后台会由goroutine不停的在放入数据,defer pc.close()会在这个函数结束后直接将pc回收注销。
//将一个首字母大写的函数 从包外接收数据
func PutLogData(msg interface{}){
esClient.LogDataChan<-msg
}2、将消息写入管道,ES从管道读取消息并且保存到ES中
// 连接es 这个一定要在kafka初始化前边 因为信息管道在es中声明初始化,kafka用之前必须先初始化
err=es.Init(cfg.ESConfig.Address,cfg.ESConfig.Index,cfg.ESConfig.MaxSize,cfg.ESConfig.GoroutineNumber)
if err!=nil{
logrus.Errorf("link es failed err:%s",err)
return
}
fmt.Println("link es success!")初始化es和将es需要的配置信息进行加载,(注意在main函数调用时,es的初始化一定要在kafka读取数据之前,因为本项目中将在es中开启缓冲管道,只有在es初始化完成以后才能kafka调用放入数据)
type ESClient struct {
client *elastic.Client
index string
LogDataChan chan interface{}//接收日志的channel
}
var (
esClient= new(ESClient)//这里必须是new初始化一个地址会有字段,直接用*会报错因为是空指针
)
//初始化Es
func Init(addr string,index string,maxSize,goroutineNum int)(err error){
client, err := elastic.NewClient(elastic.SetURL("http://"+addr))
if err != nil {
// Handle error
panic(err)
}
esClient.client=client
esClient.index=index
esClient.LogDataChan=make(chan interface{},maxSize)
fmt.Println("connect to es success")
//从通道取数据放到es中
for i:=0;i<goroutineNum;i++{
go sendToEs()
}
return
}这里将开启16个协程,完成从管道中读取数据放入es中,
func sendToEs(){
for msg:=range esClient.LogDataChan{
put1,err :=esClient.client.Index().Index(esClient.index).BodyJson(msg).Do(context.Background())
if err!=nil{
logrus.Error("msg send to es failed err:",err)
continue
}
fmt.Println(put1.Type,put1.Result)
}
}3、kibana可视化管理分析
a、连接index
在es中index相当于redis和MySQL中的表,
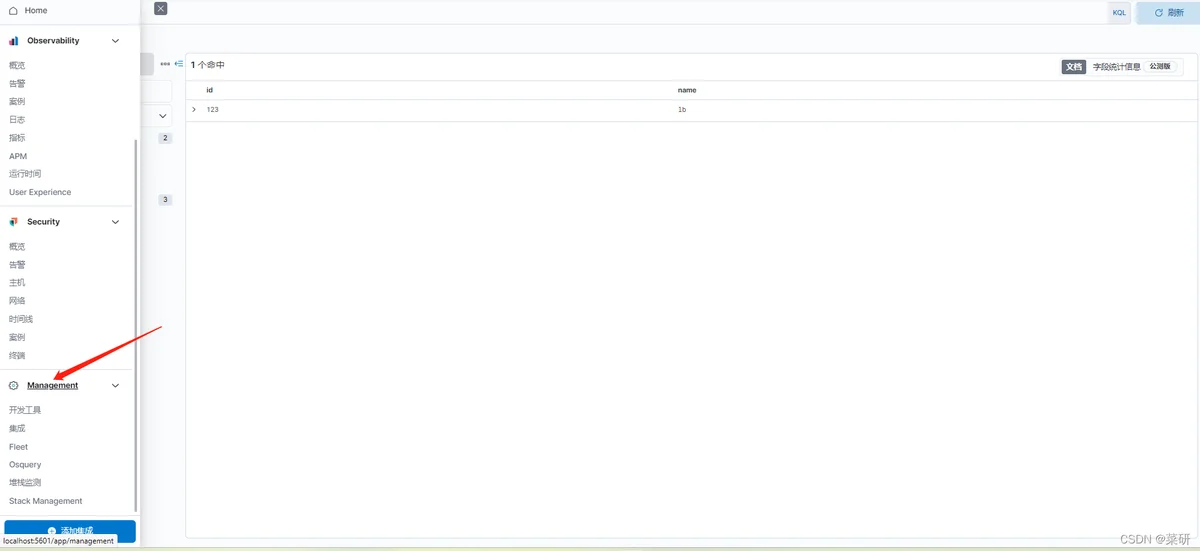
点击这个管理management选择自己写入的es表格
b、设置可查询字段
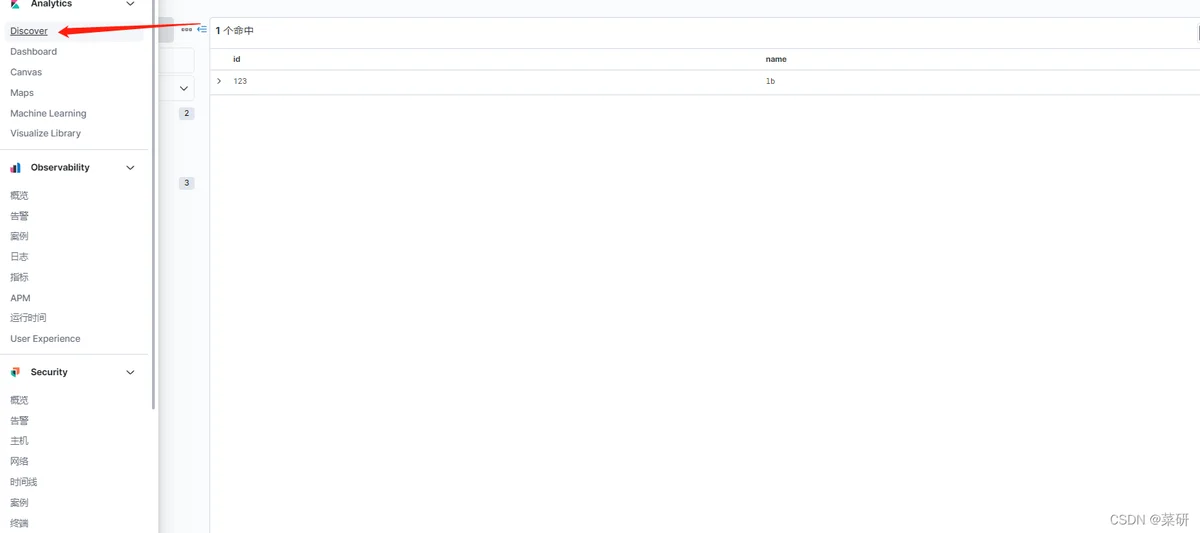
点击发现,进入搜索设置界面,在选定字段中勾选自己需要查询的字段,我选的id和name,然后可以按照自己设定的字段进行搜索。
本项目的主流功能至此结束!
1、至于为什么要写这个项目,首先filebeat也同样可以进行分布式的文件收集,但是filebeat会有一个弊端,没有使用etcd进行服务注册发现,当我们更改服务器日志收集时需要单独操作服务器,现在可以调用etcd进行配置文件热加载。
2、并且我在项目中加上了每台服务器的性能情景监视,在grafana中实时显示服务器情景,做出可视化处理。
本项目是在q1mi视频中学习,修改编写所得,感兴趣可以听听q1mi老师的视频,学习笔记和源码已经上传到GitHub中。