
Go V1.3 之前的标记-清除算法
此算法主要有两个主要的步骤:
- 标记(Mark phase)
- 清除(Sweep phase)
具体过程比较简单,就不赘述了,说一下它的缺点吧
缺点
- STW,stop the world;让程序暂停,程序出现卡顿 (重要问题)。
- 标记需要扫描整个heap
- 清除数据会产生heap碎片
所以Go V1.3版本之前就是以上来实施的, 流程是
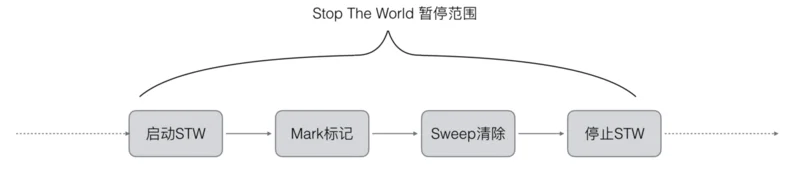
Go V1.3 做了简单的优化,将STW提前, 减少STW暂停的时间范围.如下所示
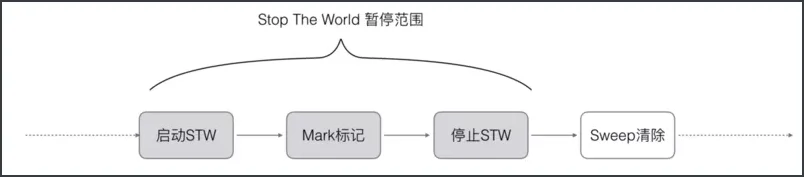
这里面最重要的问题就是:****mark-and-sweep 算法会暂停整个程序 。
Go是如何面对并这个问题的呢?接下来G V1.5版本 就用三色并发标记法 + 屏障机制 来优化这个问题.
Go V1.5的三色并发标记 + 屏障机制
三色标记法 实际上就是通过三个阶段的标记来确定需要清除的对象都有哪些. 我们来看一下具体的过程.这边用的和Java一样,都是可达性算法进行扫描,根节点主要包括:全局对象,栈对象。
第一步 , 就是只要是新创建的对象,默认的颜色都是标记为“白色”.
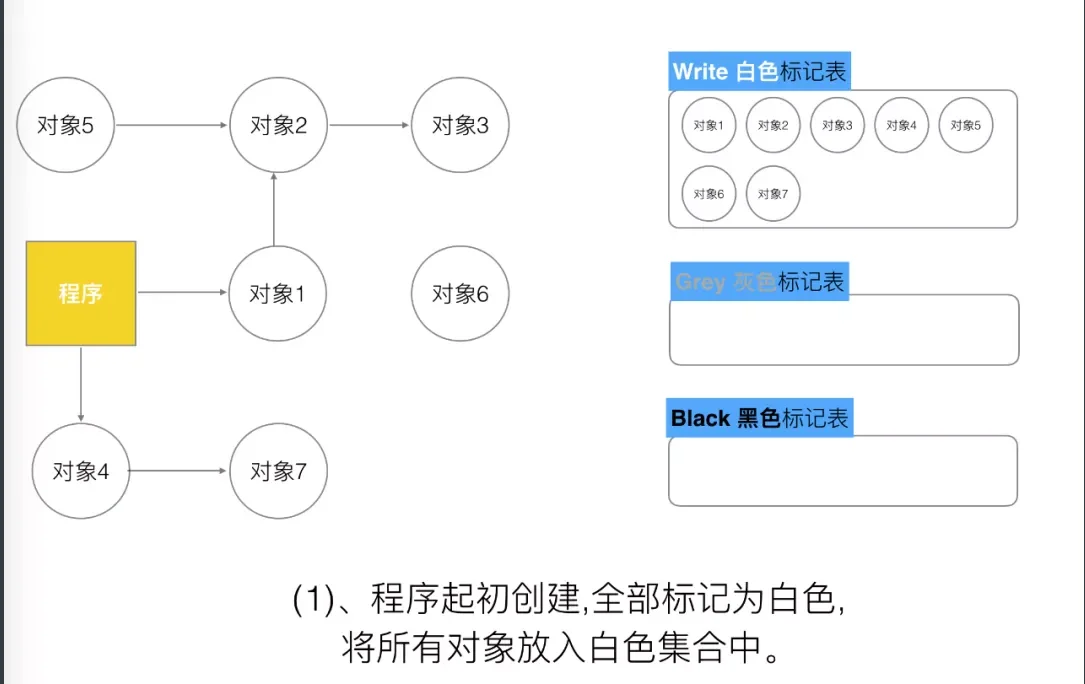
这里面需要注意的是, 所谓“程序”, 则是一些对象的跟节点集合.
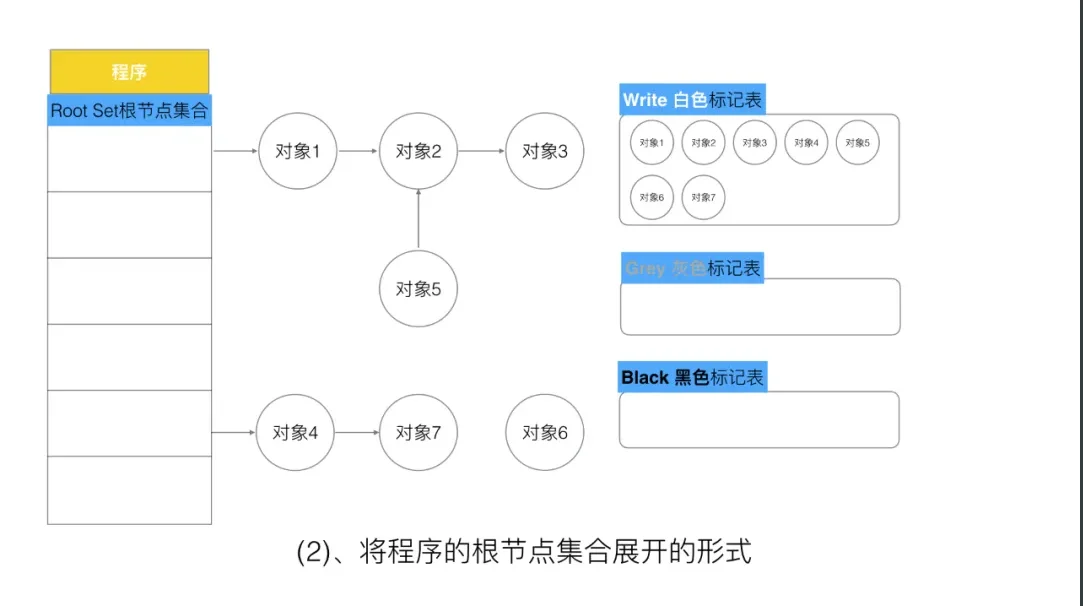
所以上图,可以转换如下的方式来表示.
第二步, 每次GC回收开始, 然后从根节点开始遍历所有对象,把遍历到的对象从白色集合放入“灰色”集合。
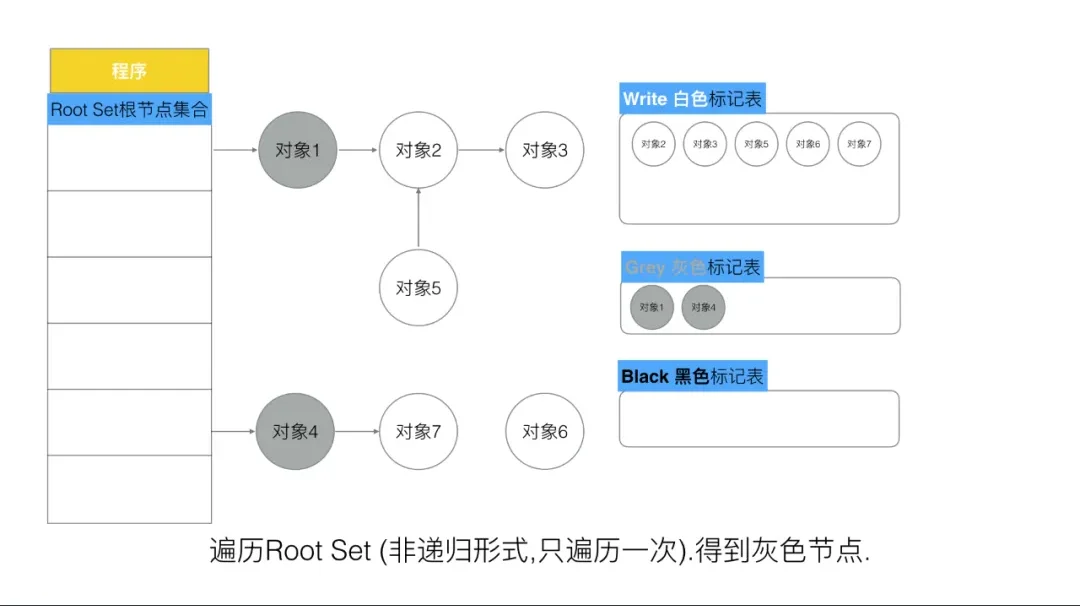
第三步, 遍历灰色集合,将灰色对象引用的对象从白色集合放入灰色集合,之后将此灰色对象放入黑色集合
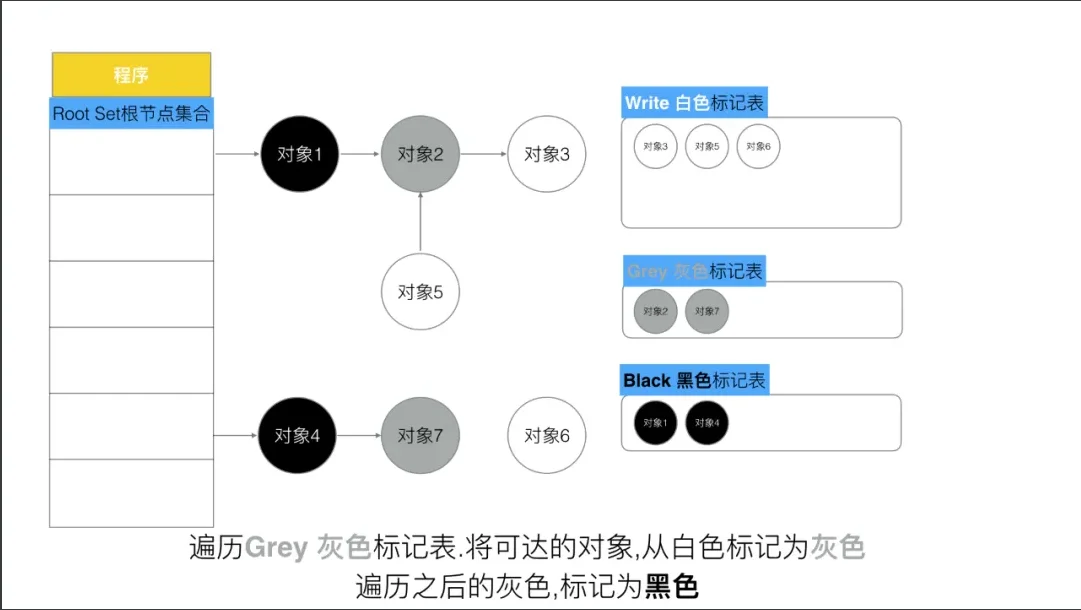
第四步, 重复第三步, 直到灰色中无任何对象.
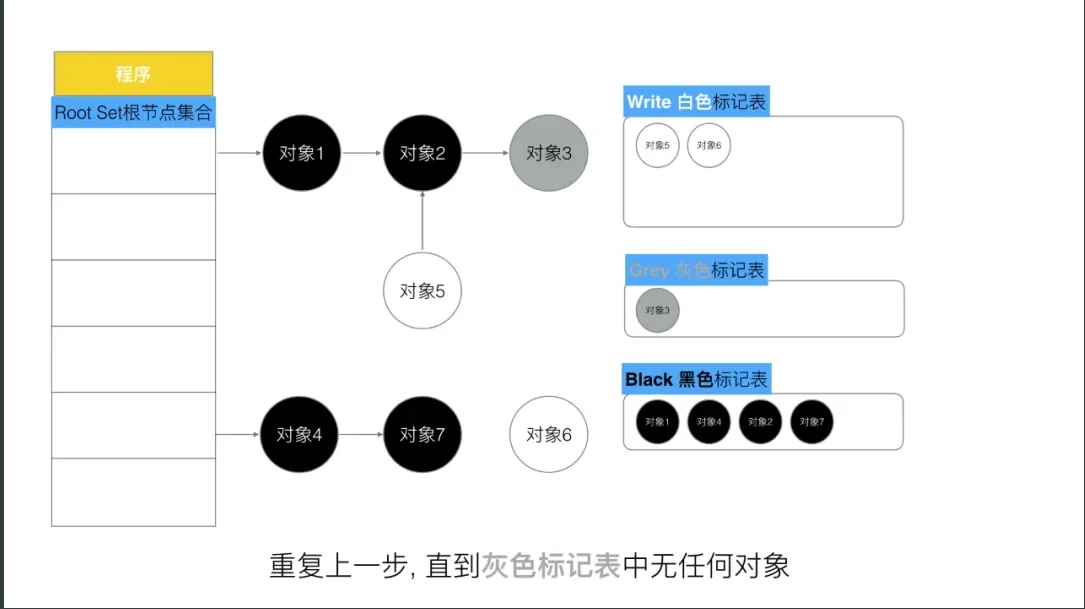
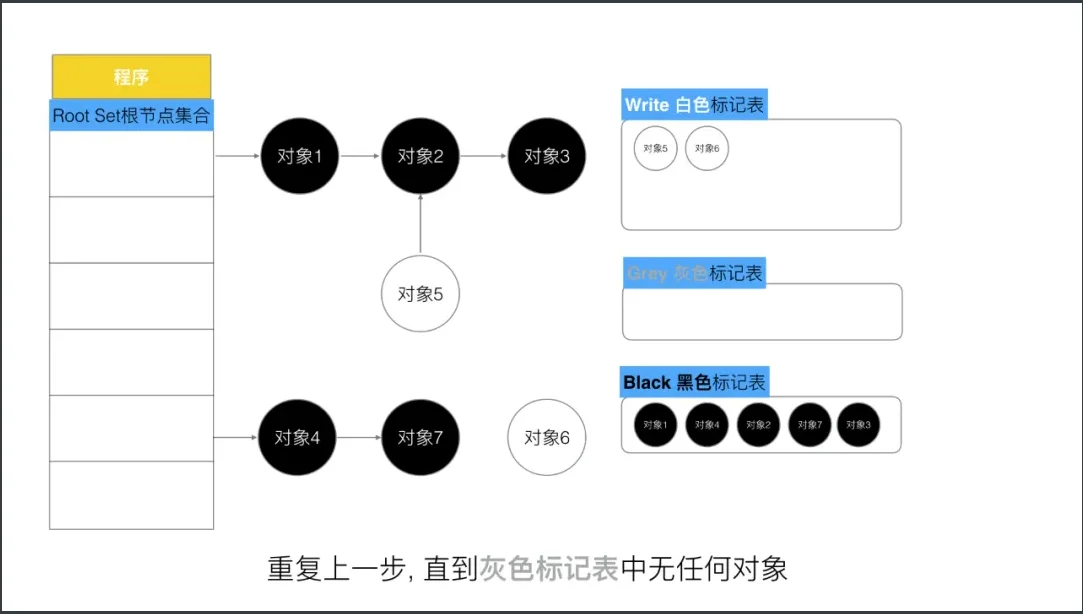
第五步,回收所有的白色标记表的对象. 也就是回收垃圾.
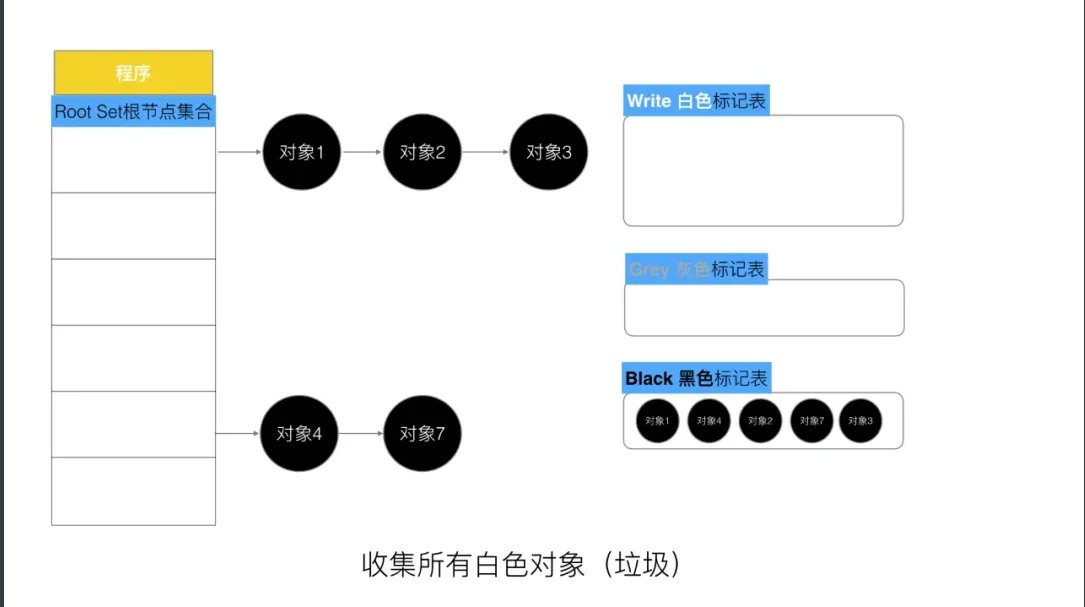
如何实现并发收集?
三色标记如果没有其他机制去控制,那么在和用户线程并行的时候,就会出现在程序运行过程当中,一些对象的引用链被修改,会出现浮动垃圾和对象消失的情况
可以看出,有两个问题, 在三色标记法中,是不希望被发生的
- 条件1: 一个白色对象被黑色对象引用(白色被挂在黑色下) ps:这也是插入屏障解决的问题
- 条件2: 灰色对象与它之间的可达关系的白色对象遭到破坏(灰色同时丢了该白色) 这是删除屏障解决的问题
当以上两个条件同时满足时, 就会出现对象丢失现象!
当然, 如果上述中的白色对象3, 如果他还有很多下游对象的话, 也会一并都清理掉.
浮动垃圾可能还好,到下一次GC就被回收了
但是对象消失就比较严重了,会导出程序出现空指针的情况
Java的CMS和G1针对对象消失这种情况,用了增量更新和原始快照的方式解决,也就是当有对象的引用链被修改的时候,就把这个对象纪录下来,然后最后再重新扫描校对一次。
屏障机制
我们让GC回收器,满足下面两种情况之一时,可保对象不丢失. 所以引出两种方式.
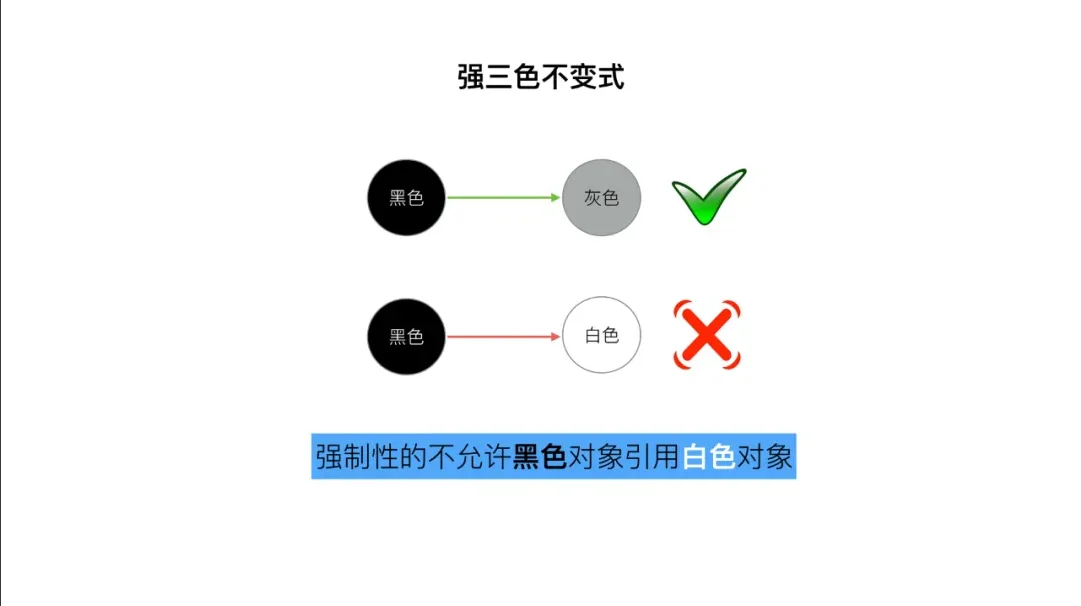
- 强三色不变式
不存在黑色对象引用到白色对象的指针。
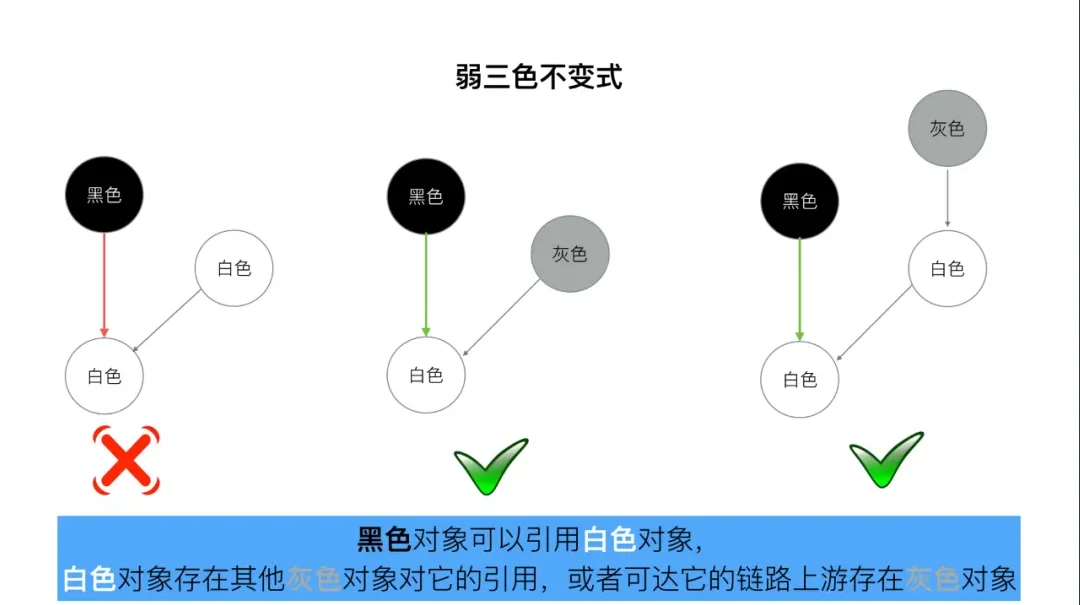
- 弱三色不变式
所有被黑色对象引用的白色对象都处于灰色保护状态.
为了遵循上述的两个方式,Golang团队初步得到了如下具体的两种屏障方式“插入屏障”, “删除屏障”.
插入屏障
在A对象引用B对象的时候,B对象被标记为灰色。(将B挂在A下游,B必须被标记为灰色)
满足栈堆这个插入屏障在gov1.5的时候并不对栈上的对象使用,只对堆上的适用
删除屏障
具体操作满足二者缺点
插入写屏障和删除写屏障的短板:
- 插入写屏障:因为栈上的对象在垃圾收集中也会被认为是根对象,所以为了保证内存的安全,Dijkstra 必须为栈上的对象增加写屏障或者在标记阶段完成重新对栈上的对象进行扫描,这两种方法各有各的缺点,前者会大幅度增加写入指针的额外开销,后者重新扫描栈对象时需要暂停程序。这里因为没对栈增加写屏障,所以结束时需要STW来重新扫描栈。
- 删除写屏障:回收精度低,GC开始时STW扫描堆栈来记录初始快照,这个过程会保护开始时刻的所有存活对象,即时你删除了一个对象,在那个时刻,即时发生了gc,它也不会被回收,因为它是灰色的。
Go V1.8的混合写屏障机制
Go V1.8版本引入了混合写屏障机制(hybrid write barrier),避免了对栈re-scan的过程,极大的减少了STW的时间。结合了两者的优点。
具体操作1、GC开始将栈上的对象全部扫描并标记为黑色(之后不再进行第二次重复扫描,无需STW),
2、GC期间,任何在栈上创建的新对象,均为黑色。
3、被删除的对象标记为灰色。
4、被添加的对象标记为灰色。
满足对于堆上的对象来说,它在GC开始的时候就被全部标为黑色,当删除的时候,它还是黑色,但是下一次GC的时候,发现不可达了,它就被清除掉了,可以堪称是一种延迟清除的解决方案。
这样就能保证栈中的对象的最终结果是正确的,就能避免对栈的重新扫描导致的STW开销。
与JavaGC的差别
- 首先都是可达性算法去扫描垃圾
- 对于三色标记的对象消失问题处理方式的不同,Java采用增量更新和原始快照,也就是说需要在真正清除垃圾之前再进行一次STW完成校对的过程,Go就采用屏障机制了,去除了这一步骤STW的开销。
- Java采用分代收集,根据不同的年龄代,启用不用的垃圾回收算法,而Go的话,就是标记清除了。
对象逃逸分析
首先如果对象被分配到栈上的话,是不参与GC的,没有GC开销,所以我们需要对程序进行逃逸分析,判断哪些对象会在栈中,哪些会在堆中.
逃逸分析的作用是什么呢?
-
逃逸分析的好处是为了减少gc的压力,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要gc标记清除。
-
逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好(逃逸的局部变量会在堆上分配 ,而没有发生逃逸的则有编译器在栈上分配)。
-
同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
-
指针逃逸
go 将函数内定义的变量返回到函数外,会将本应分配到栈上的内存分配到堆上。 -
栈空间不足逃逸
当栈空间不足或无法判断当前切片长度时会将对象分配到堆上。 -
动态类型逃逸
当函数参数为 interface 类型,编译期间无法确定参数的具体类型,也可能会产生逃逸。
函数传递指针真的比传值效率高吗?
传递指针相比值传递减少了底层拷贝,可以提高效率,但是拷贝的数据量较小,由于指针传递会产生逃逸,可能会使用堆,也可能增加gc的负担,所以指针传递不一定是高效的。
代码优化
减少对象分配 所谓减少对象的分配,实际上是尽量做到,对象的重用。 比如像如下的两个函数定义:
第一个函数没有形参,每次调用的时候返回一个 []byte,第二个函数在每次调用的时候,形参是一个 buf []byte 类型的对象,之后返回读入的 byte 的数目。
第一个函数在每次调用的时候都会分配一段空间,这会给 gc 造成额外的压力。第二个函数在每次迪调用的时候,会重用形参声明。
老生常谈 string 与 []byte 转化 在 stirng 与 []byte 之间进行转换,会给 gc 造成压力 通过 gdb,可以先对比下两者的数据结构:
两者发生转换的时候,底层数据结结构会进行复制,因此导致 gc 效率会变低。解决策略上,一种方式是一直使用 []byte,特别是在数据传输方面,[]byte 中也包含着许多 string 会常用到的有效的操作。另一种是使用更为底层的操作直接进行转化,避免复制行为的发生。
少量使用+连接 string 由于采用 + 来进行 string 的连接会生成新的对象,降低 gc 的效率,好的方式是通过 append 函数来进行。
append操作 在使用了append操作之后,数组的空间由1024增长到了1312,所以如果能提前知道数组的长度的话,最好在最初分配空间的时候就做好空间规划操作,会增加一些代码管理的成本,同时也会降低gc的压力,提升代码的效率。