
本文从我的《The Go Programming Language》学习笔记中分离出,单独成一篇文章方便查阅参考。
strings.Builder 源码解析
存在意义
使用 (strings.Builder),避免频繁创建字符串对象,进而提高性能
(Source file) https://go.dev/src/strings/builder.go
与许多支持 (string) 类型的语言一样,(golang) 中的 (string) 类型也是只读且不可变的( (string) 类型笔记 Go xmas2020 学习笔记 04、Strings - 小能日记 - 云海天 )。因此,通过循环字符串切片拼接字符串的方式会导致大量的string创建、销毁和内存分配。如果你拼接的字符串比较多的话,这显然不是一个正确的姿势。
在 (strings.Builder) 出来以前,我们是用 (bytes.Buffer) 来进行优化的。
func main() {
ss := []string{
"A",
"B",
"C",
}
var b bytes.Buffer
for _, s := range ss {
fmt.Fprint(&b, s)
}
print(b.String())
}
var b bytes.Buffer但这里依然有一个小问题: (b.String()) 会有一次 ([ ]byte -> string) 类型转换。而这个操作是会进行一次内存分配和内容拷贝的。
实现原理
Golang 官方将 (strings.Builder) 作为一个(feature) 引入。
- 与 (byte.Buffer) 思路类似,既然 (string) 在构建过程中会不断的被销毁重建,那么就尽量避免这个问题,底层使用一个 (buf [ ]byte) 来存放字符串的内容。
- 对于写操作,就是简单的将 (byte) 写入到 (buf) 即可。
- 为了解决 (bytes.Buffer.String()) 存在的 ([ ]byte -> string) 类型转换和内存拷贝问题,这里使用了一个(unsafe.Pointer) 的内存指针转换操作,实现了直接将 (buf [ ]byte)转换为 (string) 类型,同时避免了内存充分配的问题。
- 如果我们自己来实现 (strings.Builder) , 大部分情况下我们完成前3步就觉得大功告成了。但是标准库做得要更近一步。我们知道 Golang 的堆栈在大部分情况下是不需要开发者关注的,如果能够在栈上完成的工作逃逸到了堆上,性能就大打折扣了。因此,(copyCheck) 加入了一行比较 (hack) 的代码来避免 (buf) 逃逸到堆上。Go 栈、堆的知识可看 GopherCon SG 2019 "Understanding Allocations" 学习笔记 - 小能日记 - 云海天
常用方法
- String方法返回Builder构建的数据
- Len方法返回字节数组占据的字节数,1个汉字三个字节
- Cap方法返回字节数组分配的内存空间大小
- Reset方法将Builder重置为初始状态
- Write方法将字节数组加添加到buf数组后面
- WriteByte将字节c添加到buf数组后边
- WriteRune将rune字符添加到buf数组后面
- WriteString将字符串添加到buf数组后面
写入方法
(bytes.Buffer) 也支持这四个写入方法。
func (b *Builder) Write(p []byte) (int, error)
func (b *Builder) WriteByte(c byte) error
func (b *Builder) WriteRune(r rune) (int, error)
func (b *Builder) WriteString(s string) (int, error)
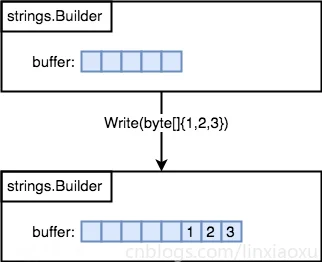
strings.BuilderrunestringWriteRune()WriteString()我们可以预定义切片的容量来避免重新分配。
扩容方法
追加内容也有讲究,因为底层是 (slice),追加数据时有可能引起 (slice) 扩容。一般的优化方案是为 (slice) 初始化合理的空间,避免多次扩容复制。(Builder) 也提供了预分配内存的方法,如 (Grow) 方法。
func (b *Builder) grow(n int) {
buf := make([]byte, len(b.buf), 2*cap(b.buf)+n)
copy(buf, b.buf)
b.buf = buf
}
func (b *Builder) Grow(n int) {
b.copyCheck()
if n < 0 {
panic("strings.Builder.Grow: negative count")
}
if cap(b.buf)-len(b.buf) < n {
b.grow(n)
}
}
2*cap(b.buf)+n- 如果容量是10,长度是5,调用 (Grow(3))结果是什么?当前容量足够使用,没有任何操作;
- 如果容量是10,长度是5,调用 (Grow(7))结果是什么?剩余空间是5,不满足7个扩容空间,底层需要扩容。扩容的时候按照之前容量的两倍再加 (n) 的新容量扩容,结果是 (2*10+7=27)。
String() 方法
func (b *Builder) String() string {
return *(*string)(unsafe.Pointer(&b.buf))
}
先获取 ([ ]byte) 地址,然后转成字符串指针,然后再取地址。
从 ptype 输出的结构来看,string 可看做 [2]uintptr,而 [ ]byte 则是 [3]uintptr,这便于我们编写代码,无需额外定义结构类型。如此,str2bytes 只需构建 [3]uintptr{ptr, len, len},而 bytes2str 更简单,直接转换指针类型,忽略掉 cap 即可。
禁止复制
type Builder struct {
addr *Builder // of receiver, to detect copies by value
buf []byte
}
(Builder) 的底层数据,它还有个字段 (addr) ,是一个指向 (Builder) 的指针。默认情况是它会指向自己。
b.addr = (*Builder)(noescape(unsafe.Pointer(b)))
(copyCheck) 用来保证复制后不允许修改的逻辑。仔细看下源码,如果 (addr) 是空,也就是没有数据的时候是可以被复制后修改的,一旦那边有数据了,就不能这么搞了。在 (Grow)、(Write)、(WriteByte)、(WriteString)、(WriteRune) 这五个函数里都有这个检查逻辑。
var b1 strings.Builder
b2 := b1
b2.WriteString("DEF")
b1.WriteString("ABC")
// b1 = ABC, b2 = DEF
var b1 strings.Builder
b1.WriteString("ABC")
b2 := b1
b2.WriteString("DEF")
illegal use of non-zero Builder copied by value下面的意思是拷贝过来的Builder进行添加修改,会造成其他Builder的修改。
Writestrings.Builder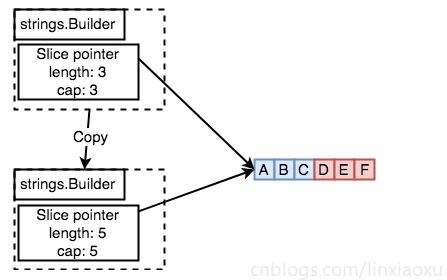
我们可以使用 (Reset) 方法对 (addr、buf) 置空。下面拷贝了使用 (Reset) 后不会报错。
var b1 strings.Builder
b1.WriteString("ABC")
b2 := b1
fmt.Println(b2.Len()) // 3
fmt.Println(b2.String()) // ABC
b2.Reset()
b2.WriteString("DEF")
fmt.Println(b2.String()) // DEF
线程不安全
func main() {
var b strings.Builder
var n int32
var wait sync.WaitGroup
for i := 0; i < 1000; i++ {
wait.Add(1)
go func() {
atomic.AddInt32(&n, 1)
b.WriteString("1")
wait.Done()
}()
}
wait.Wait()
fmt.Println(len(b.String()), n)
}
905 1000
结果是 (905 1000),并不都是 (1000) 。如果想保证线程安全,需要在 (WriteString) 的时候加锁。
io.Writer 接口
(strings.Builder) 实现了 (io.Writer) 接口。可以使用在很多例子中
- io.Copy(dst Writer, src Reader) (written int64, err error)
- bufio.NewWriter(w io.Writer) *Writer
- fmt.Fprint(w io.Writer, a …interface{}) (n int, err error)
- func (r *http.Request) Write(w io.Writer) error
- and other libraries that uses (io.Writer)
代码
func main() {
var b strings.Builder
fmt.Printf("%v", b)
fmt.Println(b.Len(), b.Cap())
for i := 3; i >= 1; i-- {
fmt.Fprintf(&b, "%d#", i)
fmt.Printf("%v
", b)
fmt.Println(b.Len(), b.Cap())
}
b.WriteString("Hello")
fmt.Printf("%v
", b)
fmt.Println(b.Len(), b.Cap())
fmt.Println(b.String())
// b.Grow(5) // ^ 扩容
b.Grow(88) // ^ 扩容
fmt.Printf("%v
", b)
fmt.Println(b.Len(), b.Cap())
fmt.Println(unsafeEqual("Hello", []byte{72, 101, 108, 108, 111}))
}
func unsafeEqual(a string, b []byte) bool {
bbp := *(*string)(unsafe.Pointer(&b))
return a == bbp
}
{<nil> []}0 0
{0xc0001223a0 [51 35]}
2 8
{0xc0001223a0 [51 35 50 35]}
4 8
{0xc0001223a0 [51 35 50 35 49 35]}
6 8
{0xc0001223a0 [51 35 50 35 49 35 72 101 108 108 111]}
11 16
3#2#1#Hello
{0xc0001223a0 [51 35 50 35 49 35 72 101 108 108 111]}
11 120
true
strings.Join 源码解析
实现原理
// Join concatenates the elements of its first argument to create a single string. The separator
// string sep is placed between elements in the resulting string.
func Join(elems []string, sep string) string {
switch len(elems) {
case 0:
return ""
case 1:
return elems[0]
}
n := len(sep) * (len(elems) - 1)
for i := 0; i < len(elems); i++ {
n += len(elems[i])
}
var b Builder
b.Grow(n)
b.WriteString(elems[0])
for _, s := range elems[1:] {
b.WriteString(sep)
b.WriteString(s)
}
return b.String()
}
前面计算出整个字符串需要的长度 (n),然后创建 (strings.Builder) 并通过 (Grow) 方法直接扩容,大小为 (0*2+n) 为 (n) ,然后通过 (WriteString) 方法写入,最后调用 (String) 方法返回字符串。只构造了一次字符串对象。
代码
func main() {
args := make([]string, 10000)
for i := 0; i < 10000; i++ {
args = append(args, strconv.Itoa(i+1))
}
var s string
start := time.Now()
for i := range args {
s += args[i]
s += " "
}
// fmt.Println(s) // ^ 因为切片数量过大先不打印就只做合并操作
t := time.Since(start)
fmt.Println("elapsed time", t)
/* -------------------------------------------------------------------------- */
start = time.Now()
s = strings.Join(args, " ")
fmt.Println(s)
t = time.Since(start)
fmt.Println("elapsed time", t)
}
elapsed time 230.8618ms
elapsed time 0s