
什么是RPC
RPC(Remote Procedure Call)远程过程调用协议,其本质是使一台机器上的程序能够调用另一台机器上的子程序,而无需关注操作系统和网络传输协议的细节,其整体工作流程如下:
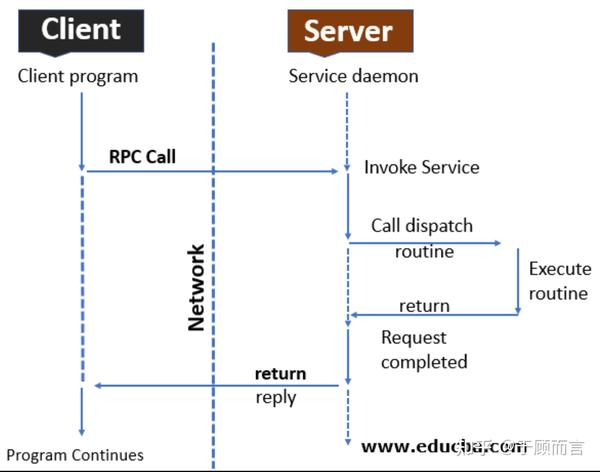
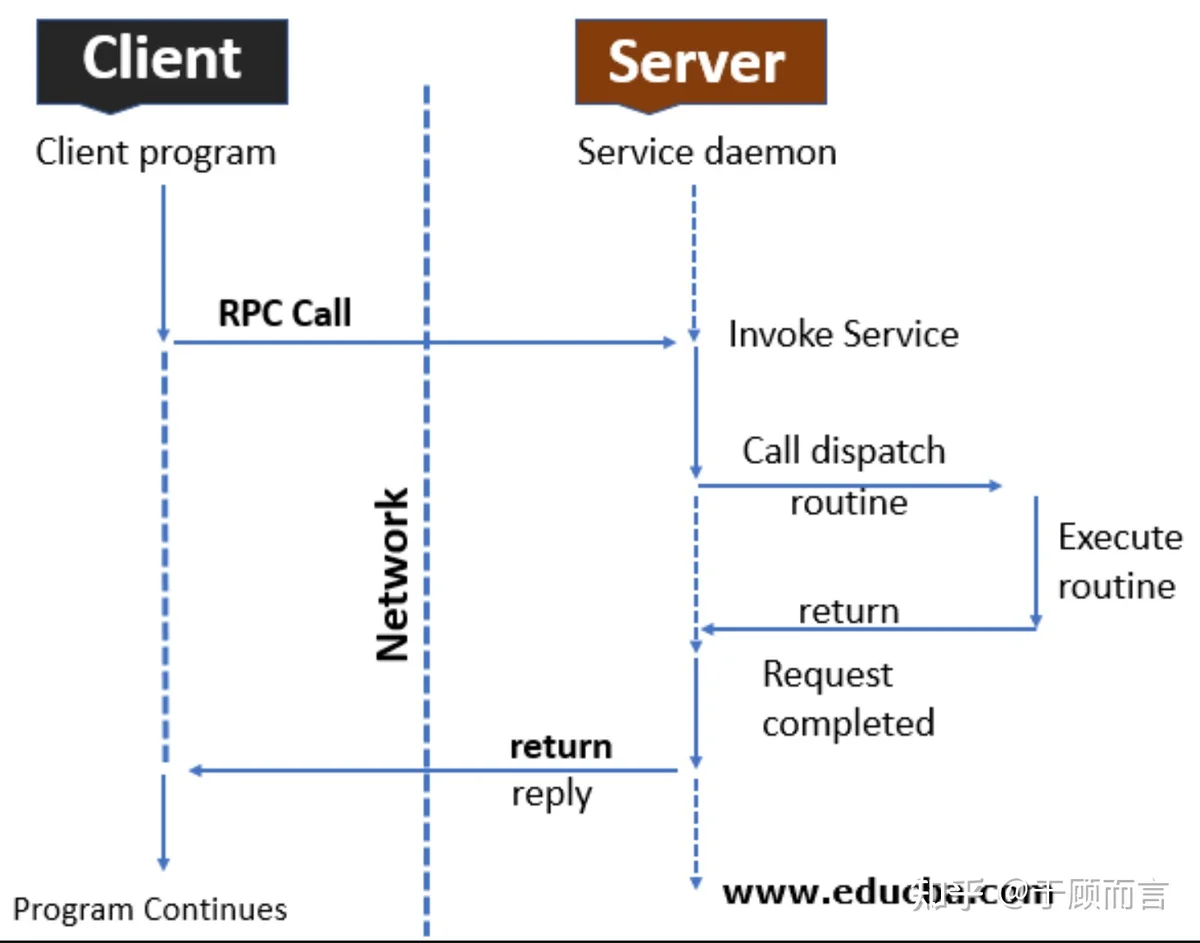
- 第一步,客户端向服务端发起rpc请求,这个请求的服务需要事先在服务端注册,也就是说服务端只会算加法,你来了一个减法请求,那显然会返回error
- 第二步,客户端发起的请求参数会通过序列化及网络传输到达服务端网卡
- 第三步,服务端收到请求报文后会通过反序列化获得执行参数,然后本地调用函数执行
- 第四步,服务端会将计算结果以相同的方式发送会客户端
- 第五步,客户端收到计算结果,这次rpc调用结束
好了,那么我现在打算用golang语言实现一个rpc调用框架,它可以方便的让我们服务端实现各种服务调用,比如base64编解码功能等等。为了不重复造轮子,我们先看看golang自带的net/rpc提供了哪些rpc调用能力。
net/rpc
下面以一个官方提供的一个简单例子来入门官方的net/rpc框架,然后再开始自己的魔改:
从这个例子从可以看到,net/rpc默认采用gob编解码,net库用于网络通信。仔细查看net/rpc代码结构发现其架构非常灵活,它通过codec将数据处理与io分开,数据处理可以自定义自己的头部格式和Marshall/unMarshall方法,io可以是 net/Conn,bytes.Buffer或者是自定义的io方法:
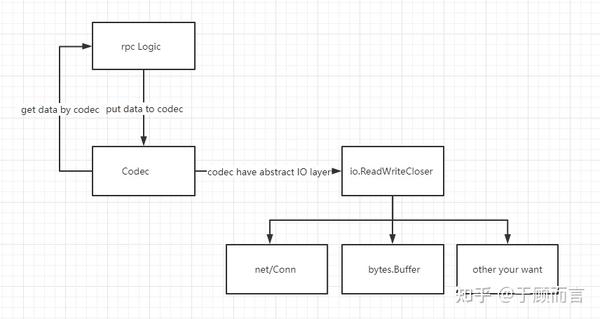
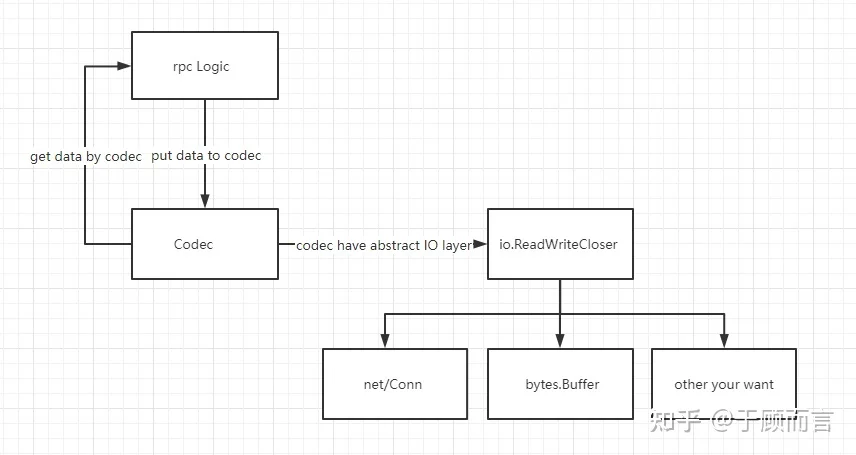
我自己新建一个工程叫zihurpc,然后将这个例子的源码按功能拆分到四个文件中:测试用例,rpc客户端实现,rpc服务端实现,以及一个目录myservice包含可以对外提供的各种服务:
用例执行如下:


proto3
通过阅读发现net/rpc使用gob编解码,具体是WriteRequest里面进行调用,那么我们能不能使用其他的序列化反序列的协议,比如说proto3,因为proto3序列化与反序列非常高效,通过下表很容易对比出来:
| 序列化 | 速度 ns/op | 内存开销 B/op | 反序列化 | 速度 ns/op | 内存开销 B/op |
|---|---|---|---|---|---|
| json | 982 | 224 | json | 2999 | 256 |
| easyjson | 643 | 720 | easyjson | 951 | 32 |
| gob | 5714 | 1808 | gob | 338 | 288 |
| protobuf | 114 | 48 | protobuf | 173 | 32 |
| msgpack | 311 | 160 | msgpack | 131 | 32 |
因此,我想用proto3编解码来替代net/rpc的gob方式,那么我们只需要重写net/rpc框架中codec部分即可,首先我们先定义自己服务的proto文件,然后通过protoc代码自动生成工具生成编解码的部分,比如说我们想要实现一个查询学生考试成绩的服务,我们的proto3定义如下:

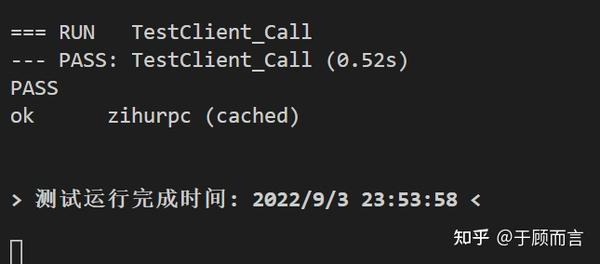
我们先验证一下,不用protoc编码看看我们的服务是否是通的:
head与codec
既然通了,下面我们用protobuf的方式编解码请求和响应报文,这个部分的实现需要重写codec,其实就是重写客户端和服务端的4个逻辑接口:
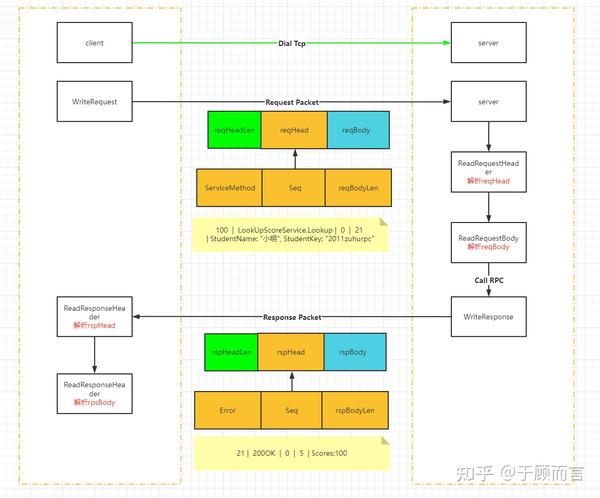
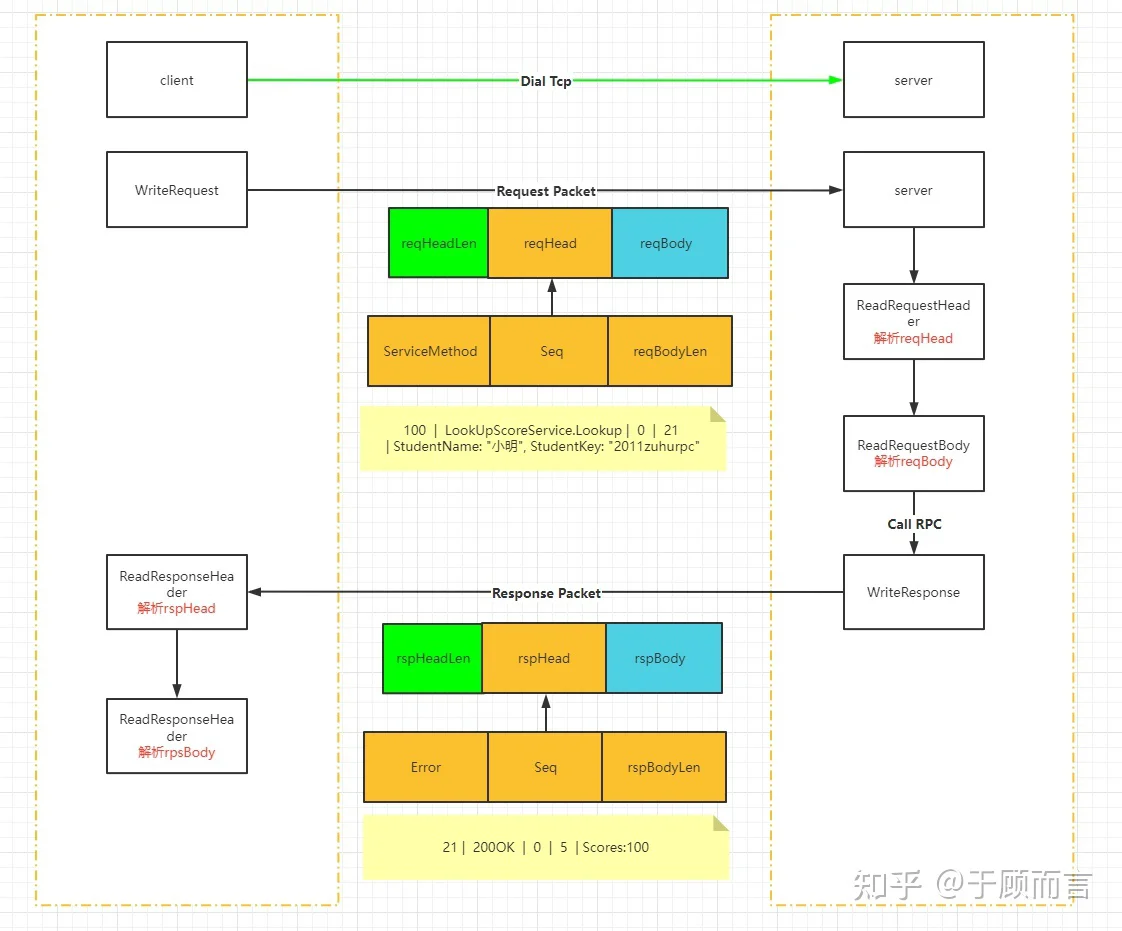
可以看到,go rpc将一次请求/响应抽象成了header+body的形式,读取数据时分为读取head和读取body,写入数据时只需写入body部分,go rpc会替我们加上head部分。这里面我设计了一个报文头部(防止粘包),然后请求和响应都共用这个结构体:
server端ReadRequestHeader的逻辑首先会先读取4个字节作为PktHead头部报文的长度,然后再根据PktHead结构体内成员变量的大小,依次从字节流中读取出各个变量值:
server端ReadRequestBody的逻辑首先会通过头部PktHead的BodyLen字段知道请求参数的长度,读取网络字节流后再通过proto.Unmarshal(data, body)获取真正的请求参数。
server端WriteResponse的逻辑首先会将响应的头部信息组装成一个byte,然后再把响应的返回值做一个proto.Marshal(body),再然后先把头部信息的长度发出去,再依次发送响应的头部信息和序列化后的远程函数调用的返回值:
client端的逻辑和上面一模一样,怎么收就怎么发,这里就不详述了。
报文发送的流程如下:
详细的代码请见gitee:
运行详见go test -v截图:
暂时先写这么多,后面这个rpc程序还可以继续迭代新功能,比如说丰富请求和响应报文头部的定义,里面加入一些校验和(防止中间人篡改)和更明确的响应码(增加用户体检),具体可以参考http的来;或者增加码流加解密的方法(防止中间人监听);再或者可以对序列化后的数据进行压缩(gzip/zlib/snappy/lz4)以增加rpc的吞吐量;再或者引入内存池(sync.Pool)的机制,当我们频繁申请一个请求或响应对象时可以直接去对象池里面拿就好了,这个也是优化的功能;再或者我们现在网络io用的是io.ReadWriteCloser,这里可以优化为bufio.NewReader(conn),bufio提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,这样访问本地磁盘的次数就减少了,从而提高效率。其他功能点这里就不一一展开了,有时间再把这些迭代上去。